这次学习SAC算法,由于训练过程从工程实现角度来说和前面PPO大体是一样的,所以直接进入骨架细读阶段,但有几个点需要提前了解:
on-policy和off-policy的区别
SAC算法是off-policy的,即离线。所谓在线和离线,核心区别就是数据分布是否由当前策略产生,这样说的确太官方,定义很好找但理解可不容易,所以最简单的就是从实现操作层面来理解
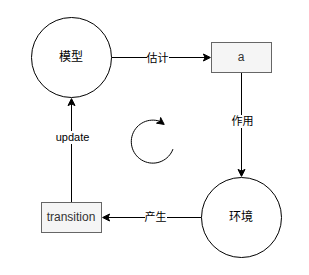
从上一篇我们大体可以学会这样一个训练套路,那么on和off的差别其实就是transition是否从a来,是就是on,否就是off,所以PPO-clip就是on-policy。而SAC是off-policy,因为它在环境和transition之间多了一个叫replaybuffer的东西。
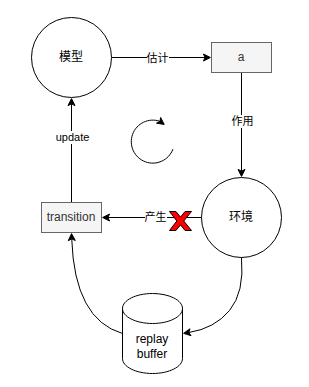
这个replaybuffer每一轮循环都会把数据存起来,而在取数据的时候是随机取的,也就是说buffer里有很多轮前的数据(完全不同于当前轮的策略,模型参数),这意味着从replaybuffer取出来的transition不一定来自这轮的a,也就不是这轮的模型参数,回到官方定义上,数据分布不一定由当前策略产生 ,所以它是off-policy的**。**由于数据的珍贵性,工程落地时肯定是能用离线数据就尽量用。
任务目标
SAC的实现示例代码没法用CartPole了,因为它是用于离散任务的,所以这次的任务目标会换成"Pendulum-v0":

DEBUG脚本和配置
test_sac_pytorch.py
python
from spinup.algos.pytorch.sac.sac import sac
from spinup.utils.run_utils import setup_logger_kwargs
import gym
def env_fn():
return gym.make("Pendulum-v0")
if __name__ == "__main__":
logger_kwargs = setup_logger_kwargs("pendulum_sac", seed=0)
sac(
env_fn=env_fn,
epochs=10,
steps_per_epoch=1000,
update_after=100,
logger_kwargs=logger_kwargs
)launch.json:
python
{
"version": "0.2.0",
"configurations": [
{
"name": "Debug test_sac_pytorch.py",
"type": "debugpy-old",
"request": "launch",
"program": "${workspaceFolder}/test/test_sac_pytorch.py",
"console": "integratedTerminal",
"justMyCode": false
}
]
}一 骨架细读
算法实现在spinup/algos/pytorch/sac/sac.py,算法的核心伪代码在官网的算法介绍中已经给出:

第一步,除了策略π,还初始化了两个模型Φ1和Φ2,和PPO里的优势函数A差不多,在PPO里优势函数用来评估这个动作比平均水平的相对价值,而Q是用于评估这个动作的绝对价值,SAC中直接以模型的方式来使用Q,至于为什么是两个Q模型,主要是用于解决过高估计的问题,因为Q的本质是最大化价值
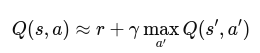
SAC 中的 Q 网络是用神经网络拟合的,网络预测存在误差,如果误差向正偏移,网络会高估动作的真实回报,所以需要两个Q模型在训练过程中,目标值计算时取 **min(Q1, Q2),**可以尽量规避这类问题。Actor-Critic的设计没有变,策略模型是Actor,Q模型是Critic。
Q,A,V的关系如下

最后,也初始化了replaybuffer,上面已经解释过不赘述。
第二步,这里有两个核心概念,一个叫bootstrap,一个叫moving target。在监督学习里,比如人脸识别训练的时候,训练的标签是很明确的,过程就是让模型不断的去认张三这个名字和张三的照片,最终拟合出张三和张三的脸之间的潜在关系,这个关系以结构和参数形式存在模型里。
很合理对吧,但是在强化学习里,这个标签就很奇特了,倒立摆的案例中这一刻正确做法是往左控制,下一刻向右才合理,这个目标是变化的,没办法打这个标签,那好,我把这一系列的动作控制看成是针对这个倒立摆案例的一套实施策略(在这里能创造这个概念已经是牛鼻爆炸了),面对这个案例我可以提炼出一个很好的策略,这就是强化学习中"策略"的简单解读,但是即便如此,环境状态时时刻刻都在变,空气流动稍微变化一下倒立摆的控制动作就需要改变,你能穷举环境吗?显然不能,因此依然无法打标签,到此才发现原来强化学习是没办法预先知道标签是什么的,所以只能妥协,既然不知道终极目标,那就求最好(最优策略或者最大化回报)。这里说的有些主观,但却很好理解,也就是,强化学习案例和人脸识别这类案例比,它本质上是:在尝试之前是不可能知道答案的,所以没答案就没法打标签,因为它面对的是时刻变化的环境宇宙。
那么,bootstrap的意思就很明确了,既然没法打标签,那就不断的尝试直到回报不断升高收敛,这就是强化学习里的"标签",收敛了才知道它。所以每一步的更新方向就是高回报所指方向,训练过程就是猜着一步一步朝着高回报走,什么意思呢?我猜应该朝这边走会更好,所以这次更新就朝这边更新,再去探索回来继续猜,继续更新,周而复始,一直到把猜中的概率提升到一个水平线,也就训练完毕了。像下面公式一样,
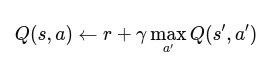
左右两边都有Q,左右两边都在猜,两个猜测的差值来为Q更新,下一轮继续,是不是非常的左脚踩右脚,这就是bootstrap。moving target就好理解了,每一步两边猜的都不一样,更新的目标值肯定也不一样,所以叫移动的靶。
而之所以这套神奇的理论能训练,最核心的就是它每一步都是有真实尝试的,也就是环境反馈,可以理解成碰壁,头破血流就逐渐学会了,每一步得到的r会不断的指引猜测越来越准。
为什么上一篇PPO的学习中没有这个神奇的情况,没有怪异的感觉,因为PPO里更多的是使用真实回报来进行更新,用当前策略跑一段轨迹,获取到数据后更新一次,然后再跑,而SAC这里是走一步猜一次,所以怪异的感觉会很强。
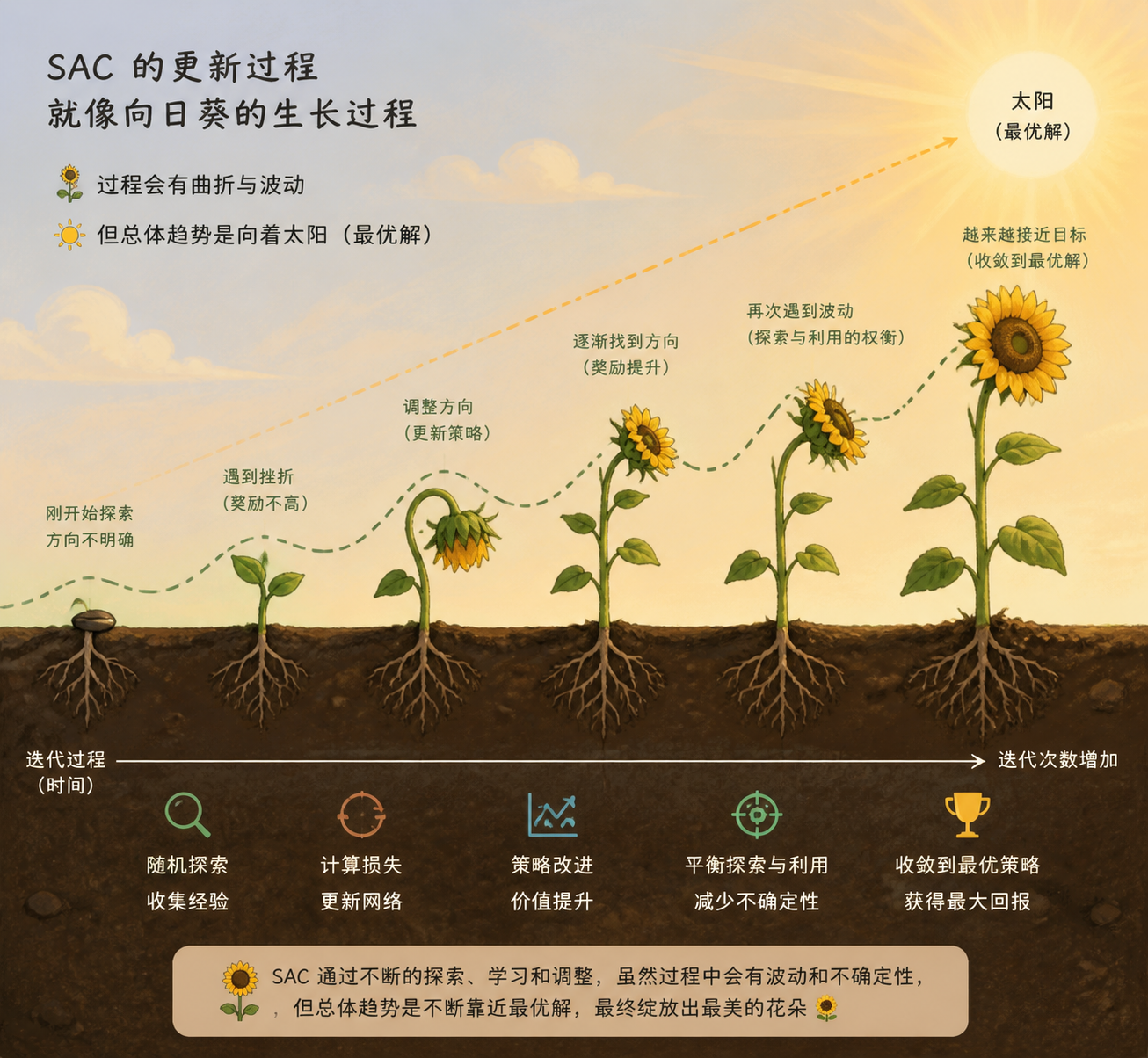
这里可以脑部一个画面,SAC的更新过程很像向日葵的生长,它一点一点的长,起初看不出来方向,一段时间以后看着总体的趋势会发现它是逐渐朝着太阳的方向长。
第二步,还是上面那个公式,在做的事情是又复制了两个模型作为Φ1和Φ2的预测目标,为了避免搞混,就只说Φ1target,Φ1target就是公式右边的Q模型,左边的是Φ1模型,也就是左脚踩右脚bootstrap刚才已经说过。这一步在初始化这个Φ1target,其实就是把Φ1复制到Φ1target。Φ1模型每一步都在更新,而Φ1target在SAC里每一步只朝着Φ1更新一点,对比其他如DQN算法是硬更新,就是隔N步直接把Φ1的参数拷贝给Φ1target,所以到这里可以明确一共有5个网络模型:策略π、Φ1和Φ2,Φ1target和Φ2target。
第三步,这里开始往下跟上一篇差不多,进入主循环。
第四步,从环境拿状态,给到策略模型预测输出动作
第五步,在环境里执行动作
第六步,获取最新的transition
第七步,transition存到replaybuffer里
第八步,这里开始又跟上一篇有所不同,判断这轮是不是结束了
第九步,判断要不要做更新
第十步,进入循环更新
第十一步,从replaybuffer里随机获取transition,注意这里就是on-policy和off-policy的核心体现,这里获取到的transition有可能不是当前策略的数据,即历史数据。
第十二步,这里就是在计算目标值,也就是更新的方向。
第十三步,有了目标值,再通过预测值算差距,然后朝着目标值更新Φ模型。
第十四步,通过Q预测动作好坏引导策略π模型更新
第十五步,通过polyak平均这个方式从φ模型缓慢更新φtarget模型
从第八步到结束和之前PPO有很多不同,先了解大致的步骤。
二 贴合代码实现,初始化阶段
还是一样的原则,对于不影响算法主体逻辑的部分就不说了。
首先初始化虚拟环境,test_env不重要不用管。
python
env, test_env = env_fn(), env_fn()
obs_dim = env.observation_space.shape
act_dim = env.action_space.shape[0]obs_dim和act_dim分别代表状态和动作空间,然后初始化actor_critic同时初始化3个基本模型:
python
ac = actor_critic(env.observation_space, env.action_space, **ac_kwargs)
python
class MLPActorCritic(nn.Module):
def __init__(self, observation_space, action_space, hidden_sizes=(256,256),
activation=nn.ReLU):
super().__init__()
obs_dim = observation_space.shape[0]
act_dim = action_space.shape[0]
act_limit = action_space.high[0]
# build policy and value functions
self.pi = SquashedGaussianMLPActor(obs_dim, act_dim, hidden_sizes, activation, act_limit)
self.q1 = MLPQFunction(obs_dim, act_dim, hidden_sizes, activation)
self.q2 = MLPQFunction(obs_dim, act_dim, hidden_sizes, activation)
def act(self, obs, deterministic=False):
with torch.no_grad():
a, _ = self.pi(obs, deterministic, False)
return a.numpy()init方法里面可以看到,定义了pi,q1和q2。其中,act_limit是取了连续动作的最大值,Pendulum环境里面对于动作的定义action ∈ -2, 2,这个值的作用是对网络的输出进行缩放,确保输出值是合法的,避免输出比如15或-37这样超出定义范围的动作值。
SquashedGaussianMLPActor代表pi策略网络,初始化代码如下:
python
def __init__(self, obs_dim, act_dim, hidden_sizes, activation, act_limit):
super().__init__()
self.net = mlp([obs_dim] + list(hidden_sizes), activation, activation)
self.mu_layer = nn.Linear(hidden_sizes[-1], act_dim)
self.log_std_layer = nn.Linear(hidden_sizes[-1], act_dim)
self.act_limit = act_limit网络net,输入的状态是3维,输出256维,两层全连接,激活用的relu(隐藏层常用)
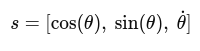 用 (cosθ, sinθ) 表示角度 + θ̇ 表示速度,共3维
用 (cosθ, sinθ) 表示角度 + θ̇ 表示速度,共3维
Sequential(
(0): Linear(in_features=3, out_features=256, bias=True)
(1): ReLU()
(2): Linear(in_features=256, out_features=256, bias=True)
(3): ReLU()
)
mu_layer层和log_std_layer层都一样是输入256维,输出1维
Linear(in_features=256, out_features=1, bias=True)
所以总体来看这个网络的结构如下
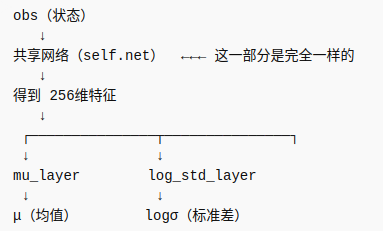
self.net被称为backbone,mu_layer和log_std_layer被称为head,head就代表具体任务的输出层,这里需要同时分别输出均值和标准差来代表输出的高斯分布,最终用于从中采样动作。
两个q网络就是两个MLP,可以看到这两个在初始化的时候一模一样。
actor_critic说得差不多了,继续看后面
python
ac_targ = deepcopy(ac)
# Freeze target networks with respect to optimizers (only update via polyak averaging)
for p in ac_targ.parameters():
p.requires_grad = False先复制一个和当前ac一模一样的对象,包括里面所有的网络结构和参数。
p.requires_grad = False这句的作用就是在后面进行更新的时候ac_targ里的模型不会更新,是一个简化的操作,否则要单独剥离出哪些更新哪些不更新没那么方便。而这个ac_targ里面的q1和q2就是前面提到过的目标Q(左边),用于引导右边的Q更新的。
下一句做了个统一q网络参数变量,作用就是可以对q1和q2两个网络的参数做统一操作
python
# List of parameters for both Q-networks (save this for convenience)
q_params = itertools.chain(ac.q1.parameters(), ac.q2.parameters())接下来就是初始化replaybuffer
python
# Experience buffer
replay_buffer = ReplayBuffer(obs_dim=obs_dim, act_dim=act_dim, size=replay_size)它的初始化init方法里,初始化的类内变量就是transition(状态s,动作a,奖励r,下一个状态s')
python
def __init__(self, obs_dim, act_dim, size):
self.obs_buf = np.zeros(core.combined_shape(size, obs_dim), dtype=np.float32)
self.obs2_buf = np.zeros(core.combined_shape(size, obs_dim), dtype=np.float32)
self.act_buf = np.zeros(core.combined_shape(size, act_dim), dtype=np.float32)
self.rew_buf = np.zeros(size, dtype=np.float32)
self.done_buf = np.zeros(size, dtype=np.float32)
self.ptr, self.size, self.max_size = 0, 0, size然后初始化优化器,注意这个q优化器传入的是q_optimizer,也就是到时候更新的时候是真对两个q网络的参数
python
# Set up optimizers for policy and q-function
pi_optimizer = Adam(ac.pi.parameters(), lr=lr)
q_optimizer = Adam(q_params, lr=lr)以上就是初始化的部分,而真正把训练跑起来就得看主循环了。
三 贴合代码实现,主循环训练阶段
python
# Main loop: collect experience in env and update/log each epoch
for t in range(total_steps):
# Until start_steps have elapsed, randomly sample actions
# from a uniform distribution for better exploration. Afterwards,
# use the learned policy.
if t > start_steps:
a = get_action(o)
else:
a = env.action_space.sample()
# Step the env
o2, r, d, _ = env.step(a)
ep_ret += r
ep_len += 1
# Ignore the "done" signal if it comes from hitting the time
# horizon (that is, when it's an artificial terminal signal
# that isn't based on the agent's state)
d = False if ep_len==max_ep_len else d
# Store experience to replay buffer
replay_buffer.store(o, a, r, o2, d)
# Super critical, easy to overlook step: make sure to update
# most recent observation!
o = o2
# End of trajectory handling
if d or (ep_len == max_ep_len):
logger.store(EpRet=ep_ret, EpLen=ep_len)
o, ep_ret, ep_len = env.reset(), 0, 0
# Update handling
if t >= update_after and t % update_every == 0:
for j in range(update_every):
batch = replay_buffer.sample_batch(batch_size)
update(data=batch)
# End of epoch handling
if (t+1) % steps_per_epoch == 0:
epoch = (t+1) // steps_per_epoch
# Save model
if (epoch % save_freq == 0) or (epoch == epochs):
logger.save_state({'env': env}, None)
# Test the performance of the deterministic version of the agent.
test_agent()
# Log info about epoch
logger.log_tabular('Epoch', epoch)
logger.log_tabular('EpRet', with_min_and_max=True)
logger.log_tabular('TestEpRet', with_min_and_max=True)
logger.log_tabular('EpLen', average_only=True)
logger.log_tabular('TestEpLen', average_only=True)
logger.log_tabular('TotalEnvInteracts', t)
logger.log_tabular('Q1Vals', with_min_and_max=True)
logger.log_tabular('Q2Vals', with_min_and_max=True)
logger.log_tabular('LogPi', with_min_and_max=True)
logger.log_tabular('LossPi', average_only=True)
logger.log_tabular('LossQ', average_only=True)
logger.log_tabular('Time', time.time()-start_time)
logger.dump_tabular()主循环的主干逻辑比较简单。
python
# Until start_steps have elapsed, randomly sample actions
# from a uniform distribution for better exploration. Afterwards,
# use the learned policy.
if t > start_steps:
a = get_action(o)
else:
a = env.action_space.sample()在最开始的时候,由于模型刚开始(其输出虽然也是随机,但更偏向于接近0的动作),所以需要加大探索度,使用环境的动作范围进行均匀采样以确保动作探索的范围。
然后执行动作后,将得到的transition存入replaybuffer里,再将状态更新为新状态为下一个循环做准备,这个就不过多介绍。
最后分别处理这一轮交互结束(重置环境和相关参数)、所有轮整体都交互结束(保存模型)以及着重需要理解的每一次更新处理:
python
# Update handling
if t >= update_after and t % update_every == 0:
for j in range(update_every):
batch = replay_buffer.sample_batch(batch_size)
update(data=batch)1)前 update_after (1000)步:
只收集经验,不更新模型。因为刚开始 replay buffer 很空,数据很少,如果模型马上训练,它会反复学习极少量、很偏的数据,容易把 Q 函数和策略带偏。
2)每隔 update_every(50)个环境步从replaybuffer中抽100个transition连续更新 update_every(50) 次:
环境走了 50 步然后模型更新 50 次,这里是在控制平衡环境收集数据的速度和模型学习数据的速度。如果更新太早数据太少,模型容易学偏;如果更新太少经验收集了很多,但模型没及时吸收,会产生要么旧经验还没吸收就被新的经验在buffer里面排掉了(因为buffer的容量毕竟是有限的),要么还没吸收完训练就结束了,就算强行增加总次数更会导致部分经验被再次选中的概率增加最终导致过拟合。但似乎前一篇PPO没有这个问题,是因为PPO是on-policy的,它的数据用完就丢。
接下来看update
python
def update(data):
# First run one gradient descent step for Q1 and Q2
q_optimizer.zero_grad()
loss_q, q_info = compute_loss_q(data)
loss_q.backward()
q_optimizer.step()
# Record things
logger.store(LossQ=loss_q.item(), **q_info)
# Freeze Q-networks so you don't waste computational effort
# computing gradients for them during the policy learning step.
for p in q_params:
p.requires_grad = False
# Next run one gradient descent step for pi.
pi_optimizer.zero_grad()
loss_pi, pi_info = compute_loss_pi(data)
loss_pi.backward()
pi_optimizer.step()
# Unfreeze Q-networks so you can optimize it at next DDPG step.
for p in q_params:
p.requires_grad = True
# Record things
logger.store(LossPi=loss_pi.item(), **pi_info)
# Finally, update target networks by polyak averaging.
with torch.no_grad():
for p, p_targ in zip(ac.parameters(), ac_targ.parameters()):
# NB: We use an in-place operations "mul_", "add_" to update target
# params, as opposed to "mul" and "add", which would make new tensors.
p_targ.data.mul_(polyak)
p_targ.data.add_((1 - polyak) * p.data)主体流程如下:
1)用TD误差计算两个Q 网络最终取小输出loss更新两个Q网络
2)冻结 Q 网络,因为马上要更新策略网络了
3)通过 Q 网络评价 pi网络,更新策略网络
4)解冻 Q 网络
5)用 Polyak averaging 更新 target 网络
这里需要注意:
首先为了避免梯度污染,在更新pi网络时需要冻结Q,而在计算Q的loss时,pi网络只提供动作并不参与其反向传播,所以不用冻结pi。
然后在最后更新target网络时,两个targetQ一个targetpi都是要一起跟随更新的(尽管如此,targetpi在整个算法里并没有其意义,可以忽略掉)。
流程基本清楚了,接下来重点看几个地方:
1)计算Q的损失
python
def compute_loss_q(data):
o, a, r, o2, d = data['obs'], data['act'], data['rew'], data['obs2'], data['done']
q1 = ac.q1(o,a)
q2 = ac.q2(o,a)
# Bellman backup for Q functions
with torch.no_grad():
# Target actions come from *current* policy
a2, logp_a2 = ac.pi(o2)
# Target Q-values
q1_pi_targ = ac_targ.q1(o2, a2)
q2_pi_targ = ac_targ.q2(o2, a2)
q_pi_targ = torch.min(q1_pi_targ, q2_pi_targ)
backup = r + gamma * (1 - d) * (q_pi_targ - alpha * logp_a2)
# MSE loss against Bellman backup
loss_q1 = ((q1 - backup)**2).mean()
loss_q2 = ((q2 - backup)**2).mean()
loss_q = loss_q1 + loss_q2
# Useful info for logging
q_info = dict(Q1Vals=q1.detach().numpy(),
Q2Vals=q2.detach().numpy())
return loss_q, q_info对应下面图中12到13步
q1和q2先直接通过模型预测,通过target模型预测再加上奖励作为TD误差计算出y(对应第12步),最后计算出TD loss(对应第13步),其中logp_a2代表熵,也就是随机性,这也是SAC的一个特色,它希望的是在最大化奖励的同时保住一定的探索度。似乎也没啥可说的了,对照着算法的图片和代码的图片挨个去对照理解会有更深的感悟。
2)计算pi的损失
python
# Set up function for computing SAC pi loss
def compute_loss_pi(data):
o = data['obs']
pi, logp_pi = ac.pi(o)
q1_pi = ac.q1(o, pi)
q2_pi = ac.q2(o, pi)
q_pi = torch.min(q1_pi, q2_pi)
# Entropy-regularized policy loss
loss_pi = (alpha * logp_pi - q_pi).mean()
# Useful info for logging
pi_info = dict(LogPi=logp_pi.detach().numpy())
return loss_pi, pi_info注意,pi的更新是on-policy的,从pi, logp_pi = ac.pi(o)这句代码就可以看出,动作必须从当前策略(理解成这轮还没有更新的策略)预测出来,用 pi 命名是为了表示它是由当前策略 π 采样得到的动作,并和数据中的动作 a 区分开。
python
# Entropy-regularized policy loss
loss_pi = (alpha * logp_pi - q_pi).mean()之前没有提到,其实这里是SAC的核心,一般看策略好不好就是看Q,因为它代表的是动作的价值,但是这里除了Q还加了一坨alpha * logp_pi,如果没有这一坨就特别好理解,谁的价值高我不断的朝它更新,但问题就是万一这个价值高存在误判呢,那就会不断朝向这个误差靠近,导致崩溃。SAC的策略就是不要太急着下判断。
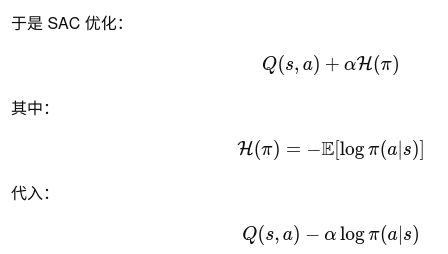
这里是有点绕的,尤其是logp越靠近0代表越确定,加上负号和优化目标是minloss,所以直接看结论,logp代表探索度,q代表收益,通过alpha超参数来权衡是更看重探索还是更看重收益。如果要更深入,就需要用具体数值代入公式来看它如何实现不确定性影响loss的。
3)更随更新的部分不细说,因为理解起来最简单,就是我原本是可以在更新结束后将ac模型全复制给ac_target,而SAC这里只是通过加个系数,让拷贝的数据只有一丁点,这个例子的polyak是0.995,所以它只拷贝了0.005的数据到target,那么就是一次只拷贝一点,它在跟着ac模型走,但都只是跟随,不会马上抵达目的地,直到ac收敛了,target才慢慢收敛。
四 回顾
如果熟悉了PPO的代码再看SAC,至少实现套路已经熟悉了,流程也无须仔细研究,反而应当多关注一些差别,比如on-policy和off-policy在代码里面的差别处处都在体现,在实现结构上也一样,SAC可以更多的使用隔100步,前10000次等条件用于加大探索度,而在PPO上我们并没有看到,这就是replaybuffer这样的设计机制导致的。另外左脚踩右脚更新也会体会更深,这也是如TD和蒙特卡洛等基本的设计思路的差异导致,理解起来有时候很反人类,有时候又很通畅。