文章目录
- [1. 模块概述](#1. 模块概述)
-
- [1.1 模块定位](#1.1 模块定位)
- [1.2 核心能力](#1.2 核心能力)
- [1.3 模块依赖关系](#1.3 模块依赖关系)
- [2. 架构设计](#2. 架构设计)
-
- [2.1 统一接口契约](#2.1 统一接口契约)
- [2.2 节点生命周期](#2.2 节点生命周期)
- [2.3 状态交互模型](#2.3 状态交互模型)
- [3. 节点分类与实现详情](#3. 节点分类与实现详情)
-
- [3.1 AI 交互类节点](#3.1 AI 交互类节点)
-
- [3.1.1 LlmNode - LLM 对话节点](#3.1.1 LlmNode - LLM 对话节点)
- [3.1.2 AgentNode - Agent 推理节点](#3.1.2 AgentNode - Agent 推理节点)
- [3.1.3 ToolNode - 工具执行节点](#3.1.3 ToolNode - 工具执行节点)
- [3.2 数据处理类节点](#3.2 数据处理类节点)
-
- [3.2.1 AssignerNode - 变量赋值节点](#3.2.1 AssignerNode - 变量赋值节点)
- [3.2.2 TemplateTransformNode - 模板转换节点](#3.2.2 TemplateTransformNode - 模板转换节点)
- [3.2.3 ListOperatorNode - 列表操作节点](#3.2.3 ListOperatorNode - 列表操作节点)
- [3.3 知识获取类节点](#3.3 知识获取类节点)
-
- [3.3.1 KnowledgeRetrievalNode - 知识库检索节点](#3.3.1 KnowledgeRetrievalNode - 知识库检索节点)
- [3.3.2 DocumentExtractorNode - 文档解析节点](#3.3.2 DocumentExtractorNode - 文档解析节点)
- [3.4 外部集成类节点](#3.4 外部集成类节点)
-
- [3.4.1 HttpNode - HTTP 请求节点](#3.4.1 HttpNode - HTTP 请求节点)
- [3.4.2 McpNode - MCP 协议节点](#3.4.2 McpNode - MCP 协议节点)
- [3.4.3 CodeExecutorNodeAction - 代码执行节点](#3.4.3 CodeExecutorNodeAction - 代码执行节点)
- [3.5 流程控制类节点](#3.5 流程控制类节点)
-
- [3.5.1 IterationNode - 循环迭代节点](#3.5.1 IterationNode - 循环迭代节点)
- [3.5.2 QuestionClassifierNode - 问题分类节点](#3.5.2 QuestionClassifierNode - 问题分类节点)
- [3.6 结构化提取节点](#3.6 结构化提取节点)
-
- [3.6.1 ParameterParsingNode - 参数解析节点](#3.6.1 ParameterParsingNode - 参数解析节点)
- [3.6.2 VariableAggregatorNode - 变量聚合节点](#3.6.2 VariableAggregatorNode - 变量聚合节点)
- [3.7 人机交互节点](#3.7 人机交互节点)
-
- [3.7.1 HumanNode - 人工介入节点](#3.7.1 HumanNode - 人工介入节点)
- [3.7.2 AnswerNode - 答案生成节点](#3.7.2 AnswerNode - 答案生成节点)
- [4. 核心设计模式](#4. 核心设计模式)
-
- [4.1 Builder 模式](#4.1 Builder 模式)
- [4.2 变量替换模式](#4.2 变量替换模式)
- [4.3 策略模式](#4.3 策略模式)
- [4.4 模板方法模式](#4.4 模板方法模式)
- [5. 通用工具与基础设施](#5. 通用工具与基础设施)
-
- [5.1 InMemoryFileStorage - 内存文件存储](#5.1 InMemoryFileStorage - 内存文件存储)
- [5.2 FileUtils - 文件工具](#5.2 FileUtils - 文件工具)
- [5.3 CodeUtils - 代码工具](#5.3 CodeUtils - 代码工具)
- [6. 使用示例](#6. 使用示例)
-
- [6.1 完整工作流示例:客服问答系统](#6.1 完整工作流示例:客服问答系统)
- [6.2 HTTP + 模板转换组合](#6.2 HTTP + 模板转换组合)
- [6.3 代码执行节点使用](#6.3 代码执行节点使用)
- [7. 扩展指南](#7. 扩展指南)
-
- [7.1 自定义节点开发](#7.1 自定义节点开发)
- [7.2 添加新的代码语言支持](#7.2 添加新的代码语言支持)
- [8. 最佳实践](#8. 最佳实践)
-
- [8.1 节点设计原则](#8.1 节点设计原则)
- [8.2 变量命名规范](#8.2 变量命名规范)
- [8.3 错误处理最佳实践](#8.3 错误处理最佳实践)
- [8.4 性能优化建议](#8.4 性能优化建议)
- 附录:节点速查表
1. 模块概述
1.1 模块定位
spring-ai-alibaba-starter-builtin-nodes 是 Spring AI Alibaba 生态系统中的核心组件,提供了一套开箱即用的工作流节点实现。这些节点覆盖了 AI 应用开发中最常见的场景,包括 LLM 调用、工具执行、HTTP 请求、数据转换、知识库检索等。
模块位置 : spring-boot-starters/spring-ai-alibaba-starter-builtin-nodes/
源码结构:
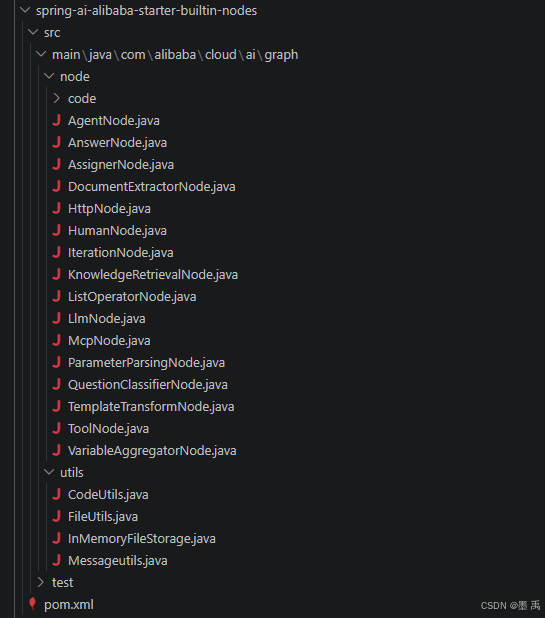
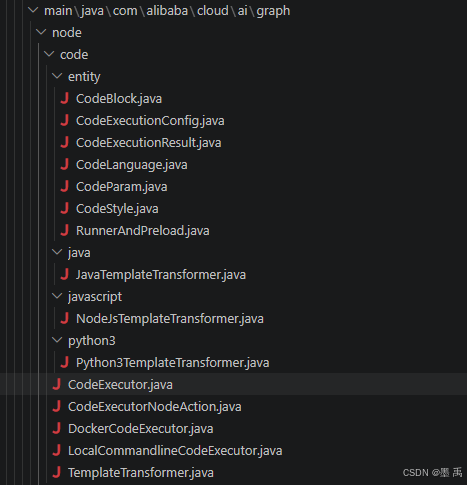
code 包:
1.2 核心能力
| 能力分类 | 描述 | 代表节点 |
|---|---|---|
| AI 交互 | LLM 对话、Agent 推理、工具调用 | LlmNode, AgentNode, ToolNode |
| 数据处理 | 变量赋值、模板转换、列表操作 | AssignerNode, TemplateTransformNode, ListOperatorNode |
| 知识获取 | 知识库检索、文档解析 | KnowledgeRetrievalNode, DocumentExtractorNode |
| 外部集成 | HTTP 请求、MCP 协议、代码执行 | HttpNode, McpNode, CodeExecutorNodeAction |
| 流程控制 | 循环迭代、条件分类 | IterationNode, QuestionClassifierNode |
| 人机交互 | 人工介入、答案生成 | HumanNode, AnswerNode |
| 结构化提取 | 参数解析、变量聚合 | ParameterParsingNode, VariableAggregatorNode |
1.3 模块依赖关系
spring-ai-alibaba-starter-builtin-nodes
├── spring-ai-alibaba-graph-core (核心依赖)
│ ├── NodeAction 接口
│ ├── OverAllState 状态管理
│ └── Checkpoint 机制
├── Spring AI (ChatClient, VectorStore)
├── Model Context Protocol (MCP)
├── Apache Tika (文档解析)
└── WebClient (HTTP 客户端)2. 架构设计
2.1 统一接口契约
所有节点都实现 NodeAction 接口,确保执行模式的一致性:
java
public interface NodeAction {
Map<String, Object> apply(OverAllState state) throws Exception;
}设计要点:
- 输入:
OverAllState- 图执行的完整状态 - 输出:
Map<String, Object>- 需要更新到状态的键值对 - 异常:允许抛出受检异常,由执行器统一处理
2.2 节点生命周期
构建阶段 (Builder)
↓
初始化 (构造函数)
↓
执行前 (变量替换)
↓
核心逻辑 (apply)
↓
结果处理 (状态更新)
↓
返回输出 Map2.3 状态交互模型
┌─────────────────────────────────────────────────────────┐
│ OverAllState │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ messages │ │ user_input │ │ custom │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
└─────────────────────────────────────────────────────────┘
↑
│ 读取/写入
↓
┌─────────────────────────────────────────────────────────┐
│ Node Action │
│ ┌───────────────────────────────────────────────────┐ │
│ │ 1. 从 state 读取变量 (state.value(key)) │ │
│ │ 2. 执行核心业务逻辑 │ │
│ │ 3. 构造输出 Map {outputKey: result} │ │
│ └───────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘3. 节点分类与实现详情
3.1 AI 交互类节点
3.1.1 LlmNode - LLM 对话节点
核心功能:调用大语言模型进行对话生成,支持流式输出和工具调用。
关键配置:
java
public class LlmNode implements NodeAction {
private final ChatClient chatClient; // Spring AI ChatClient
private final ToolCallback[] toolCallbacks; // 工具回调
private final String systemPrompt; // 系统提示词
private final String userPrompt; // 用户提示词(支持 ${key} 变量)
private final String outputKey; // 输出键名
private final boolean stream; // 是否流式输出
private final StructuredOutputSchema outputSchema; // 输出结构
}执行流程:
- 变量替换:将
systemPrompt和userPrompt中的${key}替换为 state 中的实际值 - 构建
ChatClient请求 - 配置工具回调(如果有)
- 执行调用(流式或阻塞)
- 将结果写入
outputKey或messages
变量替换机制:
java
// 使用正则表达式匹配 ${variable} 模式
private static final Pattern VARIABLE_PATTERN = Pattern.compile("\\$\\{(.+?)\\}");
private String replaceVariables(String template, OverAllState state) {
Matcher matcher = VARIABLE_PATTERN.matcher(template);
StringBuilder result = new StringBuilder();
while (matcher.find()) {
String key = matcher.group(1);
Object value = state.value(key).orElse("");
matcher.appendReplacement(result, value.toString());
}
matcher.appendTail(result);
return result.toString();
}3.1.2 AgentNode - Agent 推理节点
核心功能:实现 ReAct 和 Tool Calling 两种 Agent 策略,支持多轮推理。
策略枚举:
java
public enum Strategy {
REACT, // 思考-行动循环模式
TOOL_CALLING // 工具调用模式
}关键特性:
maxIterations:最大迭代次数,防止无限循环retryTemplate:重试机制配置- 自动管理
messages状态 - 工具执行结果自动追加到对话历史
执行流程(ReAct 模式):
开始
↓
构建系统提示词 (包含工具描述)
↓
循环直到达到 maxIterations:
├─ 调用 LLM 生成思考和行动
├─ 解析工具调用请求
├─ 执行工具
├─ 将工具结果追加到 messages
└─ 检查是否需要继续
↓
生成最终回答
↓
结束3.1.3 ToolNode - 工具执行节点
核心功能:专门执行 LLM 返回的工具调用请求,支持动态工具解析。
关键配置:
java
public class ToolNode implements NodeAction {
private final ToolCallback[] toolCallbacks;
private final ToolCallbackResolver toolCallbackResolver; // 动态工具解析
private final String outputKey;
}设计特点:
- 从 state 中读取上一轮 LLM 输出的工具调用请求
- 支持静态注册和动态解析两种工具获取方式
- 执行结果格式化为 LLM 可理解的消息格式
3.2 数据处理类节点
3.2.1 AssignerNode - 变量赋值节点
核心功能:灵活的状态变量管理,支持多种写入模式。
写入模式:
java
public enum WriteMode {
OVER_WRITE, // 覆盖写入
APPEND, // 追加模式
CLEAR, // 清空模式
INPUT_CONSTANT // 常量输入
}配置项:
java
public record AssignItem(
String targetKey, // 目标键名
String inputKey, // 输入源键名(state 中)
WriteMode writeMode, // 写入模式
Object inputValue // 常量值(INPUT_CONSTANT 模式使用)
)使用场景:
- 状态初始化:
INPUT_CONSTANT模式设置初始值 - 数据传递:将一个节点的输出重命名为另一个节点的输入
- 列表累积:
APPEND模式收集多轮结果
3.2.2 TemplateTransformNode - 模板转换节点
核心功能 :基于 OGNL 表达式的强大模板引擎,支持复杂的状态数据提取和转换。
语法特性:
| 语法 | 示例 | 说明 |
|---|---|---|
| 变量引用 | {``{user_name}} |
直接引用 state 中的键 |
| 嵌套属性 | {``{http_response.body.user.name}} |
嵌套对象属性访问 |
| 数组索引 | {``{messages[0].content}} |
列表/数组元素访问 |
| Elvis 操作符 | {``{name ?: "Unknown"}} |
空值默认值 |
| 条件表达式 | {``{score > 60 ? "Pass" : "Fail"}} |
三元运算符 |
| 方法调用 | {``{items.size()}} |
调用对象方法 |
核心实现:
java
private static final Pattern PATTERN = Pattern.compile("\\{\\{(.+?)\\}\\}");
public Map<String, Object> apply(OverAllState state) {
Matcher matcher = PATTERN.matcher(template);
StringBuffer sb = new StringBuffer();
while (matcher.find()) {
String expression = matcher.group(1);
// 使用 OGNL 求值
Object value = Ognl.getValue(expression, buildRoot(state));
matcher.appendReplacement(sb, String.valueOf(value));
}
matcher.appendTail(sb);
return Map.of(outputKey, sb.toString());
}智能 JSON 解析:
- 自动检测字符串值是否为 JSON 格式
- 自动解析为 Map 或 List,支持链式属性访问
3.2.3 ListOperatorNode - 列表操作节点
核心功能:对列表数据进行过滤、排序、分页等操作。
操作类型:
java
public enum OperationType {
FILTER, // 过滤
SORT, // 排序
LIMIT, // 限制数量
DISTINCT // 去重
}输入输出模式:
java
public enum IOType {
JSON_STR, // JSON 字符串格式
LIST, // Java List 对象
ARRAY // 数组格式
}过滤表达式:
- 支持多条件组合
- 支持比较运算符:
>,<,>=,<=,==,!= - 支持逻辑运算符:
&&,||
3.3 知识获取类节点
3.3.1 KnowledgeRetrievalNode - 知识库检索节点
核心功能 :基于向量相似度的知识库检索,可选 Rerank 重排序。
配置项:
java
public class KnowledgeRetrievalNode implements NodeAction {
private String userPromptKey; // 用户问题键
private String topKKey = "top_k"; // 检索数量键
private Double similarityThreshold; // 相似度阈值
private Boolean enableRanker = false; // 是否启用重排序
private VectorStore vectorStore; // 向量存储
private ChatModel chatModel; // 用于 Rerank
}检索流程:
- 从
state读取用户问题 - 调用
VectorStore进行相似度搜索 - 应用相似度阈值过滤
- (可选)调用
DashScope Rerank进行重排序 - 将检索到的文档追加到用户提示词后
3.3.2 DocumentExtractorNode - 文档解析节点
核心功能:多格式文档内容提取,支持本地和远程文件。
支持格式:
PDF、Word、Excel、PowerPoint(Apache Tika)HTML、Markdown、JSON、YAML- 纯文本文件
文件源类型:
java
public enum FileSourceType {
LOCAL_PATH, // 本地文件路径
NETWORK_URL, // 网络 URL
BASE64_STRING // Base64 编码字符串
}解析流程:
识别文件源类型
↓
获取文件内容(下载/读取)
↓
根据文件扩展名选择解析器
↓
调用 Tika 解析文档
↓
返回提取的文本内容3.4 外部集成类节点
3.4.1 HttpNode - HTTP 请求节点
核心功能:功能完整的 HTTP 客户端,支持认证、文件上传、重试。
支持的 HTTP 方法:
GET,POST,PUT,DELETE,PATCH,HEAD,OPTIONS
认证类型:
java
public enum AuthType {
NONE, // 无认证
BASIC, // Basic 认证
BEARER // Bearer Token
}请求体类型:
java
public enum BodyType {
NONE, // 无 Body
FORM_DATA, // multipart/form-data
X_WWW_FORM_URLENCODED, // application/x-www-form-urlencoded
RAW_TEXT, // 纯文本
JSON, // JSON
BINARY // 二进制文件
}重试配置:
java
public record RetryConfig(
int maxAttempts, // 最大重试次数
long delayMillis, // 初始延迟
double multiplier, // 延迟乘数(指数退避)
Set<Integer> retryStatuses // 需要重试的 HTTP 状态码
)执行流程:
URL、Headers、Query参数变量替换- 构建
WebClient请求 - 应用认证配置
- 处理请求体(包括文件上传)
- 执行请求(带重试机制)
- 解析响应为
{status, headers, body, files}
文件处理:
- 上传:支持通过 state 中的文件
ID引用InMemoryFileStorage中的文件 - 下载:响应文件保存到
InMemoryFileStorage,返回文件ID
3.4.2 McpNode - MCP 协议节点
核心功能:Model Context Protocol 客户端,调用 MCP Server 提供的工具。
MCP 协议栈:
┌─────────────────────────────────────────┐
│ MCP Client (io.modelcontextprotocol) │
├─────────────────────────────────────────┤
│ SSE Transport (HttpClientSseClient) │
├─────────────────────────────────────────┤
│ JSON-RPC 2.0 over HTTP/SSE │
└─────────────────────────────────────────┘关键配置:
java
public class McpNode implements NodeAction {
private final String url; // MCP Server URL
private final String tool; // 工具名称
private final Map<String, String> headers; // 请求头(用于认证)
private final Map<String, Object> params; // 工具参数
private final List<String> inputParamKeys; // 从 state 读取的参数键
private final String outputKey; // 输出键
}执行流程:
- 构建
HttpClientSseClientTransport - 初始化
McpSyncClient(发送initialize请求) - 变量替换:工具名和参数
- 调用工具:
client.callTool(request) - 解析
CallToolResult,提取文本内容 - 写入
state
3.4.3 CodeExecutorNodeAction - 代码执行节点
核心功能 :沙箱环境中执行用户代码,支持 Python、JavaScript、Java。
执行器实现:
java
public interface CodeExecutor {
CodeExecutionResult executeCodeBlocks(
List<CodeBlock> codeBlocks,
CodeExecutionConfig config
);
}可用执行器:
| 执行器 | 描述 | 隔离级别 |
|---|---|---|
LocalCommandlineCodeExecutor |
本地命令行执行 | 低 |
DockerCodeExecutor |
Docker 容器执行 | 高 |
支持的语言:
java
public enum CodeLanguage {
PYTHON3("python3"),
PYTHON("python"),
JAVASCRIPT("javascript"),
JAVA("java"),
JINJA2("jinja2")
}代码风格:
java
public enum CodeStyle {
EXPLICIT_PARAMETERS, // def main(x: int, y: int) -> dict:
GLOBAL_DICTIONARY // def main(): x = params['x']
}参数传递:
java
public record CodeParam(
String argName, // 代码中的参数名
Object value, // 直接值(优先级高)
String stateKey // 从 state 读取的键名(优先级低)
)模板转换流程 (以 Python 为例):
用户代码片段
↓
TemplateTransformer.transformCaller()
↓
包装为完整可执行脚本(注入参数、设置输出格式)
↓
执行器执行代码
↓
TemplateTransformer.transformResponse()
↓
解析输出为 Map<String, Object>3.5 流程控制类节点
3.5.1 IterationNode - 循环迭代节点
核心功能:对数组中的每个元素执行子流程,聚合最终结果。
节点类型:
- IterationStartNode:迭代开始,读取数组,初始化索引
- IterationEndNode:迭代结束,检查完成状态,聚合结果
状态管理:
迭代状态存储在 state 中:
{
"iteration_array": [...], // 待迭代的数组
"iteration_index": 0, // 当前索引
"iteration_results": [], // 已收集的结果
"iteration_current_item": {...} // 当前元素
}执行流程:
IterationStart:
├─ 读取 inputKey 对应的数组(支持 List 或 JSON 字符串)
├─ 初始化 index = 0
└─ 将当前元素写入 iteration_current_item
→ 执行中间的子流程节点
IterationEnd:
├─ 收集当前轮次的结果
├─ index++
├─ 检查是否还有下一个元素
│ ├─ 有:继续下一轮(回到 Start)
│ └─ 无:输出聚合结果
└─ 清理迭代状态3.5.2 QuestionClassifierNode - 问题分类节点
核心功能 :基于 Few-shot 学习的意图分类,将用户问题路由到不同处理分支。
分类逻辑:
- 硬编码
2个示例(可扩展) - 构建分类提示词模板
- 调用
LLM生成分类结果 - 解析输出:提取分类键和关键词
输出格式:
java
{
"category": "技术问题", // 分类结果
"keywords": ["Spring", "AI"] // 提取的关键词(可选)
}3.6 结构化提取节点
3.6.1 ParameterParsingNode - 参数解析节点
核心功能:从自然语言中提取结构化参数,用于表单填充或 API 调用。
工作原理:
Few-shot学习:2 个示例演示提取模式- 输出结构约束:
JSON Schema定义参数结构 LLM生成符合Schema的JSON输出
输出格式:
java
{
"data": { // 提取的参数
"name": "张三",
"age": 25,
"email": "zhang@example.com"
},
"is_success": true, // 是否成功
"reason": "提取成功" // 失败原因(可选)
}3.6.2 VariableAggregatorNode - 变量聚合节点
核心功能:将多个状态路径的值聚合为列表或其他格式。
聚合模式:
java
public enum OutputType {
LIST, // 输出为 List<Object>
STRING_JOIN // 输出为换行连接的字符串
}使用场景:
- 收集多轮对话的关键信息
- 将多个节点的输出合并为一个列表输入
- 生成摘要前的数据聚合
3.7 人机交互节点
3.7.1 HumanNode - 人工介入节点
核心功能 :支持 Human-in-the-loop,在关键决策点暂停执行等待人工反馈。
中断策略:
java
public enum InterruptStrategy {
ALWAYS, // 每次执行都中断
CONDITIONED // 满足条件时中断
}状态更新钩子:
java
@FunctionalInterface
public interface StateUpdateFunction {
Map<String, Object> apply(
OverAllState currentState,
Map<String, Object> humanFeedback
);
}注意 :该节点当前处于注释状态,可能正在进行重构。建议使用 Graph Core 层的 InterruptableAction 接口实现自定义中断逻辑。
3.7.2 AnswerNode - 答案生成节点
核心功能:简单的模板替换,从状态变量生成最终回答。
模板语法 :使用 {key} 占位符,示例:
"您好,{user_name}!您的订单 {order_id} 已处理完成。"4. 核心设计模式
4.1 Builder 模式
所有节点都采用 Builder 模式构建,确保:
- 不可变对象(字段为
final) - 可选参数的灵活配置
- 类型安全的构建过程
统一模式:
java
public class XxxNode implements NodeAction {
// 所有字段都是 final
private final String requiredParam;
private final Integer optionalParam;
// 私有构造函数
private XxxNode(Builder builder) {
this.requiredParam = builder.requiredParam;
this.optionalParam = builder.optionalParam;
}
// 静态 builder 入口
public static Builder builder() {
return new Builder();
}
public static class Builder {
private String requiredParam;
private Integer optionalParam = 10; // 默认值
// 链式调用方法
public Builder requiredParam(String value) {
this.requiredParam = value;
return this;
}
public Builder optionalParam(Integer value) {
this.optionalParam = value;
return this;
}
public XxxNode build() {
// 必要参数校验
if (requiredParam == null) {
throw new IllegalStateException("requiredParam must be set");
}
return new XxxNode(this);
}
}
}4.2 变量替换模式
几乎所有节点都实现了变量替换,有两种主要风格:
风格一:正则表达式替换(HttpNode, LlmNode, McpNode)
java
Pattern VARIABLE_PATTERN = Pattern.compile("\\$\\{(.+?)\\}");
// 替换 ${key} 形式的变量风格二:OGNL 表达式(TemplateTransformNode)
java
Pattern PATTERN = Pattern.compile("\\{\\{(.+?)\\}\\}");
// 替换 {{expression}} 形式的表达式,支持嵌套、索引、方法调用4.3 策略模式
多个节点使用策略模式实现行为多样性:
| 节点 | 策略接口 | 实现 |
|---|---|---|
| AgentNode | Strategy | REACT, TOOL_CALLING |
| AssignerNode | WriteMode | 4 种写入模式 |
| CodeExecutorNodeAction | CodeExecutor | Local, Docker |
4.4 模板方法模式
代码执行节点使用模板方法封装语言差异:
java
public interface TemplateTransformer {
RunnerAndPreload transformCaller(
String code,
Map<String, Object> inputs,
CodeStyle style
);
Map<String, Object> transformResponse(String response);
}
// 按语言实现
Python3TemplateTransformer
NodeJsTemplateTransformer
JavaTemplateTransformer5. 通用工具与基础设施
5.1 InMemoryFileStorage - 内存文件存储
核心功能:节点间文件传递的中间存储,避免文件系统依赖。
java
public class InMemoryFileStorage {
private final Map<String, FileEntry> storage = new ConcurrentHashMap<>();
// 存储文件,返回文件 ID
public String store(String fileName, String contentType, byte[] content)
// 根据 ID 读取文件
public Optional<FileEntry> retrieve(String fileId)
// 删除文件
public boolean remove(String fileId)
}使用场景:
HttpNode下载的文件DocumentExtractorNode解析的源文件- 节点之间的大二进制数据传递
5.2 FileUtils - 文件工具
核心功能:统一的文件获取接口,支持多种来源。
java
public class FileUtils {
// 从 URL 或本地路径获取文件内容
public static byte[] getFileContent(String pathOrUrl)
// 根据内容检测 MIME 类型
public static String detectContentType(byte[] content)
// 根据扩展名选择解析器
public static String getParserName(String fileName)
}5.3 CodeUtils - 代码工具
核心功能:代码片段的提取和清理。
java
public class CodeUtils {
// 从 Markdown 中提取代码块
public static String extractCode(String markdown, String language)
// 清理 ANSI 转义序列
public static String cleanAnsiEscapeCodes(String text)
}6. 使用示例
6.1 完整工作流示例:客服问答系统
java
// 1. 构建图
StateGraph graph = StateGraph.builder()
// 知识库检索
.addNode("retrieve", KnowledgeRetrievalNode.builder()
.userPromptKey("user_question")
.topK(3)
.similarityThreshold(0.7)
.build())
// LLM 生成回答
.addNode("answer", LlmNode.builder()
.chatClient(chatClient)
.systemPrompt("你是专业客服,请根据参考资料回答用户问题。")
.userPrompt("用户问题:${user_question}\\n参考资料:${context}")
.outputKey("answer")
.build())
// 变量重命名
.addNode("assign", AssignerNode.builder()
.assignItem(AssignItem.builder()
.targetKey("final_answer")
.inputKey("answer")
.writeMode(WriteMode.OVER_WRITE)
.build())
.build())
// 边定义
.addEdge(START, "retrieve")
.addEdge("retrieve", "answer")
.addEdge("answer", "assign")
.addEdge("assign", END)
.build();
// 2. 编译执行
CompiledGraph compiled = graph.compile();
Map<String, Object> result = compiled.invoke(
Map.of("user_question", "如何重置密码?")
);6.2 HTTP + 模板转换组合
java
StateGraph graph = StateGraph.builder()
// 调用天气 API
.addNode("weather", HttpNode.builder()
.method(HttpMethod.GET)
.url("https://api.weather.com/current?city=${city}")
.header("Authorization", "Bearer ${api_key}")
.build())
// 格式化输出
.addNode("format", TemplateTransformNode.builder()
.template("当前{{city}}的温度是{{weather.body.temperature}}℃,天气{{weather.body.condition}}。")
.outputKey("weather_report")
.build())
.build();6.3 代码执行节点使用
java
CodeExecutorNodeAction node = CodeExecutorNodeAction.builder()
.codeExecutor(new DockerCodeExecutor())
.codeLanguage("python3")
.code("result = a + b\nprint(result)")
.params(List.of(
CodeParam.withKey("a", "value_a"),
CodeParam.withKey("b", "value_b")
))
.outputKey("calc_result")
.build();7. 扩展指南
7.1 自定义节点开发
步骤一:实现 NodeAction 接口
java
public class CustomNode implements NodeAction {
private final String outputKey;
// 其他配置字段...
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
// 1. 从 state 读取输入
Object input = state.value("input_key").orElse(null);
// 2. 执行你的业务逻辑
Object result = doSomething(input);
// 3. 返回要更新的状态
return Map.of(outputKey, result);
}
}步骤二:添加 Builder 模式
java
public static Builder builder() {
return new Builder();
}
public static class Builder {
private String outputKey;
public Builder outputKey(String outputKey) {
this.outputKey = outputKey;
return this;
}
public CustomNode build() {
return new CustomNode(this);
}
}步骤三:支持变量替换(可选)
java
private static final Pattern VARIABLE_PATTERN = Pattern.compile("\\$\\{(.+?)\\}");
private String replaceVariables(String template, OverAllState state) {
// 参考现有实现
}7.2 添加新的代码语言支持
步骤一:实现 TemplateTransformer
java
public class RustTemplateTransformer implements TemplateTransformer {
@Override
public RunnerAndPreload transformCaller(String code, Map<String, Object> inputs, CodeStyle style) {
// 1. 生成参数声明代码
// 2. 包装用户代码
// 3. 生成输出序列化代码
}
@Override
public Map<String, Object> transformResponse(String response) {
// 解析执行输出为 Map
}
}步骤二:注册到 CodeExecutorNodeAction
java
private static final Map<CodeLanguage, TemplateTransformer> CODE_TEMPLATE_TRANSFORMERS = Map.of(
// ... 现有语言
CodeLanguage.RUST, new RustTemplateTransformer()
);8. 最佳实践
8.1 节点设计原则
- 单一职责:每个节点只做一件事,保持粒度适中
- 无状态 :节点本身不保存执行状态,所有状态通过
OverAllState传递 - 幂等性:相同输入应产生相同输出(除非有外部副作用)
- 可组合:节点输入输出格式标准化,便于组合使用
8.2 变量命名规范
| 类型 | 命名建议 | 示例 |
|---|---|---|
| 用户输入 | xxx_input, user_xxx |
user_question |
| 节点输出 | xxx_result, xxx_output |
llm_result |
| 中间状态 | _xxx_internal |
_iteration_index |
| 配置项 | config_xxx |
config_max_retries |
8.3 错误处理最佳实践
-
明确异常类型:
java// 推荐:自定义异常 throw new McpNodeException("MCP call failed: " + e.getMessage(), e); // 避免:泛化异常 throw new RuntimeException("error"); -
日志记录:
- 进入节点时
INFO级别记录关键参数 - 异常时
ERROR级别记录堆栈 - 调试信息使用
DEBUG级别
- 进入节点时
-
优雅降级:
HTTP节点:配置重试策略和降级返回LLM节点:考虑缓存或默认回答- 知识库检索:相似度阈值处理
8.4 性能优化建议
-
大文件处理:
- 使用
InMemoryFileStorage传递文件引用,而非内容本身 - 及时清理不再需要的文件
- 使用
-
状态管理:
- 避免在
state中存储过大对象 - 迭代节点及时清理中间状态
- 避免在
-
外部调用:
HTTP/MCP节点合理配置超时和重试- 考虑缓存幂等的外部调用结果
附录:节点速查表
| 节点类 | 主要功能 | 典型输入键 | 典型输出键 |
|---|---|---|---|
LlmNode |
LLM 对话 | messages, 自定义 |
messages, 自定义 |
AgentNode |
Agent 推理 | messages, 自定义 |
messages |
ToolNode |
工具执行 | messages |
messages |
AssignerNode |
变量赋值 | 自定义 | 自定义 |
TemplateTransformNode |
模板转换 | 自定义 | 自定义 |
ListOperatorNode |
列表操作 | 列表键 | 处理后列表 |
HttpNode |
HTTP 请求 | URL 变量 | status, body, headers |
McpNode |
MCP 调用 | 参数变量 | 自定义 |
CodeExecutorNodeAction |
代码执行 | 参数变量 | 自定义 |
KnowledgeRetrievalNode |
知识库检索 | user_question |
context |
DocumentExtractorNode |
文档解析 | 文件路径 | content |
IterationNode |
循环迭代 | 数组键 | 结果数组 |
QuestionClassifierNode |
问题分类 | user_question |
category, keywords |
ParameterParsingNode |
参数解析 | user_question |
data, is_success |
VariableAggregatorNode |
变量聚合 | 多键 | 聚合列表 |
AnswerNode |
答案生成 | 多变量 | answer |
HumanNode |
人工介入 | 自定义 | 自定义 |