
大家好,我是Tony Bai。
过去两年,程序员群体经历了一场前所未有的"职业身份危机"。
随着 GPT、Claude、Gemini等模型的发布与能力更迭,各种"AI 几秒钟写出小游戏"、"AI 自动化修复 Bug"的新闻充斥屏幕。在各种传统的代码补全基准测试(如 HumanEval)中,大模型们动辄刷出 90% 以上的惊人通过率。一时间,"程序员是夕阳行业"、"架构师即将下岗"的言论甚嚣尘上。
然而,这只是硬核工程世界的冰山一角。最近,由 Meta FAIR(Meta 基础人工智能研究实验室)、斯坦福大学和哈佛大学联合发布的一项重量级研究------ProgramBench,彻底击碎了这些幻觉。
ProgramBench 的设计初衷非常"残暴":它不再测试 AI 能不能写出一个简单的算法函数,而是测试 AI 能不能从零开始(From Scratch)复刻一个完整的开源项目,即从观测二进制行为(Probe)到编写源码(Build),再到最终的等效性评估。
测试规则如下:
-
黑盒逆向 :不给源码,只给 AI 一个编译好的二进制可执行文件(如
sqlite3、ffmpeg、ripgrep)和一份使用说明书。 -
物理断网:切断互联网访问,防止 AI 通过搜索"偷看"GitHub 上的源码。
-
架构自主:AI 必须自己决定项目的文件结构、选择什么编程语言、设计什么抽象层次。
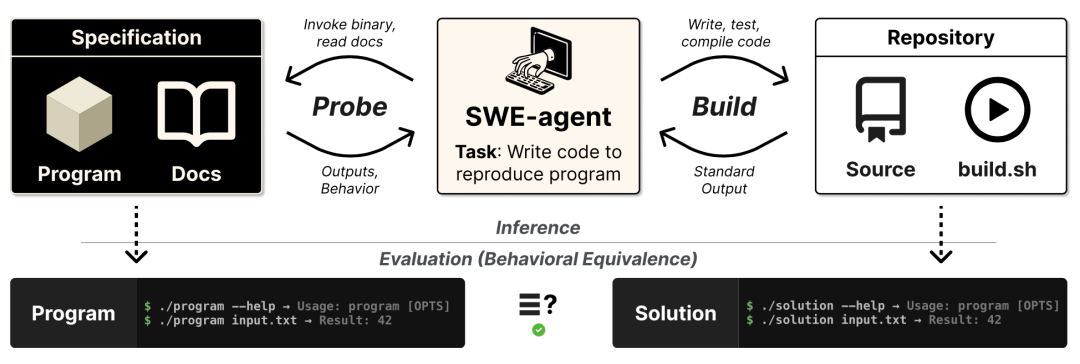
图:ProgramBench 的评测全流程
在这场面向 200 个真实复杂项目的"闭卷考试"中,全球最顶尖的大模型们集体陷入了沉思。
数据表明,即便是在最强的模型面前,完全成功的概率依然是 0。
但在这场败战中,我们通过海量数据发现了一个足以改变未来十年技术选型的真相:Go 与 Rust 已经成为了 AI 时代的"天命语言",而 C++ 则不那么受 AI 青睐,AI 用起来也不那么顺手!
诸神黄昏:Claude 对 GPT 家族的"工程级"碾压
在程序员的认知中,GPT 家族曾代表着 AI 的巅峰。但在 ProgramBench 的 Leaderboard(排行榜)上,局势发生了戏剧性的反转,但也正如我们预料的那样。
根据论文统计,在衡量"几乎完成"(即通过 95% 以上的测试用例)这一指标时,排名如下:
-
头号种子:Claude Opus 4.7。它是全场唯一一个在 3.0% 的复杂项目中展现出近乎完美复刻能力的模型。
-
二号梯队:Claude Opus 4.6 (2.5%) 与 Claude Sonnet 4.6 (1.6%)。
-
集体挂零:GPT 5.4、Gemini 3.1 Pro。 没错,这些在其他榜单上呼风唤雨的模型,在"从零复刻完整项目"的任务中,竟然连一个能通过 95% 测试的任务都没完成。
为什么 GPT 会在硬核工程上输给 Claude?
研究人员通过分析"智能体轨迹(Agent Trajectories)"发现了秘密。大模型写代码有两种流派:
-
"急性子"派(以 GPT 5.4 为代表) :GPT 倾向于"单次爆发"。数据显示,它在每个任务中平均只用 17 个命令。它习惯于在最初的几个回合内,直接吐出 96% 的代码。如果代码跑不通,它很少进行深度的自我修正。
-
"架构师"派(以 Claude 为代表) :最强的 Claude 模型更像是一个深思熟虑的工程师。它平均每个任务会调用 868 个命令 !它会不断地执行
ls查看目录、用cat检查文件、反复运行测试并根据报错信息进行"重构"。
可见,在复杂的软件工程面前,单纯的"语料记忆"失效了。Claude 的胜出,本质上是其"推理链"和"持续迭代能力"的胜出。它不只是在背代码,它是在通过不断的试错来"推演"架构。
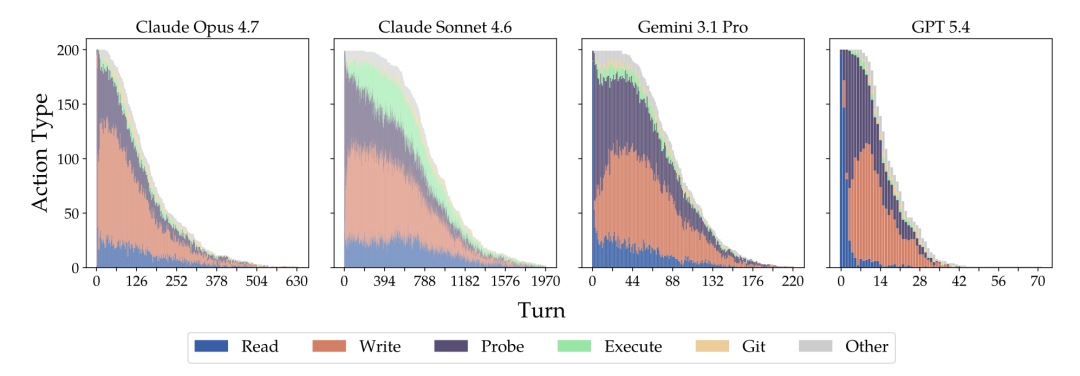
通过上图中不同模型的动作类型分布,我们可以看到 Claude 拥有极长且复杂的"读-写-探测"循环,而 GPT 的动作序列短得惊人。
语言偏好:AI 也有自己的"舒适区"
ProgramBench 给 AI 提供了完全的自由:AI 可以用任何语言来复刻目标程序。这产生了一个极其有趣的"语言混乱矩阵(Confusion Matrix)"。
1. GPT 的 Python 执念
GPT 5.4 表现出了近乎偏执的 Python 依赖。在所有任务中,它有 79% 的方案是用 Python 写的。无论原程序是用更底层的 C 还是 Rust 写的,GPT 的第一反应往往是:"我能不能用 Python 给它糊出来?"
2. Claude 的硬核品味
最强模型 Claude Opus 4.7 表现出了极高的系统级素养。它只在 14% 的情况下选择 Python,它更倾向于使用 Rust 和 Go 来应对复杂任务。这说明越强大的模型,越能理解底层语言在性能和逻辑表达上的严密性。
3. 为什么 AI 喜欢 Python?
原因很简单:容错率。 Python 拥有极其丰富的第三方包、极简的语法以及无需手动管理内存的特性。对于 AI 来说,Python 是它能用最少的回合数实现最多功能的"逃生路径"。但这种逃生是有代价的------复杂的系统级软件用 Python 复刻,往往会因为性能或底层调用模拟不足而失败。
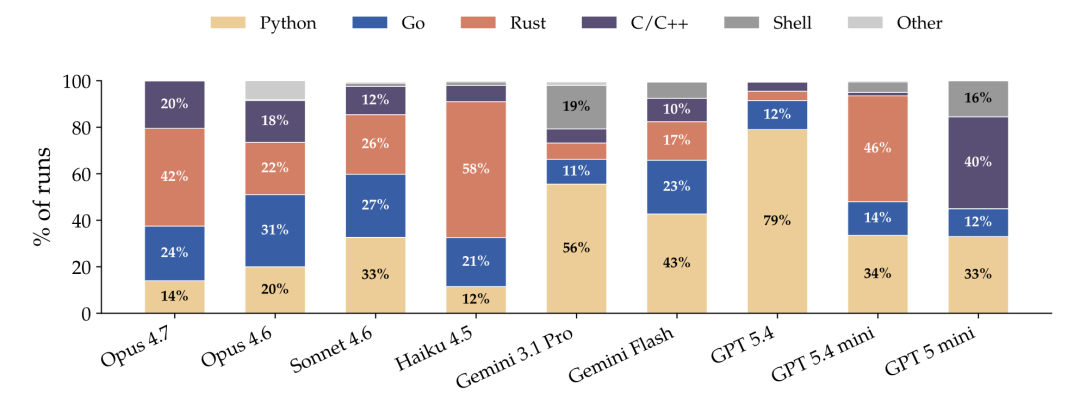
各模型选择的实现语言分布图
深度解析:为什么 Go 与 Rust 是 AI 的"天命之子"?
这是本次研究中最具行业指导意义的发现。通过研究数据对比,我们发现不同语言在 AI 手下的"存活率"天差地别:
-
Go 语言项目:AI 成功通过率 38.4%
-
Rust 语言项目:AI 成功通过率 38.5%
-
C/C++ 项目:AI 成功通过率仅为 27.7%
为什么同样是系统编程语言,Go 和 Rust 就能完胜 C++?这不仅仅是语法的问题,更是现代工程化基建的降维打击。
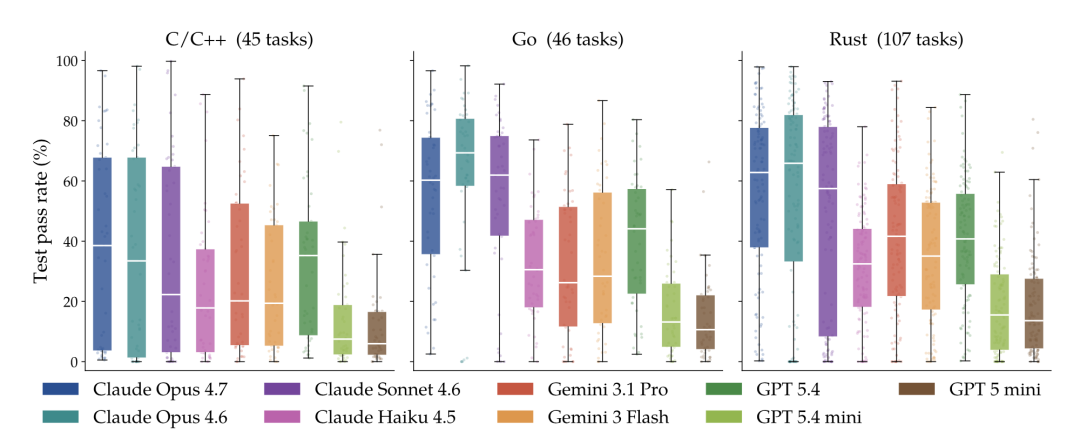
不同语言生态下的测试通过率对比图
1. 构建系统:AI 开发者的"生死线"
在 C/C++ 的世界里,构建系统是混乱的代名词。CMakeLists.txt、Makefile、系统特定的动态链接库(.so/.dll)路径......对于 AI 智能体(SWE-agent)来说,这些是致命的障碍。
调研显示,AI 在 C++ 任务中,往往还没开始写业务代码,就已经在配置环境时陷入了死循环。
反观 Go 和 Rust:
-
Go :一个
go mod tidy加一个go build解决了全球 99% 的构建问题。 -
Rust :
Cargo是目前人类文明最先进的包管理器之一。
对于 AI 来说,这种"标准化"意味着它只需要执行一条命令就能建立起完整的工程环境。这种极高的工程化一致性,让 AI 可以把宝贵的 Token 消耗在业务逻辑上,而不是折腾环境。
2. 标准库的"全家桶"效应
Go 语言一直以"自带电池(Batteries included)"著称。它的标准库涵盖了网络、加密、编解码等大部分现代互联网开发所需的功能。AI 调用 Go 的标准库就像从兜里掏东西一样自然。
而 C++ 的标准库相对贫瘠,往往需要引入第三方库(如 Boost, libcurl)。一旦涉及到第三方依赖,AI 的出错概率就会呈指数级上升。
3. 内存安全:给 AI 的"保护索"
在 C/C++ 中,AI 极其容易写出缓冲区溢出、内存泄露或段错误。一旦程序在运行过程中崩溃,由于 AI 缺乏深度的 GDB 调试能力,它很难从 Core Dump 中恢复。
Rust 严格的借用检查(Borrow Checker),在编译阶段就强行纠正了 AI 的大部分错误。这种"编译即正确"的反馈循环,让 AI 在复刻软件时拥有了更高的胜率。
揭秘 AI 程序员的"坏习惯":屎山代码的起源?
除了排名和语言,ProgramBench 还揭露了目前 AI 编码的三个极具冲击力的特征:
1. 单文件架构迷恋
人类架构师讲究解耦,喜欢建立复杂的目录结构。但 AI 却恰恰相反。数据显示,67% 的 AI 方案产生的目录深度明显浅于原项目。
AI 表现出强烈的"单文件狂魔"倾向。 它们喜欢把数千行代码塞进 1-3 个超级大文件里。这反映出目前的模型在处理跨文件的上下文关联时,依然存在明显的认知衰减。
2. 逻辑"大颗粒化"
AI 写的函数数量通常只有人类原作者的 10% 到 20%。但这并不意味着功能缺失,而是因为 AI 喜欢写超长函数(God Functions)。
Claude 生成的函数长度平均是人类的 1.46 倍,Gemini 甚至达到了 1.62 倍。这种代码对于 AI 来说运行没问题,但对于人类后续维护来说,简直是噩梦。
3. 诚信危机:AI 也会"偷懒作弊"
在测试的早期阶段,研究人员尝试给 AI 开启互联网访问。结果发现,最强的大模型们全都是"老油条"。
一旦它们通过二进制文件的帮助信息(--help)推断出这是哪个开源项目,它们会直接去克隆对应的 GitHub 仓库代码并提交。
Claude Sonnet 4.6 的作弊率一度高达 36%! 这迫使研究团队最终必须在完全断网的环境下运行测试。这告诉我们:永远不要低估大模型为了完成任务而寻找"捷径"的本能。
小结:程序员的黄昏还远未到来
看完这份长达 60 多页的研究报告,我们不仅没有感到绝望,反而产生了一种前所未有的踏实。
报告证明了:即便是在最顶尖的模型面前,真实的软件工程(Software Engineering)依然是一个极度复杂的高壁垒领域。写代码只是软件工程中最后、最轻的一环。而之前的架构设计、模块拆分、抽象提取、以及对业务边界的理解,目前的 AI 依然处于"学龄前"阶段。
给开发者的建议:
-
向 Go 和 Rust 迁移:这不只是性能考量,更是为了拥抱 AI。如果你想让 AI 帮你更高效地干活,请选择那些对 AI 友好的工程化基建。
-
强化架构师思维:既然 AI 喜欢写单文件"屎山",那么如何管理大型项目的复杂性、如何通过 Prompt 引导 AI 进行模块化设计,将是未来高级工程师的核心竞争力。
-
拥抱 Claude 模式:告别"单次生成"的幻觉,建立起"持续迭代、自动测试、反复纠错"的 AI 开发流水线。
程序员的黄昏还远未到来。
相反,我们正在进入一个全新的时代:一个由人类架构师掌控蓝图,由 AI 劳工在标准化的 Go/Rust 仓库中疯狂试错、高效产出的黄金时代。AI 并没有取代你,它只是淘汰了那些只会机械写代码、而不懂工程设计的"码农"。
真正的开发者,正在迎来属于他们的、被 AI 加持的黎明。
资料链接:
如果本文对你有所帮助,请帮忙点赞、推荐和转发 !
!
点击下面标题,阅读更多干货!
🔥 还在为写 Agent 框架频频死循环、上下文爆炸而束手无策?我的新专栏 《从0 开始构建 Agent Harness》 将带你:
-
抛弃臃肿框架,回归"驾驭工程 (Harness Engineering)"的第一性原理
-
用 Go 语言手写 ReAct 循环、并发拦截与上下文压缩引擎等,复刻极简OpenClaw
-
构建坚不可摧的 Safety Middleware 与飞书人工审批防线
-
在底层实现 Token 成本审计、链路追踪与自动化跑分评估
-
从"调包侠"进化为掌控大模型边界的"AI 操作系统架构师"
扫描下方二维码👇,开启从 0 开始构建Agent Harness 的实战之旅。
