【LangGraph】LangGraph 实战(四):预定流程 ------ 中断与人工干预
-
- 一、预定流程架构
-
- [1.1 为什么预定流程不做成子图?](#1.1 为什么预定流程不做成子图?)
- [1.2 流程概览](#1.2 流程概览)
- [1.3 整体流程图](#1.3 整体流程图)
- [1.4 节点说明](#1.4 节点说明)
- [1.5 与推荐子图的对比](#1.5 与推荐子图的对比)
- [二、interrupt 机制详解](#二、interrupt 机制详解)
-
- [2.1 什么是 interrupt?](#2.1 什么是 interrupt?)
- [2.2 interrupt 的工作原理](#2.2 interrupt 的工作原理)
- [2.3 interrupt 的两种用法](#2.3 interrupt 的两种用法)
- [2.4 interrupt 的客户端调用](#2.4 interrupt 的客户端调用)
- 三、循环验证模式
-
- [3.1 为什么需要循环验证?](#3.1 为什么需要循环验证?)
- [3.2 get_title 节点](#3.2 get_title 节点)
- [3.3 get_phone 节点](#3.3 get_phone 节点)
- [3.4 get_id 节点](#3.4 get_id 节点)
- [3.5 取消机制](#3.5 取消机制)
- 四、工具定义与调用
-
- [4.1 自定义工具 generate_orders](#4.1 自定义工具 generate_orders)
- [4.2 ToolRuntime 与 InjectedStore](#4.2 ToolRuntime 与 InjectedStore)
- [4.3 持久化存储逻辑](#4.3 持久化存储逻辑)
- 五、主图中的预定流程集成
-
- [5.1 ReserveState 状态定义](#5.1 ReserveState 状态定义)
- [5.2 add_reserve_message 节点](#5.2 add_reserve_message 节点)
- [5.3 call_orders 节点](#5.3 call_orders 节点)
- [5.4 cancel_node 节点](#5.4 cancel_node 节点)
- [5.5 在主图中添加预定节点](#5.5 在主图中添加预定节点)
- [5.6 条件边配置](#5.6 条件边配置)
- [5.7 路由入口](#5.7 路由入口)
- [六、tools_condition 详解](#六、tools_condition 详解)
-
- [6.1 什么是 tools_condition?](#6.1 什么是 tools_condition?)
- [6.2 判断逻辑](#6.2 判断逻辑)
- 七、执行效果展示
-
- [7.1 正常预定流程](#7.1 正常预定流程)
- [7.2 验证重试示例](#7.2 验证重试示例)
- [7.3 取消预定示例](#7.3 取消预定示例)
- 八、副作用处理最佳实践
-
- [8.1 什么是副作用?](#8.1 什么是副作用?)
- [8.2 预定流程的副作用控制](#8.2 预定流程的副作用控制)
- 九、本文总结
上一章------>【LangGraph】House_Agent 实战(三):推荐子图 ------ 数据库交互与工具调用

一、预定流程架构
1.1 为什么预定流程不做成子图?
在第二篇中我们提到,推荐流程以子图 形式嵌入主图
但预定流程不同------它的节点直接集成在主图中,而不是封装为独立子图
原因在于 interrupt 机制的事件传递:
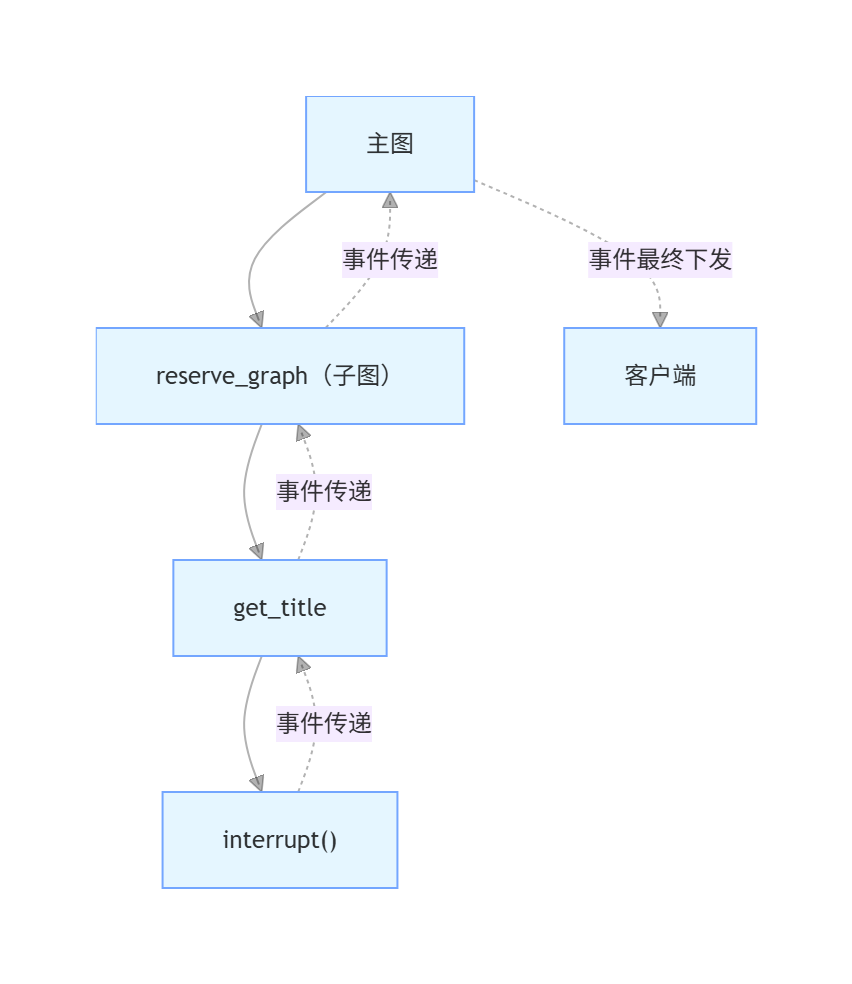
方案A:预定子图(interrupt 事件传递路径长)
方案B:直接节点(interrupt 事件直接到达)
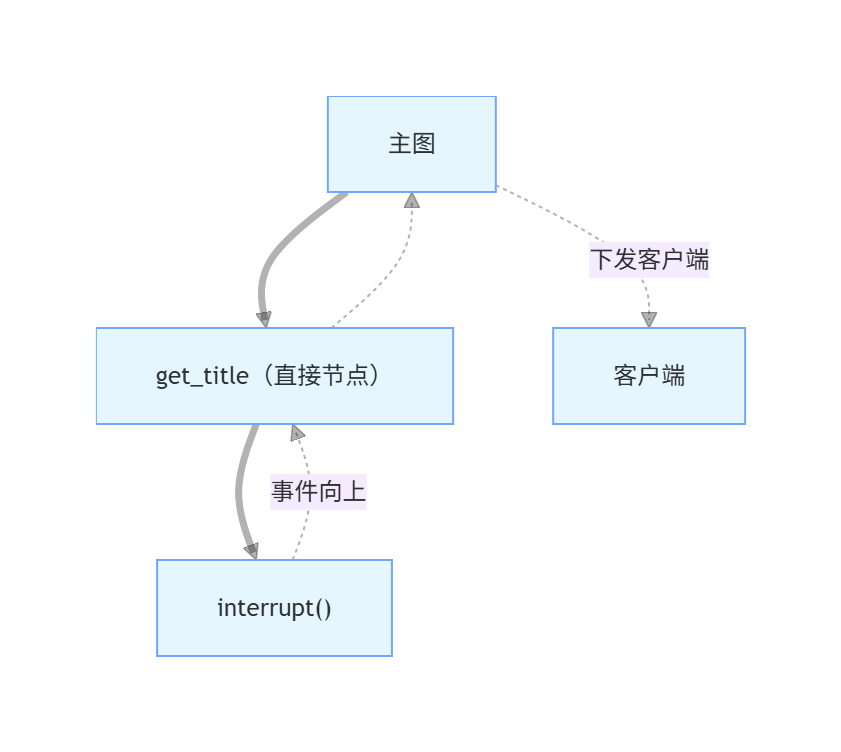
当 interrupt 事件需要从子图传递到主图再到客户端时,事件转发链路变长,增加了调试难度和出错概率,
将预定节点直接放在主图中,interrupt 事件可以直接从主图发出,前端接收更可靠
1.2 流程概览
预定流程负责收集用户信息、生成预定工单
需要多轮人工交互------用户必须依次输入房源名称、手机号、身份证号,每一步都需要验证
主要流程:
- 收集房源名称:用户输入要预定的房源
- 收集手机号:用户输入手机号,格式校验
- 收集身份证号:用户输入身份证号,格式校验
- 生成工单:调用工具生成预定工单并持久化存储
1.3 整体流程图
python
# 生成命令(预定流程节点在主图中,直接打印主图即可)
print(graph.get_graph(xray=True).draw_mermaid())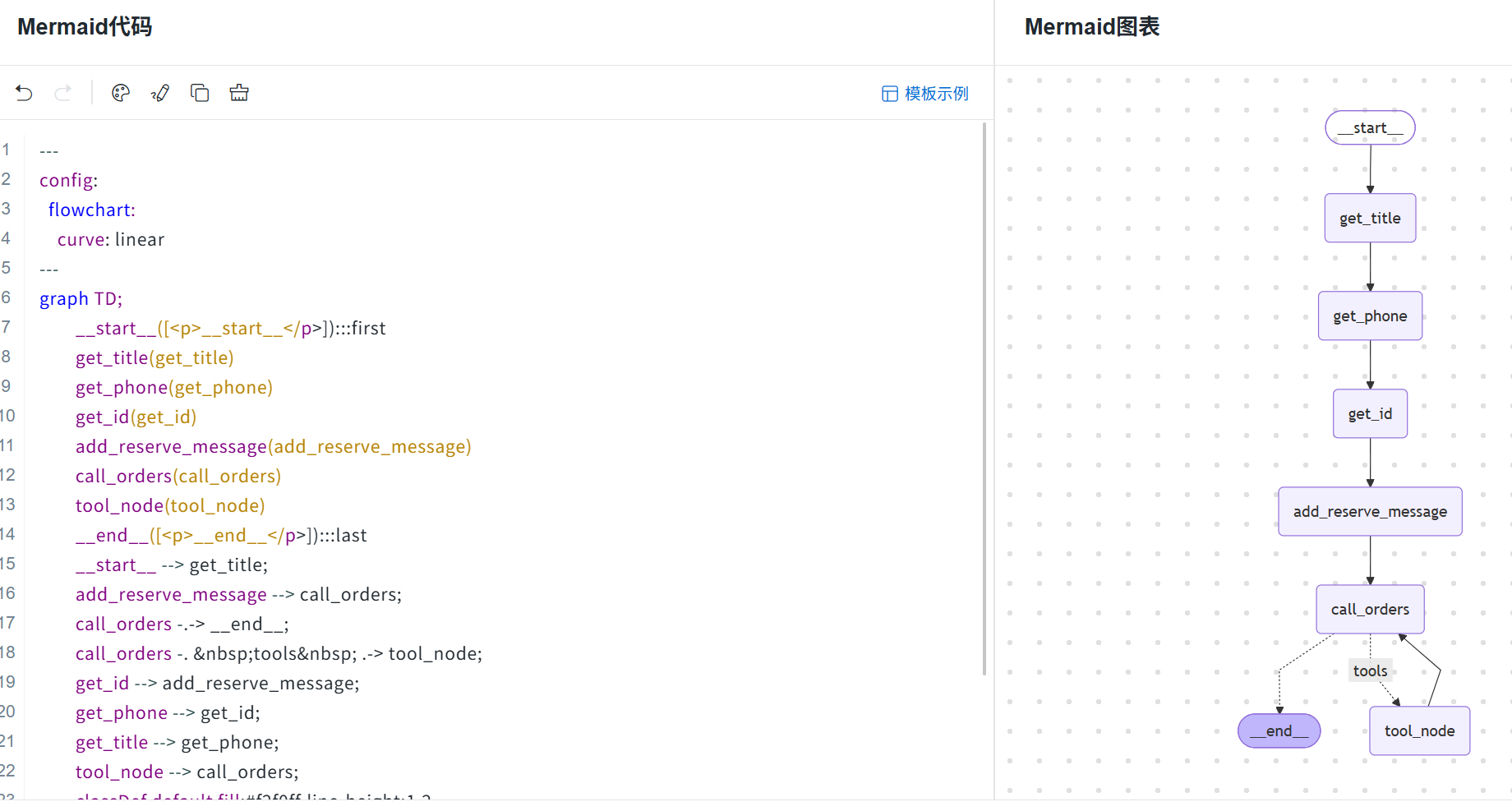
1.4 节点说明
| 节点 | 职责 | 输入 | 输出 |
|---|---|---|---|
get_title |
收集房源名称 | 用户输入(interrupt) | title |
get_phone |
收集手机号 | 用户输入(interrupt) | phone_number |
get_id |
收集身份证号 | 用户输入(interrupt) | id_card |
add_reserve_message |
构建预定消息 | title + phone + id | HumanMessage |
call_orders |
LLM 决定是否调用工具 | 消息列表 | 工具调用或最终回复 |
tool_node |
执行 generate_orders 工具 | 工具调用参数 | 工单结果 |
cancel_node |
取消预定 | - | 取消提示消息 |
1.5 与推荐子图的对比
| 维度 | 推荐子图 | 预定流程 |
|---|---|---|
| 集成方式 | 子图(独立编译) | 主图直接节点 |
| 交互模式 | 单轮查询 | 多轮收集 |
| 核心技术 | SQLDatabaseToolkit | interrupt + ToolNode |
| 循环机制 | SQL 生成→执行循环 | 验证→重试循环 |
| 副作用 | 无 | 生成工单、持久化存储 |
| 工具调用 | 系统内置工具 | 自定义工具 |
二、interrupt 机制详解
2.1 什么是 interrupt?
interrupt 是 LangGraph 提供的人工干预原语
当节点执行到 interrupt() 时,图会暂停执行,等待外部输入
用户输入后,图从暂停点恢复继续执行
python
from langgraph.types import interrupt
def my_node(state):
# 执行到这里时,图会暂停
user_input = interrupt("请输入你的名字:")
# 用户输入后,图恢复执行
return {"name": user_input}执行流程:
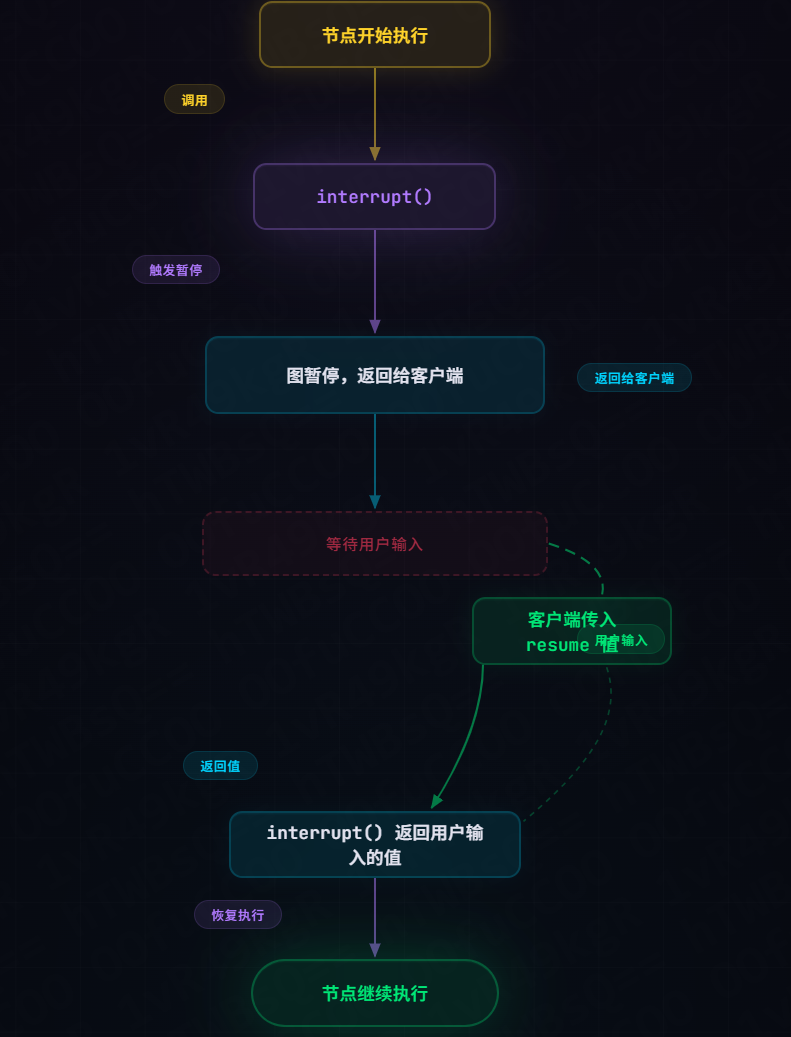
2.2 interrupt 的工作原理
LangGraph 的 interrupt 机制依赖于 Checkpoint(检查点):
- 暂停时:图的状态被保存到 Checkpoint
- 恢复时 :从 Checkpoint 加载状态,将用户输入注入到
interrupt()的返回值 - 继续执行 :节点从
interrupt()处继续执行
这意味着即使服务重启,只要有 Checkpoint,就能恢复到暂停点继续执行
2.3 interrupt 的两种用法
用法一:收集用户输入(本项目使用)
python
def get_title(state):
prompt = '请输入要预定的房源名称'
title = interrupt(prompt) # 等待用户输入
return {"title": title}用法二:人工审核确认
python
def review_node(state):
ai_content = state["generated_content"]
user_decision = interrupt(f"AI 生成的内容:\n{ai_content}\n\n请确认或修改:")
return {"final_content": user_decision}两种用法的核心机制相同,只是语义不同。在预定流程中,interrupt 用于逐步收集信息
2.4 interrupt 的客户端调用
客户端通过 LangGraph API 恢复被中断的图:
python
# 首次调用 - 图会在 interrupt 处暂停
result = graph.invoke({"messages": [HumanMessage("我要预定")]})
# 恢复执行 - 传入用户输入
from langgraph.types import Command
result = graph.invoke(Command(resume="长安花园"), config)在 SSE 流式场景中,客户端会收到一个 interrupt 事件,包含提示信息;用户输入后,发送 resume 请求恢复执行。
三、循环验证模式
3.1 为什么需要循环验证?
用户输入不可信,手机号可能是无效格式,身份证号可能少一位
我们需要在每个收集节点中实现验证-重试循环:
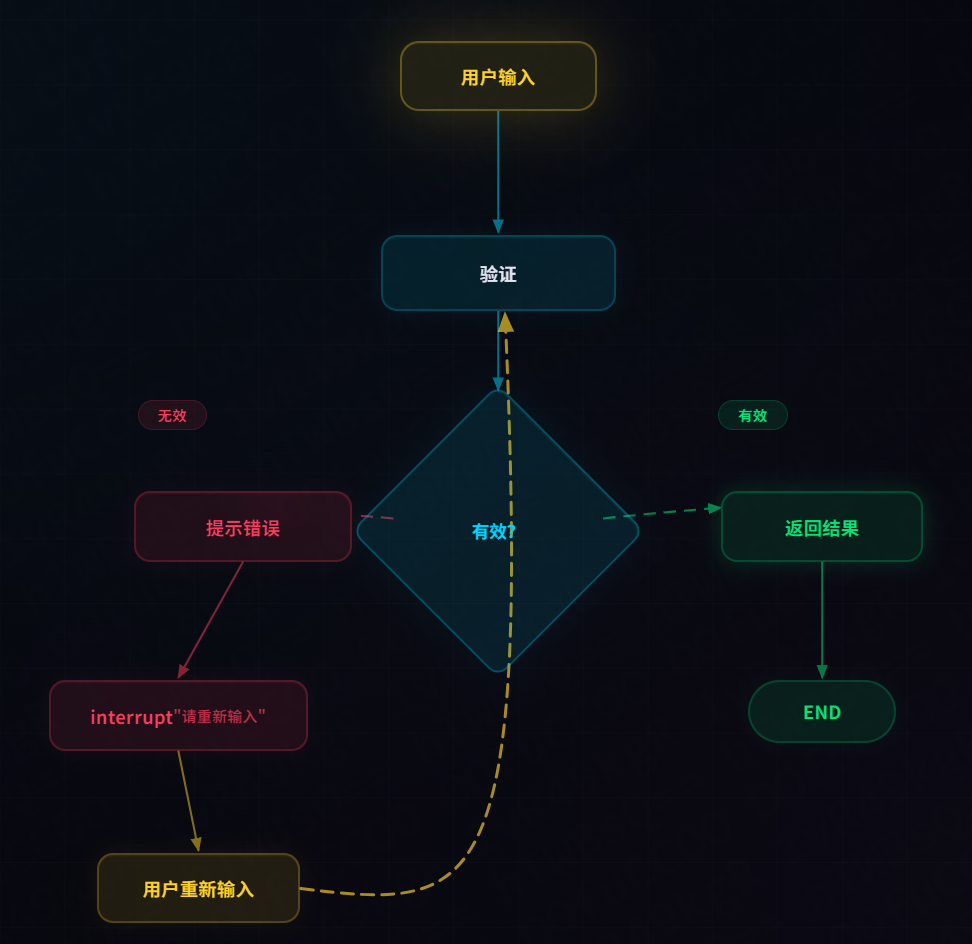
3.2 get_title 节点
python
# src/agent/node/reserve.py
from langgraph.types import interrupt
_CANCEL_KEYWORDS = {"取消", "退出", "不需要", "跳过", "算了"}
def _is_cancel(text: str) -> bool:
return text.strip() in _CANCEL_KEYWORDS
def get_title(state: ReserveState):
prompt = '请输入要预定的房源名称(输入"取消"可退出)'
while True:
title = interrupt(prompt)
if _is_cancel(title):
return {"cancel": True}
if not title or not title.strip():
prompt = "房源名称不能为空,请重新输入。"
else:
return {"title": title.strip()}关键设计:
- while True 循环:节点内部循环验证,直到输入有效才返回
- 取消支持 :检测取消关键词,设置
cancel标志 - 动态提示:验证失败时更新提示信息,引导用户正确输入
- 空值检查:防止用户提交空内容
3.3 get_phone 节点
python
import re
def get_phone(state: ReserveState):
prompt = '请输入要预定的手机号(输入"取消"可退出)'
while True:
phone_number = interrupt(prompt)
if _is_cancel(phone_number):
return {"cancel": True}
if not phone_number or not phone_number.strip():
prompt = "手机号不能为空,请重新输入。"
elif not re.match(r"^1[3-9]\d{9}$", phone_number.strip()):
prompt = f"'{phone_number}' 不是有效的手机号,请输入11位手机号码。"
else:
return {"phone_number": phone_number.strip()}验证规则:
- 不能为空
- 必须匹配
^1[3-9]\d{9}$(11位手机号,以1开头,第二位3-9) - 验证失败时返回具体的错误信息
3.4 get_id 节点
python
def get_id(state: ReserveState):
prompt = '请输入要预定的身份证号码(输入"取消"可退出)'
while True:
id_card = interrupt(prompt)
if _is_cancel(id_card):
return {"cancel": True}
if not id_card or not id_card.strip():
prompt = "身份证号码不能为空,请重新输入。"
elif not re.match(r"^\d{17}[\dXx]$", id_card.strip()):
prompt = f"'{id_card}' 不是有效的身份证号码,请输入18位身份证号码。"
else:
return {"id_card": id_card.strip()}验证规则:
- 不能为空
- 必须匹配
^\d{17}[\dXx]$(18位,前17位数字,最后一位数字或X) - 最后一位支持大小写 X
3.5 取消机制
三个收集节点都支持取消操作:
python
_CANCEL_KEYWORDS = {"取消", "退出", "不需要", "跳过", "算了"}
def _is_cancel(text: str) -> bool:
return text.strip() in _CANCEL_KEYWORDS当用户输入取消关键词时:
- 节点返回
{"cancel": True} - 条件边
_should_continue检查cancel标志 - 跳转到
cancel_node,返回友好的取消提示
python
def _should_continue(state: ReserveState):
return "cancel" if state.get("cancel") else "continue"四、工具定义与调用
4.1 自定义工具 generate_orders
python
# src/agent/node/reserve.py
import uuid
from typing import Annotated, Any
from langchain.tools import tool
from langgraph.prebuilt import ToolNode, ToolRuntime, InjectedStore
from src.agent.common.store import ReservedInfo, UserPreferences
@tool
def generate_orders(
phone_number: str,
id_card: str,
title: str,
runtime: ToolRuntime,
store: Annotated[Any, InjectedStore()]
) -> str:
"""
根据用户电话,身份证,预定房源。
Args:
phone_number: 用户电话
id_card: 身份证
title: 用户要预定的房源标题
runtime: 工具的运行时信息
store: 注入工具的持久存储
"""
# 1. 生成工单号
order_id = str(uuid.uuid4())
# 2. 构建预定信息
reserved_info = ReservedInfo(
order_id=order_id,
phone_number=phone_number,
title=title,
)
# 3. 持久化存储
user_id = runtime.context.get("user_id") if runtime.context else None
if not user_id:
return f"预定失败:无法获取用户信息"
namespace = (user_id, "preferences")
prefs_result = store.search(namespace)
if len(prefs_result) == 0:
# 无持久化信息,新增
prefs = UserPreferences(reserved_info=[reserved_info])
store.put(
namespace,
str(uuid.uuid4()),
prefs.model_dump(exclude_none=True)
)
else:
# 有偏好数据,更新
prefs = prefs_result[0].value or {}
prefs.setdefault("reserved_info", []).append(reserved_info.model_dump())
store.put(namespace, prefs_result[0].key, prefs)
return f"已预定房源为:{title},预定工单号为:{order_id}"4.2 ToolRuntime 与 InjectedStore
这是 LangGraph 提供的两个重要机制:
ToolRuntime :工具的运行时上下文,提供对 context 的访问
python
# 获取运行时上下文中的 user_id
user_id = runtime.context.get("user_id")InjectedStore:将持久化存储注入到工具中
python
# 类型注解方式注入 store
store: Annotated[Any, InjectedStore()]这两个参数不会出现在工具的 schema 中,LLM 不会尝试填充它们------它们由框架在运行时自动注入。
设计意图:
| 参数 | 来源 | 用途 |
|---|---|---|
phone_number |
LLM 工具调用 | 用户电话 |
id_card |
LLM 工具调用 | 身份证号 |
title |
LLM 工具调用 | 房源名称 |
runtime |
框架注入 | 获取 user_id |
store |
框架注入 | 持久化存储 |
4.3 持久化存储逻辑
工具中的存储逻辑遵循查询-更新/新增模式:
python
namespace = (user_id, "preferences")
prefs_result = store.search(namespace)
if len(prefs_result) == 0:
# 首次预定:创建新的偏好记录
prefs = UserPreferences(reserved_info=[reserved_info])
store.put(namespace, str(uuid.uuid4()), prefs.model_dump(exclude_none=True))
else:
# 已有记录:追加预定信息
prefs = prefs_result[0].value or {}
prefs.setdefault("reserved_info", []).append(reserved_info.model_dump())
store.put(namespace, prefs_result[0].key, prefs)Store 的 namespace 设计:
namespace: (user_id, "preferences")
│
├── key: uuid-1
└── value: {
"budget_min": 3000,
"budget_max": 5000,
"reserved_info": [
{"order_id": "xxx", "title": "长安花园", "phone_number": "138..."}
]
}五、主图中的预定流程集成
5.1 ReserveState 状态定义
python
# src/agent/state/reserve.py
from typing import Optional
from langgraph.graph import MessagesState
class ReserveState(MessagesState):
title: Optional[str] = None # 预定的房源
phone_number: Optional[str] = None # 预定电话
id_card: Optional[str] = None # 身份证设计特点:
- 继承
MessagesState,自动拥有messages字段 - 添加三个私有字段用于收集预定信息
- 使用
Optional类型,初始值为None
5.2 add_reserve_message 节点
收集完所有信息后,需要将它们组装成一条消息:
python
# src/agent/node/reserve.py
from langchain_core.messages import HumanMessage
def add_reserve_message(state: ReserveState):
reserve_prompt = """根据提供的信息,帮我预定房源。
- 预定的房源标题: {title}
- 用户预定号码: {phone_number}
- 用户身份证号码: {id_card}"""
reserve_message = HumanMessage(content=reserve_prompt.format(
title=state['title'],
phone_number=state['phone_number'],
id_card=state['id_card']
))
return {"messages": [reserve_message]}为什么需要这个节点?
将结构化的状态字段转换为自然语言消息,供 LLM 理解并决定是否调用工具。
5.3 call_orders 节点
python
# src/agent/node/reserve.py
from langchain_core.messages import SystemMessage
from src.agent.common.llm import model
def call_orders(state: ReserveState):
result = model.bind_tools([generate_orders]).invoke(
[SystemMessage(content="你是一个工单生成的助手,支持调用工具进行房源预定工单生成。"
"支持查看查询的结果并返回最终答案")]
+ state["messages"]
)
return {"messages": [result]}关键点:
- LLM 绑定
generate_orders工具 - LLM 根据消息内容决定是否调用工具
- 如果 LLM 认为信息完整,会生成工具调用
- 如果信息不足,会返回自然语言回复
5.4 cancel_node 节点
python
def cancel_node(state: ReserveState):
return {"messages": [AIMessage(content="已取消预定,如需帮助请随时告诉我~")]}当用户在任何收集步骤中输入取消关键词时,流程跳转到此节点
5.5 在主图中添加预定节点
预定流程的节点直接在 graph.py 中注册:
python
# src/agent/graph.py(预定流程部分)
from src.agent.node.reserve import (
get_title, get_phone, get_id,
add_reserve_message, call_orders,
tool_node, cancel_node, _should_continue
)
# 预定流程节点(直接集成在主图,确保 interrupt 事件能转发到前端)
builder.add_node(get_title)
builder.add_node(get_phone)
builder.add_node(get_id)
builder.add_node(add_reserve_message)
builder.add_node(call_orders)
builder.add_node("tool_node", tool_node)
builder.add_node(cancel_node)5.6 条件边配置
每个收集节点之后都通过 _should_continue 检查是否取消:
python
# 每步检查取消
builder.add_conditional_edges("get_title", _should_continue, {"continue": "get_phone", "cancel": "cancel_node"})
builder.add_conditional_edges("get_phone", _should_continue, {"continue": "get_id", "cancel": "cancel_node"})
builder.add_conditional_edges("get_id", _should_continue, {"continue": "add_reserve_message", "cancel": "cancel_node"})
# 正常流程
builder.add_edge("add_reserve_message", "call_orders")
# 工具调用循环
builder.add_conditional_edges("call_orders", tools_condition, {"tools": "tool_node", "__end__": END})
builder.add_edge("tool_node", "call_orders")
# 取消出口
builder.add_edge("cancel_node", END)流程图:
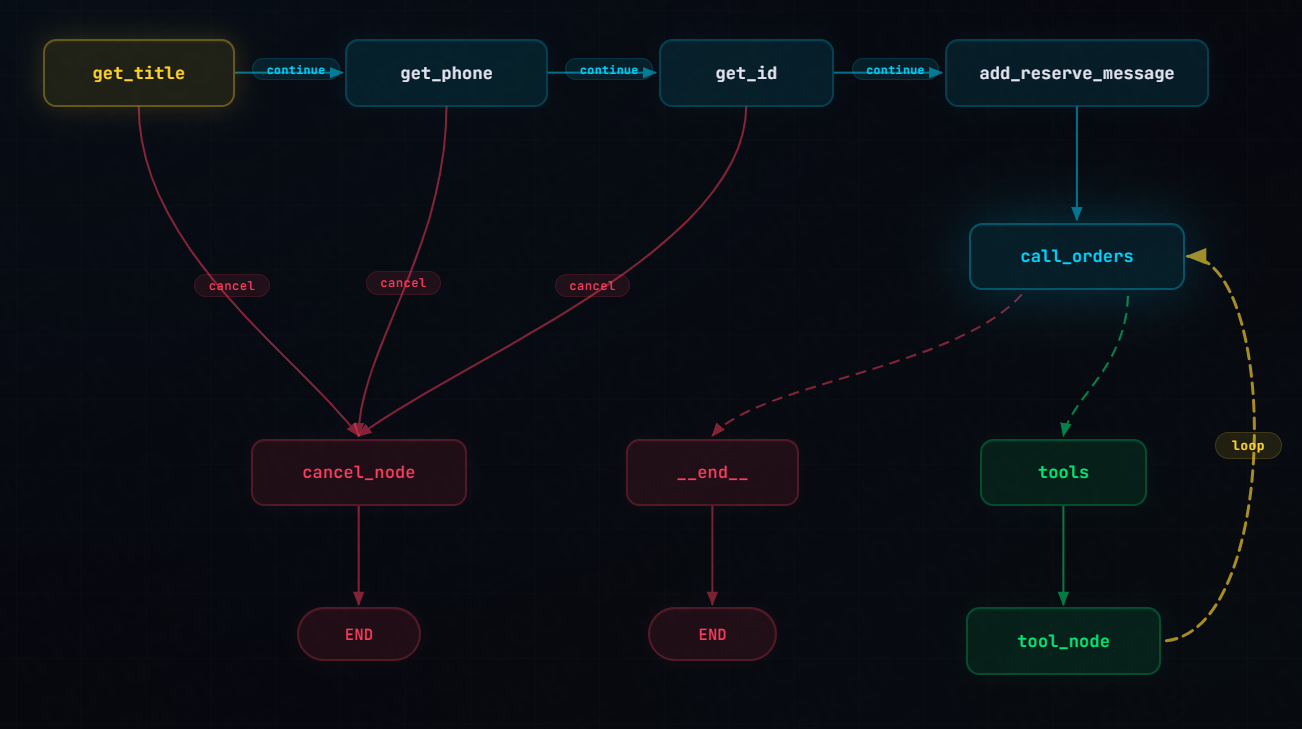
5.7 路由入口
从意图识别和推荐子图都可以进入预定流程:
python
# 意图识别直接路由
def router_message(state):
...
elif user_intent == "reserve_house":
return "get_title" # 直接路由到预定流程
# 推荐完成后的询问
def should_reserve(state):
if state["reserve"] == "需要":
return "get_title" # 跳转到预定流程
else:
return END六、tools_condition 详解
6.1 什么是 tools_condition?
tools_condition 是 LangGraph 内置的条件路由函数,用于判断 LLM 是否生成了工具调用:
python
from langgraph.prebuilt import tools_condition
builder.add_conditional_edges(
"call_orders",
tools_condition, # 内置条件路由
{
"tools": "tool_node", # 有工具调用 → 执行工具
"__end__": END, # 无工具调用 → 结束
}
)6.2 判断逻辑
python
# 简化版实现
def tools_condition(state):
last_message = state["messages"][-1]
if last_message.tool_calls:
return "tools" # LLM 生成了工具调用
else:
return "__end__" # LLM 返回了最终回复工作流程:
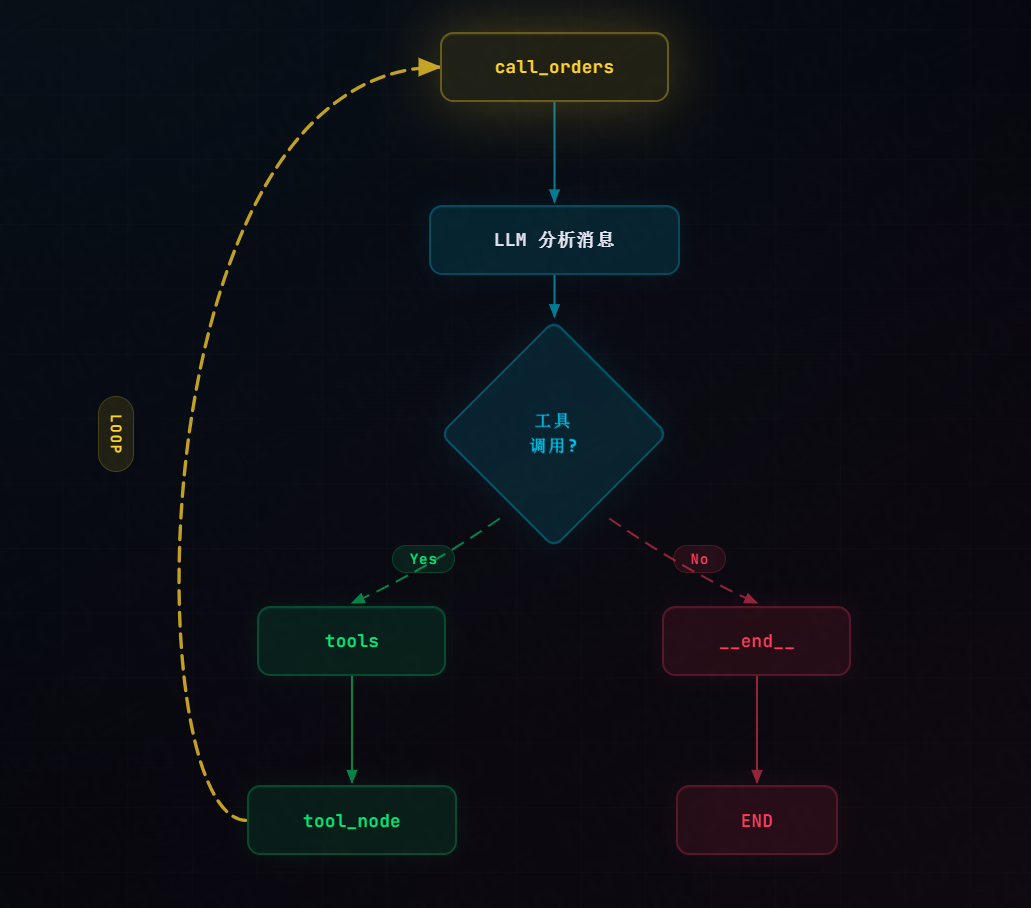
七、执行效果展示
7.1 正常预定流程
(此处留白,插入实际运行效果)
示例对话:
系统:请输入要预定的房源名称(输入"取消"可退出)
用户:长安花园
系统:请输入要预定的手机号(输入"取消"可退出)
用户:13800138000
系统:请输入要预定的身份证号码(输入"取消"可退出)
用户:110101199001011234
助手:已预定房源为:长安花园,预定工单号为:a1b2c3d4-e5f6-7890-abcd-ef12345678907.2 验证重试示例
系统:请输入要预定的手机号(输入"取消"可退出)
用户:abc
系统:'abc' 不是有效的手机号,请输入11位手机号码。
用户:123
系统:'123' 不是有效的手机号,请输入11位手机号码。
用户:13800138000
系统:请输入要预定的身份证号码(输入"取消"可退出)7.3 取消预定示例
系统:请输入要预定的房源名称(输入"取消"可退出)
用户:取消
助手:已取消预定,如需帮助请随时告诉我~八、副作用处理最佳实践
8.1 什么是副作用?
在 Agent 开发中,副作用(Side Effect) 指的是对外部系统产生影响的操作:
| 操作 | 副作用类型 | 风险等级 |
|---|---|---|
| 查询数据库 | 只读 | 低 |
| 生成工单 | 写入 | 高 |
| 发送通知 | 不可逆 | 高 |
| 调用支付接口 | 资金变动 | 极高 |
8.2 预定流程的副作用控制
在预定流程中,副作用被集中在 generate_orders 工具中:
设计要点:
- 收集阶段无副作用:get_title、get_phone、get_id 只做输入收集和验证
- 工具层执行副作用:generate_orders 是唯一的写入操作
- LLM 作为决策层:call_orders 让 LLM 决定是否执行工具,增加了灵活性
- 可追溯记录:每笔预定生成唯一的 order_id(UUID)
九、本文总结
本文详细介绍了预定流程的实现:
- 为什么不做子图:interrupt 事件直接从主图发出,传递更可靠
- interrupt 机制:暂停执行等待人工输入,依赖 Checkpoint 实现状态保存
- 循环验证模式:while True + interrupt 实现输入验证和重试
- 自定义工具:generate_orders 工具的定义和持久化逻辑
- ToolRuntime 与 InjectedStore:框架自动注入的运行时参数
- tools_condition:内置的工具调用条件路由
- 副作用处理:收集阶段无副作用,工具层执行写入操作
下一篇文章 :
我们将深入探讨持久化、流式输出与部署,学习如何让 Agent 在生产环境中稳定运行
本文是 House_Agent 实战系列的第二篇
如果觉得有帮助,欢迎点赞和分享!
咱们下篇再见~~~~
