深度学习(Deep Learning)是机器学习的重要分支。它以多层神经网络为核心,通过大量数据训练,使模型能够自动学习数据中的特征表示,并完成识别、预测、理解、生成和决策等任务。
与许多传统机器学习方法相比,深度学习更强调让模型在训练过程中自动学习特征。以图像为例,模型可以从像素中逐层提取边缘、纹理、局部形状、对象部件,最终形成对整张图像的语义判断;以文本为例,模型可以从词语、句子和上下文中学习语义关系;以视频为例,模型还需要理解连续画面中的动作变化和时间结构。
因此,深度学习特别适合处理图像、语音、文本、视频、时间序列等复杂数据。理解深度学习的主要任务,有助于把握它在人工智能系统中的基本分工。
一、深度学习任务的基本划分
深度学习面对的问题并不只是"分类"或"回归"。在真实应用中,它通常围绕复杂数据展开,例如:
• 识别图像中有什么对象
• 判断语音中说了什么内容
• 理解一句话或一段文本的含义
• 预测一段序列的未来变化
• 生成图片、文本、语音或视频
• 将复杂数据转换为向量表示
• 在环境中学习怎样行动
从整体上看,深度学习的主要任务可以概括为六类。
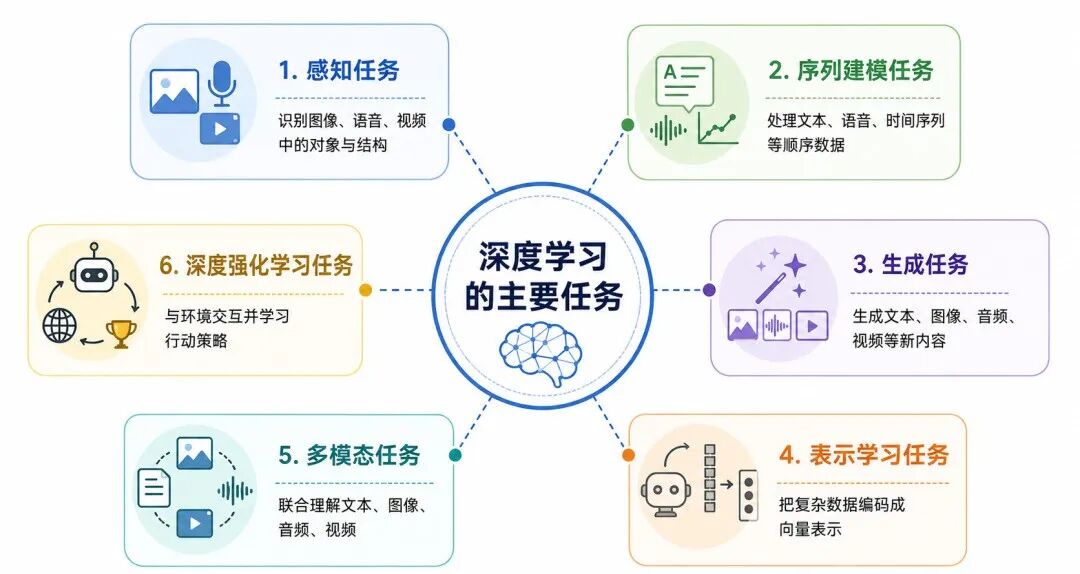
图 1:深度学习的主要任务分类
1、感知任务
从图像、语音、视频等数据中识别对象、内容、结构和变化。
2、序列建模任务
处理文本、语音、时间序列、视频帧等具有顺序关系的数据。
3、生成任务
学习数据分布,并生成新的文本、图像、音频或视频。
4、表示学习任务
把复杂数据转换为便于计算、比较、检索和迁移的向量表示。
5、多模态任务
联合处理文本、图像、音频、视频等不同类型的信息。
6、深度强化学习任务
使用神经网络与环境交互,学习更优行动策略。
需要注意的是,这些任务并不是完全割裂的。一个现代人工智能系统往往会同时涉及多种任务。
例如,大语言模型既涉及序列建模,也涉及文本生成和表示学习;多模态模型通常同时包含图像理解、文本理解、跨模态表示和生成能力;自动驾驶系统则可能同时使用目标检测、图像分割、轨迹预测和行为决策。
二、感知任务:让模型识别对象、内容与结构
感知任务(Perception Task)是深度学习最典型的应用方向之一。它主要处理图像、语音、视频等感知数据,使模型能够识别其中的对象、内容、位置、结构和变化。
例如:
• 在图片中识别猫、狗、汽车和行人
• 在医学影像中识别病灶区域
• 在工业场景中检测产品缺陷
• 在语音中识别说话内容
• 在视频中理解人物动作和事件变化
感知任务的核心是:把原始感知数据转换为可理解的语义结果。
以图像为例,一张图片在计算机中本质上是由像素组成的数组。深度学习模型要做的,不是直接"看懂"图片,而是通过多层网络逐步提取特征,从低级视觉模式逐渐形成高级语义判断。
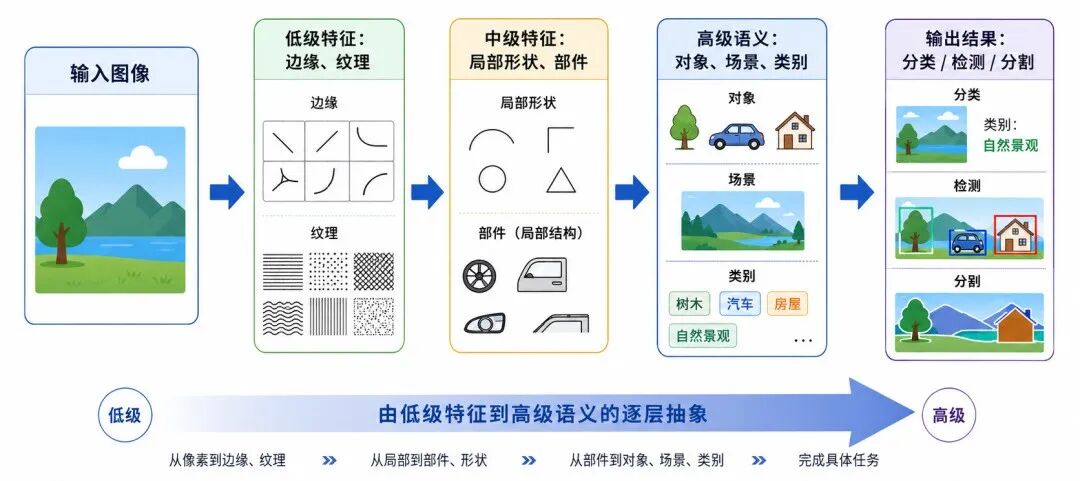
图 2:图像感知任务的一般过程
在深度学习中,感知任务常由卷积神经网络(Convolutional Neural Network,CNN)、视觉 Transformer(Vision Transformer,ViT)等模型完成。
1、图像分类
图像分类(Image Classification)是最基础的视觉任务。它的目标是判断一张图像属于哪个类别。
例如:
• 判断一张图片是猫还是狗
• 判断手写数字是 0 到 9 中的哪一个
• 判断医学影像是否存在某种疾病迹象
• 判断产品图片是否存在质量缺陷
若用数学形式表示,图像分类可以写成:
其中:
• x 表示输入图像
• f 表示深度学习模型
• ŷ 表示模型预测的类别
y 表示真实标签,任务目标是让 ŷ 尽可能接近 y。
对于多分类任务,模型通常会输出每个类别的概率:
其中:
• z 表示模型最后一层输出的原始分数
• p̂ 表示各类别的预测概率
softmax 常用于把多个分数转换为概率分布,概率最大的类别通常作为最终预测结果。
例如,在手写数字识别任务中,模型输入一张数字图片,输出 0 到 9 共 10 个类别的概率,概率最高的类别就是模型的判断结果。
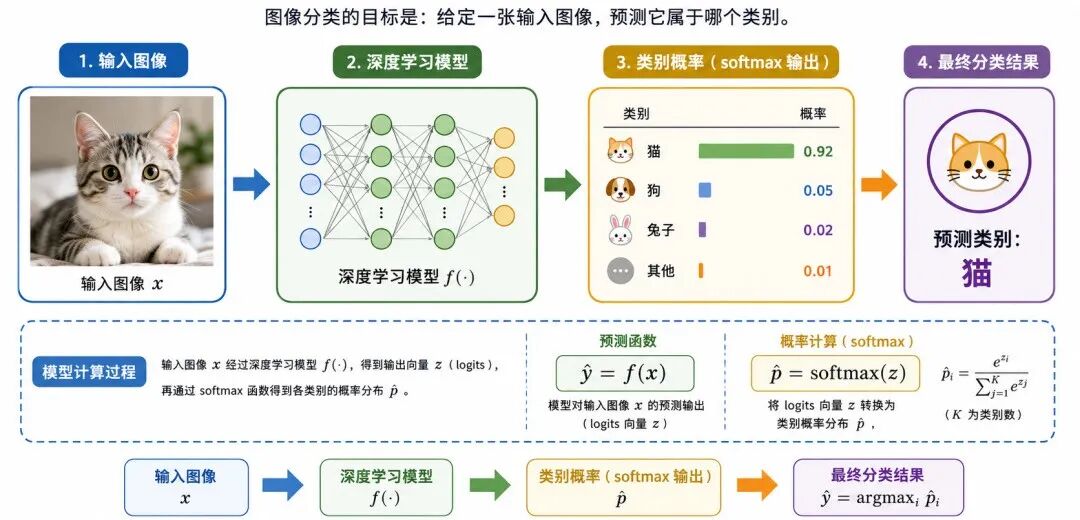
图 3:图像分类任务
2、目标检测
目标检测(Object Detection)不仅要判断图像中有什么,还要指出对象在哪里。
例如,在自动驾驶场景中,模型不仅要识别"行人""汽车""交通灯",还要给出它们在图像中的位置。这通常通过边界框(Bounding Box)表示。
一个目标检测结果通常包含两类信息:
• 类别:对象是什么
• 位置:对象在图像中的区域
其结果可以简化表示为:
其中:
• c 表示预测类别
• b 表示边界框位置
• ŷ 表示目标检测结果
边界框常见形式为:
其中:
• x 表示边界框中心点的横坐标
• y 表示边界框中心点的纵坐标
• w 表示边界框宽度
• h 表示边界框高度
常见目标检测模型包括 R-CNN 系列、YOLO 系列、SSD 和 DETR 等。
目标检测比图像分类更复杂,因为它同时包含"识别"和"定位"两个目标。
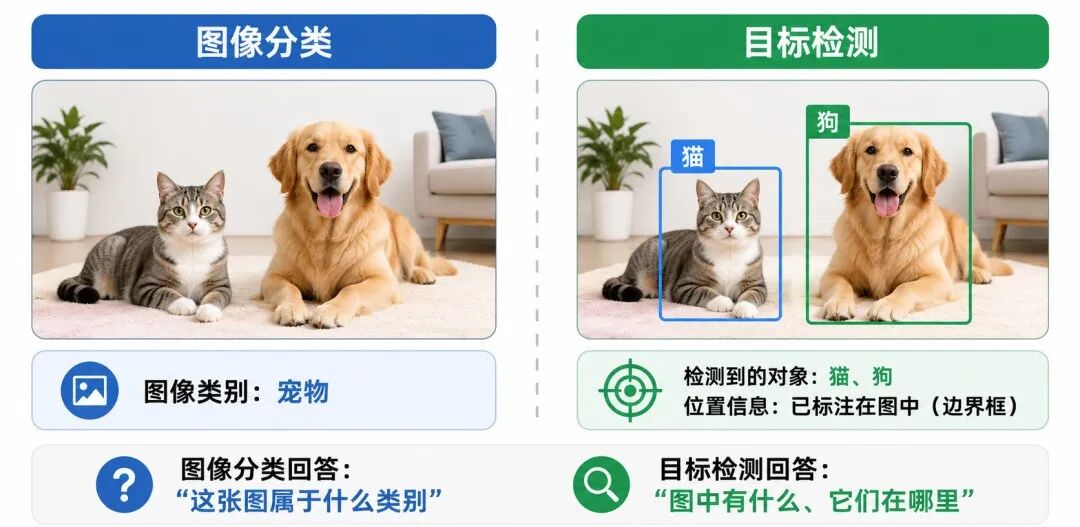
图 4:图像分类与目标检测的区别
3、图像分割
图像分割(Image Segmentation)进一步要求模型判断图像中每个像素属于哪个类别。
与目标检测相比,图像分割的结果更加精细。目标检测通常用矩形框标出对象的大致位置,而图像分割需要勾勒出对象的具体轮廓。
常见图像分割任务包括:
• 语义分割(Semantic Segmentation)
• 实例分割(Instance Segmentation)
• 医学影像分割
• 道路场景分割
• 智能抠图
语义分割的目标可以表示为:
其中:
• x 表示输入图像
• M 表示像素级类别掩码。M 中的每个位置对应原图中一个像素的类别
例如,在道路场景分割中,模型需要把每个像素判断为道路、天空、车辆、行人、建筑物等类别。

图 5:视觉感知任务的层级关系
从任务粒度看,图像分类最粗,目标检测更精细,图像分割最细。
4、语音识别与视频理解
除了图像任务,语音识别和视频理解也是重要的感知任务。
语音识别(Speech Recognition)的目标是把语音信号转换为文字内容,可以简化表示为:
其中:
• a 表示输入语音信号
• t̂ 表示模型识别出的文本
• f 表示语音识别模型
视频理解(Video Understanding)则要求模型理解连续画面中的对象、动作和事件。例如:
• 判断视频中正在发生什么动作
• 检测视频中的异常行为
• 识别体育比赛中的关键事件
• 理解监控视频中的人员活动
视频数据不仅包含空间信息,还包含时间变化。因此,视频理解通常比单张图像识别更复杂。
三、序列建模任务:理解有顺序关系的数据
序列建模任务(Sequence Modeling Task)处理的是有先后顺序的数据。文本、语音、时间序列、视频帧都属于典型序列数据。
例如:
• 一句话中的词语有前后顺序
• 一段语音中的声音帧按时间排列
• 股票价格、气温、电力负荷按时间变化
• 视频由连续帧组成
序列建模的核心是:模型不仅要理解单个元素,还要理解元素之间的上下文关系。
一个序列可以表示为:
其中:
• x 表示完整序列
• xₜ 表示第 t 个时间步或位置上的元素
• T 表示序列长度
序列建模的目标,是根据已有序列信息完成分类、预测、生成或转换。
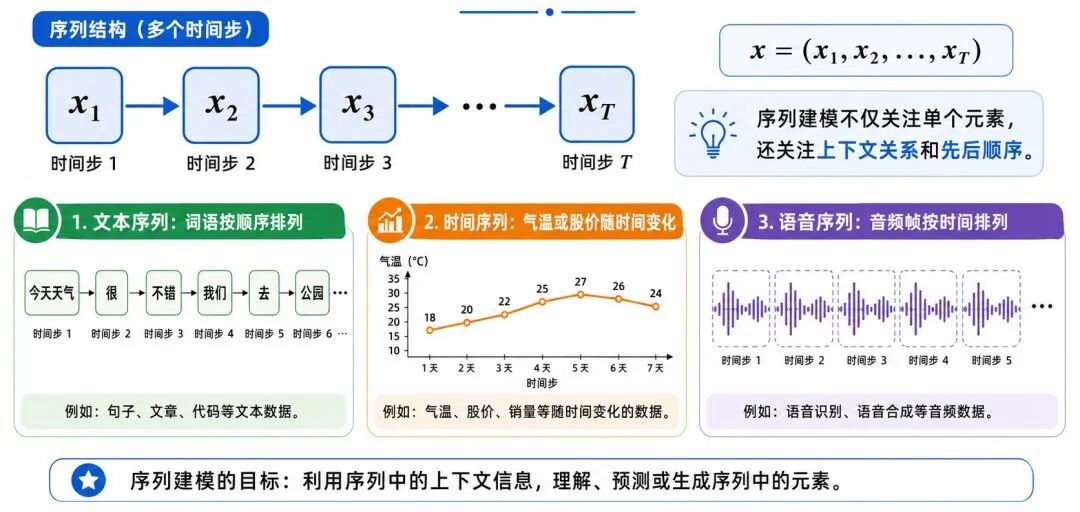
图 6:序列建模任务
1、文本分类
文本分类(Text Classification)是自然语言处理中的基础任务。它的目标是判断一段文本属于哪个类别。
例如:
• 判断一条评论是正面还是负面
• 判断一封邮件是否为垃圾邮件
• 判断一篇新闻属于财经、体育还是科技
• 判断用户问题属于哪个意图类别
文本分类可以表示为:
其中:
• x₁,x₂,...,xₜ 表示文本中的词、字或子词
• f 表示文本模型
• ŷ 表示预测类别
与普通分类不同,文本分类需要考虑词语顺序和上下文含义。例如,"不太好"和"好"只差几个字,但语义明显不同。
常见文本模型包括循环神经网络(Recurrent Neural Network,RNN)、长短期记忆网络(Long Short-Term Memory,LSTM)、门控循环单元(Gated Recurrent Unit,GRU)、Transformer 和 BERT 类预训练模型等。
2、序列预测
序列预测(Sequence Prediction)是根据已有序列预测未来内容。
例如:
• 根据过去几天气温预测明天气温
• 根据历史销量预测未来销量
• 根据前面的词预测下一个词
• 根据视频前几帧预测后续动作
序列预测可以写成:
其中:
• x₁,x₂,...,xₜ 表示已有序列
• x̂ₜ₊₁ 表示模型预测的下一个元素
• f 表示序列预测模型
如果预测多个未来时间步,则可以写成:
其中:
• k 表示需要预测的未来步数
模型需要根据历史趋势推断未来变化。
在时间序列预测中,深度学习模型常用于处理非线性关系、长时间依赖和多变量输入。
3、机器翻译
机器翻译(Machine Translation)是典型的序列到序列任务。它的目标是把一种语言的句子转换成另一种语言的句子。
例如:
• 中文翻译成英文
• 英文翻译成日文
• 法文翻译成中文
其基本形式可以写成:
其中:
• x₁,x₂,...,xₙ 表示源语言序列
• y₁,y₂,...,yₘ 表示目标语言序列
• n 和 m 可以不同,说明输入和输出长度不一定相等
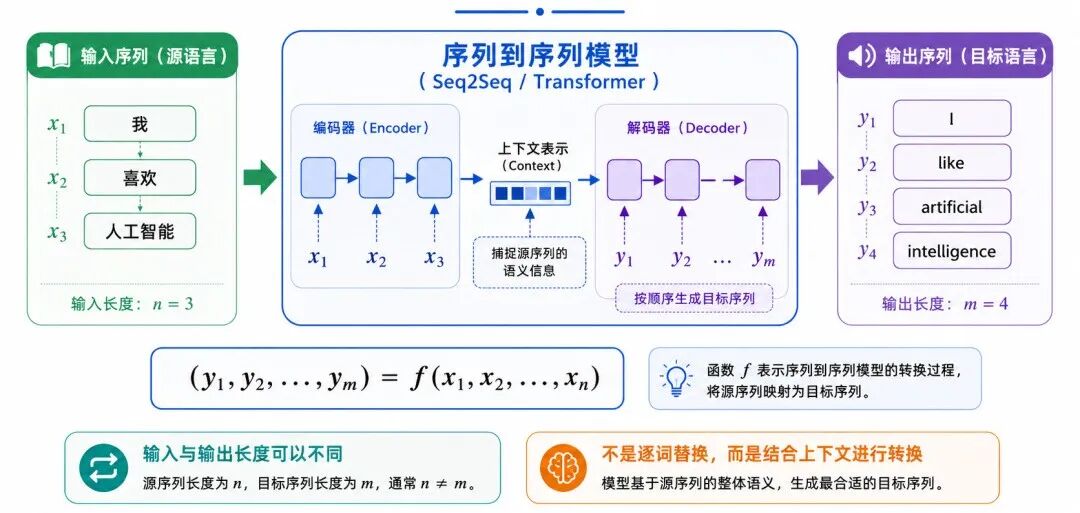
图 7:序列到序列任务
机器翻译并不是逐词替换,而是要理解上下文、语法结构和语义关系。因此,它是深度学习在自然语言处理中的重要任务之一。
四、生成任务:让模型创造新的内容
生成任务(Generative Task)的目标不是简单判断类别,也不是只预测一个数值,而是让模型生成新的数据。
例如:
• 根据提示生成一段文字
• 根据文字生成一张图片
• 根据文本生成语音
• 根据已有旋律生成音乐
• 根据已有视频生成后续画面
• 根据草图、线稿或低清图像生成新图像
生成任务的核心是:模型需要学习数据分布,并从这种分布中生成新的样本。
从数学角度看,真实数据可以表示为:
其中:
• x 表示真实数据样本
• p_data(x) 表示真实数据分布
• x ∼ p_data(x) 表示样本 x 来自真实数据分布
生成模型学习到的分布可以表示为:
其中:
• pθ(x) 表示模型学习到的数据分布
• θ 表示模型参数
• 目标是让 pθ(x) 尽可能接近 p_data(x)
这说明,生成任务的本质不是简单记忆训练样本,而是学习样本背后的规律,并生成符合这种规律的新内容。
2、文本生成
文本生成(Text Generation)是自然语言生成中的核心任务。它的目标是根据已有上下文生成后续文本。
例如:
• 自动续写文章
• 生成摘要
• 生成问答回复
• 生成代码
• 生成对话内容
在语言模型中,文本生成通常可以表示为:
其中:
• xₜ 表示第 t 个词、字或 token
• p(xₜ ∣ x₁,x₂,...,xₜ₋₁) 表示在前文条件下生成当前 token 的概率
• ∏ 表示连乘
• 整段文本的概率可以分解为逐步生成每个 token 的条件概率
这说明,文本生成通常不是一次性凭空产生整篇文本,而是根据已有上下文一步一步生成后续内容。
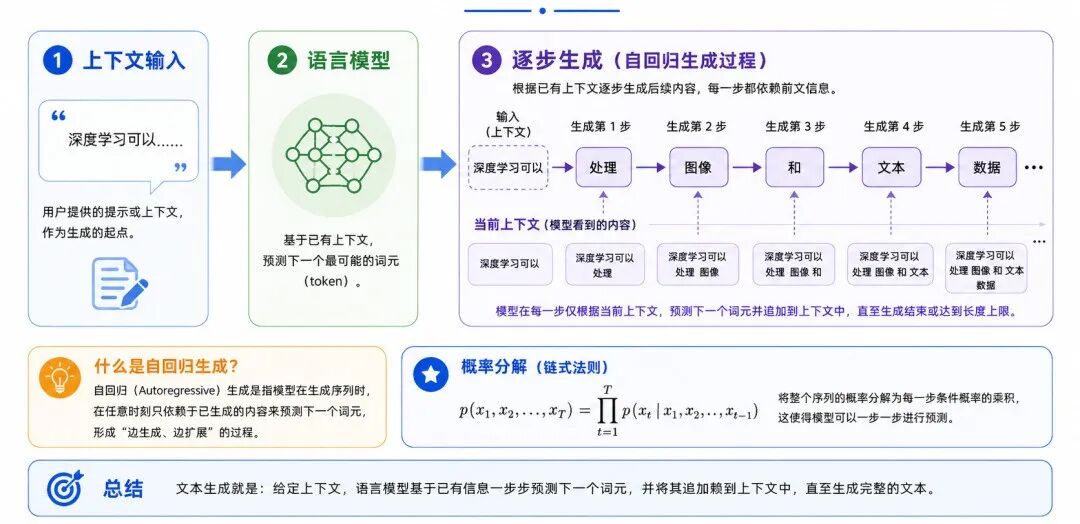
图 8:文本生成的一般过程
大语言模型(Large Language Model,LLM)就是典型的文本生成模型。它通过大规模语料训练,学习语言结构、知识关联和上下文表达方式。
2、图像生成
图像生成(Image Generation)的目标是让模型生成新的图像。
例如:
• 根据文字提示生成图片
• 根据线稿生成彩色图像
• 根据低清图像生成高清图像
• 对旧照片进行修复和上色
• 生成风格化人像、场景图或设计图
图像生成可以简化表示为:
其中:
• z 表示随机噪声或潜在向量
• G 表示生成模型
• x̂ 表示生成图像
如果是文本生成图像,则可以写成:
其中:
• c 表示文本条件
• z 表示随机噪声或潜在变量
• G 表示条件生成模型
• x̂ 表示生成图像
常见图像生成模型包括生成对抗网络(Generative Adversarial Network,GAN)、变分自编码器(Variational Autoencoder,VAE)和扩散模型(Diffusion Model)等。
在扩散模型中,模型通常先向图像逐步加入噪声,再学习如何从噪声中逐步恢复图像。这类方法已经成为当前图像生成的重要技术路线。
3、语音、音频与视频生成
语音生成(Speech Generation)、音频生成(Audio Generation)和视频生成(Video Generation)也是深度学习的重要生成任务。
例如:
• 文本转语音
• 语音克隆
• 音乐生成
• 音效生成
• 视频补帧
• 根据文本生成短视频
文本转语音任务可以表示为:
其中:
• t 表示输入文本
• â 表示生成的语音信号
• f 表示文本到语音的生成模型
视频生成可以简化表示为:
其中:
• z 表示随机噪声或潜在变量
• c 表示文本、图像或其他条件信息
• G 表示视频生成模型
• v̂ 表示生成视频
语音生成不仅要读出文字,还要控制发音、语调、停顿、节奏和情感。视频生成则需要同时保持画面质量、对象一致性和时间连续性,因此通常比静态图像生成更加复杂。
五、表示学习任务:把复杂数据转换为向量表示
表示学习(Representation Learning)是深度学习的核心思想之一。它的目标是让模型自动学习数据的有效表示,而不是完全依赖人工设计特征。
所谓"表示",可以理解为模型内部对数据的编码方式。
例如:
• 把一个词表示为一个向量
• 把一张图像表示为一个特征向量
• 把一个用户表示为一个兴趣向量
• 把一段文本表示为一个语义向量
• 把一段音频表示为一个声学向量
表示学习的基本形式可以写成:
其中:
• x 表示原始输入
• fθ 表示带参数 θ 的神经网络
• h 表示模型学习到的表示向量
• θ 表示模型参数
这说明,深度学习模型不仅会输出最终结果,还会在中间层形成对数据的抽象表示。
1、词向量与语义表示
在自然语言处理中,词向量(Word Embedding)是表示学习的典型例子。它把词语转换为向量,使计算机可以对词语进行数学计算。
例如:
• "苹果"可以表示为一个向量
• "橘子"可以表示为另一个向量
语义相近的词,在向量空间中通常距离较近。
词向量可以写成:
其中:
• w 表示一个词或 token
• e 表示该词对应的向量
• Embedding 表示嵌入层或嵌入函数
如果两个词语语义接近,它们的向量往往也更接近。常用的相似度计算方式是余弦相似度:
其中:
• a 和 b 表示两个向量
• a · b 表示向量点积
• ‖a‖ 和 ‖b‖ 表示向量长度
• 结果越接近 1,通常表示两个向量方向越相似
2、图像表示与跨模态表示
在计算机视觉中,深度学习模型也会把图像转换为特征向量。
例如,一张人脸图像可以被编码成一个向量,用于人脸识别;一张商品图片可以被编码成一个向量,用于相似商品检索。
图像表示可以写成:
其中:
• x 表示输入图像
• f_image 表示图像编码模型
• h_image 表示图像表示向量
在跨模态表示学习中,模型还需要把图像、文本、音频等不同类型的数据映射到统一表示空间。例如:
其中:
• t 表示文本
• x 表示图像
• h_text 表示文本向量
• h_image 表示图像向量
如果文本和图像语义匹配,那么它们在表示空间中的距离应当更近。
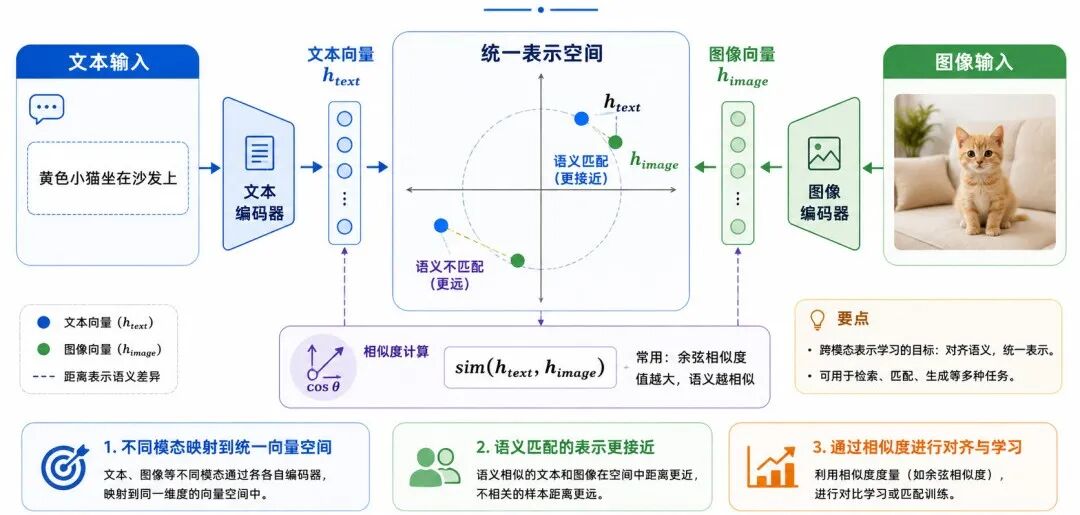
图 9:跨模态表示学习
表示学习之所以重要,是因为许多复杂任务都依赖好的表示。表示质量越高,分类、检索、推荐、生成和推理往往越容易完成。
3、预训练与迁移学习
在深度学习中,表示学习常常与预训练(Pre-training)和迁移学习(Transfer Learning)结合使用。
预训练是指先让模型在大规模数据上学习通用表示,再将这些表示迁移到具体任务中。迁移学习则是把一个任务中学到的知识,用到另一个相关任务中。
这一过程可以简化表示为:
其中:
• θ_pretrain 表示预训练阶段得到的模型参数
• θ_finetune 表示在具体任务上微调后的模型参数
• → 表示参数从通用任务迁移到具体任务
例如,一个在大规模图像数据上预训练的视觉模型,可以迁移到医学影像分类、工业缺陷检测等任务中;一个在大规模文本数据上预训练的语言模型,可以迁移到问答、摘要、分类、翻译等任务中。
这说明,深度学习中的表示并不只服务于单一任务,还可以成为多个任务共享的基础能力。
六、多模态任务:联合理解不同类型的数据
多模态任务(Multimodal Task)是深度学习发展的重要方向。它要求模型能够同时处理文本、图像、音频、视频等不同类型的数据,并在它们之间建立语义联系。
例如:
• 根据图片回答问题
• 根据文字生成图片
• 根据视频内容生成摘要
• 根据语音和画面理解会议内容
• 根据图文信息判断商品是否匹配
• 根据图片和文本进行跨模态检索
多模态任务的核心是:不同类型的数据虽然形式不同,但可以在语义层面建立联系。
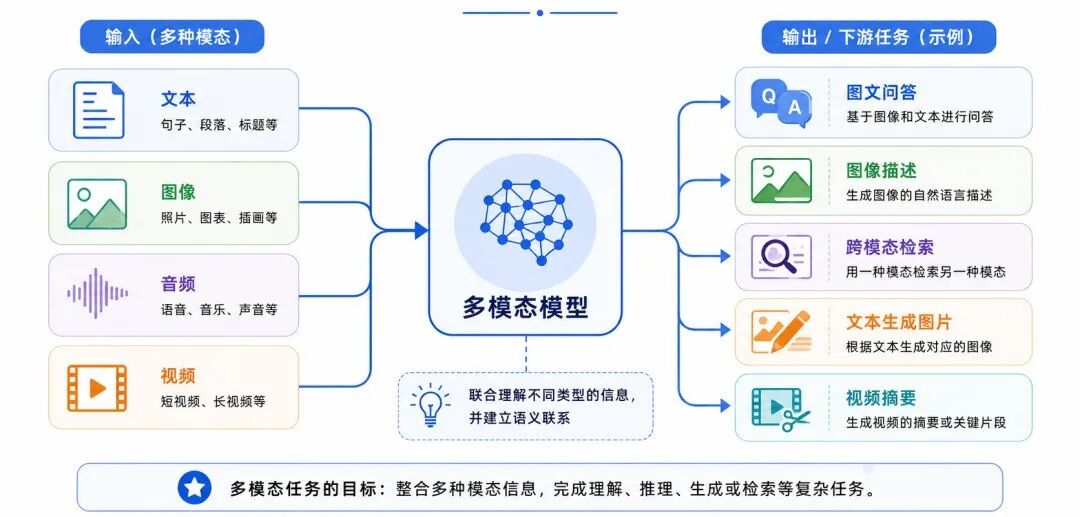
图 10:多模态任务的一般结构
1、图文理解
图文理解(Vision-Language Understanding)要求模型同时理解图像内容和文本问题。
例如,用户输入一张交通场景图片,并提出问题:
go
"图中是否有人正在过马路?"模型需要先识别图像中的道路、行人、车辆和交通环境,再结合文本问题给出回答。
图文问答可以表示为:
其中:
• q 表示文本问题
• x_image 表示输入图像
• a 表示模型回答
• f 表示图文理解模型
图文理解不是简单的"看图说话",而是要把视觉信息与语言问题结合起来。
2、跨模态检索
跨模态检索(Cross-modal Retrieval)是指用一种模态的信息去检索另一种模态的信息。
例如:
• 输入一句文字,检索相关图片
• 输入一张图片,检索相关文字描述
• 输入一段音频,检索相关视频片段
跨模态检索依赖统一表示空间。可以简化表示为:
其中:
• h_text 表示文本向量
• h_image 表示图像向量
• sim 表示相似度函数
相似度越高,表示文本与图像越匹配。
跨模态检索说明,深度学习不仅可以处理单一类型数据,还可以在不同类型数据之间建立语义桥梁。
七、深度强化学习任务:用神经网络学习行动策略
深度强化学习(Deep Reinforcement Learning)是深度学习与强化学习结合形成的方向。它使用神经网络表示策略函数或价值函数,使智能体能够在复杂环境中学习行动策略。
普通强化学习常用于状态空间较小的问题,而深度强化学习适合处理高维状态,例如:
• 游戏画面
• 机器人传感器数据
• 自动驾驶环境感知信息
• 连续控制任务
在深度强化学习中,智能体(Agent)通过与环境(Environment)交互,不断尝试动作,并根据奖励反馈调整策略。
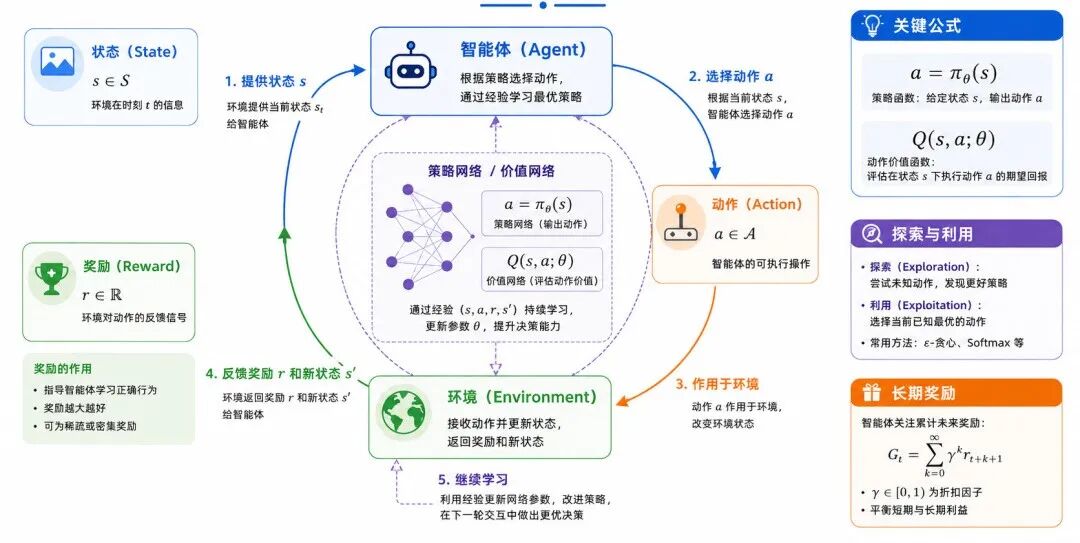
图 11:深度强化学习交互过程
1、策略学习
策略(Policy)表示智能体在某个状态下选择动作的规则。
在深度强化学习中,策略可以由神经网络表示:
其中:
• s 表示当前状态
• a 表示智能体选择的动作
• πθ 表示由参数 θ 控制的策略网络
如果动作是离散的,策略也可以输出每个动作的概率:
其中:
• πθ(a ∣ s) 表示在状态 s 下选择动作 a 的概率
模型训练的目标是让高价值动作获得更高概率。
例如,在游戏智能体中,输入可以是当前游戏画面,输出可以是向上、向下、向左、向右、攻击、跳跃等动作的概率。
2、价值学习
价值函数(Value Function)用于评估某个状态或某个动作在长期来看是否有利。
状态价值函数可以写成:
其中:
• V(s) 表示状态 s 的长期价值
价值越高,说明从该状态出发越可能获得较高累积奖励。
动作价值函数可以写成:
其中:
• Q(s,a) 表示在状态 s 下执行动作 a 的长期价值
它不仅评价当前状态,也评价具体动作。
在深度 Q 网络(Deep Q-Network,DQN)中,Q 函数由神经网络近似:
其中:
• θ 表示神经网络参数
• 模型输入状态 s,输出不同动作的价值估计
• 智能体通常选择 Q 值较高的动作
深度强化学习的核心难点在于:模型不仅要识别环境状态,还要在长期奖励、探索与利用之间做权衡。
八、深度学习任务之间的区别与联系
深度学习任务虽然形式多样,但并不是彼此孤立的。
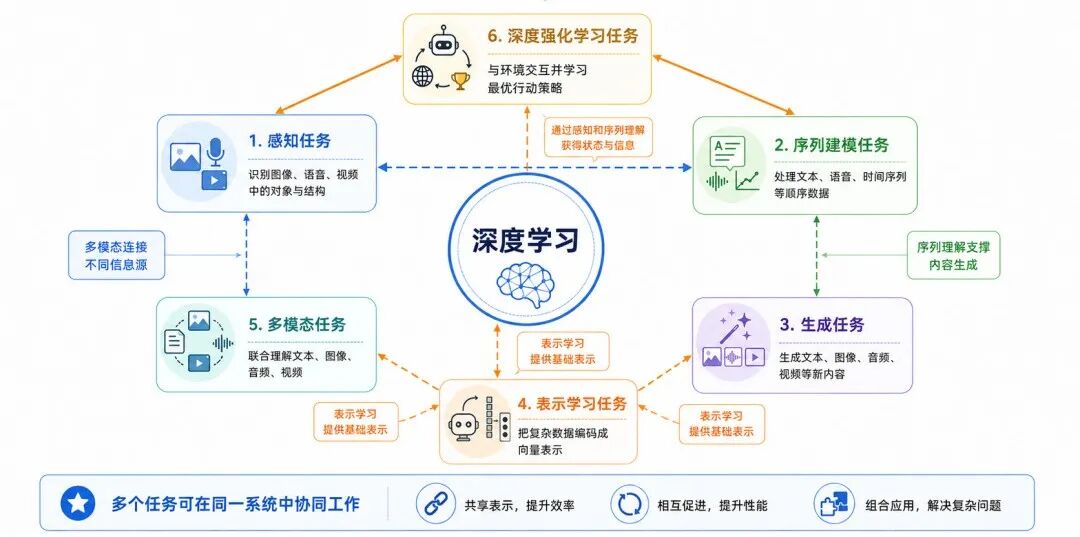
图 12:深度学习任务之间的关系
感知任务强调从复杂输入中识别对象和结构,例如图像分类、目标检测、图像分割、语音识别和视频理解。
序列建模任务强调处理有顺序关系的数据,例如文本分类、机器翻译、语音识别和时间序列预测。
生成任务强调学习数据分布,并创造新的内容,例如文本生成、图像生成、语音生成、音乐生成和视频生成。
表示学习任务强调学习数据的内部表示。它往往不是最终应用本身,而是支撑分类、检索、推荐、生成和推理的基础能力。
多模态任务强调联合处理不同类型的数据,使模型能够在文本、图像、音频和视频之间建立联系。
深度强化学习任务强调在交互过程中学习行动策略。它不只是"看懂数据",还要根据环境反馈决定"怎样行动"。
如果用更直观的话概括:
• 感知任务回答"看到了什么、听到了什么"
• 序列建模任务回答"前后关系是什么、接下来会怎样"
• 生成任务回答"能否创造新的内容"
• 表示学习任务回答"如何把复杂数据变成可计算的表示"
• 多模态任务回答"如何联合理解不同类型的信息"
• 深度强化学习任务回答"在环境中应该怎样行动"
从技术角度看,很多现代系统并不会只使用一种任务。例如,自动驾驶系统可能同时使用目标检测、图像分割、轨迹预测和强化学习;大语言模型既涉及序列建模,也涉及生成任务和表示学习;多模态模型则同时处理文本、图像、音频和视频。
因此,理解深度学习的主要任务,不只是记住若干任务名称,更重要的是理解:深度学习如何围绕数据表示、模式识别、内容生成、多模态理解和行为决策,构建完整的智能系统。
📘 小结
深度学习的主要任务包括感知、序列建模、生成、表示学习、多模态理解和深度强化学习。它通过多层神经网络学习复杂数据表示,既能识别内容、理解序列,也能生成数据、连接多种模态,并支持智能决策。

"点赞有美意,赞赏是鼓励"