
目录
[一. 大模型接入](#一. 大模型接入)
[ChatMemory (会话记忆)](#ChatMemory (会话记忆))
[二. 结构化输出](#二. 结构化输出)
本期我们来学习Spring AI这个框架的相关技术和知识点(注意AI技术迭代的很快,当前版本可能很快就会进行迭代,具体请结合官方文档进行学习)
一. 大模型接入
AI大模型就是指具有大规模参数的深度学习模型,通过对大规模数据的训练,能够展现出强大的推理能力和创作能力的模型,大模型的强大之处在于随着模型参数量和训练数据量的增加,模型会展现出训练过程中未明确赋予的新能力。
国内的大模型有:文心一言、通义千问、豆包、星火、deepseek等
国外的大模型有:GPT-4o、Claude 3系列、Gemini、Llama等

大模型应用的开发流程:
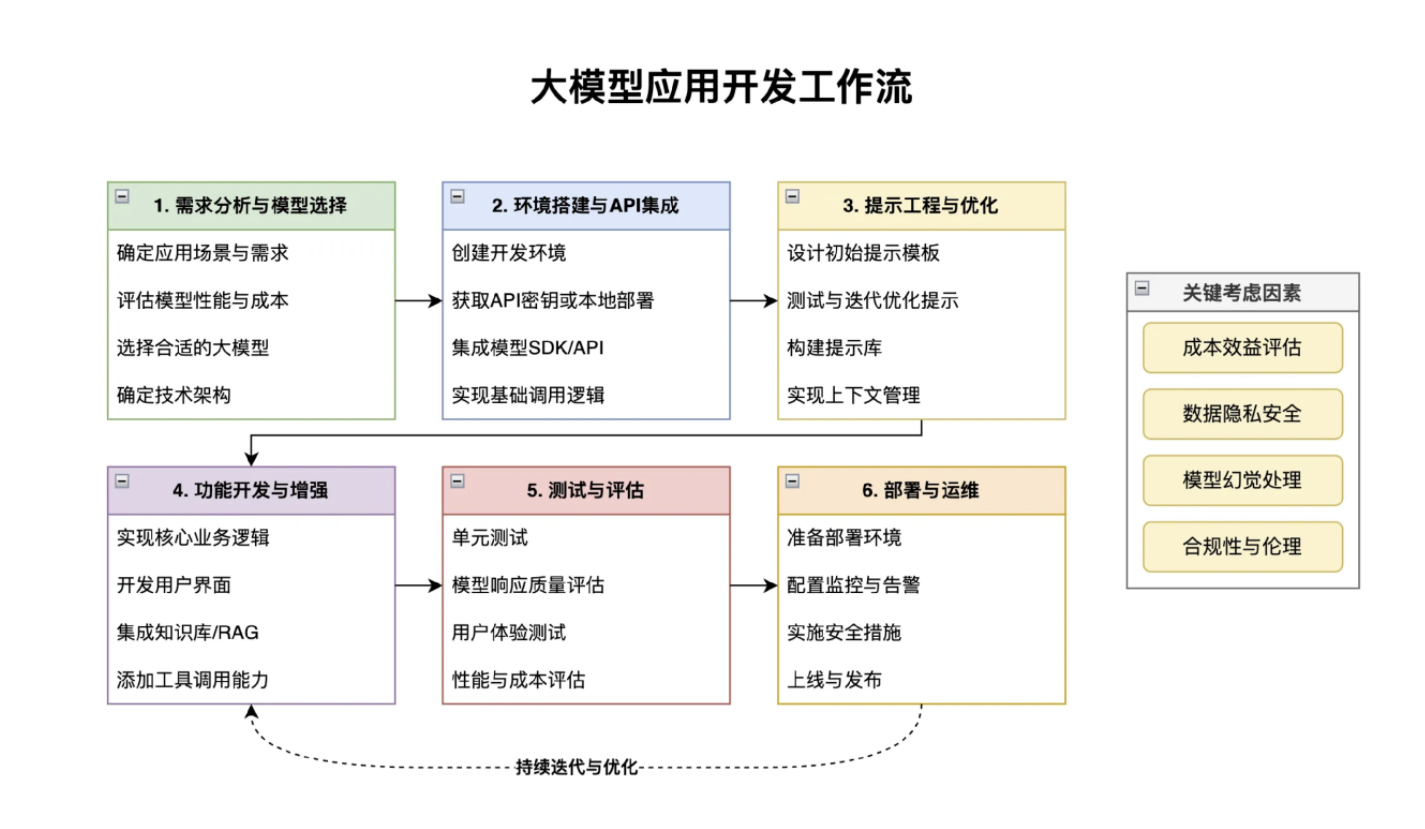
通过程序接入大模型
直接调用AI大模型,比如调用qwen-plus,这种方式可以使用特定平台提供的SDK和API来接入,也可以使用AI开发框架来接入,比如使用SpringIAi、Spring AI Alibaba、LangChain4j等自主选择大模型调用,通过框架来实现可以灵活切换使用的大模型
Spring、SpringAI、SpringAlibab依赖选择:
在这里我选择使用最新的版本(与时俱进):
<properties>
<java.version>17</java.version>
<!-- 定义关键 BOM 版本,实现统一管理 -->
<spring-boot.version>3.5.8</spring-boot.version>
<spring-ai.version>1.1.2</spring-ai.version>
<spring-ai-alibaba.version>1.1.2.0</spring-ai-alibaba.version>
</properties>
<dependencyManagement>
<dependencies>
<!-- Spring Boot BOM,统一管理 Spring Boot 核心依赖版本 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- Spring AI BOM,统一管理 Spring AI 核心依赖版本 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- Spring AI Alibaba BOM,统一管理 Alibaba 扩展依赖版本 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>${spring-ai-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- Spring AI Alibaba Extensions BOM,管理 DashScope 模型、MCP 等扩展版本 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-extensions-bom</artifactId>
<version>${spring-ai-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Spring AI Alibaba Agent Framework 核心依赖 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-agent-framework</artifactId>
</dependency>
<!-- Spring AI Alibaba DashScope Starter,提供与通义千问模型集成 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.36</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.37</version>
</dependency>
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>4.4.0</version>
</dependency>
</dependencies>application.yml配置:
spring:
application:
name: spring-ai-agent
ai:
dashscope:
api-key: {你自己的AI-api-key}
chat:
options:
model: qwen-plus
server:
port: 8123
servlet:
context-path: /api
springdoc:
swagger-ui:
path: /swagger-ui.html
tags-sorter: alpha
operations-sorter: alpha
api-docs:
path: /v3/api-docs
group-configs:
- group: 'default'
paths-to-match: '/**'
packages-to-scan: com.sunny.springaiagent.controller
knife4j:
enable: true
setting:
language: zh_cnChatClient和Chatmodel的关系
ChatModel:代表底层的聊天模型(如 OpenAI 的 GPT-4、Anthropic 的 Claude 等)。它封装了模型的具体调用逻辑、参数配置(温度、最大 token 等)以及原始的请求/响应格式。你可以把它看作"模型接口"。
ChatClient:是更高层的客户端工具,用于简化与 ChatModel 的交互。它通常提供更友好的 API(如链式调用、消息历史管理、工具调用等),并封装了会话上下文、重试、日志等通用功能。你可以把它看作"模型使用助手"。
ChatClient依赖ChatModel,需要注入一个具体的模型实例才能工作。
ChatClient对ChatModel进行封装和增强,让开发者不必直接处理底层模型细节。典型调用链:
ChatClient接收用户消息 → 构建请求 → 调用ChatModel→ 返回格式化响应。简单类比:
ChatModel是"发动机",ChatClient是"汽车",汽车依赖发动机并提供更完整的驾驶体验。
接下来我们先来构建一个LoveAPP类:

在这个类中我们来构建一个ChatClient-ai客户端:
package com.sunny.springaiagent.app;
import com.sunny.springaiagent.advisor.MyLoggerAdvisor;
import jakarta.annotation.Resource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.chat.client.advisor.vectorstore.QuestionAnswerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
import java.util.List;
@Component
@Slf4j
public class LoveAPP {
//初始化ai客户端
private final ChatClient chatClient;
//构建prompt
private static final String SYSTEM_PROMPT = "扮演深耕恋爱心理领域的专家。开场向用户表明身份,告知用户可倾诉恋爱难题。" +
"围绕单身、恋爱、已婚三种状态提问:单身状态询问社交圈拓展及追求心仪对象的困扰;" +
"恋爱状态询问沟通、习惯差异引发的矛盾;已婚状态询问家庭责任与亲属关系处理的问题。" +
"引导用户详述事情经过、对方反应及自身想法,以便给出专属解决方案。";
// 从chatmemory配置类中获得bean
public LoveAPP(ChatModel dashscopeChatModel,@Qualifier("chatFileMemory") ChatMemory chatFileMemory) {
// 3. 用Builder模式创建MessageChatMemoryAdvisor(拦截器,唯一正确方式)
MessageChatMemoryAdvisor advisor = MessageChatMemoryAdvisor.builder(chatFileMemory)
.build();
chatClient =ChatClient.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT)
.defaultAdvisors(advisor)
.build();
}
}在上面代码中有很多名词接下来来解释一下这些名词:
prompt(提示词)
Prompt 是用户发给聊天模型的输入文本(通常包含指令、上下文、示例等),模型根据它生成回复。在代码中定义的SYSTEM_PROMPT 这是我们自己定义的系统提示词,当用户调用AI大模型时,
SYSTEM_PROMPT会随着用户的提示词一起传给 AI。此时AI就会知道自己的设定是什么,从而给出更加精确的回答ChatMemory (会话记忆)
ChatMemory 是用于管理对话历史的组件。它让 AI 能够"记住"用户之前说过的话,从而实现多轮连续对话。
核心作用
保存消息记录:存储每个会话(session)中用户和 AI 之间的所有消息。
提供历史上下文:当用户发送新消息时,ChatMemory 会取出该会话之前的若干条消息,连同新消息一起发给 AI,让 AI 理解上下文。
自动管理窗口:可以限制保留的消息数量(如最近 20 条),防止 token 超限。
管理对话记忆的行为 :如何添加消息、如何获取历史、如何清理(例如滑动窗口策略、保留系统消息等)。简单来说就是一个记忆管理器(决定"记什么、忘什么、怎么整理")
在上述代码中@Qualifier("chatFileMemory") ChatMemory chatFileMemory,就是我们自己自定义配置的一个记忆管理器
ChatMemoryConfig实现:package com.sunny.springaiagent.config;
import com.sunny.springaiagent.chatmemory.FileBasedChatMemory;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.InMemoryChatMemoryRepository;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ChatMemoryConfig {
/**
* 存储到文件中的chatmemory
* @return
*/
@Bean
public ChatMemory chatFileMemory() {
// 在这里集中配置你需要的所有参数
return MessageWindowChatMemory.builder()
.chatMemoryRepository(new FileBasedChatMemory("D:/super-agent/spring-ai-agent/chat-memory")) // 存储介质
.maxMessages(20) // 消息窗口大小
.build();
}
}
MessageWindowChatMemory(记忆管理)
MessageWindowChatMemory是 Spring AI 框架中默认的、基于固定大小滑动窗口 策略的记忆管理实现。(个人理解为时某种管理算法的实现,通过这个算法来管理会话存储)在上述代码中MessageWindowChatMemory.builder(),我们就是要定义出一个这样的算法
ChatMemoryRepository(仓库管理员)ChatMemoryRepository是 Spring AI 框架中的一个接口,它定义了最底层的存储操作,专注于处理消息的持久化(增、删、改、查)。它就像一个专注于存取的"仓库管理员",也就是将会话存放在哪里,怎么存,怎么查等操作都是由它来决定的
chatMemoryRepository(new FileBasedChatMemory("D:/super-agent/spring-ai-agent/chat-memory")) 上面的这串代码中FileBasedChatMemory就是我们自定义的chatMemoryRepository,在里面去实现和定义我们想要将会话存放的位置和增加新会话的规则和取会话的规则
ChatMemoryRepository实现:

package com.sunny.springaiagent.chatmemory;
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
import org.objenesis.strategy.StdInstantiatorStrategy;
import org.springframework.ai.chat.memory.ChatMemoryRepository;
import org.springframework.ai.chat.messages.Message;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
/**
* 基于文件持久化的对话记忆存储库
*
* <p>实现 Spring AI 官方的 ChatMemoryRepository 接口,将对话历史持久化到本地文件系统中。
* 使用 Kryo 序列化框架进行对象序列化,支持任意 Java 对象的存储。</p>
*
* <p><b>核心功能:</b></p>
* <ul>
* <li>保存对话历史到 .kryo 文件</li>
* <li>根据会话ID读取完整对话历史</li>
* <li>查询所有已存储的会话ID列表</li>
* <li>删除指定会话的对话记录</li>
* </ul>
*
* <p><b>工作流程说明:</b></p>
* <ol>
* <li>框架在每次对话前调用 {@link #findByConversationId(String)} 读取历史消息</li>
* <li>框架自动合并历史消息和新消息,并根据窗口大小(maxMessages)进行裁剪</li>
* <li>框架在对话结束后调用 {@link #saveAll(String, List)} 保存裁剪后的完整消息列表</li>
* <li>本类只需负责文件的读写操作,不需要关心消息合并和裁剪逻辑</li>
* </ol>
*
* <p><b>存储格式:</b></p>
* <ul>
* <li>文件命名规则:{conversationId}.kryo</li>
* <li>存储位置:构造函数指定的 baseDir 目录</li>
* <li>序列化方式:Kryo(高性能二进制序列化)</li>
* </ul>
*
* @author Sunny
* @version 1.0
* @see org.springframework.ai.chat.memory.ChatMemoryRepository
* @see org.springframework.ai.chat.memory.MessageWindowChatMemory
*/
public class FileBasedChatMemory implements ChatMemoryRepository {
/** 聊天记录存储的根目录路径 */
private final String BASE_DIR;
/**
* Kryo 序列化工具(线程安全版本)
*
* <p>使用 ThreadLocal 确保每个线程都有自己的 Kryo 实例,避免多线程并发问题。
* Kryo 不是线程安全的,因此需要这样做。</p>
*
* <p><b>配置说明:</b></p>
* <ul>
* <li>{@code setRegistrationRequired(false)}:不需要预先注册类,使用更灵活但性能略低</li>
* <li>{@code setInstantiatorStrategy(new StdInstantiatorStrategy())}:支持实例化没有无参构造函数的类</li>
* </ul>
*/
private static final ThreadLocal<Kryo> KRYO_LOCAL = ThreadLocal.withInitial(() -> {
Kryo kryo = new Kryo();
kryo.setRegistrationRequired(false); // 不强制要求注册类,提高灵活性
kryo.setInstantiatorStrategy(new StdInstantiatorStrategy()); // 支持无参构造函数的类实例化
return kryo;
});
/**
* 构造方法:初始化文件存储目录
*
* <p>如果指定的目录不存在,会自动创建(包括必要的父目录)。</p>
*
* @param baseDir 存储根路径(例如:D:/chat-memory/ 或 ./data/conversations/)
*/
public FileBasedChatMemory(String baseDir) {
this.BASE_DIR = baseDir;
File directory = new File(baseDir);
if (!directory.exists()) {
directory.mkdirs(); // 创建目录(包括不存在的父目录)
}
}
/**
* 获取所有已存储的会话ID列表
*
* <p>通过扫描存储目录下所有 .kryo 文件,提取文件名(不含扩展名)作为会话ID。</p>
*
* @return 所有会话ID的列表,如果没有找到任何会话则返回空列表(不会返回null)
*/
@Override
public List<String> findConversationIds() {
File dir = new File(BASE_DIR);
File[] files = dir.listFiles();
if (files == null) {
return new ArrayList<>(); // 目录不存在或无法读取时返回空列表
}
return Arrays.stream(files)
.filter(file -> file.isFile() && file.getName().endsWith(".kryo")) // 只处理 .kryo 文件
.map(file -> file.getName().replace(".kryo", "")) // 去掉扩展名得到会话ID
.collect(Collectors.toList());
}
/**
* 根据会话ID读取完整的聊天历史
*
* <p><b>重要说明:</b></p>
* <ul>
* <li>如果文件不存在,返回空列表(不会创建文件)</li>
* <li>返回的消息列表顺序是从旧到新的时间顺序</li>
* <li>框架会自动处理这个列表的合并和裁剪</li>
* </ul>
*
* @param conversationId 会话唯一标识符
* @return 该会话的消息列表(从旧到新),如果会话不存在则返回空列表
*/
@Override
public List<Message> findByConversationId(String conversationId) {
File file = getConversationFile(conversationId);
// 文件不存在时直接返回空列表,不创建文件
if (!file.exists()) {
return new ArrayList<>();
}
// 反序列化:从文件中读取消息列表
try (Input input = new Input(new FileInputStream(file))) {
return KRYO_LOCAL.get().readObject(input, ArrayList.class);
} catch (Exception e) {
e.printStackTrace();
return new ArrayList<>(); // 读取失败时返回空列表
}
}
/**
* 保存指定会话的所有消息(覆盖写入)
*
* <p><b>⚠️ 重要:这是覆盖写入,不是追加!</b></p>
*
* <p><b>调用时机:</b></p>
* <ol>
* <li>框架会先通过 {@link #findByConversationId(String)} 读取旧消息</li>
* <li>框架自动合并旧消息和新消息</li>
* <li>框架根据 maxMessages 窗口大小进行裁剪(保留最近的 N 条)</li>
* <li>框架将裁剪后的<b>完整消息列表</b>传入此方法</li>
* </ol>
*
* <p><b>实现要求:</b></p>
* <ul>
* <li>必须覆盖写入,不要尝试读取旧文件或进行合并</li>
* <li>传入的 messages 参数已经是最终需要保存的完整数据</li>
* <li>文件不存在时会自动创建</li>
* </ul>
*
* @param conversationId 会话唯一标识符
* @param messages 需要保存的完整消息列表(框架已处理好合并和裁剪)
*/
@Override
public void saveAll(String conversationId, List<Message> messages) {
File file = getConversationFile(conversationId);
// 覆盖写入:将完整的消息列表序列化到文件
try (Output output = new Output(new FileOutputStream(file))) {
KRYO_LOCAL.get().writeObject(output, messages);
} catch (IOException e) {
e.printStackTrace(); // 生产环境建议使用日志框架记录
}
}
/**
* 删除指定会话的所有对话记录
*
* <p>如果文件存在则删除,不存在则不做任何操作。</p>
*
* @param conversationId 会话唯一标识符
*/
@Override
public void deleteByConversationId(String conversationId) {
File file = getConversationFile(conversationId);
if (file.exists()) {
file.delete(); // 永久删除文件
}
}
/**
* 根据会话ID获取对应的文件对象
*
* <p><b>注意:</b>此方法只是构建 File 对象,不会在磁盘上创建实际文件。</p>
*
* @param conversationId 会话唯一标识符
* @return 指向 {BASE_DIR}/{conversationId}.kryo 的文件对象
*/
private File getConversationFile(String conversationId) {
return new File(BASE_DIR, conversationId + ".kryo");
}
}回到ChatMemoryConfig这里:
maxMessages(20) // 消息窗口大小这里其实就是定义我们存储窗口的大小,就是我们存储介质中最多能存多少条会话,比如说我有一个default.kryo文件,这是我存放会话的文件,此时里面有20条历史会话,但是我现在调用ai产生的新的10条对话,那么此时就不会记录历史对话的前10条,而只会记录历史对话的后10条和新的10条对话,在我当前用的spring AI Alibaba版本中,调用ai取出历史会话也是通过这个参数,这里定义的20,意味着我取也只会取出20条历史会话作为上下文实现会话记忆
此时我们将chatFileMemory交给Spring管理,回到LoveAPP中:
MessageChatMemoryAdvisor又是什么东西呢?首先我们要先了解AdvisorAdvisor 是 Spring AI 框架中的一个核心概念,它借鉴了 Spring AOP(面向切面编程)中的 "通知/增强器" 思想,用于在
ChatClient调用 AI 模型之前和之后,插入额外的处理逻辑,而无需修改核心的对话流程。简单理解:Advisor 就像是一个"拦截器"或"中间件",让你能够在发送 prompt 给 AI 之前做一些事情,在收到 AI 回复之后再做另一些事情
MessageChatMemoryAdvisor可以理解为 Spring AI 里的一个 "记忆秘书" ,它的核心职责就是在ChatClient与 AI 模型交互的过程中,自动管理对话历史,让 AI 能记住聊天的上下文。通过我们刚才构建的chatFileMemory作为参数实现MessageChatMemoryAdvisor,那么这个"记忆秘书 "就会根据我chatFileMemory中配置的策略来做一些事情,比如说我调用ai时,那么此时我的
MessageChatMemoryAdvisor就会根据 chatFileMemory中配置的策略来进行处理,那么我之前实现的 FileBasedChatMemory,记忆秘书就会从我指定的文件中寻找历史会话,然后结合用户当前的提示词,一并传给ai,这样ai就能通过历史会话,知道历史会话记录,从而实现和用户对话拥有记忆的功能
那么此时MessageChatMemoryAdvisor也构建好了之后:
public LoveAPP(ChatModel dashscopeChatModel,@Qualifier("chatFileMemory") ChatMemory chatFileMemory) {
// 3. 用Builder模式创建MessageChatMemoryAdvisor(拦截器,唯一正确方式)
MessageChatMemoryAdvisor advisor = MessageChatMemoryAdvisor.builder(chatFileMemory)
.build();
chatClient =ChatClient.builder(dashscopeChatModel)
.defaultSystem(SYSTEM_PROMPT) //系统提示词
.defaultAdvisors(advisor) //会话记忆拦截器
.build();
}chatClient就能够构建出来了,接着来实现一个AI基础对话(支持多轮对话记忆)
/**
* 实现AI基础对话(支持多轮对话记忆)
* @param message
* @param chatId
* @return
*/
public String doChat (String message ,String chatId){
ChatResponse message1 = chatClient
.prompt()// 构建一次提问
.system(SYSTEM_PROMPT)//系统提示词
.user(message)// 用户输入的问题
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
.call()
.chatResponse();
String content = message1.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))这是实现对话记忆的关键:doChat 方法
│
├─ .advisors(spec -> spec.param(CONVERSATION_ID, chatId)) // ① 设置参数
│
└─ chatClient.call()
│
▼
MessageChatMemoryAdvisor(在调用前执行)
│
├─ 从请求中取出参数 CONVERSATION_ID 的值(即 chatId) // ② 获取会话ID
│
└─ 调用内部的 ChatMemory(例如 MessageWindowChatMemory)
│
├─ ChatMemory 内部持有 ChatMemoryRepository(你的 FileBasedChatMemory) // ③ 注入
│
└─ ChatMemory 调用 repository.findByConversationId(chatId) // ④ 读取历史
└─ 最后调用 repository.saveAll(chatId, newMessages) // ⑤ 保存新消息

构建一个测试案例:
@Test
void test() {
String chatID= UUID.randomUUID().toString();
//第一轮对话
String message1="你好,我是晴曛";
String ans1=loveAPP.doChat(message1,chatID);
//第二轮对话
String message2="我想让我的另一半(小猫)更爱我,我应该怎么做,我和她都是大学生";
String ans2=loveAPP.doChat(message2,chatID);
Assertions.assertNotNull(ans2);
//第三轮对话
String message3="我的另一半叫什么来着,我刚才好像和你说过";
String ans3=loveAPP.doChat(message3,chatID);
Assertions.assertNotNull(ans3);
}运行结果:
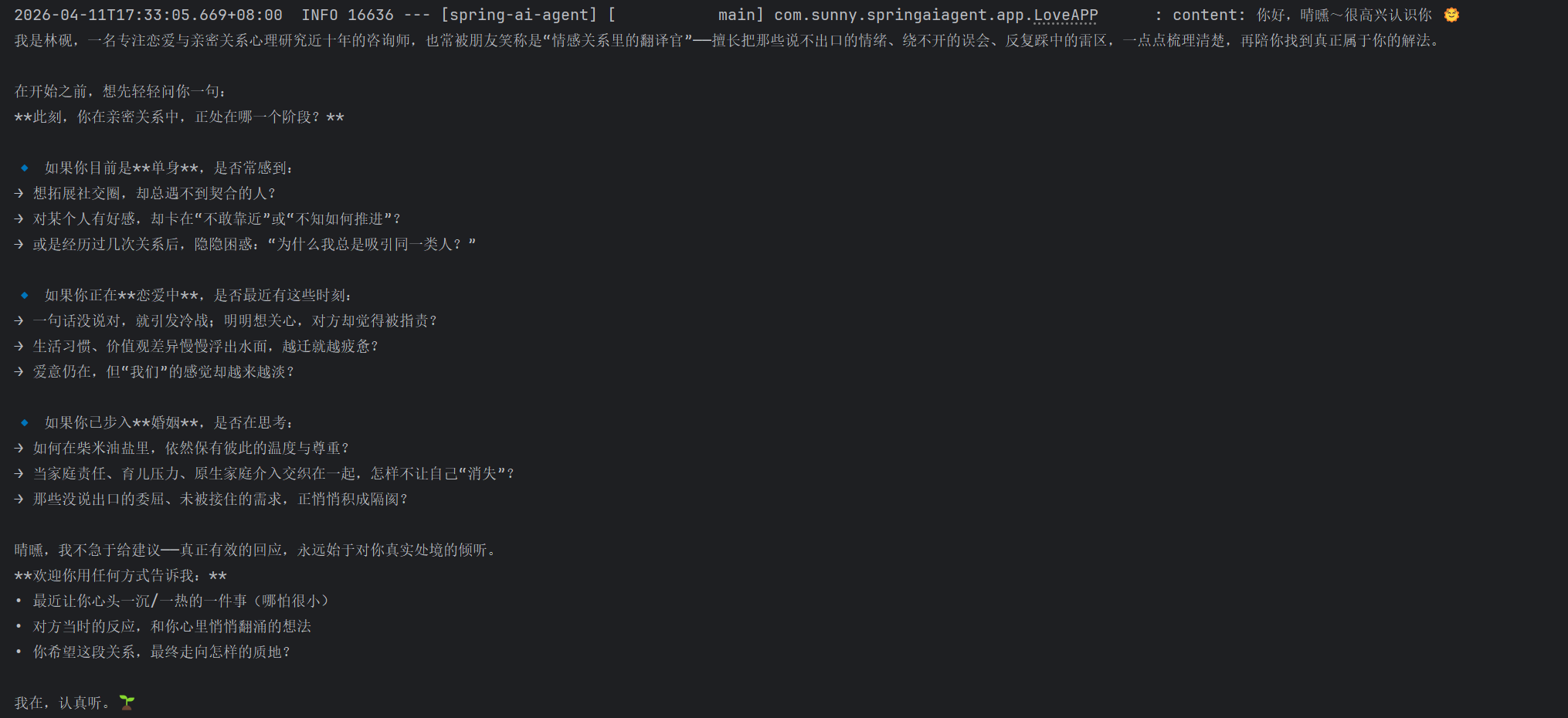
二. 结构化输出
结构化转换器是Spring AI 提供的一种实现机制,将大语言模型返回的文本输出转换为结构化数据格式、如JSON、XML或是java类等
基本原理---工作流程
调用前:转换器会在提示词后面附加上格式指定,明确告诉模型应该生成哪种结构的输出,引导模型生成符合指定格式的响应。
调用后:转换器会将模型的文本输出转换为结构化类型的实例,比如将原始文本映射为JSON等特定的数据结构
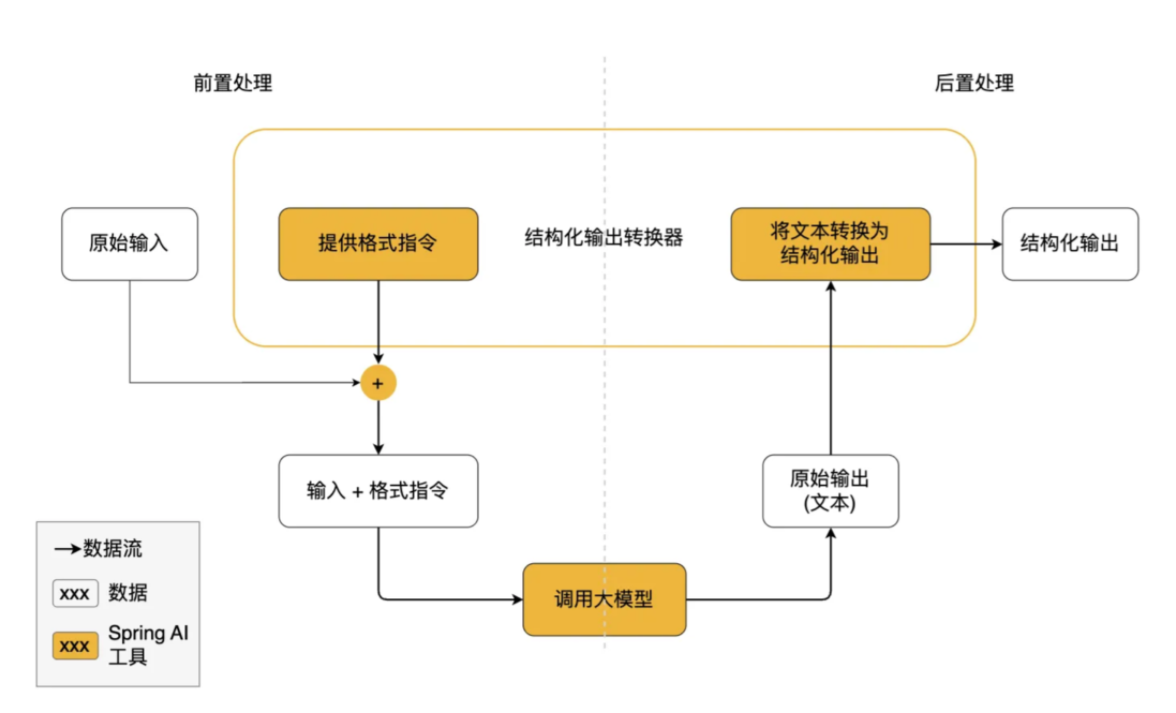
注意:结构化转换器只能尽最大努力将模型输出转化为结构化数据,AI模型不保证一定按照要求返回结构化输出
使用示例:官方文档中提供了很多转换示例
1.BeanOutPutConverter示例,将AI输出转换为自定义的Java类:
// 定义一个记录类
record ActorsFilms(String actor, List<String> movies) {}
// 使用高级 ChatClient API
ActorsFilms actorsFilms = ChatClient.create(chatModel).prompt()
.user("Generate 5 movies for Tom Hanks.")
.call()
.entity(ActorsFilms.class); ----》这是转换的重点方法还可以转换为对象列表:
// 可以转换为对象列表
List<ActorsFilms> actorsFilms = ChatClient.create(chatModel).prompt()
.user("Generate the filmography of 5 movies for Tom Hanks and Bill Murray.")
.call()
.entity(new ParameterizedTypeReference<List<ActorsFilms>>() {});2.MapOutputConverter示例,将模型输出转换为包含数字列表的Map
Map<String, Object> result = ChatClient.create(chatModel).prompt()
.user(u -> u.text("Provide me a List of {subject}")
.param("subject", "an array of numbers from 1 to 9 under they key name 'numbers'"))
.call()
.entity(new ParameterizedTypeReference<Map<String, Object>>() {});-
ListOutputConverter示例,将模型输出转换为字符串列表:
List
flavors = ChatClient.create(chatModel).prompt()
.user(u -> u.text("List five {subject}")
.param("subject", "ice cream flavors"))
.call()
.entity(new ListOutputConverter(new DefaultConversionService()));
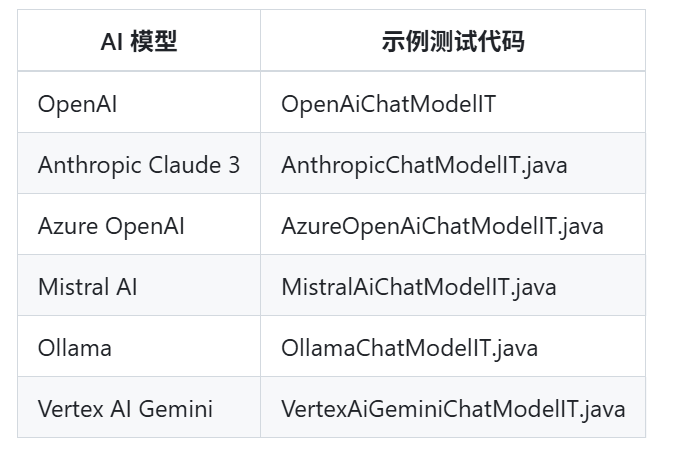
以下AI模型经过测试,支持这几个结构化输出:
接下来我们来实现一个结构化输出方法
引入依赖:
// JSON Schema 生成依赖
<dependency>
<groupId>com.github.victools</groupId>
<artifactId>jsonschema-generator</artifactId>
<version>4.38.0</version>
</dependency>在LoveApp中编写方法:
// // 生成报告用的专属SYSTEM_PROMPT(强制JSON)
private static final String REPORT_PROMPT = "你是恋爱心理专家,根据用户的恋爱问题,生成一份结构化的恋爱报告。";
//快速定义临时类
record LoveReport(String title, List<String> suggestions) {
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("LoveReport{\n");
sb.append(" title: ").append(title).append("\n");
sb.append(" suggestions:\n");
for (int i = 0; i < suggestions.size(); i++) {
sb.append(" ").append(i + 1).append(". ").append(suggestions.get(i)).append("\n");
}
sb.append("}");
return sb.toString();
}
}
/**
* 实现AI基础对话(结构化输出)
* @param message
* @param chatId
* @return
*/
public LoveReport doChatWithReport(String message, String chatId) {
LoveReport loveReport = chatClient
.prompt()
.system(REPORT_PROMPT)
.user(message)
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
.call()
.entity(LoveReport.class);
log.info("loveReport: {}", loveReport);
return loveReport;
}测试代码:
@Test
void doChatWithReport() {
String chatId = UUID.randomUUID().toString();
// 第一轮
String message = "你好,我是晴曛,我想让另一半(小猫)更爱我,但我不知道该怎么做";
LoveAPP.LoveReport loveReport = loveAPP.doChatWithReport(message, chatId);
Assertions.assertNotNull(loveReport);
}运行结果:

通过运行结果就会发现,生成的结果就转换成我们上面定义的loveReport类中的结构了分为:title和suggestions,这就实现了结构化输出的功能了,以上我们就实现了一个有记忆并且能够结构化输出的恋爱咨询机器人了
