一、短剧漫剧批量译制完整指南:流程、工具与团队协作
随着短剧和漫剧出海项目数量不断增加,越来越多团队开始面临规模化译制带来的管理挑战。单个项目的翻译和配音工作或许能够通过人工协调完成,但当多个项目并行推进、更新频率持续提升时,流程效率、质量控制和团队协作往往会成为新的瓶颈。
在实际生产过程中,翻译、配音、审核和交付等环节相互关联,任何一个节点出现延迟或质量问题,都可能影响整体制作进度。例如角色音色不统一、术语翻译前后不一致、多语言版本返工率过高等问题,都会增加项目管理成本。对于批量译制团队而言,关键挑战不仅在于完成单条内容制作,更在于建立能够兼顾效率与质量的标准化生产流程。
本文将围绕短剧和漫剧出海场景,系统拆解批量译制的完整工作流程,包括产线标准化建设、团队协作模式、术语库管理、多语言版本生产以及批量交付策略等核心环节,为团队搭建可复制、可扩展的译制体系提供参考。

二、单条手工译制,为什么撑不起日更体量
手工译制单条视频的问题,不是质量不好,而是时间结构决定了它无法线性扩展。
一条20分钟短剧集数的完整译制流程,从转写、翻译、配音生成、音轨合成到字幕校对,手工操作大约需要4到8小时。如果是100集体量的短剧,光配音这一项的工时就是400到800小时,相当于一个人全职工作2到4个月只做这一件事。
更根本的问题是,手工流程里的每一步都是串行的------翻译没完成就没法生成配音,配音没生成就没法合成,合成没完成就没法审核。任何一个环节卡住,后面全部等待。这种串行结构在单条视频时感觉不明显,但在日更体量下会把等待时间指数级放大。
短剧批量翻译要解决的核心问题是把串行流程变成并行流程,同时把每个节点的重复操作变成一次设置、多次复用的自动化流程。
三、批量译制产线的标准生产流程
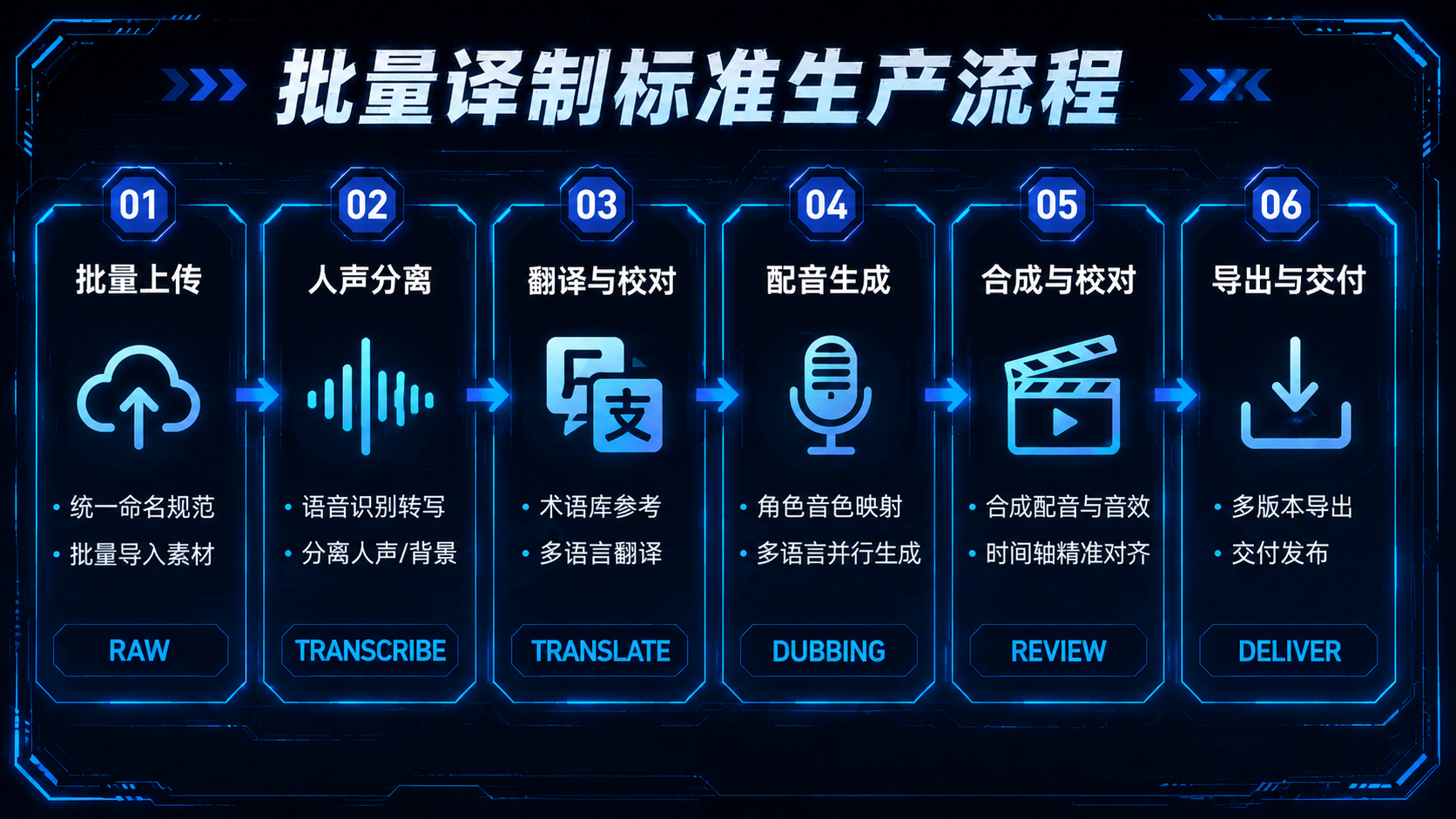
批量上传与命名规范,避免后期混乱
批量译制的第一个管理问题,往往不是技术问题,而是文件混乱问题。100集短剧同时在处理,如果命名不规范,处理到一半就会出现"这是第几集的配音""这个音色是哪个角色的"这类低效的信息确认。
建议在批量上传前统一文件命名规则:
剧名缩写 + 集数(三位数补零)+ 语言版本 + 状态标注。例如:XJY_EP001_EN_raw(星际游侠第1集英文原始版)、XJY_EP001_EN_final(完成版)。三位数补零的目的是让文件在文件夹里按集数顺序自然排列,避免出现第10集排在第1集和第2集之间的问题。
多语言版本同时推进时,在命名里加语言代码:EN(英语)、ES(西班牙语)、ID(印尼语)、TH(泰语),避免不同语言版本的文件混在一起。
处理状态用后缀标注,建议设四个状态节点:raw(原始上传)、dubbed(配音完成)、reviewed(人工审核通过)、final(可发布版本)。任何时候打开文件夹,每条视频处在流程的哪个节点一目了然。
术语库与角色音色映射,保证全集一致
AI漫剧译制和短剧译制面临同一个跨集一致性问题:第1集设定好的角色名翻译,到第50集有没有保持一致?主角的配音音色在第1集和第80集是同一个声音吗?
这两个问题靠人工记忆来保证是不可靠的,需要在流程开始前建立两份基础文件:
术语库:记录所有专有名词的固定译法。角色名、地名、组织名、特殊道具名------这些词在翻译时如果没有统一标准,会在不同集数里出现不同译法,观众会察觉。术语库在第一集翻译完成后就应该建立,后续每集翻译时强制对照。漫剧的术语库通常比短剧更复杂,因为漫剧世界观设定往往更庞大,专有名词密度更高。
角色音色映射表:列出所有出场角色(至少包括所有有台词的角色),每个角色对应一个固定的音色ID。主要角色必须一对一锁定,次要角色可以按声音类型归类(青年男配、中年女配等)。这份映射表在批量处理时作为配音参数的输入依据,系统自动调用,不依赖每次手动选择。
多语言一次性批量导出
短剧自动化译制的效率杠杆之一,是把多语言版本的生产并行化,而不是先做完英文版再做西班牙语版。
在实际产线里,多语言并行的操作逻辑是:原视频上传并完成人声分离之后,去人声底轨作为所有语言版本的共同基础,同时触发多个语言的翻译和配音生成任务。英文版、西班牙语版、印尼语版可以在同一批次里并行处理,而不是排队串行。
多语言并行的前提条件是:术语库在各语言版本之间保持对应关系(每个专有名词在每种语言里都有固定译法),以及每种语言都有预先设置好的角色音色映射。这两份基础文件如果在第一批处理前准备好,后续批量并行导出的质量才有保证。
四、哪些节点必须保留人工审核
批量自动化不等于全程无人值守。漫剧出海和短剧出海的规模化产线里,有几个节点的人工审核是省不掉的,省掉之后出现的问题会在后期以更高的成本暴露出来。

首集全量审核
每部剧或每个新项目的第一集,必须做完整的人工审核,而不是抽检。第一集的审核目标是验证所有参数设置是否正确:术语库覆盖是否完整、角色音色映射是否符合预期、翻译风格是否和内容调性匹配。第一集发现问题并修正,后续批量处理才能稳定。如果第一集跳过全量审核,问题会在第10集、第30集才暴露,到时候返工成本是第一集的数十倍。
新角色引入集的音色核查
当剧情发展到新的主要角色登场时,这一集需要单独审核新角色的音色设置。新角色的音色是在这一集第一次出现,如果这里设置错误,后续所有包含这个角色的集数都会跟着出错。
情绪密集段落的专项抽检
批量处理完成后,在整批次里专项抽取情绪密集的段落进行审听,而不是随机抽集。大哭、争吵、摊牌、临终独白------这类段落是AI配音最容易出现情绪强度不足的地方,也是观众最容易感知到问题的地方。每批次完成后,花20到30分钟专门回放这类段落,能拦截掉大部分会损害观看体验的质量问题。
多语言版本的交叉核查
多语言并行处理完成后,对同一个情节段落,分别播放两个语言版本,确认情绪方向和节奏在不同语言里保持一致。有时候同一句台词,英文配音情绪方向对了,西班牙语版本却因为语言节奏的差异而显得平淡,需要在这个节点发现并修正。
五、小团队怎么用 VividDub 搭起译制工作流
对于3到5人的小团队来说,短剧漫剧批量译制的工作流搭建,核心目标是让有限的人力专注在只有人能做好的环节(翻译质量判断、情绪审核、术语维护),把所有可以自动化的操作交给工具处理。

VividDub 在这套工作流里覆盖的环节:
原视频批量上传后,系统自动完成语音识别和人声分离,生成带时间轴的原语言文稿。这个步骤在传统手工流程里通常需要专门的转写人员,自动化处理后这个人力可以释放出来做其他工作。
角色音色映射表在VividDub的项目设置里配置完成后,批量处理多集时系统自动调用对应角色的音色,不需要每集手动选择。术语库可以在翻译文稿的编辑界面里作为参照,翻译人员在工具内直接完成文稿校对和改写,而不需要在工具外部维护一份单独的文档再粘贴回来。
多语言并行导出在同一个项目里操作,选定目标语言后系统并行生成各语言版本的配音,共用同一条去人声底轨,不需要重复上传原视频。
配音与背景音轨的合成在平台内自动完成,导出成片格式直接满足各发布平台的上传要求。
对于日更体量的团队,建议把VividDub的批量处理排程和团队的人工审核节奏对齐:每天批量提交一批新集数,次日完成后进行当天的人工抽检,形成稳定的日产出循环。
六、规模化译制团队最常问的问题
80到100集能批量自动处理吗?
可以,但"批量自动处理"的前提是前期参数标准化工作完成到位。在正式批量提交100集之前,需要完成:第一集全量审核通过、所有主要角色的音色映射确认、术语库建立并验证。这三项工作完成后,后续批量处理可以高度自动化,人工介入主要集中在抽检和问题修正上。如果跳过前期标准化直接批量处理100集,出现系统性问题(如某个角色音色全部跑偏)时的返工成本会非常高。
多角色怎么自动分配音色?
核心是在项目开始前建立角色音色映射表,而不是依赖系统自动判断。全自动的说话人识别和音色分配在技术上可以实现,但在短剧和漫剧这类多角色、对话密集的内容里,自动识别的准确率在复杂段落(多人同时出现、旁白与对话交替)下会下降。更可靠的做法是:第一集处理时人工完成说话人标注和音色分配,生成角色映射配置文件,后续批量处理时系统调用这份配置自动分配,而不是每次重新判断。
批量处理时背景音效会保留吗?
取决于工具是否支持人声分离。支持人声分离的工具,在处理每条视频时会把人声轨道和背景声(BGM、音效、环境声)分开保存,配音替换后背景声自动还原。批量处理时每条视频独立完成这个分离和还原流程,背景声保留不受批量数量影响。需要注意的是,背景声中如果有中文歌词的BGM,人声分离有时会把BGM人声也一并处理,需要在第一集审核时确认这种情况是否出现。
漫剧和短剧在译制流程上有什么区别?
漫剧的主要特殊性在于:通常没有真人人声,原始素材是纯配音加动画,人声分离相对简单,但角色数量往往更多,术语密度更高,世界观设定词汇需要在术语库里做更细致的管理。短剧有真人表情和肢体语言,配音的情绪方向需要更严格地与画面表演对齐。两种内容的批量译制产线框架基本相同,差异主要体现在术语库的复杂度和情绪配音的审核标准上。
译制质量怎么在批量处理后快速评估?
建议建立一套标准化的抽检评分表,对每批抽检的集数从三个维度打分:音色一致性(主要角色声音是否全程稳定)、情绪准确性(重点情绪段落的配音强度是否达标)、时间轴精度(配音和画面节奏是否对齐)。三个维度各自5分,总分低于12分的集数需要返回修正,高于12分的可以进入发布队列。这个评分标准不需要专业配音知识,团队成员都可以执行,保证抽检结果的客观性和可比性。
结尾
短剧漫剧批量译制的规模化,本质上是一个产线管理问题。工具的自动化能力决定了产量上限,但前期的标准化准备(术语库、音色映射、命名规范)和人工审核节点的设计,决定了这条产线能不能稳定运转而不是频繁返工。
把这篇文章里的流程跑通一遍,建立起可复用的参数配置和审核标准,批量译制的效率才能真正发挥出来。