RT-DETRv2训练自定义数据集的排坑全记录
最近在使用lyuwenyu/RT-DETR的PyTorch版本训练自定义缺陷检测数据集,从启动报错到成功训练,踩了不少典型的"新手坑",这里把完整的排坑过程和解决方案整理出来,帮大家一次性避坑!
一、环境与项目准备
1.1 项目准备
我用的是Windows系统,Anaconda创建的Python 3.8环境,PyTorch 2.0+,CUDA 11.8,项目结构如下:
RT-DETR-V2/
├── tools/train.py # 训练入口脚本
├── configs/rtdetrv2/ # 模型配置文件
├── src/ # 核心源码
└── datasets/ # 自定义数据集数据集是COCO格式,包含train.json、val.json和图片文件,标注的类别是N和P两类。
1.2 选择yml文件
选择训练时传入的yml文件,我是用这个,不用改
长这样
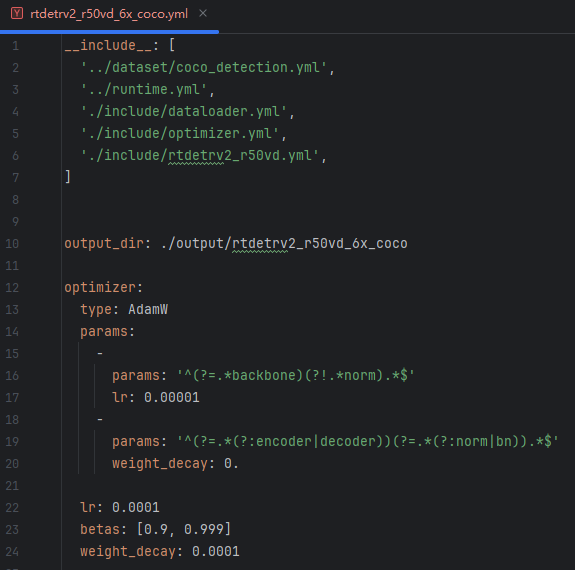
1.3 修改coco_detection.yml文件
修改coco_detection.yml文件,修改输入数据集路径、num_classes和remap_mscoco_category,我的是2个类别 ,yolo格式的类别ID是0、1,而coco是从1开始为,变为1、2,这里num_classes则填3 ,下文的坑3就是填为2,报错了
1.4 修改训练的epoches
修改dataloader.yml和optiminzer.yml中的epoches,2个文件的epoches需要保持一致
1.5 开始运行
命令为: python tools/train.py -c configs/rtdetrv2/rtdetrv2_r50vd_6x_coco.yml二、排坑全过程(按报错顺序)
坑1:FileNotFoundError: No such file or directory 配置文件找不到
报错截图:
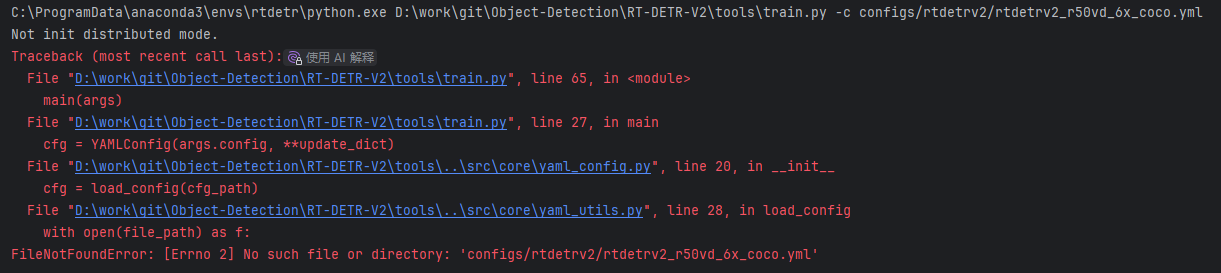
报错信息:
FileNotFoundError: [Errno 2] No such file or directory: 'configs/rtdetrv2/rtdetrv2_r50vd_6x_coco.yml'问题分析:
启动命令是在tools目录下运行的:
bash
python tools/train.py -c configs/rtdetrv2/rtdetrv2_r50vd_6x_coco.yml此时工作目录是tools/,相对路径configs/会被解析为tools/configs/,但配置文件实际在项目根目录的configs/下,路径不匹配导致文件找不到。
解决方案:
-
方法1:切换工作目录到项目根目录
bashcd D:\work\git\Object-Detection\RT-DETR-V2 python tools/train.py -c configs/rtdetrv2/rtdetrv2_r50vd_6x_coco.yml -
方法2:使用绝对路径
bashpython tools/train.py -c D:\work\git\Object-Detection\RT-DETR-V2\configs\rtdetrv2\rtdetrv2_r50vd_6x_coco.yml
坑2:UnicodeDecodeError: 'gbk' codec can't decode byte 0xaf JSON文件编码错误
报错截图:
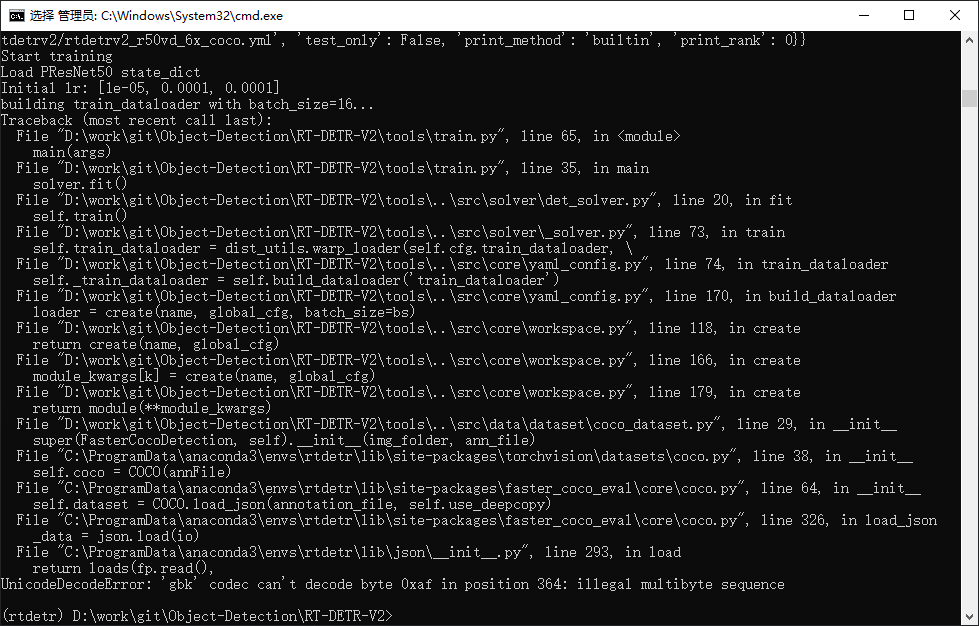
报错信息:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xaf in position 364: illegal multibyte sequence问题分析:
我的图像文件有中文字符 ,Windows系统默认编码是GBK,而你的COCO标注JSON文件是UTF-8编码,文件中包含了GBK无法识别的字符(比如特殊标点、中文注释 ),导致json.load()读取失败。
解决方案:
修改src/data/dataset/coco_dataset.py中读取JSON文件的代码,指定encoding='utf-8':
python
# 原代码(报错)
self.coco = COCO(ann_file)
# 修改后
with open(ann_file, 'r', encoding='utf-8') as f:
self.coco = COCO(json.load(f))或者直接用VS Code打开train.json,点击右下角的编码格式,选择UTF-8保存,强制转换编码。
坑3:CUDA error: device-side assert triggered 类别ID越界
报错截图:
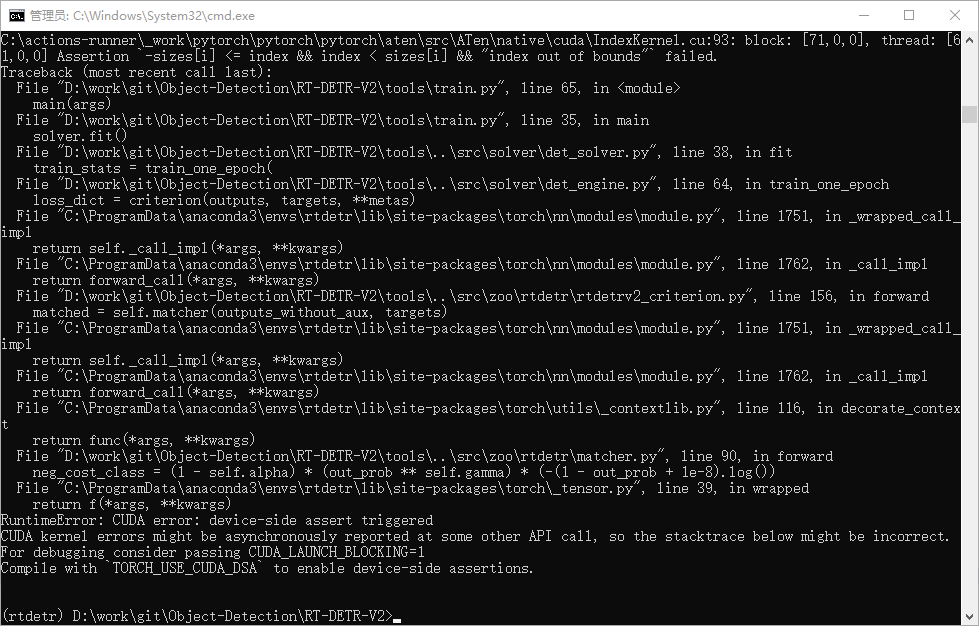
报错信息:
C:\actions-runner\_work\pytorch\pytorch\pytorch\aten\src\ATen\native\cuda\IndexKernel.cu:93: Assertion `index out of bounds` failed.
RuntimeError: CUDA error: device-side assert triggered问题分析:
这是DETR系列模型最经典的"类别ID越界"错误,根源是:
-
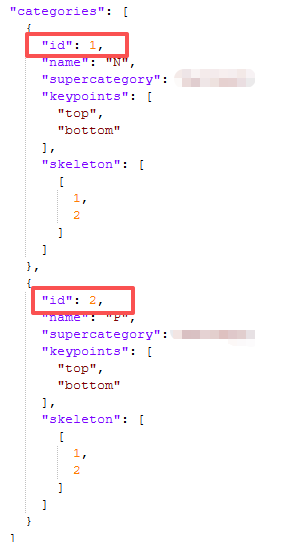
你的标注文件中,
categories的id是从1开始的(N:1、P:2) -
配置文件中
num_classes: 2,模型预留的类别索引是0和1 -
当模型读取到
category_id=2的标注时,会尝试访问数组的第3个位置(索引从0开始),直接越界触发CUDA断言错误。
解决方案:
有两种方案,推荐方案1,不用修改标注文件: -
方案1:修改配置文件
num_classes
把rtdetrv2_r50vd_6x_coco.yml中的num_classes改成3,这样模型就支持0,1,2三个索引,完美匹配你的标注ID。yaml# 原配置 num_classes: 2 # 修改后 num_classes: 3 -
方案2:修改标注文件,把类别ID改成从0开始
json"categories": [ {"id": 0, "name": "N"}, {"id": 1, "name": "P"} ]同时把所有
annotations中的category_id:1改成0,category_id:2改成1,保持num_classes:2不变。
最终成功训练的日志截图
解决完以上三个坑后,模型终于正常启动训练,loss也在稳定下降:
Epoch: [0] [0/48] eta: 0:11:06 lr: 0.000000 loss: 40.9994 (40.9994)
Epoch: [0] [47/48] eta: 0:00:01 lr: 0.000000 loss: 40.2926 (40.7860)三、避坑总结与经验
- 路径问题优先排查:Windows下运行脚本时,一定要注意工作目录和相对路径的匹配,优先切换到项目根目录运行。
- 编码问题别忽视 :JSON文件在Windows下很容易出现编码错误,读取时务必指定
encoding='utf-8'。 - 类别ID是重中之重 :DETR模型对类别ID非常敏感,必须保证标注的
category_id不超过num_classes-1,要么修改配置,要么重映射ID。 - 调试CUDA报错的技巧 :在
train.py最顶部加上os.environ["CUDA_LAUNCH_BLOCKING"] = "1",可以强制同步CUDA操作,让报错直接定位到CPU代码行,更容易排查问题。