阿里云 PAI 团队针对 Qwen3.5 等模型对大 Head Dimension 的训练需求,设计并实现了面向 large head dimension 场景的专用 FA4 Kernel,有效支撑了千卡规模训练,已合入 Dao-AILab/flash-attention 官方仓库。
动机与挑战
当前社区版 FlashAttention-4 (FA4) 在特定架构上尚未支持 head_dim=256。其根本瓶颈在于 Tensor Memory (TMEM) 的容量限制 :当 head_dim 从 128 扩展至 256 时,Backward 过程中 dK/dV 等中间变量的存储需求翻倍,导致原有 Tile 切分策略下的 TMEM 溢出(OOM),无法直接沿用既有流水线设计。这使得 FA4 难以满足 Qwen3.5 等新模型对大 Head Dimension 的训练需求。为此,我们设计并实现了一套针对大 Head Dimension 的 FA4 专用 Kernel,该方案已通过 PR#2412 合入 Dao-AILab/flash-attention 官方仓库。主要技术创新包括:
1、Forward 优化 :通过重构流水线突破 TMEM 容量限制,重新规划 TMEM 使用策略;同时借助 2 CTA 设计优化线程协作,显著提高计算访存比,确保持续高吞吐。
2、Backward 优化 :采用 双 Kernel 拆分策略(dQ Kernel + dKdV Kernel)。虽然引入了一定的重算开销,但有效降低了单个 Kernel 对 TMEM 和 Shared Memory 的峰值压力,借助 2 CTA 实现整体性能优化。
在 L20A 平台上的基准测试显示,该方案在长序列场景下表现卓越:
-
Forward 吞吐 :最高可达 1700 TFLOPS
-
Backward 吞吐 :最高可达 980 TFLOPS
-
加速比 :相较于 FlashAttention-3 (FA3),长序列训练整体性能提升超过 2 倍。
该成果有效填补了社区在大 Head Dimension 场景下的高性能算子空白,为大模型训练提供了关键算力支持。
架构特性与编程范式演进
2.1 从 SIMT 向 NPU 范式靠拢
随着 NVIDIA GPU 架构的迭代,其编程模型正从传统的单指令多线程(SIMT)逐渐向更接近专用神经网络处理器(NPU)的异构异步范式演进。这一转变旨在通过硬件特性的精细化分工,突破内存墙限制,榨取极致算力。
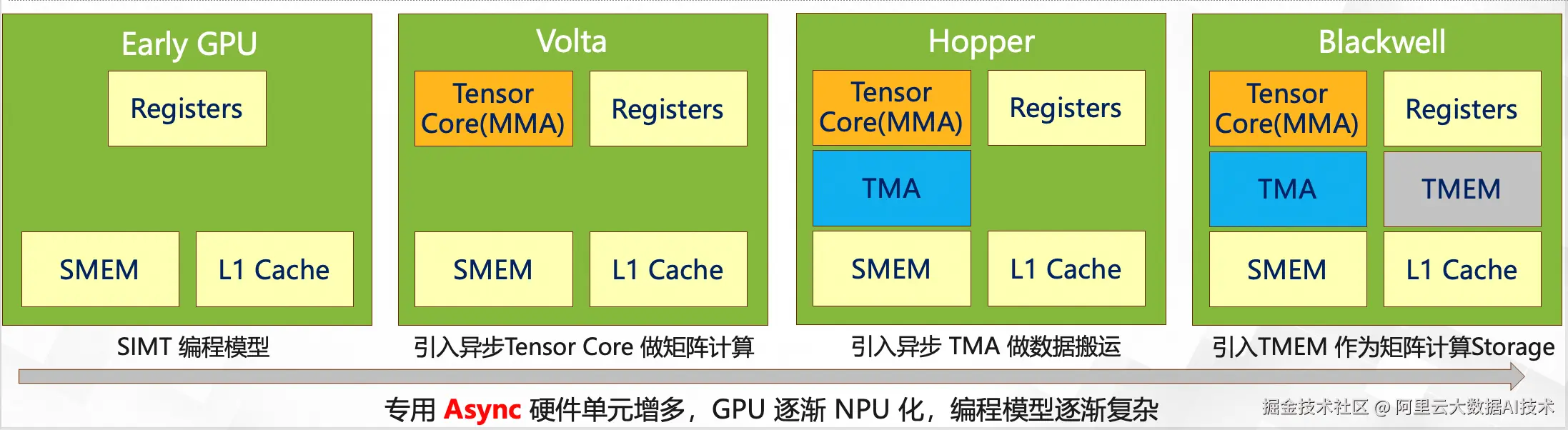
-
Volta 时代 :引入 Async Tensor Core,实现矩阵乘法累加(MMA)操作的异步化,初步分离计算与控制流。
-
Hopper 时代 :引入 Async TMA (Tensor Memory Accelerator),专门负责全局内存(GMEM)到共享内存(SMEM)的高速数据搬运,进一步解耦数据加载与计算。
-
更新一代架构 :引入 Tensor Memory (TMEM),这是一种专为 Tensor Core 设计的片上存储介质。其本质是寄存器文件(Register File, RF)的扩展,旨在解决大尺寸矩阵运算中寄存器资源极度稀缺的问题。
2.2 Tensor Memory:突破寄存器瓶颈的关键
1. 设计背景
Tensor Core 的性能提升长期受限于"内存墙"。历代架构通过优化数据路径(Ampere cp.async、Hopper TMA)、扩大缓存容量(SMEM/L1/L2)以及减少访存次数(增大 Tile Size、低精度计算、TMA Multicast)来提升效率。然而,随着 MMA 算子规模扩大,寄存器文件(RF)成为新的瓶颈。
TMEM 应运而生,它作为 RF 的延伸,专门用于存储 Tensor Core 的操作数与中间结果,从而缓解 RF 的极端压力。
2. 规格与限制
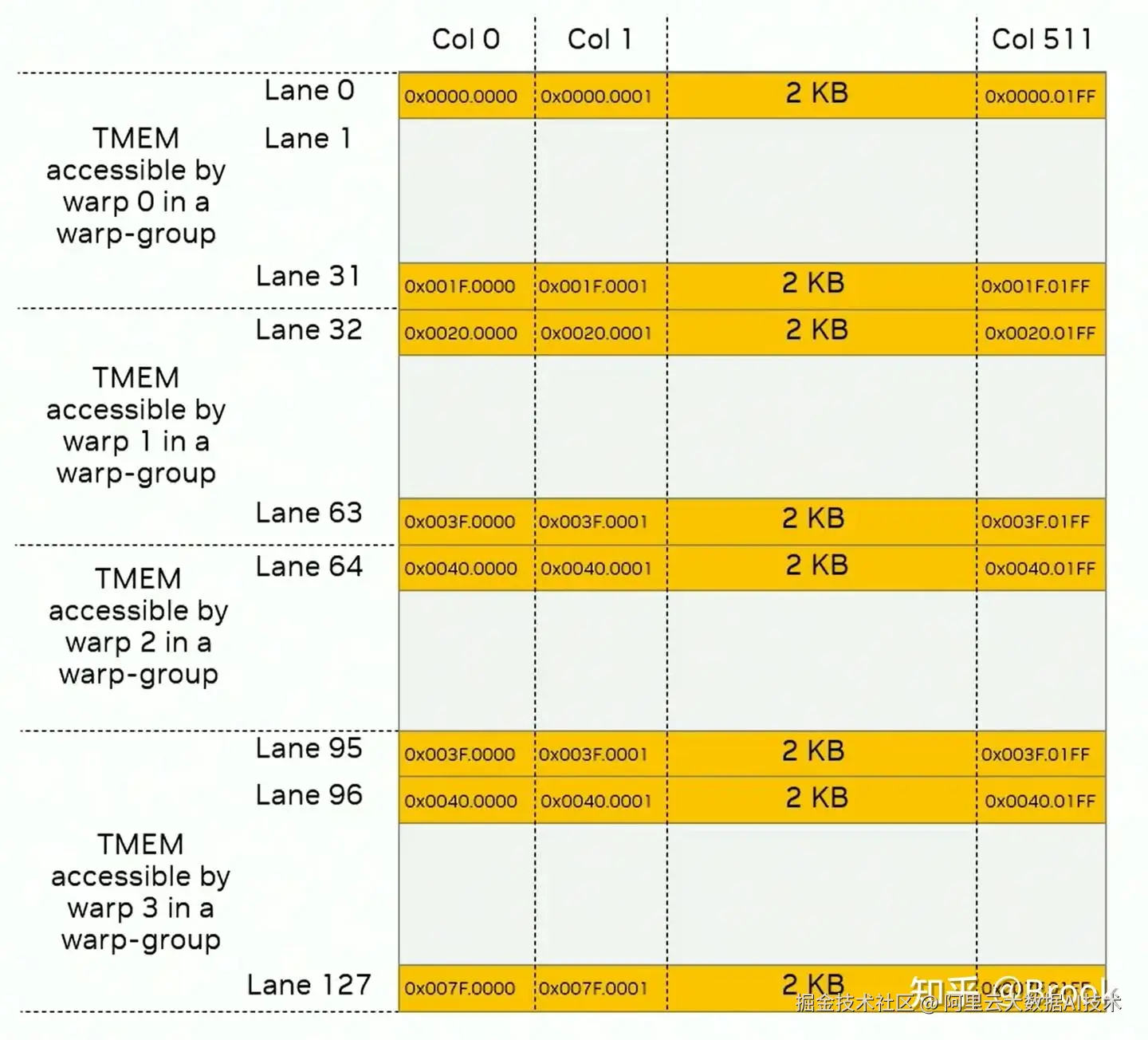
每个 Streaming Multiprocessor (SM) 配备 256KB TMEM(128 rows × 512 cols × 4 Bytes),容量与 RF 相当。其访问机制具有严格的硬件约束:
-
协作访问 :需由一个 Warp Group 共同访问,且每个 Warp 仅能访问特定的 Lane 集合。
-
列式分配 :支持按列分配,宽度仅限
[32, 64, 128, 256, 512],高度固定为 128 行。 -
显式管理:程序员需手动管理 TMEM 的分配、释放及数据拷贝。
-
数据流向 :支持从 RF/SMEM/L1 写入 TMEM,但仅能向 RF 读出数据(即 TMEM 不能直接作为最终结果输出到 GMEM)。
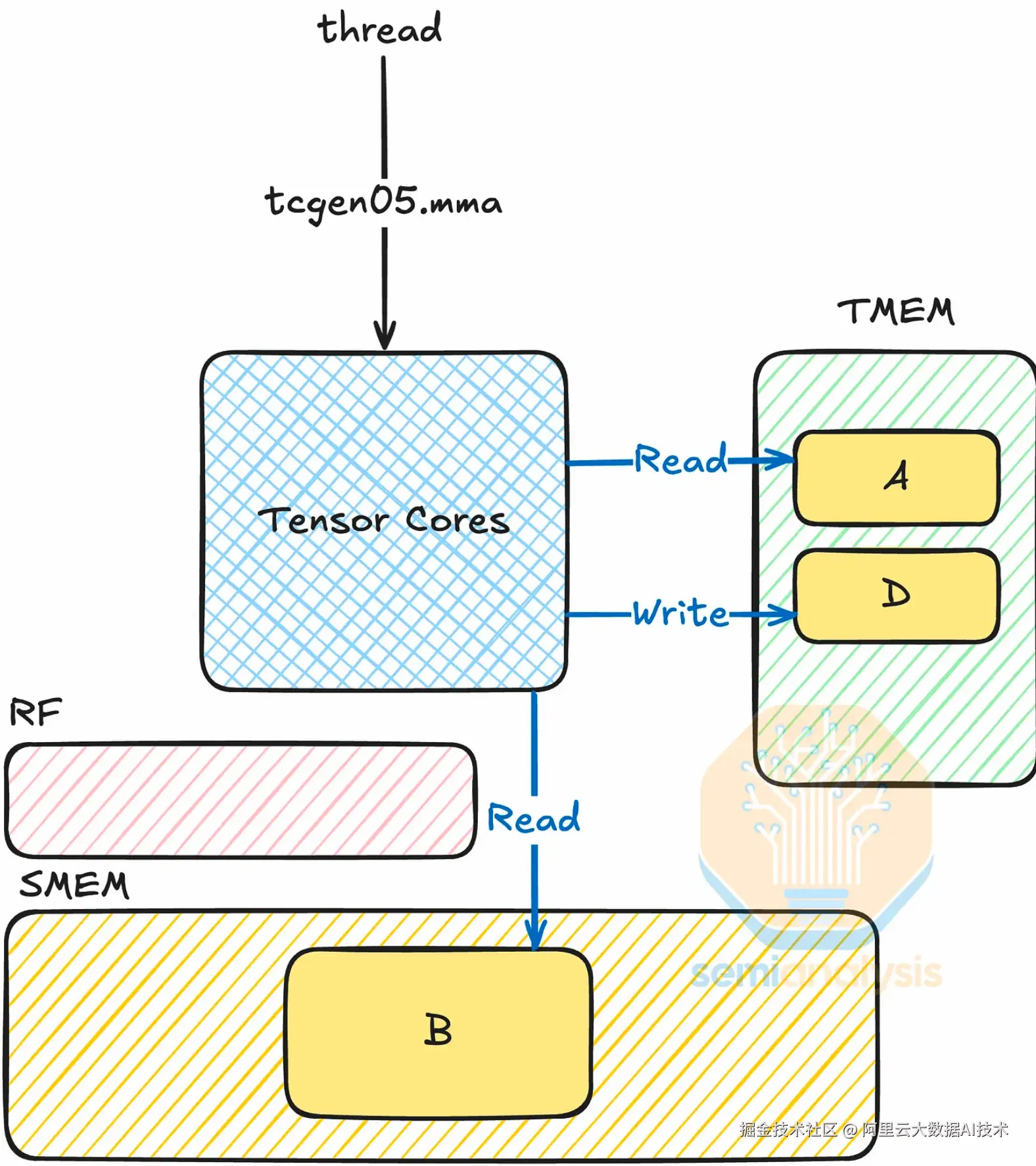
2.3 第 5 代 Tensor Core MMA 与 CTA Pair
1. 零寄存器占用的 MMA 计算
特定架构引入的第五代 MMA 指令(PTX: tcgen05.mma)实现了寄存器零占用的矩阵运算:
-
操作数存储:矩阵 A、B 及累加结果 D 均存储在 SMEM 或 TMEM 中,不再占用 RF。
-
线程级发起:仅需单个线程发起 MMA 指令,无需占用整个 Warp Group。其余线程可并行执行数据准备或 Epilogue 操作。
-
流水线重叠:相比 Hopper 架构中 WGMMA 与数据写回均需争夺寄存器资源,特定架构允许 MMA 计算与数据重排/写回完全重叠,显著提升流水线效率。
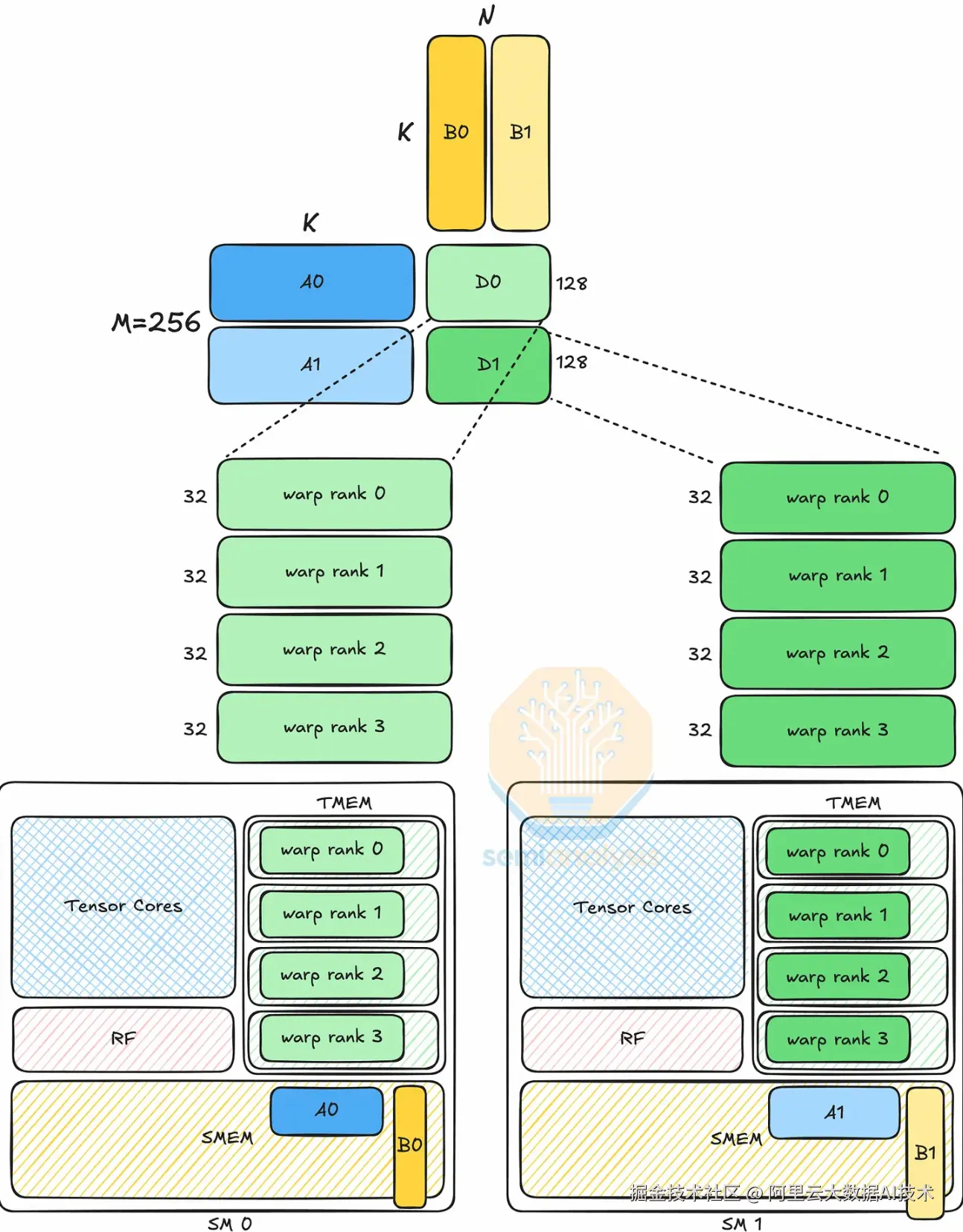
2. CTA Pair 与 DSMEM
为支持更大规模的矩阵运算,特定架构引入了 CTA Pair 概念:
-
机制 :在 Thread Block Cluster 中,相邻的两个 CTA(如 0 号与 1 号)结成一对。它们通过 分布式共享内存 (DSMEM) 共享输入操作数。
-
优势:
-
节省 SMEM:矩阵 B 等重复使用的操作数只需加载一次,即可在两个 CTA 间共享。
-
扩展 M 维度:相比单 SM 模式,2-CTA 模式支持的 M 维度翻倍,允许使用更大的 Tile Size(如 128×128),从而提升计算密度。
-
-
执行模型:由 Leader CTA 中的单个线程发起 MMA 操作,两个 SM 分别加载不同的 A 和 D 分块,协同完成计算。
下图展示了使用 CTA Pair 时的矩阵乘法过程。
2.4 编程范式转型:异构化与异步化
现代 GPU 高性能编程已超越传统的统一 SIMT 模型,转向两种更贴近硬件特性的范式:
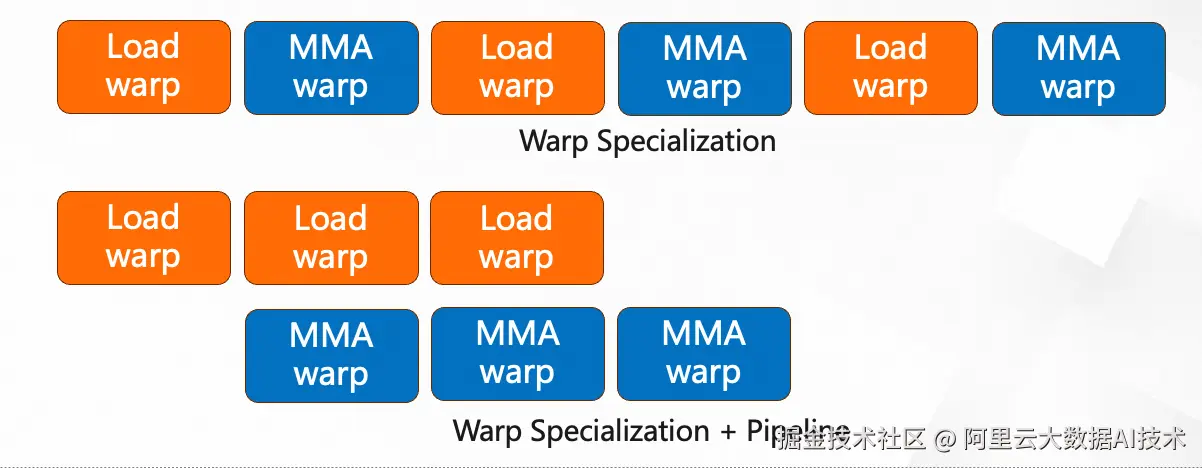
-
Warp Specialization :
-
核心思想:将 Block 内的不同 Warp 静态绑定至流水线的特定阶段。例如,部分 Warp 专职 TMA 数据搬运,部分专职 MMA 计算,部分专职数据重排。
-
收益:避免同一 Warp 内因分支逻辑导致的指令发散(Divergence),使指令序列更规则、寄存器使用更稳定,有利于编译器优化与硬件调度。
-
-
Async Pipeline :
-
核心思想:显式串联各类异步硬件单元(TMA 搬运、MMA 计算、SMEM 暂存)。通过多级 Double-Buffering 与时序控制,实现数据加载与计算的深度重叠。
-
要求:开发者需以"生产者-消费者"视角组织代码,在无全局时钟的情况下,手动协调多 Warp、多 CTA 的执行进度,确保数据依赖的正确性。
-
社区版 FlashAttention-4
3.1 背景
在本次 PR 合并之前,社区在特定架构上针对大 head_dim(如 256)的 FlashAttention 实现存在显著空白。各版本算子的支持情况如下表所示:
| FA 版本 | head_dim ≤ 128 | head_dim = 256 | 备注 |
|---|---|---|---|
| FA4 | ✅ | ❌ | TMEM OOM:受限于 Tensor Memory 容量,尚未完成适配 |
| FA3 | ❌ | ❌ | 架构不兼容:深度绑定 Hopper 特性,无法在 SM 100 运行 |
| FA2 | ✅ | ✅ | 性能落后:通用性强但未利用新硬件特性,效率较低 |
| cuDNN FA | ✅ | ❌ | 功能缺失:暂不支持 head_dim=256 |
在本次优化之前,在更新一代架构平台上运行大 head_dim 模型(如 Qwen 3.5)时,开发者被迫回退至低效的 FA2 实现,无法发挥新硬件在计算与访存上的优势。因此,本次工作针对特定架构重新设计了 Attention Kernel,重点解决了 TMEM 容量约束下的 Layout 与 Pipeline 优化问题,填补了高性能算子空白。
3.2 FA4 (TriDao) 社区方案详解
本章节深入解析由 TriDao 团队提出的社区版 FA4 通用实现方案,该方案构成了我们针对 head_dim=256 专用优化的技术基础。
3.2.1 Forward 实现
基本原理
FlashAttention Forward 的计算流程可抽象为以下三个 tile 级别的核心矩阵运算。假设我们选取 tile 为 Q tile, K tile, head_dim:
1、Score 计算 (S):S=Q \times K^T,S 的 Shape 为 Q tile x K tile
2、Softmax 处理 (P):P=softmax(S),P 的 shape 为 Q tile x K tile
3、Output 计算 (O):O=P \times V^T,O 的 shape 为 Q tile x head_dim。
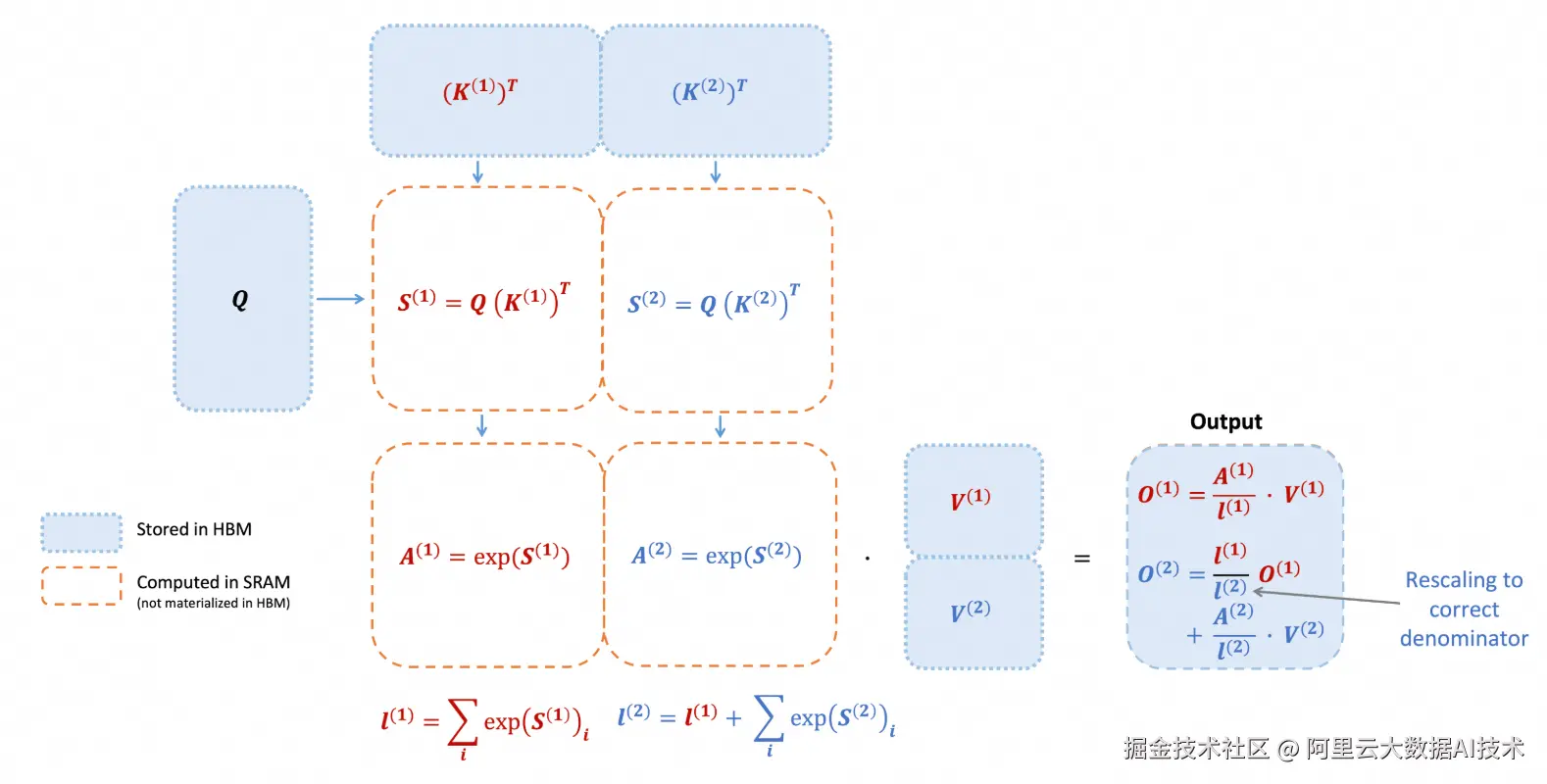
性能优化的核心在于构建高效的"生产-消费"流水线,将 Tensor Core 的 MMA 操作 (S 阶段与 O 阶段)与 CUDA Core 的 Softmax 后处理(P 阶段)进行极致重叠(Overlap),以最大化 Tensor Core 的利用率。
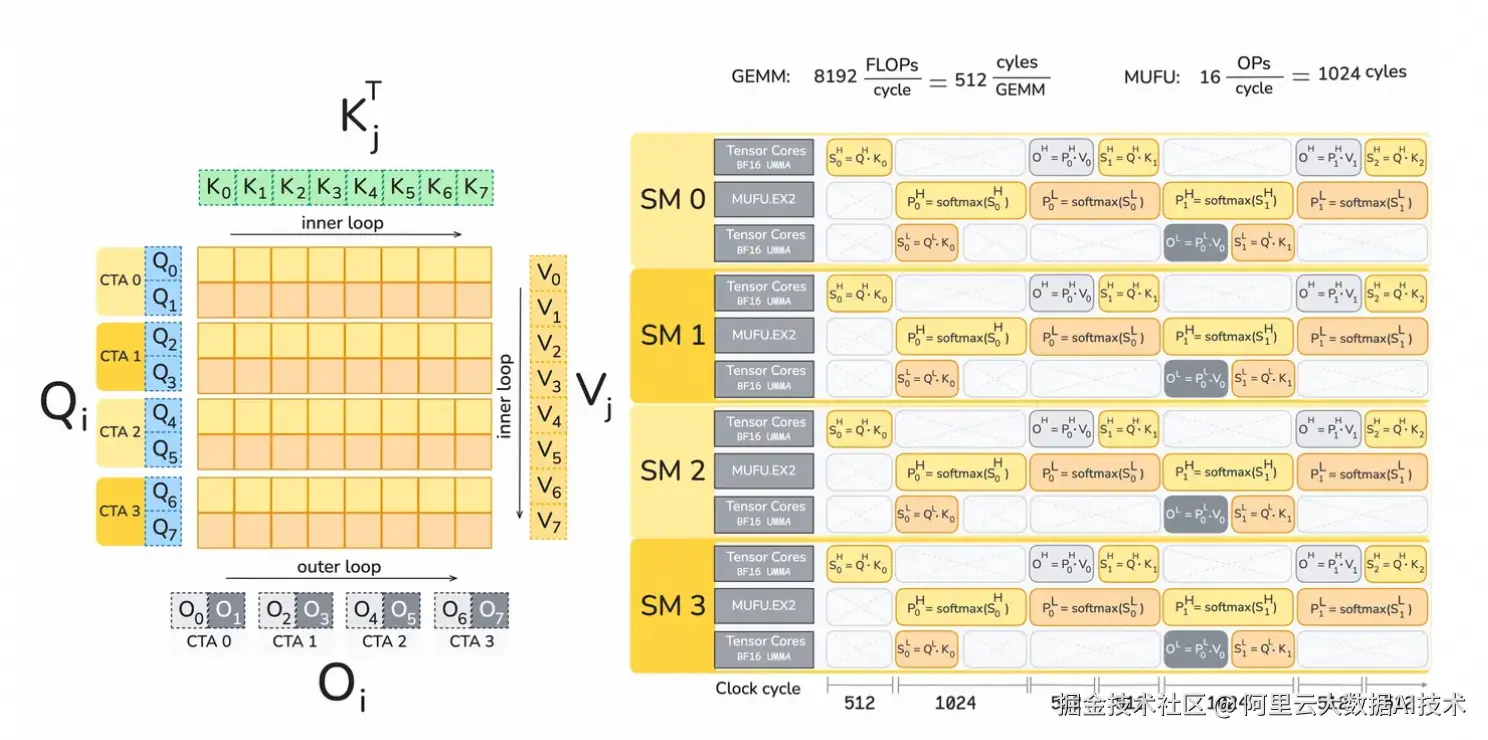
Pipeline 设计(结合 Warp Specialization)
通过 Warp 静态分工实现异步流水线:
-
Load Warps:负责加载 Q Tile,并流式传输所有 K 和 V Tiles。
-
MMA Warps :执行 QKT=S_QKT_=S 与 PV=O_PV_=O 矩阵乘法。
-
Softmax Warps:计算归一化的 Attention Scores。
-
Correction Warps:根据归一化系数的变化,对历史输出进行重缩放(Rescale)。
-
Epilogue Warps(可选):将完整的 Output Tiles 写回全局内存。
效率关键: Pipeline 的整体吞吐取决于两个 MMA 操作对单个 Softmax 延迟的掩盖效率。在流水设计上,因为 head_dim = 128 时,其 Softmax 的操作耗时约等于 2 MMA 的耗时,因此尽可能用两个 MMA 掩盖 1 Softmax。
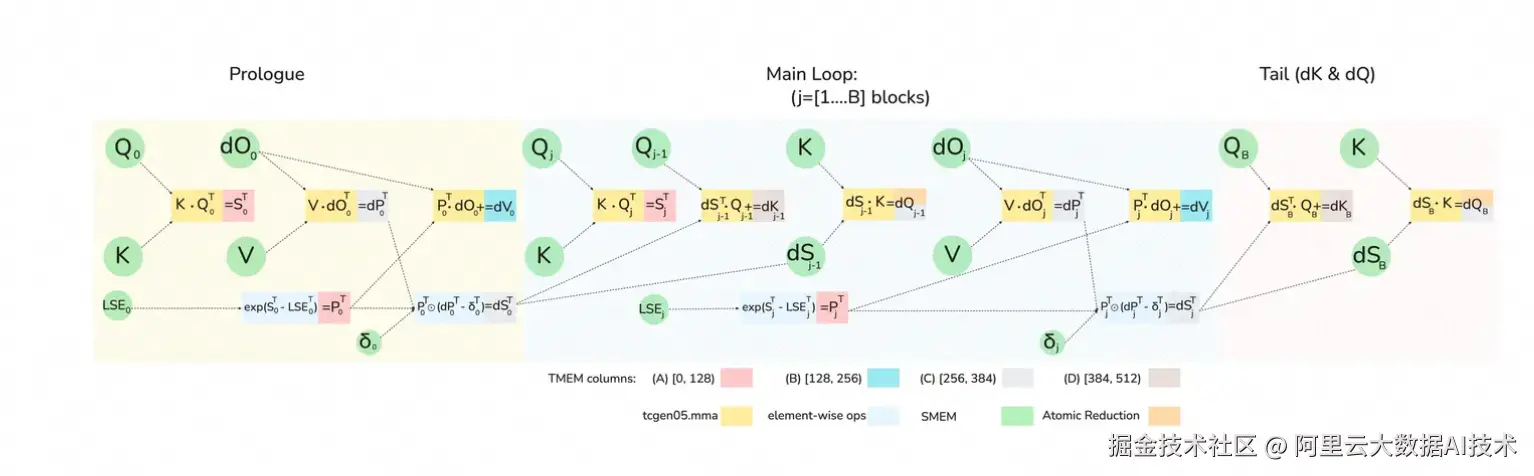
3.2.2 Backward 实现
基本原理
FlashAttention Backward 涉及 5 个 MMA 操作,远高于 Forward 的 2 个。这是由于梯度传播需沿计算图反向展开多个依赖路径:
-
重算 Score:S^T=K \times Q^T,这是 FlashAttention 引入的重算机制
-
计算 dP:dP=dO \times V^T,用于反向传播至 Softmax 前
-
计算 dV:dV=P^T \times dO,shape 为 K tile x head_dim
-
计算 dK:dK=dS^T \times Q,shape 为 K tile x head_dim
-
计算 dQ:dQ=dS \times K^T,shape 为 Q tile x head_dim
假设 Q tile 和 K tile 均选取 128,那么dQ, dK, dV 将占据 TMEM 的空间为 128 x 384,只留下 128 x 128 给剩下两个 MMA,TMEM 压力很大,但也能够通过 Pipeline 合理安排其排布。
Pipeline 设计(结合 Warp Specialization + CTA Pair)
在特定架构上,累加器(accumulators)驻留在 TMEM 中,这使得在 CUDA Core 处理 P 和 dS 的逐元素运算时,保持多个 MMA(矩阵乘累加)操作并行执行变得切实可行。根据官方的 Roofline 模型分析,指数运算的吞吐量与两次 MMA 操作相当,因此通过流水线重叠来隐藏其延迟是值得的。
另外,该方案通过集群内分布式共享内存(DSMEM)在CTA Pair 间交换半数 dS,将 dS 沿非规约轴重排,使每个 CTA 仅负责 M/2 行但持有完整的 2N 规约维度。在此 2-CTA 模式下,dQ 的矩阵乘法变为 (M/2, 2N) 乘以 (2N, d),并在 TMEM 中累加 (M/2, d) 的 Tile;而其他操作(S, dP, dV, dK)仍保持 M=256,dQ 则使用 M=128 且规约维度翻倍至 2N=256。
HeadDim=256 场景下的 FA4 优化方案
4.1 背景与挑战:为何 HeadDim=256 难以直接沿用原有设计?
TriDao FA4 在 head_dim=128 时表现优异,但在 head_dim=256 时面临严重的存储瓶颈。按照 Tile size [128×128] 的设计,HeadDim 翻倍导致部分矩阵乘法累加器(Accumulator)的存储需求显著增加。具体来看:
-
Forward :S 矩阵 Shape = 128x128 不变,但 O 矩阵 Shape 受 headDim 翻倍影响,从 128x128 变成 128x256。这在 q_stage = 2 的情况下,无法同时存放 2 个 O 矩阵,原有的 Pipeline 掩盖方案无法实现
-
Backward:dQ, dK, dV 的 Shape 都会受到 headDim 翻倍影响,每个矩阵的 Shape 都变成 128x256,即最多只能承载 2 个 output
4.2 Attention Forward 专用优化方案
4.2.1 计算流程拆解
为了保持良好的吞吐效率,我们依然使用最大的 tile size 即 128x128x256 来驱动 Pipeline 的设计。这是因为更大的 MMA shape 具有更高的计算访存比,同时各个模块最好完全掩盖,减少流水线空泡。
具体针对到 Forward 性能方面,我们将 FA4 的计算流程拆解为以下阶段,并针对 Storage、Compute Unit 和 Data Dependency进行联合优化。但是这需要考虑硬件限制,其次计算单元的占用和数据依赖决定了流水线的 stage 数,进而决定了掩盖效率。
| 阶段 (Stage) | 操作 (Operation) | 数据流向 (Storage Flow) | 计算单元 (Compute Unit) | 数据依赖 (Dependency) |
|---|---|---|---|---|
| Load | Load Q, K, V | GMEM → SMEM | - | - |
| Matmul 1 | S = Q · K^T | SMEM → TMEM | Tensor Core | Q, K |
| Softmax | P = Softmax(S) | TMEM → RF → TMEM | CUDA Core | S |
| Matmul 2 | O = P · V^T | TMEM (Read/Write) | Tensor Core | P, V |
| Correction | Rescale/Correct O | TMEM → RF → SMEM | CUDA Core | O (Partial) |
| Store | Store O | SMEM → GMEM | - | O (Final) |
4.2.2 Pipeline 设计的目标
Pipeline 设计的核心在于平衡以下三者:
-
Storage(存储):SMEM、TMEM、RF 的容量限制决定了最大 Tile Size。
-
Compute Unit(计算单元):Tensor Core 与 CUDA Core 的占用率决定并发能力。
-
Data Dependency(数据依赖):决定流水线的 Stage 数和气泡大小。
优化目标:
-
最大化 Tile Size:更大的 MMA Shape 通常带来更高的计算访存比(Arithmetic Intensity)。
-
完全掩盖延迟通过微基准测试(Microbenchmark)评估各模块耗时,合理划分 Stage,使内存加载、Tensor Core 计算和 CUDA Core 处理完全重叠,消除流水线空泡。
4.2.3 新 Pipeline 方案
我们已知:当 HeadDim 增至 256 时,若维持 128x128 Tile,TMEM 无法容纳原有的双缓冲 S 和 O(因为 S 和 O 的第二维变为 256,占用翻倍)。但这里需要重新思考核心的问题:
当 head_Dim = 256时,我们是否依然要沿用 headDim = 128 的 Pipeline 掩盖方式?
对于计算密集型的算子,Pipeline 的设计目标总是应该以尽可能打满 tensor core 为第一准则。相关 stage 数量的设置应该为 Pipeline 的掩盖方案服务,而不是反过来。对于 HeadDim = 256 的 MMA,几乎只需要 1 个 MMA 去掩盖 1 个 softmax (MMA 计算翻倍,softmax 计算不变),以此为基础去设计 Pipeline 掩盖,我们发现 q stage 可以降低到 1,此时 TMEM 上也只需存放 1 个 O 矩阵即可。而对于 SMEM 的压力,我们通过 2 CTA 的方式均摊负载。
总结来看,针对 HeadDim=256 的 Pipeline 重构方案,核心逻辑如下:
1、 确立计算优先原则: Pipeline 设计以"打满 Tensor Core"为第一准则,Stage 数量应服务于掩盖方案,而非受限于传统缓冲策略。
2、 优化计算掩盖比例:鉴于 HeadDim=256 时 MMA 计算量翻倍而 Softmax 开销不变,仅需 1 个 MMA 即可有效掩盖 1 个 Softmax 阶段,实现了计算与访存的高效重叠。
3、 极简 TMEM 占用:基于上述掩盖关系,将 Q 的 Stage 数精简至 1,使得 TMEM 中仅需驻留 1 个 O 矩阵,彻底解决了高维下的片上存储瓶颈。
4、SMEM 负载均摊:通过引入 2-CTA 协作机制,将 SMEM 的负载压力在两个 CTA 间均摊,在确保计算单元饱和运行的同时,实现了存储资源与计算效率的最优平衡。
对于 TMEM,我们合理的使用了全部的空间。通过只使用 1 个 O stage 达到 TMEM 的空间需求。 
对于 Pipeline 调度层面,我们不使用不同的 Q 做 ping pong 掩盖,而是针对同一个 Q 使用不同的 K 做 ping pong 达到掩盖目的。 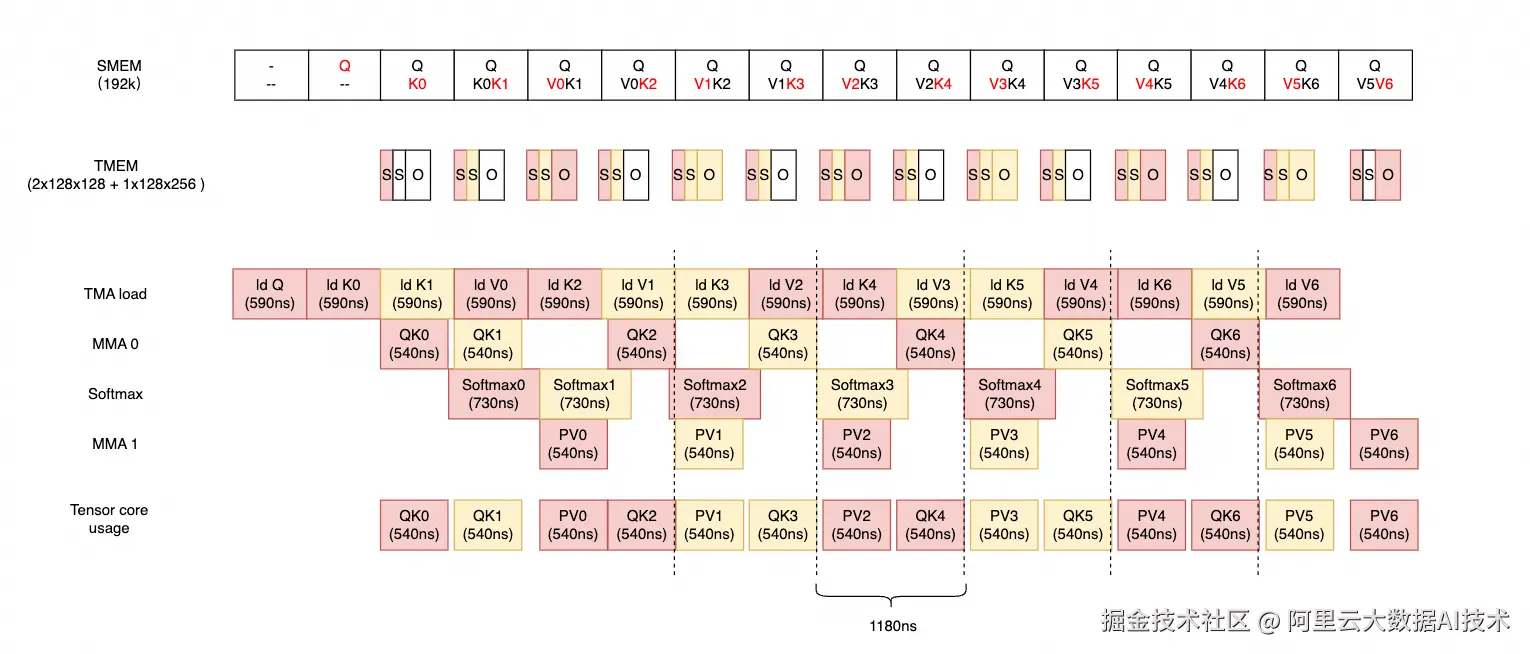
4.3 Attention Backward 专用优化方案
4.3.1 计算流程拆解
Backward 比 Forward 阶段的 MMA 更多,从 FlashAttention 原理上需要有个 S 矩阵的重建过程,所以理论上共 5 个 MMA。为了追求尽可能大的 tile size,我们此处 backward 拆分为两个独立 kernel---dQ kernel 和 dKdV kernel,以缓解单 kernel 的存储压力,但是这必然又引入了新的重计算代价。
-
dQ kernel(3 个 MMA)
-
重算 S:S=Q \times K^T,
-
计算 Score: P=softmax(S),以上两步是 FlashAttention 引入的重算机制
-
计算 Score Gradient: dP=V \times dO^T
-
计算 S Gradient: dS=dSoftmax(P, dP, sumOdO)
-
计算 dQ: dQ=dS \times K^T
-
-
dKdV kernel (4 个 MMA)
-
重算 S:S^T=K \times Q^T,
-
计算 Score:P^T=softmax(S^T),以上两步是 FlashAttention 引入的重算机制
-
计算 ScoreGradient: dP=V \times dO^T
-
计算 S Gradient: dS^T=dSoftmax(P^T, dP^T, sumOdO)
-
计算 dV: dQ=P \times dO
-
计算 dK: dQ=dS^T \times Q
-
相比原始 backward 共需 5 个 MMA,拆分方案实际执行 7 个 MMA。但这一损失需通过更大的 tile size(如 128×128)和 2 CTA 带来的访存效率提升与流水线优化来补偿。另外,我们在两个 Kernel 中分别采用不同的 loop 顺序。可以观察到 dQ kernel 采用了和 Forward 相同的 loop 顺序:以 Q 为 outer loop,K 为 inner loop,而 dKdV 则相反。
4.3.2 dQ Kernel 优化
-
循环结构与 Storage :采用 128×128 Tile 配合 Outer-Q/Inner-K 循环。通过 Swap AB 操作数角色,使 dQ_dQ_ 成为 Inner Loop 的累加目标并常驻 TMEM。由于 dQ 无需跨 Outer Loop 迭代保持状态,其存储区可与中间结果隔离,恰好占满可用 TMEM 容量
-
Pipeline 调度策略: 针对 HeadDim=256 时 MMA 计算量翻倍的特性,原有的"2 MMA 掩盖 1 Softmax"策略不再适用。我们重新调整了 Stage 数与同步点,利用单次 Softmax 相对延迟缩短的特点,实现了更紧凑的计算重叠,确保 Tensor Core 在高维计算下依然饱和运行。
根据上面的掩盖关系,我们调整 dQ Kernel 的策略如下: 
对应的 TMEM 可以做如下划分。此方案和 Forward 在结构上非常类似。

4.3.3 dKdV Kernel 优化
为了避免 dK 和 dV 两个 Output 同时占满所有的 TMEM,我们无法同时将 Q 和 K 两个方向的 tile size 都扩大到 128,只能采取一个折中的策略。
-
循环结构与 Storage: 采用 128×64 Tile 配合 Outer-K/Inner-Q 循环。dK 与 dV 作为 Outer Loop 的累加目标常驻 TMEM。值得注意的是,受 MMA 指令输出 Layout 及 Two CTA 协作机制影响,逻辑上 64×256 的梯度矩阵在 TMEM 中被重映射为 128×128 的物理 Footprint。
-
性能表现: 尽管 128×64 Tile 下单次 Softmax 延迟略大于一个 MMA 周期,导致无法实现 100% 掩盖,但未掩盖部分的占比极小。该结构高度复用了 HeadDim=128 时的成熟数据流经验,在维持高 Tensor Core 利用率的同时,有效平衡了计算与访存的开销。
根据掩盖和数据依赖关系,我们设计如下的 Pipeline 掩盖方案。由于 tile size 采用 128×64,单次 Softmax 的延迟略大于一个 MMA 周期,无法被完全掩盖。但未被掩盖的部分占比较小,对整体 MFU 影响有限,仍可维持较高的 Tensor Core 利用率。

此时对应的 TMEM 划分如下。 
Benchmark
根据 PR #2412 合并后的最新基准测试数据,FA4 在 L20C 平台上的性能表现如下:
-
Forward
-
FA4 vs FA3:FA4 在所有序列长度下均优于 FA3,在 seqlen ≥ 8k 时实现 2.0--2.3x 加速
-
峰值吞吐 :在 GQA、非因果模式下,seqlen=16k 时达到约 1839 TFLOPS
-
短序列优势:在 seqlen=4k 时,FA4 仍领先约 1.15x
-
长序列稳定性:在 seqlen=128k 时,FA3 出现 OOM,而 FA4 仍能维持约 1300 TFLOPS
-
-
Backward
-
FA4 vs FA3:FA4 consistently faster,在 seqlen=4k 时实现 1.4x 加速,在 seqlen=64k 时达到 2.6x 加速
-
峰值吞吐 :在长序列场景下达到约 950 TFLOPS
-
拆分方案通过增大 tile size 提升 Tensor Core 利用率,虽引入少量重算开销,但整体收益显著。 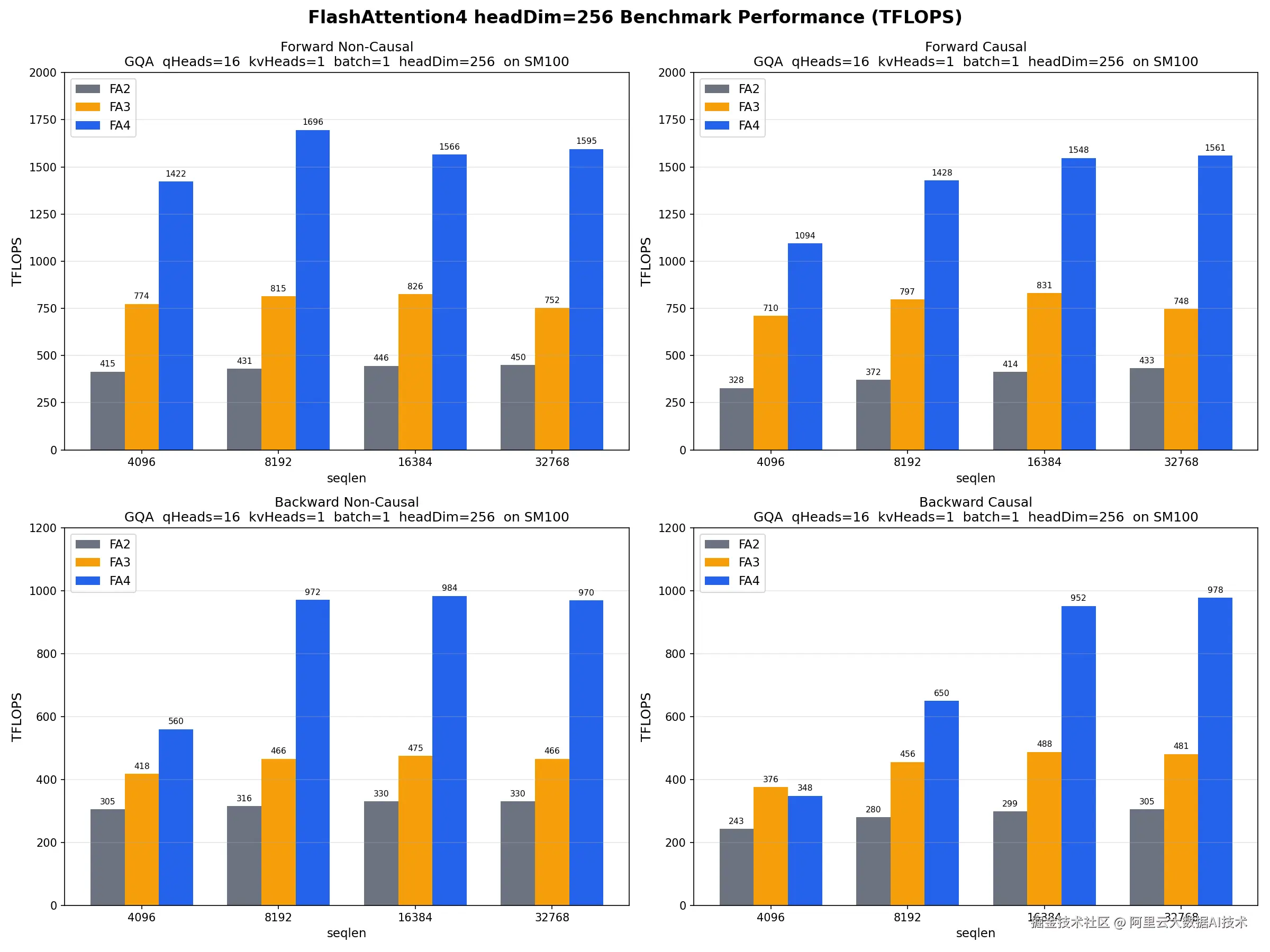
总结与展望
本文针对特定架构上 HeadDim=256 的场景,提出了一套硬件感知的多级异步流水线方案。通过协同优化存储布局与流水线调度,实现了前向 1600 TFLOPS、反向 950 TFLOPS 的高吞吐性能,有效支撑了千卡规模训练。未来工作将聚焦于推理场景适配(如 FP8 KV Cache、Paged KV Block、SplitKV)及稀疏化算子支持,以进一步完善工程体系并加速线上落地。