面试官问"为什么
<script>会阻塞 DOM 解析",大部分人背的答案是"因为 JS 可能操作 DOM"。但这只是表面原因------真正的问题是:浏览器用栈在搭 DOM 树,JS 可能把栈拆了。 这篇文章从浏览器收到 HTML 字节流那一刻讲起,一步步推到"JS 为什么非得让解析器暂停",让你以后再也不用背这个答案。
一、从一个问题开始
打开任意网页,F12 控制台输入:
js
const nav = performance.getEntriesByType("navigation")[0];
console.log(
"DOM解析耗时:",
(nav.domInteractive - nav.responseEnd).toFixed(1),
"ms",
);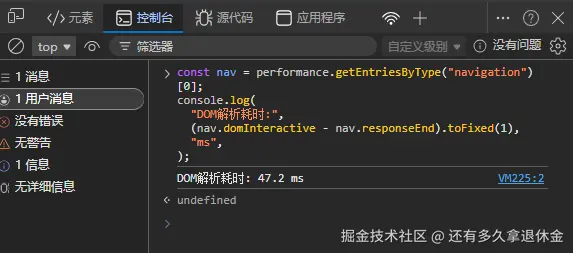 你会看到一个数字,比如
你会看到一个数字,比如 47.2ms。这 47.2 毫秒里,浏览器干了四件事:
字节 → 字符 → Token → 节点 → DOM 树
这是 DOM 解析的完整路径。理解了这四步,你就理解了为什么 JS 会打断它------因为 JS 可能从中间插一杠子,把正在搭的积木碰倒。
下面我们一步步来。
二、第一步:字节 → 字符(浏览器在"识字")
浏览器从服务器拿到的是字节流------一堆 0 和 1。它得先"识字":
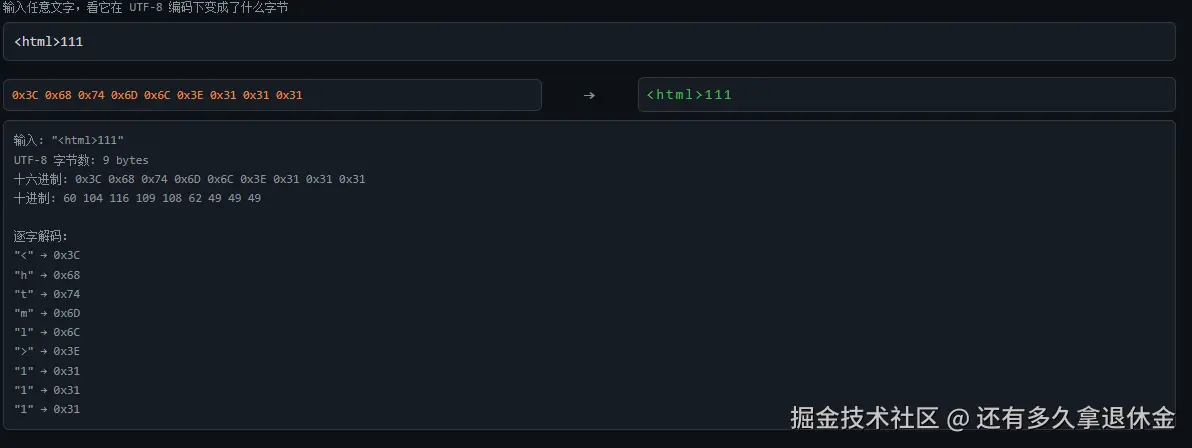
css
服务器发来的:0x3C 0x68 0x74 0x6D 0x6C 0x3E
↓ 按 UTF-8 解码
浏览器读到的:<html>怎么知道用 UTF-8 解码?两个地方说了算:
- 响应头
Content-Type: text/html; charset=UTF-8 - HTML 里的
<meta charset="UTF-8">
如果这俩不一致呢? 浏览器选错解码器 → 字节映射成错误的字符 → 页面乱码。这就是为什么乱码排查第一步永远是检查编码声明。
三、第二步:字符 → Token(状态机在"分词")
识完字,浏览器要搞清楚每个字是"标签名""属性"还是"文字内容"。这个活交给状态机------一个有 80 多个状态的自动机,逐字符读入,根据当前字符切换状态,碰到关键节点就"吐出"一个 Token。
举个例子,读入 <div id="app">:
bash
当前状态:Data(闲着等输入)
读到 '<' → 切换到 TagOpen 状态:"哦,标签来了"
读到 'd' → 切换到 TagName 状态,开始收集标签名
读到 'i' → 继续,标签名 = "di"
读到 'v' → 继续,标签名 = "div"
读到 ' ' → 标签名收完,切到 AttrBefore:"要读属性了"
读到 'i' → 切到 AttrName,收集属性名
...(省略属性值读取)
读到 '>' → 发出 StartTagToken { name:"div", id:"app" },回到 Data 状态关键点:状态机是逐字符推进的,它不知道后面会来什么。 读到 < 的时候,它不知道后面是 <div> 还是 </div> 还是 <!-- 注释 -->,它只知道"标签开始了,我得换个状态处理"。
这也解释了为什么 HTML 比 XML 容错------HTML 的状态机有大量"兜底逻辑":缺闭合标签?自动补上。属性没加引号?也行。</br> 当成 <br> 处理。XML 的状态机没有这些后门,一个错误直接报错停机。

四、第三步:Token → 节点(造零件)
每个 StartTagToken 都会变成一个 DOM 节点:
css
StartTagToken { name: "div" } → HTMLDivElement { nodeName: "DIV", childNodes: [] }
StartTagToken { name: "p" } → HTMLParagraphElement { nodeName: "P", childNodes: [] }
CharacterToken { value: "hi" } → Text { data: "hi" }这一步比较直白------Token 告诉你"要造什么类型的节点",浏览器就造一个对应的空节点出来,属性挂上,等后面组装。
五、第四步:节点 → DOM 树(用栈搭积木,这是关键!)
单有节点没用,得拼成树。浏览器用栈来维护父子关系:
arduino
规则很简单:
遇到 StartTag → 造节点 → 压栈(这个节点变成"当前父节点")
遇到 EndTag → 弹栈(回到上一层父节点)
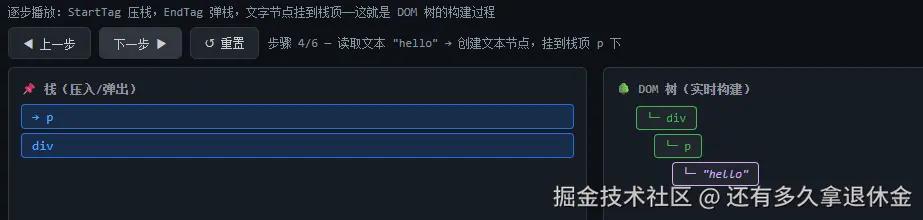
遇到文字 → 造文本节点,挂到栈顶节点下面用 <div><p>hello</p></div> 走一遍:
less
读取 <div> → 创建 div 节点 → 压栈 → 栈:[div] → div 挂到 document
读取 <p> → 创建 p 节点 → 压栈 → 栈:[div, p] → p 挂到 div 下面
读取 hello → 创建文本节点 → 挂栈顶 → "hello" 挂到 p 下面
读取 </p> → 弹栈 → 栈:[div] → p 子树完成
读取 </div> → 弹栈 → 栈:[] → div 子树完成注意看这个栈------它记录的是"当前正在构建的层级"。 栈顶就是"我正在给谁当爹"。压栈就是"我生了个儿子,现在给孙子当爹",弹栈就是"这个儿子生完了,回到上一层"。
六、好了,JS 来了------问题出在哪?
现在设想这个场景:浏览器正在用栈搭 DOM 树,栈里是 [html, body, div],正准备读下一个 Token------
突然遇到 <script>。
浏览器必须暂停解析。
为什么?因为 JS 可以调用 document.write(),往当前解析位置插入新的 HTML。
假设 JS 执行了 document.write('<p>surprise!</p>'),这意味着:
<p>surprise!</p>这段 HTML 要被插入到当前栈的位置 ------也就是<div>里面- 如果浏览器不暂停,继续往后解析,栈结构就跟 JS 插入的内容对不上了
- 父子关系就乱了
栈是解析器的命脉,JS 可能改栈,所以解析器必须等 JS 执行完才敢继续。
这就像你在搭乐高,搭到一半有人要往中间插一块------你必须让他先插完,确认结构没乱,才能继续搭。不然你搭你的他插他的,最后拼出来啥都不是。
那 JS 不调用 document.write() 呢?
浏览器不知道你会不会调。它不能赌------万一你调了呢?所以保险起见,一律暂停。
这就像安检:你包里可能没有违禁品,但安检员不能赌你没有,一律过机器。
七、document.write() 的两个世界
理解了栈,就能理解 document.write() 最容易踩的坑:
DOM 构建中调用:内容插入到栈顶位置,正常追加。因为栈还在,解析器知道"往哪插"。
js
// <div> 正在解析中
document.write("<p>插入的内容</p>");
// <p> 被插入到 <div> 里面,栈正常处理DOM 构建完成后调用 :document.write() 会调用 document.open(),清空整个页面,然后重写。因为栈已经空了------DOM 树搭完了,栈弹出所有元素归零了,没有"当前插入位置"。
js
// DOMContentLoaded 之后
document.write("<h1>新页面</h1>");
// 整个页面被清空,只剩 <h1>新页面</h1>这也是为什么 MDN 上一再警告"不要用 document.write()"------它跟解析器的栈机制绑得太紧,时机不对就炸。
八、解法:defer 和 async------让 JS 别那么霸道
既然问题是"JS 执行时解析器必须暂停",那解法就是让 JS 晚点执行:
defer:下载不挡路,执行等解析完
css
主解析器: ──解析HTML──────────────────完成──
defer脚本: ──下载── ──执行──- 下载和 HTML 解析并行,不阻塞
- 执行等 DOM 解析完(在
DOMContentLoaded之前) - 多个 defer 脚本按顺序执行
适用:需要操作 DOM 的脚本(比如绑定事件)
async:下载完就执行,不管解析器
csharp
主解析器: ──解析HTML────暂停──继续──完成──
async脚本: ──下载──────执行──- 下载和 HTML 解析并行,不阻塞
- 下载完立即执行,执行时暂停 DOM 解析
- 多个 async 脚本执行顺序不保证(谁先下完谁先跑)
适用:不依赖 DOM 的独立脚本(比如统计、广告)
没有 defer/async(默认)
主解析器: ──解析──暂停──────继续──
script: ──下载──执行──- 下载阻塞,执行也阻塞,最慢
- 唯一的"好处":脚本执行时能确保前面的 DOM 都解析完了
一张图总结
xml
| 下载HTML时 | 下载JS时 | 执行JS时 | 执行顺序
普通 <script> | 阻塞解析 | 阻塞解析 | 阻塞解析 | 按出现顺序
defer | 不阻塞 | 不阻塞 | 等解析完再执行 | 按出现顺序
async | 不阻塞 | 不阻塞 | 立即执行(阻塞)| 谁先下完谁先跑
放 </body>前 | 不阻塞 | 不阻塞 | 几乎不阻塞 | 按出现顺序九、CSS 呢?CSS 不阻塞解析,但会"迂回"影响
CSS 和 JS 不同------CSS 不阻塞 DOM 解析 。解析器遇到 <link rel="stylesheet"> 时不会暂停,DOM 树照常搭。
但 CSS 会阻塞两件事:
1. 阻塞渲染:浏览器必须等 CSSOM(CSS 的树结构)建好,才能把 DOM 树 + CSSOM 合成 Render Tree 来绘制。CSS 没好 = 画不出来。
2. 阻塞后续 JS 执行 :如果 JS 前面有还没下完的 CSS,JS 也得等。因为 JS 可能读取样式(getComputedStyle),浏览器要确保 JS 读到的是正确的值。
所以 CSS 放页面底部会出现 FOUC(Flash of Unstyled Content):
时间线:
DOM解析完成 → 没等CSS,先画一次(没样式,丑)→ CSS下完了 → 再画一次(有样式,好看)
用户看到:丑 → 闪烁 → 好看解法:CSS 放 <head> 里尽早加载,让 CSSOM 和 DOM 树并行构建,DOM 解析完 CSSOM 也差不多了,不用等。
十、预扫描器:浏览器偷偷干的聪明事
你可能会想:既然 <script> 阻塞解析,那外联脚本不是最慢的吗?------因为要等下载啊。
其实没那么惨。现代浏览器有个预扫描器(Preload Scanner):
xml
主解析器: ──解析──遇到<script>暂停──等JS──继续──
预扫描器: ───────────────────偷偷往后扫──发现<script src="b.js">──开始下载b.js──主解析器暂停的时候,预扫描器继续往后读 HTML,提前发现 <script src>、<link href>、<img src> 这些资源引用,立刻开始下载。
等主解析器恢复时,资源可能已经下完了------不用再等。
这就像你在排队等上菜,厨师先把后面几桌的菜备好了,等轮到你的时候直接上。
十一、用解析原理解释 SSR 为什么快
CSR(客户端渲染):
css
浏览器下载空HTML → 下载JS → JS执行 → JS请求数据 → JS生成DOM → 渲染
└──────── 多了这几步 ──────────┘SSR(服务端渲染):
css
浏览器下载完整HTML → 字节→字符→Token→节点→DOM树 → 渲染SSR 快的原因不是"服务端渲染有魔法",而是浏览器拿到的就是完整的 HTML,直接走四步解析就能出画面,省掉了 CSR 里 JS 下载、执行、请求数据、生成 DOM 那一大圈。
本质上就是:SSR 把"生成 DOM"的活从浏览器(JS 执行)搬到了服务器(拼 HTML 字符串),浏览器只需要做它最擅长的------解析 HTML。
十二、总结:一个原理串起一堆题
| 原理 | 推出结论 | 对应的题 |
|---|---|---|
| 字节→字符靠编码解码 | 编码不一致 → 乱码 | 页面乱码怎么排查? |
| 状态机逐字符推进 | HTML 有容错,XML 没有 | 为什么 HTML 比 XML 容错? |
| 栈维护 DOM 父子关系 | JS 可能改栈 → 必须暂停 | <script> 为什么阻塞? |
| 栈在建时才有"插入位置" | 栈空后 write() 清空页面 |
document.write() 什么时候炸? |
| defer/async 改变执行时机 | defer 等 DOM,async 不等 | defer 和 async 区别? |
| CSS 不阻塞解析但阻塞渲染 | 先画没样式的,再画有样式的 | FOUC 怎么来的? |
| 预扫描器提前下载资源 | 外联脚本不是最慢的 | 为什么外联脚本没那么惨? |
| SSR 直接给完整 HTML | 少走好几步 | SSR 为什么首屏快? |
一条线串下来:解析器在用栈搭 DOM 树 → JS 可能改栈 → 所以解析器必须等 JS → 所以 <script> 阻塞解析 → 所以有了 defer/async → 所以脚本位置很重要。
不是背答案,是从原理推出来的。