目录
[2.1. 为什么不用二叉查找树 / 红黑树?](#2.1. 为什么不用二叉查找树 / 红黑树?)
[2.2. 为什么不用哈希表(Hash)?](#2.2. 为什么不用哈希表(Hash)?)
[2.3. B 树(B-Tree)的妥协与痛点](#2.3. B 树(B-Tree)的妥协与痛点)
[2.4. B+ 树(MySQL 的选择)](#2.4. B+ 树(MySQL 的选择))
[三、 聚簇索引 vs 非聚簇索引](#三、 聚簇索引 vs 非聚簇索引)
[1. 聚簇索引(Clustered Index / 主键索引)](#1. 聚簇索引(Clustered Index / 主键索引))
[2. 非聚簇索引(Secondary Index / 辅助索引 / 二级索引)](#2. 非聚簇索引(Secondary Index / 辅助索引 / 二级索引))
[四、 回表(Lookup)](#四、 回表(Lookup))
[SQL 1(无回表):](#SQL 1(无回表):)
[SQL 2(发生回表):](#SQL 2(发生回表):)
一、什么是索引?
索引 是帮助MySQL加快查询速度 的排好序 的数据结构。
日常开发中,我们常说"给这个字段加个索引"。但在 MySQL 的物理世界(磁盘)里,索引绝对不是一个简单的"目录",而是一棵由数据页连接而成的庞大树形结构。
二、MySQL索引数据结构的选择
2.1. 为什么不用二叉查找树 / 红黑树?
-
二叉树(BST): 如果插入的数据是有序的(比如自增 ID 1, 2, 3, 4),二叉树会严重退化成一个一字长蛇阵(链表) 。此时查找时间复杂度退化为 O(N),跟全表扫描没区别。
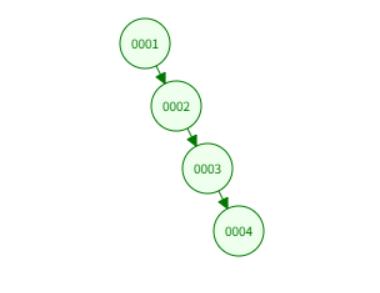
-
红黑树(平衡二叉树): 虽然红黑树会通过旋转自动保持平衡,查找时间复杂度是 O(log2N),但它致命的缺点是只有二叉 。当数据量达到千万级时,树的高度(Height)会非常高(可能达到 20 多层)。
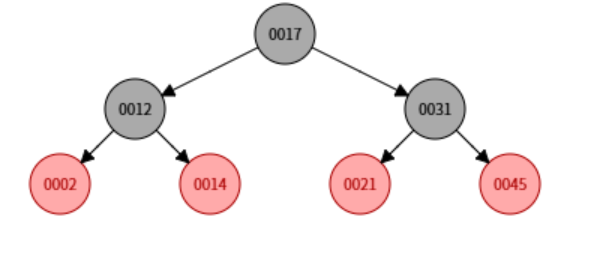
为什么高度致命? 在数据库中,树的每一层都代表一次磁盘 I/O。机械硬盘或固态硬盘的 I/O 是极慢的(毫秒级)。查一条数据要扇形扫描磁盘 20 多次,系统早就卡死了。
2.2. 为什么不用哈希表(Hash)?
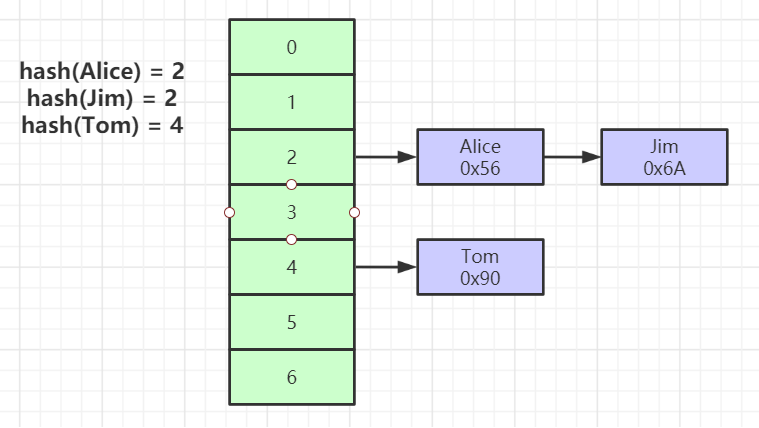
- Hash 的优势: 根据 Key 精确查找某一行数据时,时间复杂度是 O(1),快到飞起。
- Hash 的死穴: 无法进行范围查询(Range Query) 。比如
WHERE age > 20,Hash 索引就彻底抓瞎了,因为哈希函数映射后的值是无序的,它必须全表扫描。
2.3. B 树(B-Tree)的妥协与痛点
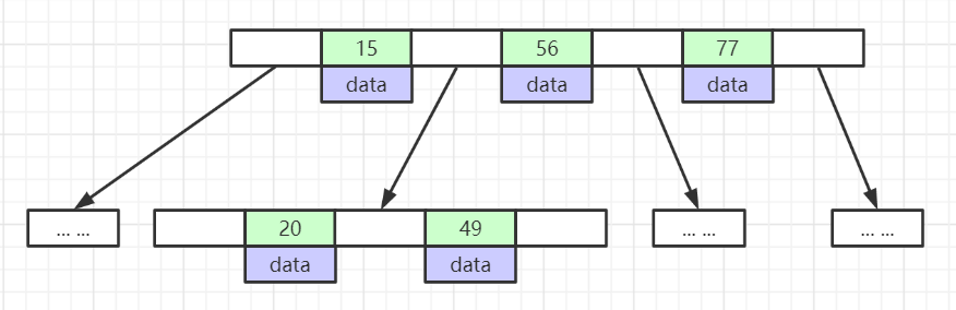
B 树是"多叉平衡查找树",它把二叉变成了"N叉",每个节点可以存多个数据,大大压低了树的高度。但它有一个致命问题:每个节点既要存索引的 Key,又要存这一行的整行数据(Data)。
- 计算机磁盘 I/O 的最小单位是页(Page,MySQL默认是 16KB)。
- 如果节点里塞满了大块的整行数据,那么一个 16KB 的页能存的索引数量就非常有限。这意味着树还是会变高,而且进行范围查询时,需要频繁在父子节点间"上下横跳"做回溯,效率很低。
2.4. B+ 树(MySQL 的选择)
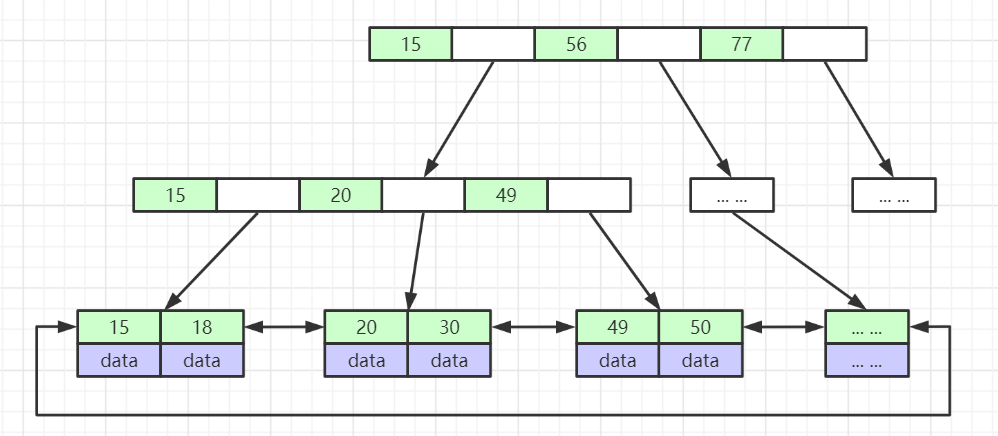
B+ 树是 B 树的改良版,它做出了两个决定性的改变:
- 非叶子节点不存 Data,只存 Key(索引值)和指针。 所有的完整数据(Data)全部挪到最底层的叶子节点。
- 所有的叶子节点之间,用双向链表首尾相连,且是有序的。
这带来的两个巨大优势:
- 出色的扇出(Fan-out)能力: 既然非叶子节点只存 Key 和指针(大概占 10-14 字节),那么一个 16KB 的页就能存下上百甚至上千个索引项。这意味着,一棵高度仅为 3 层 的 B+ 树,就能存储千万级的数据。你只需要 3 次磁盘 I/O 就能在两千万行数据里秒抓出你需要的那一行。
- 天然支持范围查询: 比如查
WHERE id BETWEEN 10 AND 50。B+ 树只需要先通过根节点往下定位到id=10的叶子节点,然后顺着叶子节点底部的双向链表一直往右扫 ,直到看到id=50停止。不需要再回溯到上层节点。
BTree和B+Tree对比
|-------------------|--------------------------------------|---------------------------------------------|
| 对比维度 | B-Tree (B树) | B+Tree (B+树 ------ MySQL 的选择) |
| 数据(Data)存在哪 | 所有节点(根节点、中间节点、叶子节点全都有数据) | 仅存在最底层的叶子节点中,上层节点纯粹是导航用的 Key。 |
| 单页(16KB)存储容量 | 极小。因为行数据很胖,一个页装不了几个 Key。 | 极大。因为不存行数据,一个页能装上千个 Key,树变得极矮胖。 |
| 范围查询(Between) | 灾难。 必须在树的上下层级之间不断回溯、重复遍历。 | 降维打击。 只需要找到左边界,直接沿着底部的链表向右顺序横扫。 |
| 查询稳定性 | 不稳定。运气好在根节点就找到了(1次 I/O),运气差在叶子节点才找到。 | 绝对稳定。 任何数据都必须走到最底层叶子节点,每次查询 I/O 次数严格一致。 |
三、 聚簇索引 vs 非聚簇索引
在 InnoDB 引擎中,根据叶子节点存储内容的不同,索引被严格分为两类。
1. 聚簇索引(Clustered Index / 主键索引)
聚簇索引不是一种单独的索引类型,而是一种数据存储方式 。它的核心特征是:索引的叶子节点,就是真正的数据行本身。
- 唯一性: 一张表有且只能有一个聚簇索引,因为数据物理上只能按一种顺序存储。
- InnoDB 的主键选择策略:
- 如果你定义了
PRIMARY KEY,InnoDB 就用它做聚簇索引。 - 如果没定义,InnoDB 会找第一个非空的唯一索引(Unique)代替。
- 如果连唯一索引都没有,InnoDB 会在后台自动生成一个 6 字节的隐式自增列(RowID)来构建聚簇索引。
2. 非聚簇索引(Secondary Index / 辅助索引 / 二级索引)
日常我们自己通过 CREATE INDEX 创建的索引(比如给 age、name 加索引),全部都是二级索引。它的核心特征是:索引的叶子节点,存储的是索引列的值 + 对应的主键值。
为了更直观地理解,它们在物理存储上的结构对比图如下:
【 聚簇索引 (主键 id) 】 【 二级索引 (普通列 age) 】
[ Root ] [ Root ]
/ \ / \
[ Node ] [ Node ] [ Node ] [ Node ]
/ \ / \ / \ / \
[Leaf] <=> [Leaf] <=> [Leaf] [Leaf] <=> [Leaf] <=> [Leaf]
| | | | | |
+-------+ +-------+ +-------+ +-------+ +-------+ +-------+
| id=1 | | id=5 | | id=10 | | age=18| | age=20| | age=25|
|name=A | |name=B | |name=C | | id=5 | | id=1 | | id=10 |
|age=20 | |age=18 | |age=25 | +-------+ +-------+ +-------+
+-------+ +-------+ +-------+ (叶子节点只存索引列的值和主键id)
(叶子节点包含整行数据的完整字段)四、 回表(Lookup)
假设 id 是主键,age 是二级索引。我们执行以下两条 SQL:
SQL 1(无回表):
sql
SELECT id FROM users WHERE age = 20;- 执行过程: 执行器请求 InnoDB 查
age索引树,在叶子节点找到了age=20,同时拿到它的对应主键id=1。因为你只需要id,二级索引树上已经有现成的了。 - 专业术语: 这叫 "覆盖索引(Covering Index)",效率极高,不需要看聚簇索引一眼。
SQL 2(发生回表):
sql
SELECT name FROM users WHERE age = 20;- 执行过程:
- 执行器请求 InnoDB 查
age索引树,找到age=20的节点,拿到主键id=1。 - 发现你要拿
name,但二级索引树上没有name的数据。 - 回表: InnoDB 拿着
id=1这个钥匙,转身去聚簇索引树(主键树)里重新查一次,从根节点一路向下定位到id=1的叶子节点,从中取出name=A。 - 把
name返回给执行器。
- 痛点: 这意味着你查一次数据,走完了两棵独立的 B+ 树。如果查询结果有 1000 条,可能就要执行 1000 次回表操作,这正是很多 SQL 变慢的根源。