目录
[三、K8s 环境最佳实践](#三、K8s 环境最佳实践)
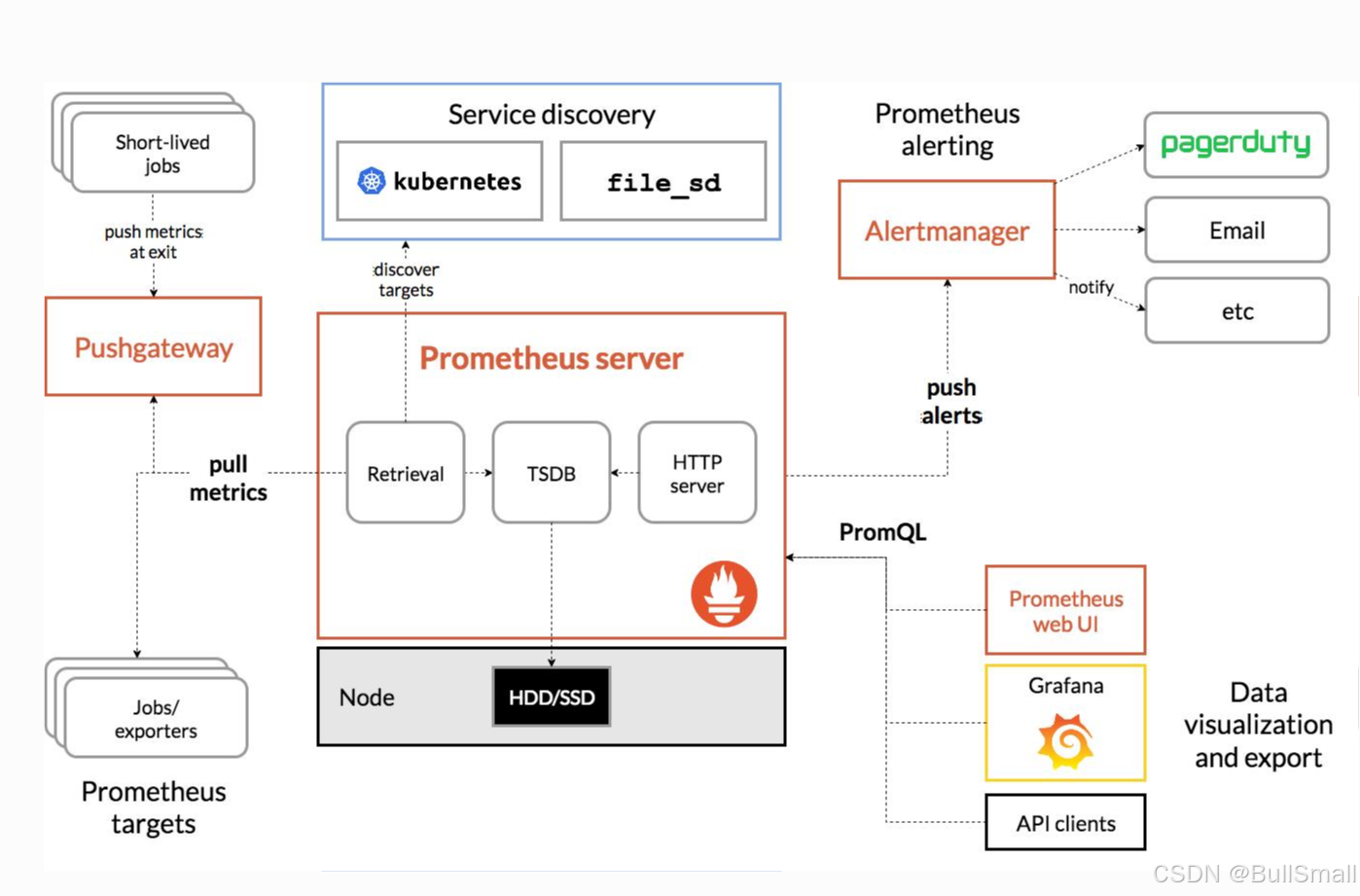
Prometheus 与 Alertmanager 之间应走管理平面(运维 / 监控平面),不走业务平面。
一、为什么是管理平面
- 功能定位 :两者都属于运维 / 监控基础设施 ,不是业务应用;告警下发、状态查询属于管理控制流量,和业务流量无关。
- 安全隔离 :管理平面通常做访问控制、ACL、加密,避免业务网络的攻击 / 风暴影响监控系统。
- 稳定性优先 :监控与告警需要独立、可靠的网络,不与业务争抢带宽,也不受业务扩容 / 波动影响。
- 端口与协议 :通信为 HTTP/HTTPS ,端口 9093(Alertmanager)、9094(集群 gossip),属于管理端口,非业务端口。
二、网络平面划分建议
- 管理平面(推荐)
- 承载:Prometheus ↔ Alertmanager、Prometheus ↔ 被监控端(exporter)、运维 SSH/API、Grafana ↔ Prometheus。
- 网段:独立网段(如 10.xx.0.0/24),防火墙仅开放 9090、9093、9094、22 等管理端口。
- 业务平面
- 承载:业务应用间、用户请求、数据库 / 缓存等业务流量。
- 网段:业务网段(如 192.168.xx.0/24),不开放监控组件端口。
三、K8s 环境最佳实践
- 部署:Prometheus、Alertmanager 放 独立命名空间(如 monitoring),与业务隔离。
- 网络策略:只允许 monitoring 命名空间内通信,禁止业务 Pod 访问 Alertmanager 9093 端口。
- 服务发现:用 ClusterIP(管理平面) 暴露 Alertmanager,不用 NodePort/LoadBalancer(业务平面)。
四、典型错误与后果
- 走业务平面:业务流量突增会挤占带宽、延迟告警 ;业务网络被攻破后,告警系统易被篡改 / 瘫痪。
- 负载均衡:官方明确禁止 LB,必须 Full Mesh(Prometheus 直连所有 Alertmanager 实例),避免告警丢失 / 重复。
五、配置示例(管理平面)
# Prometheus 配置
alerting:
alertmanagers:
- static_configs:
- targets:
- 10.xx.0.10:9093 # 管理平面IP
- 10.xx.0.11:9093