文章目录
- [1. 概述](#1. 概述)
- [2. 核心组件](#2. 核心组件)
-
- [2.1 InterruptionMetadata](#2.1 InterruptionMetadata)
- [2.2 MainGraphExecutor](#2.2 MainGraphExecutor)
- [2.3 GraphRunnerContext](#2.3 GraphRunnerContext)
- [2.4 NodeExecutor](#2.4 NodeExecutor)
- [2.5 InterruptableAction](#2.5 InterruptableAction)
- [2.6 Hook](#2.6 Hook)
-
- [2.6.1 InterruptionHook](#2.6.1 InterruptionHook)
- [2.6.2 HumanInTheLoopHook](#2.6.2 HumanInTheLoopHook)
- [3. IinterruptableAction 模式(节点动态中断)](#3. IinterruptableAction 模式(节点动态中断))
-
- [3.1 中断判断逻辑](#3.1 中断判断逻辑)
-
- [3.1.1 interrupt()](#3.1.1 interrupt())
- [3.1.2 interruptAfter()](#3.1.2 interruptAfter())
- [3.2 构建中断元数据](#3.2 构建中断元数据)
- [3.3 返回中断响应](#3.3 返回中断响应)
- [3.4 初始化执行上下文](#3.4 初始化执行上下文)
- [3.5 合并状态(BUG)](#3.5 合并状态(BUG))
- [3.6 STATE_UPDATE 合并状态](#3.6 STATE_UPDATE 合并状态)
- [3.7 执行结束](#3.7 执行结束)
1. 概述
中断机制允许图执行在特定节点暂停,等待外部输入(如人工审批、用户反馈)后恢复执行。
核心流程:
- 判断是否需要中断
- 需要中断时,会构建
InterruptionMetadata并响应 - 恢复执行时,构建【恢复模式】的执行上下文
- 合并初始状态与检查点保存的状态
- 继续执行直到完成
2. 核心组件
2.1 InterruptionMetadata
【中断元数据】继承 NodeOutput,记录图执行过程中的中断信息 和工具审批状态。
核心职责:
- 中断记录:记录图在哪个节点中断
- 工具审批:记录需要人工审批的工具调用及审批结果
- 状态保存:保存中断时的图状态
- 元数据携带:支持携带自定义元数据
典型使用场景:
- 工具审批 :
AI想要执行敏感工具时,等待人工审批 - 人工审核 :
AI生成内容后,等待人工审核 - 交互式输入:需要用户补充信息时中断等待
java
// InterruptionMetadata.java
public final class InterruptionMetadata extends NodeOutput implements HasMetadata<Builder> {
private final Map<String, Object> metadata; // 自定义元数据
private List<AssistantMessage.ToolCall> toolsAutomaticallyApproved; // 自动批准的工具
private List<ToolFeedback> toolFeedbacks; // 工具审批反馈
// 内置字段
// - nodeId: 中断发生的节点ID
// - state: 中断时的状态快照
}2.2 MainGraphExecutor
MainGraphExecutor 是 流程引擎的核心主执行器 ,继承自 BaseGraphExecutor 基础执行器,是实现流程图全生命周期调度、节点执行、中断管控、断点续跑的核心组件。
实现中断功能相关:
- 中断机制核心支撑 : 集成流程中断判断逻辑,触发中断时构建并返回
InterruptionMetadata中断元数据,实现流程暂停、状态快照保存,为人在回路(HITL)提供底层执行支持。 - 断点续跑与动态路由 :处理中断恢复逻辑,适配
interruptBeforeEdge延迟路由特性,在流程续跑时动态修正下一个执行节点,保障人工干预后的条件路由正常生效。
核心源码:
java
public class MainGraphExecutor extends BaseGraphExecutor {
// 节点执行器:负责具体节点的业务逻辑运行
private final NodeExecutor nodeExecutor;
// 构造方法:初始化节点执行器
public MainGraphExecutor() {
this.nodeExecutor = new NodeExecutor(this);
}
/**
* 【核心执行方法】
* 驱动整个流程图的运行、中断、恢复
*/
@Override
public Flux<GraphResponse<NodeOutput>> execute(GraphRunnerContext context, AtomicReference<Object> resultValue) {
// 1. 流程终止/达到最大迭代次数 → 结束执行
if (context.shouldStop() || context.isMaxIterationsReached()) {
return handleCompletion(context, resultValue);
}
// 2. 断点续跑逻辑:处理中断恢复 + 动态路由(interruptBeforeEdge)
final var resumeFrom = context.getResumeFromAndReset();
if (resumeFrom.isPresent()) {
// 开启延迟路由 + 当前是中断标记 → 重新计算下一个节点
if (context.getCompiledGraph().compileConfig.interruptBeforeEdge()
&& java.util.Objects.equals(context.getNextNodeId(), INTERRUPT_AFTER)) {
var nextNode = context.nextNodeId(resumeFrom.get(), context.getCurrentStateData());
context.setNextNodeId(nextNode.gotoNode());
context.setCurrentNodeId(null);
}
}
// 3. 判断是否需要中断 → 触发中断,返回中断元数据
if (context.shouldInterrupt()) {
InterruptionMetadata metadata = InterruptionMetadata
.builder(context.getCurrentNodeId(), context.cloneState(context.getCurrentStateData()))
.build();
return Flux.just(GraphResponse.done(metadata));
}
// 4. 执行开始节点(流程启动)
if (context.isStartNode()) {
return handleStartNode(context);
}
// 5. 执行结束节点(流程结束)
if (context.isEndNode()) {
return handleEndNode(context, resultValue);
}
// 6. 委托节点执行器,运行具体业务节点
return nodeExecutor.execute(context, resultValue);
}
/**
* 处理流程【开始节点】
*/
private Flux<GraphResponse<NodeOutput>> handleStartNode(GraphRunnerContext context) {
// 设置下一个执行节点
context.setNextNodeId(context.getEntryPoint().gotoNode());
context.setCurrentNodeId(context.getNextNodeId());
// 递归继续执行流程
return Flux.just(GraphResponse.of(context.buildOutput("START")))
.concatWith(Flux.defer(() -> execute(context, new AtomicReference<>())));
}
/**
* 处理流程【结束节点】
*/
private Flux<GraphResponse<NodeOutput>> handleEndNode(GraphRunnerContext context, AtomicReference<Object> resultValue) {
return Flux.just(GraphResponse.of(context.buildOutput("END")))
.concatWith(handleCompletion(context, resultValue));
}
}2.3 GraphRunnerContext
GraphRunnerContext 是 流程执行上下文 ,贯穿流程图全生命周期,负责管理流程状态、节点信息、执行配置 ,是中断机制、断点续跑、人在回路的核心载体。
中断相关核心功能:
- 中断标记 :定义
__INTERRUPTED__固定标记,标识流程处于中断状态 - 中断判断 :统一判断节点执行前/执行后是否需要触发中断
- 断点续跑:初始化续跑上下文,恢复中断前的流程状态与节点信息
- 状态管理:保存/恢复中断时的流程快照,支撑流程暂停与恢复
核心源码:
java
package com.alibaba.cloud.ai.graph;
import java.util.Map;
import java.util.Optional;
import static com.alibaba.cloud.ai.graph.StateGraph.START;
/**
* 流程执行上下文
* 核心:管理状态、节点、中断、续跑
*/
public class GraphRunnerContext {
// ==================== 中断核心常量 ====================
// 流程中断标记:标识流程处于暂停状态
public static final String INTERRUPT_AFTER = "__INTERRUPTED__";
// 编译后的流程图
final CompiledGraph compiledGraph;
// 流程总状态
OverAllState overallState;
// 运行配置
RunnableConfig config;
// 当前/下一个执行节点ID
String currentNodeId;
String nextNodeId;
// 断点续跑:中断来源节点ID
String resumeFrom;
// ==================== 构造方法:初始化流程(新启动/断点续跑) ====================
public GraphRunnerContext(OverAllState initialState, RunnableConfig config, CompiledGraph compiledGraph) throws Exception {
this.compiledGraph = compiledGraph;
this.config = config;
// 判断:有检查点/人工反馈 → 断点续跑初始化
if (config.checkPointId().isPresent()) {
initializeFromResume(initialState, config);
} else {
// 全新流程初始化
initializeFromStart(initialState, config);
}
}
// ==================== 断点续跑:恢复中断流程 ====================
private void initializeFromResume(OverAllState initialState, RunnableConfig config) {
// 获取中断检查点
var checkpoint = compiledGraph.compileConfig().checkpointSaver().get().get(config).get();
// 恢复中断时的节点与状态
this.nextNodeId = checkpoint.getNextNodeId();
this.overallState = initialState.input(checkpoint.getState());
// 记录:从哪个节点续跑
this.resumeFrom = checkpoint.getNodeId();
}
// ==================== 全新流程:初始化 ====================
private void initializeFromStart(OverAllState initialState, RunnableConfig config) {
this.overallState = initialState;
// 初始节点:START
this.currentNodeId = START;
}
// ==================== 中断核心:总判断(是否需要中断) ====================
public boolean shouldInterrupt() {
// 执行前中断 || 执行后中断
return shouldInterruptBefore(nextNodeId, currentNodeId)
|| shouldInterruptAfter(currentNodeId, nextNodeId);
}
// ==================== 执行前中断判断 ====================
private boolean shouldInterruptBefore(String nodeId, String previousNodeId) {
// 节点在 interruptBefore 配置列表中 → 中断
return compiledGraph.compileConfig().interruptsBefore().contains(nodeId);
}
// ==================== 执行后中断判断 ====================
private boolean shouldInterruptAfter(String nodeId, String previousNodeId) {
// 1. 开启延迟路由 + 中断标记 → 中断
// 2. 节点在 interruptAfter 配置列表中 → 中断
return (compiledGraph.compileConfig().interruptBeforeEdge()
&& nodeId.equals(INTERRUPT_AFTER))
|| compiledGraph.compileConfig().interruptsAfter().contains(nodeId);
}
// ==================== 续跑工具方法 ====================
// 获取续跑节点并重置(一次性使用)
public Optional<String> getResumeFromAndReset() {
Optional<String> result = Optional.ofNullable(resumeFrom);
resumeFrom = null;
return result;
}
// ==================== 基础 Get/Set ====================
public String getCurrentNodeId() { return currentNodeId; }
public String getNextNodeId() { return nextNodeId; }
public void setNextNodeId(String nodeId) { this.nextNodeId = nodeId; }
public Map<String, Object> getCurrentStateData() { return overallState.data(); }
public CompiledGraph getCompiledGraph() { return compiledGraph; }
}2.4 NodeExecutor
NodeExecutor 是 图引擎的节点执行器 ,负责单个节点的全生命周期执行 ,是动态中断 (InterruptableAction) 功能的核心实现组件。
中断相关核心功能:
- 动态中断判断 :执行
InterruptableAction节点时,自动判断是否需要触发中断 - 中断响应 :生成
InterruptionMetadata中断对象,通知流程引擎暂停执行 - 执行后中断:节点逻辑执行完毕后,支持后置中断校验
- 配合中断配置 :支持
interruptBeforeEdge延迟路由标记 - 节点执行:异步运行节点业务逻辑、合并状态、驱动流程流转
核心源码:
java
public class NodeExecutor extends BaseGraphExecutor {
// 主执行器引用
private final MainGraphExecutor mainGraphExecutor;
public NodeExecutor(MainGraphExecutor mainGraphExecutor) {
this.mainGraphExecutor = mainGraphExecutor;
}
/**
* 【核心】执行节点
*/
@Override
public Flux<GraphResponse<NodeOutput>> execute(GraphRunnerContext context, AtomicReference<Object> resultValue) {
return executeNode(context, resultValue);
}
/**
* 节点执行逻辑(含中断处理)
*/
private Flux<GraphResponse<NodeOutput>> executeNode(GraphRunnerContext context, AtomicReference<Object> resultValue) {
try {
// 1. 设置当前执行节点
String currentNodeId = context.getNextNodeId();
context.setCurrentNodeId(currentNodeId);
AsyncNodeActionWithConfig action = context.getNodeAction(currentNodeId);
// 2. 【核心中断】处理动态中断节点:InterruptableAction
if (action instanceof InterruptableAction interruptAction) {
// 调用节点的中断判断方法
Optional<InterruptionMetadata> interruptMetadata = interruptAction.interrupt(
currentNodeId,
context.cloneState(context.getCurrentStateData()),
context.getConfig()
);
// 3. 需要中断:返回中断元数据,流程暂停
if (interruptMetadata.isPresent()) {
return Flux.just(GraphResponse.done(interruptMetadata.get()));
}
}
// 4. 执行节点业务逻辑(异步)
CompletableFuture<Map<String, Object>> future = action.apply(context.getOverallState(), context.getConfig());
// 5. 处理节点执行结果
return Mono.fromFuture(future)
.flatMapMany(updateState -> handleActionResult(context, updateState, resultValue));
} catch (Exception e) {
return Flux.just(GraphResponse.error(e));
}
}
/**
* 处理节点执行结果(含执行后中断)
*/
private Flux<GraphResponse<NodeOutput>> handleActionResult(
GraphRunnerContext context,
Map<String, Object> updateState,
AtomicReference<Object> resultValue
) {
try {
String currentNodeId = context.getCurrentNodeId();
AsyncNodeActionWithConfig action = context.getNodeAction(currentNodeId);
// 【核心】执行后中断判断
if (action instanceof InterruptableAction interruptAction) {
Optional<InterruptionMetadata> interruptMetadata = interruptAction.interruptAfter(
currentNodeId,
context.cloneState(context.getCurrentStateData()),
updateState,
context.getConfig()
);
// 执行后需要中断:流程暂停
if (interruptMetadata.isPresent()) {
context.mergeIntoCurrentState(updateState);
return Flux.just(GraphResponse.done(interruptMetadata.get()));
}
}
// 6. 合并节点执行后的状态
context.mergeIntoCurrentState(updateState);
// 7. 配合 interruptBeforeEdge:标记中断,延迟计算下一个节点
if (context.getCompiledGraph().compileConfig().interruptBeforeEdge()
&& context.getCompiledGraph().compileConfig().interruptsAfter().contains(currentNodeId)) {
context.setNextNodeId(INTERRUPT_AFTER);
} else {
// 8. 正常计算下一个执行节点
Command nextCommand = context.nextNodeId(currentNodeId, context.getCurrentStateData());
context.setNextNodeId(nextCommand.gotoNode());
}
// 9. 递归调用主执行器,继续执行流程
return Flux.just(GraphResponse.of(context.buildNodeOutputAndAddCheckpoint(updateState)))
.concatWith(Flux.defer(() -> mainGraphExecutor.execute(context, resultValue)));
} catch (Exception e) {
return Flux.just(GraphResponse.error(e));
}
}
}2.5 InterruptableAction
InterruptableAction 是 Graph 动态中断机制的核心契约接口 ,专为需要自定义中断逻辑的节点设计。
它定义了节点执行前、执行后 两个中断钩子,让节点可以根据运行时状态/执行结果动态决定是否中断流程。
核心特性:
- 动态中断:基于运行时状态/结果判断中断,而非静态配置
- 双钩子机制:执行前中断 + 执行后中断
- 默认适配 :
interruptAfter提供空默认实现,按需重写即可 - 标准契约:所有支持动态中断的节点必须实现此接口
标准执行流程:
interrupt() 【执行前中断判断】
↓
apply() 【执行业务逻辑】
↓
interruptAfter() 【执行后中断判断】接口源码:
java
/**
* 可中断动作接口:定义图执行中断的标准契约
* 提供【执行前】和【执行后】两个中断钩子,实现动态中断
* 执行流程:interrupt() -> apply() -> interruptAfter()
*/
public interface InterruptableAction {
/**
* 【节点执行前中断】
* 在节点 apply() 方法执行前调用,判断是否需要中断
* @param nodeId 当前节点ID
* @param state 流程当前状态
* @param config 运行配置
* @return 中断元数据(中断) / empty(继续执行)
*/
Optional<InterruptionMetadata> interrupt(String nodeId, OverAllState state, RunnableConfig config);
/**
* 【节点执行后中断】
* 在节点 apply() 执行完成后、状态合并前调用
* 可根据节点执行结果判断是否中断
* @param nodeId 当前节点ID
* @param state 执行前的状态
* @param actionResult 节点执行结果
* @param config 运行配置
* @return 中断元数据(中断) / empty(继续执行)
*/
default Optional<InterruptionMetadata> interruptAfter(String nodeId, OverAllState state,
Map<String, Object> actionResult, RunnableConfig config) {
// 默认不中断
return Optional.empty();
}
}2.6 Hook
2.6.1 InterruptionHook
InterruptionHook 是 React 智能体的中断钩子 ,继承 ModelHook 并实现动态中断接口 ,在大模型调用前执行。
核心中断能力:
- 前置中断:模型调用前检测中断信号,触发流程暂停
- 反馈处理:接收人工输入,自动注入对话上下文
- 线程安全:基于会话ID隔离多轮对话的中断/反馈状态
精简源码:
java
/**
* 中断钩子:实现【模型调用前】的动态中断 + 人工反馈处理
* 位置:@HookPositions(HookPosition.BEFORE_MODEL)
*/
public class InterruptionHook extends ModelHook implements AsyncNodeActionWithConfig, InterruptableAction {
// 中断反馈的存储KEY
public static final String INTERRUPTION_FEEDBACK_KEY = "INTERRUPTION_FEEDBACK";
// 中断节点名称
public static final String INTERRUPTION_NODE_NAME = "INTERRUPTION";
/**
* 【核心】节点执行:处理人工反馈消息
* 读取会话中的反馈,追加到智能体对话上下文
*/
@Override
public CompletableFuture<Map<String, Object>> apply(OverAllState state, RunnableConfig config) {
// 获取当前会话的状态
String threadId = config.threadId().orElse("default");
Map<String, Object> threadState = getAgent().getThreadState(threadId);
if (threadState == null) return CompletableFuture.completedFuture(Map.of());
// 原子获取并移除人工反馈
Object feedback = threadState.remove(INTERRUPTION_FEEDBACK_KEY);
if (feedback == null) return CompletableFuture.completedFuture(Map.of());
// 解析反馈为对话消息
List<Message> newMessages = switch (feedback) {
case List<?> list -> list.stream().filter(Message.class::isInstance).map(Message.class::cast).toList();
case UserMessage msg -> List.of(msg);
case String text -> List.of(new UserMessage(text));
default -> List.of();
};
// 返回更新后的对话消息
return CompletableFuture.completedFuture(Map.of("messages", newMessages));
}
/**
* 【核心中断】模型执行前:判断是否需要中断流程
* 规则:检测到【空列表反馈】→ 触发中断
*/
@Override
public Optional<InterruptionMetadata> interrupt(String nodeId, OverAllState state, RunnableConfig config) {
String threadId = config.threadId().orElse("default");
Map<String, Object> threadState = getAgent().getThreadState(threadId);
if (threadState == null) return Optional.empty();
// 获取中断信号
Object feedback = threadState.get(INTERRUPTION_FEEDBACK_KEY);
// 空列表 = 人工请求中断 → 返回中断元数据
if (feedback instanceof List<?> list && list.isEmpty()) {
log.debug("检测到人工中断请求,触发流程暂停");
return Optional.of(InterruptionMetadata.builder(nodeId, state).build());
}
// 无中断信号,继续执行
return Optional.empty();
}
// 默认实现:节点名称、跳转策略、状态策略
@Override
public String getName() { return INTERRUPTION_NODE_NAME; }
}2.6.2 HumanInTheLoopHook
HumanInTheLoopHook 是人在回路 (Human-In-The-Loop)的核心实现,在大模型调用完成后 执行,专门用于AI工具调用的人工审核 ,自动拦截需要人工审批的工具调用,触发流程中断;接收人工的批准/编辑/拒绝反馈后,恢复流程执行。
核心能力:
- 工具审批中断:模型生成工具调用后,自动检测并中断需要人工审核的工具
- 人工反馈处理:支持人工批准、编辑参数、拒绝工具调用
- 自动放行:无需审批的工具直接自动通过
- 状态同步:根据人工结果更新对话上下文,驱动流程继续
3. IinterruptableAction 模式(节点动态中断)
核心特性:
- 动态判断:基于运行时状态 / 执行结果决定是否中断
- 双钩子:
interrupt()(执行前) +interruptAfter()(执行后) - 人工反馈合并:恢复时合并外部输入的状态数据
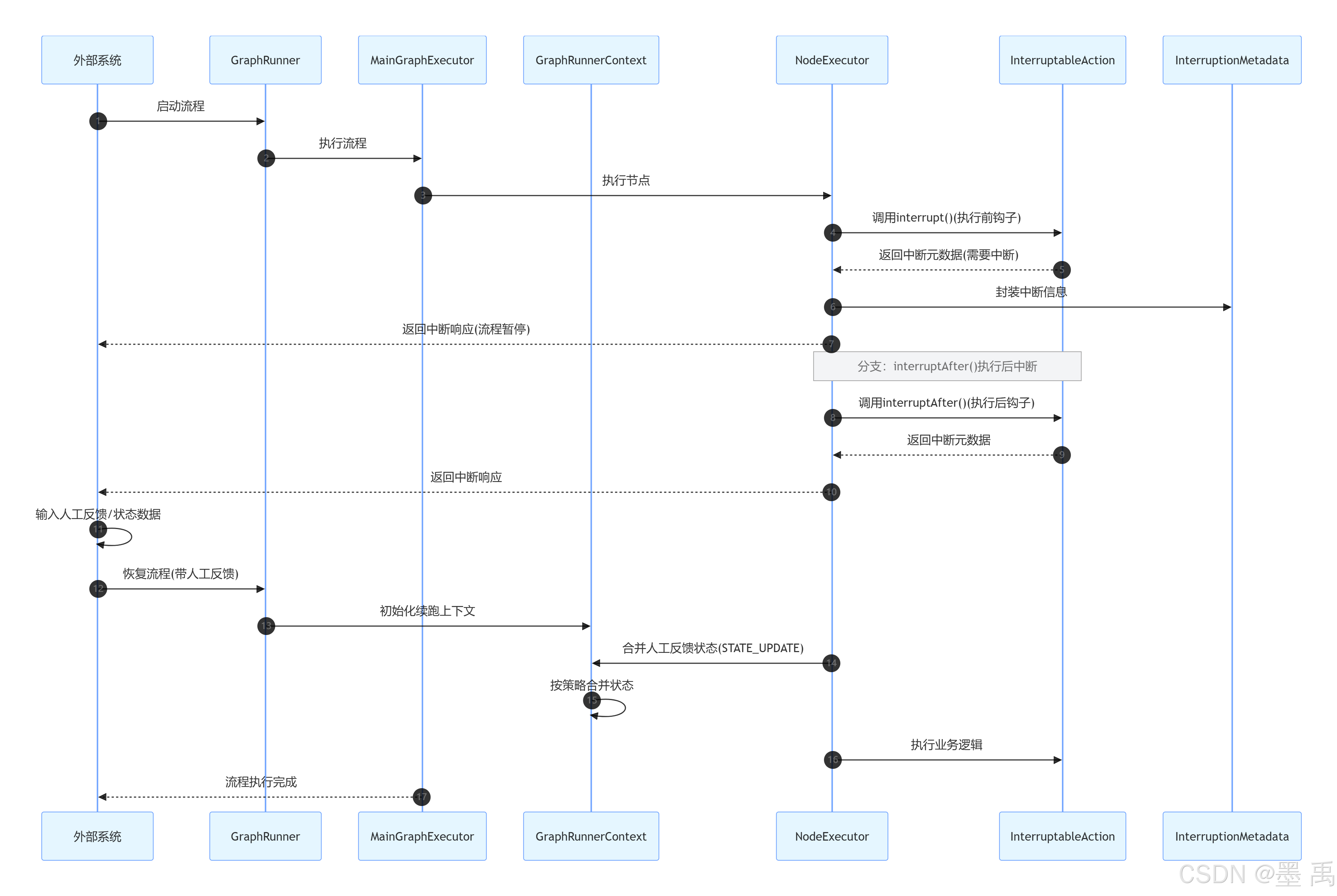
3.1 中断判断逻辑
3.1.1 interrupt()
对于实现了 InterruptableAction 接口的节点,是在 NodeExecutor 执行中判断的,调用 interrupt 方法如果返回 InterruptionMetadata 不为 null ,表示要进行中断,返回中断响应 → 流程暂停:
java
// 判断当前节点是否为【可中断节点】(人工审批/暂停节点)
if (action instanceof InterruptableAction) {
// ....................
// 执行中断逻辑:触发流程暂停(等待人工审批/外部输入)
Optional<InterruptionMetadata> interruptMetadata = ((InterruptableAction) action)
.interrupt(
currentNodeId, // 当前节点ID
context.cloneState(context.getCurrentStateData()), // 克隆当前完整状态
context.getConfig() // 执行配置
);
// 如果需要中断(人工暂停)
if (interruptMetadata.isPresent()) {
// 保存中断信息(用于后续恢复)
resultValue.set(interruptMetadata.get());
// 返回中断响应 → 流程暂停,不再继续执行
return Flux.just(GraphResponse.done(interruptMetadata.get()));
}
}3.1.2 interruptAfter()
节点执行完成后进入 NodeExecutor#handleActionResult ,如果实现了 InterruptableAction 接口,调用 interruptAfter 方法,判断是否需要在节点执行后进行中断:
java
// ==============================
// 执行节点后中断钩子(在 apply() 执行之后、状态合并之前)
// ==============================
String currentNodeId = context.getCurrentNodeId();
// 获取当前节点要执行的动作
AsyncNodeActionWithConfig action = context.getNodeAction(currentNodeId);
// 判断节点是否支持中断(人工审批/暂停)
if (action instanceof InterruptableAction) {
// 调用 interruptAfter 方法,判断是否需要中断
Optional<InterruptionMetadata> interruptMetadata = ((InterruptableAction) action)
.interruptAfter(
currentNodeId, // 当前节点ID
context.cloneState(context.getCurrentStateData()), // 克隆当前状态
updateState, // 节点执行后的变更状态
context.getConfig() // 执行配置
);
// 如果需要中断(例如:等待人工审批)
if (interruptMetadata.isPresent()) {
// ==============================
// 【关键步骤 1】合并节点执行结果到当前状态
// 合并规则:走 updateState → 无策略默认替换
// ==============================
context.mergeIntoCurrentState(updateState);
// ==============================
// 【关键步骤 2】提前计算下一个节点
// 恢复时直接从这个节点继续执行
// ==============================
Command nextCommand = context.nextNodeId(currentNodeId, context.getCurrentStateData());
context.setNextNodeId(nextCommand.gotoNode());
// ==============================
// 【关键步骤 3】构建检查点并保存
// 保存内容:当前状态 + 下一个节点ID
// ==============================
context.buildNodeOutputAndAddCheckpoint(updateState);
// 执行节点后监听器
context.doListeners(NODE_AFTER, null);
// 返回中断结果 → 流程暂停
resultValue.set(interruptMetadata.get());
return Flux.just(GraphResponse.done(interruptMetadata.get()));
}
}3.2 构建中断元数据
【中断元数据】是实现了 InterruptableAction 接口处理的,如果需要中断则需要自定构建并返回,不需要中断返回 null 即可。
3.3 返回中断响应
需要中断时都会直接响应 interrupt() 、interruptAfter() 返回的中断元数据:
java
// 返回中断结果 → 流程暂停
resultValue.set(interruptMetadata.get());
return Flux.just(GraphResponse.done(interruptMetadata.get()));前中断逻辑示例:
java
/**
* 前中断逻辑 - 审核前判断
* 如果标记了 skip_ai_review = true,则跳过 AI 审核直接进入人工审核
*/
@Override
public Optional<InterruptionMetadata> interrupt(String nodeId, OverAllState state, RunnableConfig config) {
Boolean skipAiReview = state.value("skip_ai_review", Boolean.class).orElse(false);
if (Boolean.TRUE.equals(skipAiReview)) {
log.info("Skipping AI review as requested, interrupting before execution...");
return Optional.of(InterruptionMetadata.builder(nodeId, state)
.addMetadata("interruption_type", "SKIP_AI_REVIEW")
.addMetadata("reason", "已配置跳过 AI 审核,直接进入人工审核")
.addMetadata("skip_ai_review", true)
.build());
}
return Optional.empty();
}3.4 初始化执行上下文
用户操作后进入到流程恢复阶段,首先进入到 GraphRunner#run 方法初始化【执行】上下文,再调用执行器执行:
java
public Flux<GraphResponse<NodeOutput>> run(OverAllState initialState) {
return Flux.defer(() -> {
try {
GraphRunnerContext context = new GraphRunnerContext(initialState, config, compiledGraph);
// Delegate to the main execution handler - demonstrates polymorphism
return mainGraphExecutor.execute(context, resultValue);
}
catch (Exception e) {
return Flux.error(e);
}
});
}GraphRunnerContext 构造函数创建实例时,会传入初始全局状态 、运行配置 、编译后的执行图三个核心参数,满足以下两个条件之一,代表需要恢复运行:
RunnableConfig中存在名为HUMAN_FEEDBACK的值RunnableConfig中存在checkPointId值(检查点ID)
java
/**
* GraphRunnerContext 构造函数
* 初始化图执行上下文,根据运行配置自动选择【全新启动】或【断点恢复】初始化逻辑
* @param initialState 初始全局状态,任务执行的起始总状态
* @param config 运行配置,包含元数据、检查点ID等核心执行配置
* @param compiledGraph 编译后的执行图,定义了任务的执行流程结构
* @throws Exception 初始化过程中抛出的异常
*/
public GraphRunnerContext(OverAllState initialState, RunnableConfig config, CompiledGraph compiledGraph)
throws Exception {
// 赋值编译后的执行图(核心执行流程)
this.compiledGraph = compiledGraph;
// 赋值运行时配置
this.config = config;
// 判断:配置中存在【人工反馈元数据】 或 存在【检查点ID】 → 代表需要恢复运行
if (config.metadata(RunnableConfig.HUMAN_FEEDBACK_METADATA_KEY).isPresent() || config.checkPointId().isPresent()) {
// 从断点/人工反馈状态恢复初始化(续跑逻辑)
initializeFromResume(initialState, config);
} else {
// 无恢复标识 → 全新启动初始化(从头开始执行)
initializeFromStart(initialState, config);
}
}initializeFromResume 从【断点恢复/人工反馈续跑】状态初始化上下文处理逻辑:
- 首先打印日志
RESUME REQUEST,标记接收到任务恢复请求 - 从编译图配置中获取检查点持久化器,若未配置则直接抛出异常,保证续跑的基础依赖存在
- 通过检查点持久化器根据运行配置加载检查点数据,无有效检查点时抛出异常,确保续跑数据有效
- 根据检查点中的下一个节点
ID,从编译图中获取对应的节点执行动作 - 判断节点动作类型:
- 若为可恢复的子图动作 :基于原配置重新构建运行配置,清空检查点
ID,添加子图恢复元数据,并清空配置上下文缓存 - 若为普通节点动作:仅重置运行配置中的检查点
ID,避免重复触发恢复逻辑
- 若为可恢复的子图动作 :基于原配置重新构建运行配置,清空检查点
- 初始化当前节点
ID为null,续跑流程从检查点记录的下一个节点开始执行 - 将下一个执行节点设置为检查点中记录的目标节点
ID - 合并初始全局状态与检查点保存的业务状态,恢复任务的全局运行状态
- 记录任务恢复的来源节点
ID(即检查点所属的节点) - 打印日志,输出任务恢复的来源节点
ID,完成续跑初始化全流程
java
/**
* 从【断点恢复/人工反馈续跑】状态初始化上下文
* 核心作用:加载检查点数据,重置运行配置,恢复任务执行的上下文状态
* @param initialState 初始全局状态(用于合并检查点状态)
* @param config 运行配置(包含检查点ID、恢复元数据等)
*/
private void initializeFromResume(OverAllState initialState, RunnableConfig config) {
// 打印日志:标记接收到任务恢复请求
log.trace("RESUME REQUEST");
// 从编译图配置中获取【检查点持久化器】
// 如果未配置检查点保存器,直接抛出异常:续跑必须依赖检查点
var saver = compiledGraph.compileConfig.checkpointSaver()
.orElseThrow(() -> new IllegalStateException("Resume request without a configured checkpoint saver!"));
// 通过检查点持久化器,根据运行配置获取对应的【检查点数据】
// 如果没有找到有效检查点,抛出异常:无法执行续跑
var checkpoint = saver.get(config)
.orElseThrow(() -> new IllegalStateException("Resume request without a valid checkpoint!"));
// 根据检查点记录的【下一个节点ID】,获取编译图中对应的节点执行动作
var startCheckpointNextNodeAction = compiledGraph.getNodeAction(checkpoint.getNextNodeId());
// 判断:该节点动作是否为【可恢复的子图动作】(支持子图断点续跑)
if (startCheckpointNextNodeAction instanceof ResumableSubGraphAction resumableAction) {
// 日志标记:检测到需要从子图恢复执行
// 重新构建运行配置:基于原配置修改
this.config = RunnableConfig.builder(config)
.checkPointId(null) // 重置检查点ID(续跑后清空,避免重复恢复)
.addMetadata(resumableAction.getResumeSubGraphId(), true) // 添加子图恢复专用元数据,标记需要恢复的子图
.build();
// 清空配置中的上下文缓存
this.config.clearContext();
} else {
// 普通节点续跑:仅重置检查点ID,无需额外元数据
this.config = config.withCheckPointId(null);
}
// 初始化当前节点ID为null(续跑从下一个节点开始)
this.currentNodeId = null;
// 设置下一个执行节点为检查点记录的目标节点
this.nextNodeId = checkpoint.getNextNodeId();
// 合并初始状态与检查点保存的业务状态,恢复全局状态
this.overallState = initialState.input(checkpoint.getState());
// 记录:当前任务是从哪个节点的检查点恢复的
this.resumeFrom = checkpoint.getNodeId();
// 打印日志:输出任务恢复的来源节点ID
log.trace("RESUME FROM {}", checkpoint.getNodeId());
}3.5 合并状态(BUG)
这里有个
BUG在之前说过了!!!这里详细分析为啥是BUG
在初始化执行上下文中,有一个比较重要的步骤,就是【合并初始状态与检查点保存的状态】,initialState 是恢复执行时传递的状态,checkpoint.getState() 是中断时保存的状态:
checkpoint.getState()→ 拿到断点持久化快照Map- 调用
input()→ 按策略把快照数据合并进initialState - 赋值给上下文
overallState→ 续跑流程拿到还原后的状态,接着执行下一个节点
java
// 合并初始状态与检查点保存的业务状态,恢复全局状态
this.overallState = initialState.input(checkpoint.getState());在断点恢复 流程中,把检查点快照里保存的历史状态数据,按照预先定义的 KeyStrategy 策略,合并/覆盖到当前初始全局状态里,还原流程断点那一刻的运行上下文,保证续跑能从正确状态、正确节点接着往下执行。
合并逻辑:
- 接收检查点快照状态
checkPointStatus,作为待恢复的数据源 - 做空安全防护 :快照为
null或空集合时,直接不做任何状态变更 - 加载全局状态预定义的
KeyStrategy字段合并策略(执行图中指定的不可修改) - 自动过滤掉没有配置策略的无效
Key,只处理业务约定好的状态字段 - 对每个有效字段,按对应策略做状态合并:
- 替换策略:用断点快照值直接覆盖当前初始状态值(流程节点、状态标识必用)
- 累加策略:当前值 + 断点值 做累计(次数、金额、计数类)
- 追加策略:集合类数据新旧合并(日志、任务列表、流水记录)
- 最终把合并后的完整状态,赋值给
overallState,还原断点暂停时的现场 - 支持链式调用,方便后续流程直接使用恢复后的全局状态
java
/**
* 向全局状态中输入/更新数据
* 根据预设的键值策略,合并外部输入的数据到当前全局状态中
* @param input 外部输入的键值对数据(可为null/空)
* @return 处理后的全局状态对象(自身实例)
*/
public OverAllState input(Map<String, Object> input) {
// 入参为null,无需处理,直接返回当前全局状态
if (input == null) {
return this;
}
// 入参为空集合,无需处理,直接返回当前全局状态
if (CollectionUtils.isEmpty(input)) {
return this;
}
// 获取当前全局状态的【键处理策略】映射
// 每个数据键对应一个专属的合并/更新策略
Map<String, KeyStrategy> keyStrategies = keyStrategies();
// 核心逻辑:遍历输入数据,仅处理存在对应策略的键
input.keySet().stream()
// 过滤:只保留在策略映射中存在的键(忽略无策略的无效键)
.filter(key -> keyStrategies.containsKey(key))
// 遍历有效键,执行数据合并/更新
.forEach(key -> {
// 1. 获取当前状态中该键的旧值
// 2. 通过键策略的apply方法,合并旧值和输入的新值
// 3. 将合并后的值存入全局状态的data容器
this.data.put(key, keyStrategies.get(key).apply(value(key, null), input.get(key)));
});
// 返回处理完成的全局状态自身(支持链式调用)
return this;
}在调用图的 stream 方法进行流程恢复时,必须传入 RunnableConfig ,可用的方法只有一个:
java
public Flux<NodeOutput> stream(Map<String, Object> inputs, RunnableConfig config) {
return streamFromInitialNode(stateCreate(inputs), config);
}在 stateCreate(inputs) 中的处理逻辑:
inputs == null:设置为空Map- 强制保证执行
ID(EXECUTION_ID)存在,不存在则自动生成 - 构建新的
OverAllState对象inputs封装到data属性- 设置
Key替换策略(keyStrategyMap从编译图对象中获取) - 设置状态存储(从
CompileConfig中获取)
java
/**
* 创建全局状态对象(OverAllState)
* 用于流程启动、断点恢复时,初始化状态实例
*
* @param inputs 输入的状态数据(可为null)
* @return 构建完成的全局状态对象
*/
private OverAllState stateCreate(Map<String, Object> inputs) {
// 处理空输入(例如断点恢复场景,无初始输入数据)
if (inputs == null) {
inputs = new HashMap<>();
}
// 强制保证执行ID(EXECUTION_ID)存在,不存在则自动生成
// 执行ID是流程唯一标识,用于日志、追踪、断点存储
if (!inputs.containsKey(GraphLifecycleListener.EXECUTION_ID_KEY)) {
// 复制原输入Map,避免修改外部传入的集合
Map<String, Object> newInputs = new HashMap<>(inputs);
// 生成随机UUID作为执行ID
newInputs.put(GraphLifecycleListener.EXECUTION_ID_KEY, java.util.UUID.randomUUID().toString());
inputs = newInputs;
}
// 使用图的策略配置 + 输入数据,构建新的全局状态实例
return OverAllStateBuilder.builder()
.withKeyStrategies(getKeyStrategyMap()) // 设置数据合并策略
.withData(inputs) // 设置初始状态数据
.withStore(compileConfig.getStore()) // 设置状态存储(持久化/缓存)
.build(); // 构建最终状态对象
}示例,持久化保存的检查点快照数据为:
json
{
"flowStatus": "PAUSED",
"processCount": 5,
"recordList": ["step1","step2"],
"age": 20,
"address": "beijing"
}字段策略表(关键):
| key | 策略 | 行为 |
|---|---|---|
| currentNodeId | 替换 | 用断点值覆盖 |
| flowStatus | 替换 | 用断点值覆盖 |
| processCount | 累加 | 旧值 + 断点值 |
| recordList | 追加 | 旧列表 + 断点列表 |
| age | 无策略 | 直接忽略,不处理 |
| address | 无策略 | 直接忽略,不处理 |
恢复执行时传入的初始状态 initialState(全新状态)数据为:
json
data: {
"currentNodeId": null, // 替换策略
"flowStatus": "NEW", // 替换策略
"processCount": 0, // 累加策略
"recordList": [], // 追加策略
"userName": null // 【无策略】
}input(checkPointStatus) 后的最终结果
json
data: {
"currentNodeId": "node_audit", // 替换成功
"flowStatus": "PAUSED", // 替换成功
"processCount": 5, // 累加:0+5=5
"recordList": ["step1","step2"], // 追加成功
"userName": null, // 保持不变
"age": 【不存在】, // 无策略 → 被忽略,不会写入
"address": 【不存在】 // 无策略 → 被忽略,不会写入
}有策略的 key 一定会被处理:
- 替换 → 覆盖
- 累加 → 相加
- 追加 → 合并
没有策略的 key 完全被忽略:
age、address
关于 stream() 调用时,检查点状态数据如何合并到全局状态中的重要说明:
- 没有策略的
key不会合并到全局状态 - 配置了
ReplaceStrategy的Key会替换掉恢复时传入的值 - 如果想要直接使用检查点状态数据,可以先查询再
stream()时传入 - 如果想要替换掉检查点状态数据中的某个
Key,需要针对该值自定义替换策略
3.6 STATE_UPDATE 合并状态
接着进入到 NodeExecutor 进行 InterruptableAction 的中断续跑处理:
- 从配置的元数据中,获取【人工反馈/恢复时带来的状态更新数据】
- 如果存在元数据就进行合并状态
- 过滤
token统计
java
// 判断当前节点是否为【可中断节点】(人工审批/暂停节点)
if (action instanceof InterruptableAction) {
// 从配置的元数据中,获取【人工反馈带来的状态更新数据】
context.getConfig().metadata(RunnableConfig.STATE_UPDATE_METADATA_KEY)
.ifPresent(updateFromFeedback -> {
// 判断状态更新数据是否为 Map 类型
if (updateFromFeedback instanceof Map<?, ?>) {
// 【关键】将人工反馈的状态数据,合并到当前全局状态
context.mergeIntoCurrentState((Map<String, Object>) updateFromFeedback);
} else {
// 类型错误,抛出异常
throw new RuntimeException("人工反馈状态更新数据必须是 Map 类型");
}
});元数据中存放【人工状态更新】的固定 KEY :
java
public static final String STATE_UPDATE_METADATA_KEY = "STATE_UPDATE";会从元数据中获取 KEY 为 STATE_UPDATE 的状态数据(必须是 Map 类型),才会进行状态合并,入口:
java
/**
* 更新当前流程状态 + 全局状态
* @param updateState 要更新的状态数据
*/
public void mergeIntoCurrentState(Map<String, Object> updateState) {
// 过滤掉 token 使用量(特殊处理)
Map<String, Object> filteredState = findTokenUsageInDeltaState(updateState);
// 调用全局状态的 updateState 方法 → 真正执行更新
this.overallState.updateState(filteredState);
}过滤 token 统计(临时修复方法):
java
/**
* 临时修复:从状态更新中分离出 Token 用量(不进入业务状态)
* 配合 AI 节点非流式模式使用
*/
private Map<String, Object> findTokenUsageInDeltaState(Map<String, Object> updateState) {
Map<String, Object> filteredState = new HashMap<>();
for (Map.Entry<String, Object> entry : updateState.entrySet()) {
Object value = entry.getValue();
// 如果是 _TOKEN_USAGE_ 且类型是 Usage → 单独存起来,不进业务状态
if (value instanceof Usage && entry.getKey().equals("_TOKEN_USAGE_")) {
this.tokenUsage = (Usage) value;
} else {
// 正常业务状态 → 保留
filteredState.put(entry.getKey(), value);
}
}
return filteredState;
}updateState 是全局状态的最终更新入口:
- 遍历你传入的所有
key - 查找
key对应的策略,没有策略 默认使用KeyStrategy.REPLACE(替换) - 你传什么,就覆盖什么,默认全部替换检查点状态
java
/**
* 批量更新状态(支持策略:替换/累加/追加)
* @param partialState 要更新的部分状态
* @return 最终状态
*/
public Map<String, Object> updateState(Map<String, Object> partialState) {
// 获取当前状态定义的 Key 策略
Map<String, KeyStrategy> keyStrategies = keyStrategies();
// 遍历要更新的所有 key
partialState.keySet().forEach(key -> {
// 获取该 key 对应的策略
KeyStrategy strategy = keyStrategies != null ? keyStrategies.get(key) : null;
// ==============================
// 【超级重要】
// 如果没有配置策略 → 默认使用 REPLACE(替换)
// ==============================
if (strategy == null) {
strategy = KeyStrategy.REPLACE;
}
// 如果标记为删除 → 移除 key
if (partialState.get(key) == MARK_FOR_REMOVAL) {
this.data.remove(key);
} else {
// ==============================
// 按策略合并:旧值 + 新值 → 覆盖/累加/追加
// ==============================
this.data.put(
key,
strategy.apply(value(key, null), partialState.get(key))
);
}
});
return data();
}3.7 执行结束
合并状态之后,说明这个暂停节点已经被正式恢复了,按照正常流程继续执行直到结束。