数据库的分区与分片
分区
数据库的分区是将数据库的表或索引分成若干个逻辑上独立的部分,并存储在不同的物理位置上。分区表是数据库层面做的分区,事务等都是数据库在管理,无需额外干涉。
优势:
- 按分区键查询可以限定检索的范围,提升查询性能;
- 允许在不同的分区上并行执行操作,如涉及sum()和count()等聚合函数查询时,可以在每个分区上并行处理,最终汇总所有分区的结果;
劣势:
- 可并行的IO资源,设备计算资源与内存等资源无法突破单体限制;
- 查询必须包含分区键,且分区键必须是主键的一部分(mysql)。
所以,在mysql中想用分区,需要设定联合主键,把分区键放入联合主键中。
分区类型:
范围分区(Range Partitioning):基于连续的值范围。
列表分区(List Partitioning):基于固定的值列表。
哈希分区(Hash Partitioning):基于列值的哈希码。
应用场景:
时间序列数据:按时间戳分区。
地理位置数据:按地区或国家分区。
分片
定义:
分片是将数据水平分割到多个服务器或节点上的过程,每个节点存储数据的一个子集。
目的
扩展性:通过增加更多的节点来扩展系统的存储容量和处理能力。分表可以用不同的数据引擎存储,只要前置代理组件可以正常路由就行。
负载均衡:将负载分布到多个节点上。
分片键
类似于分区键,分片键用于确定数据应该存储在哪个分片上。
类型
基于范围的分片:数据根据值的范围分配到不同的分片。容易导致数据分布不均匀,尾部热点问题。如按日期分片,最近日期的数据查询总是最多的,之前日期的数据查询很少。
基于哈希的分片:数据根据分片键的哈希值分配到分片。缺点是难以扩展,增加节点需要把所有的数据重新hash。解决方式是利用一致性hash算法进行分片。
缺点
额外的前置代理增加了复杂度;
分布式事务需要考虑;
聚合,分页,排序困难;
比较和区别
范围和限制: 分区通常在单个数据库实例内部进行,而分片可能跨越多个数据库实例或服务器。
管理: 分区通常由数据库管理系统自动管理,而分片可能需要额外的中间件或服务来管理数据的分布和路由。
扩展性: 分片通常用于需要水平扩展的场景,可以通过增加更多的分片节点来扩展系统。
复杂性: 分片可能比分区更复杂,因为它涉及到跨多个节点的数据管理和一致性问题。
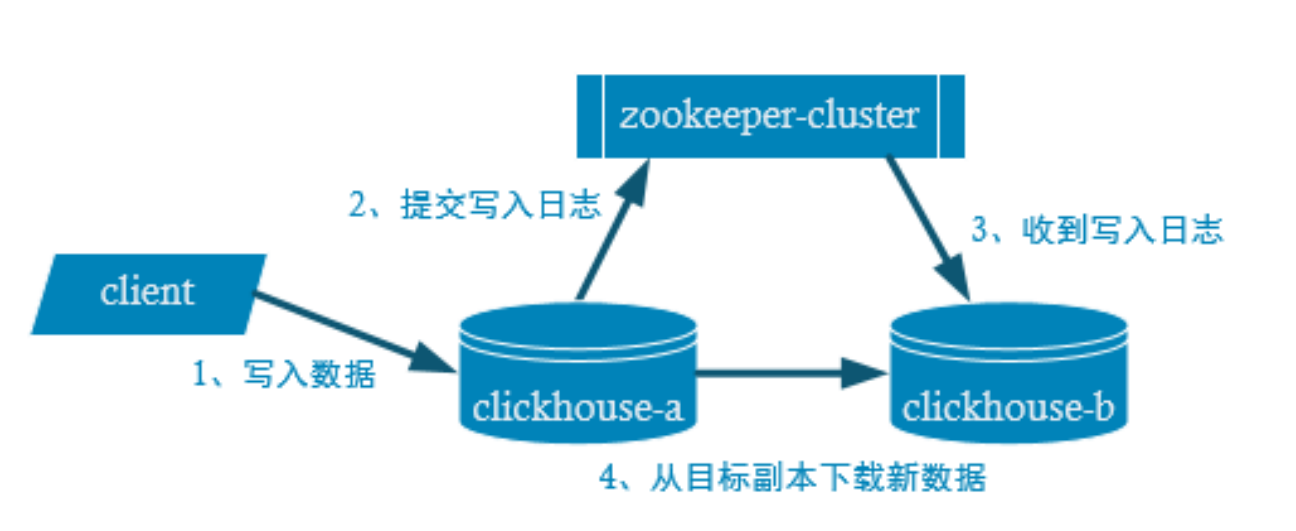
ClickHouse集群原理
ClickHouse 采用典型的分组式的分布式架构,具体集群架构如上图所示。
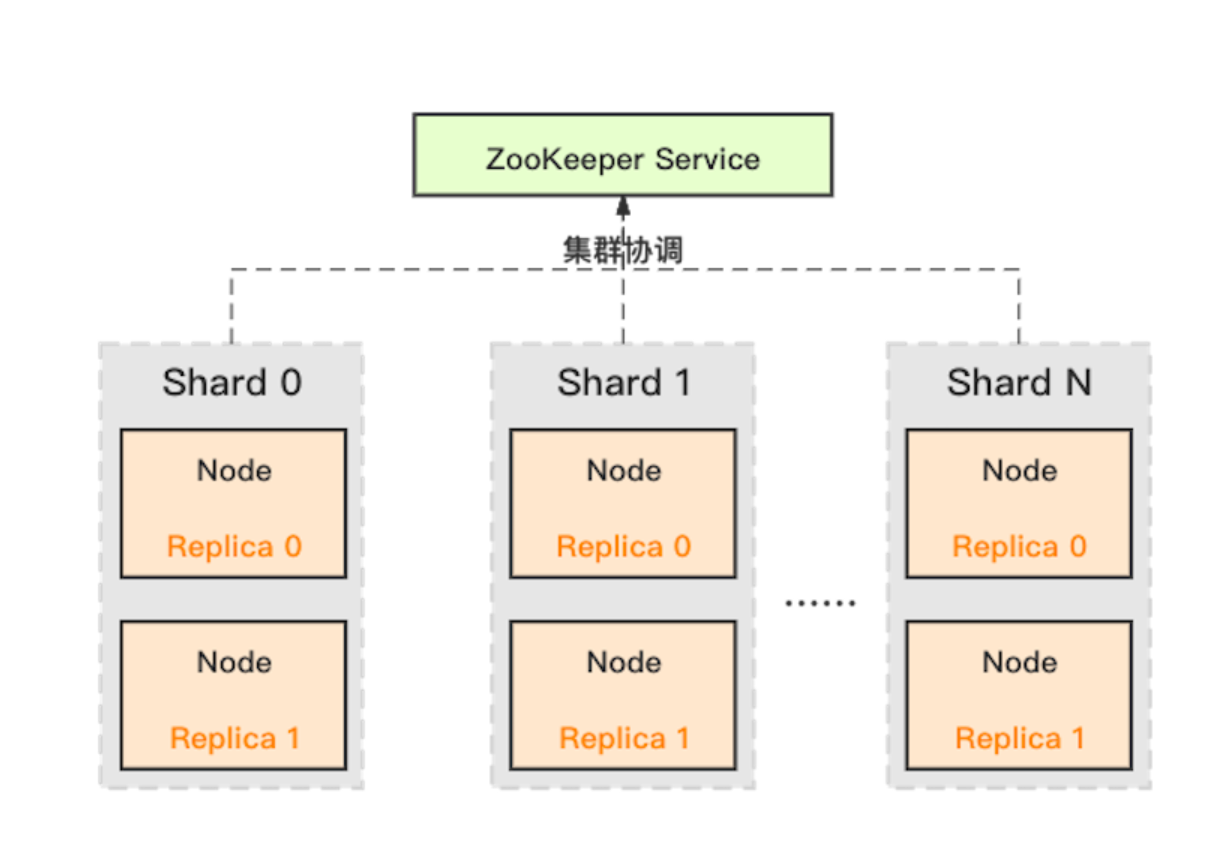
分片集群
集群内划分为多个分片或分组(Shard 0 ... Shard N),通过 Shard 的线性扩展能力,支持海量数据的分布式存储计算。
分布式表引擎(Distributed)
ClickHouse提供了分布式表引擎。与MergeTree引擎不同的是,Distributed引擎自身不存储任何数据,而是作为数据分片的透明代理,能够自动路由数据至集群中的各个节点,所以Distributed表引擎需要和其他数据表引擎一起协同工作。
有点类似于 MyCat 之于 MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
从实体表层面来看,一张分片表由两部分组成:
本地表:通常以_local为后缀进行命名。本地表是承载数据的载体,可以使用非Distributed的任意表引擎,一张本地表对应了一个数据分片。
分布式表:通常以_dist为后缀进行命名。分布式表只能使用Distributed表引擎,它与本地表形成一对多的映射关系,日后将通过分布式表代理操作多张本地表。
对于分布式表与本地表之间表结构的一致性检查,Distributed表引擎采用了读时检查的机制,这意味着如果它们的表结构不兼容,只有在查询时才会抛出错误,而在创建表时并不会进行检查。
集群写入数据流程(3分片2副本)
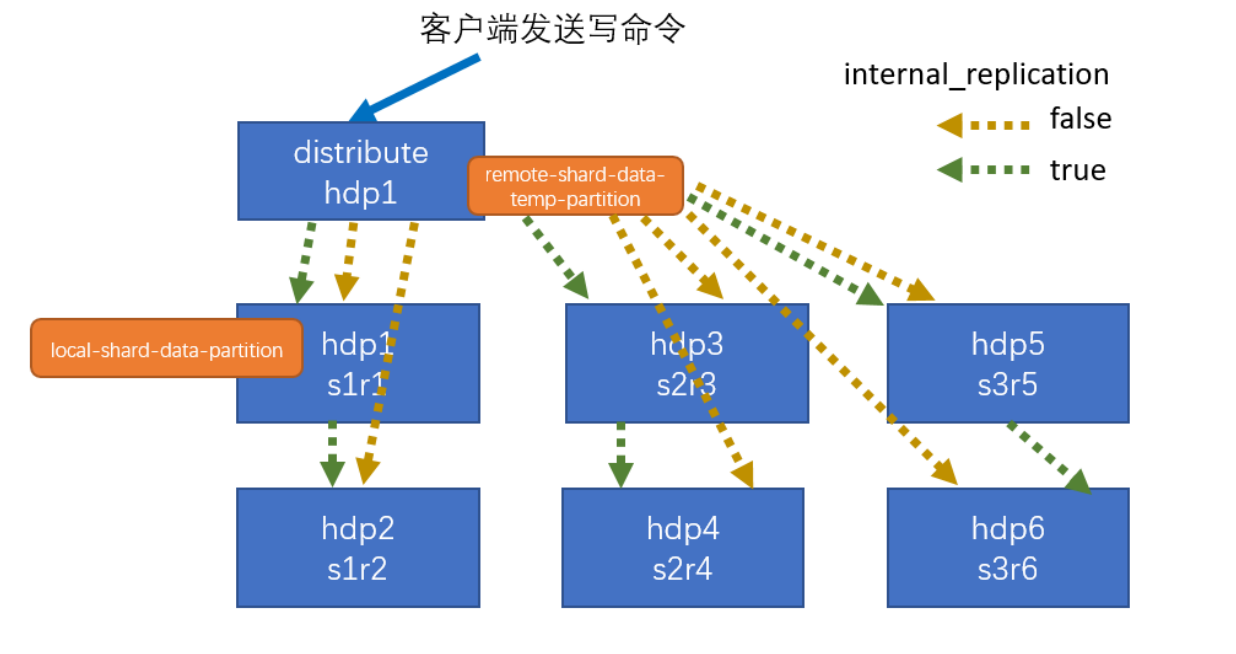
internal_replication是内部同步机制。黄色虚线代表未开启,绿色虚线代表开启。
当internal_replication关闭时,分布式表收入写入命令,会对3分片2副本的6个节点进行数据同步。
当internal_replication开启时,分布式表只对3个分片的某个副本进行数据同步。然后由副本内部进行其他副本的数据同步。
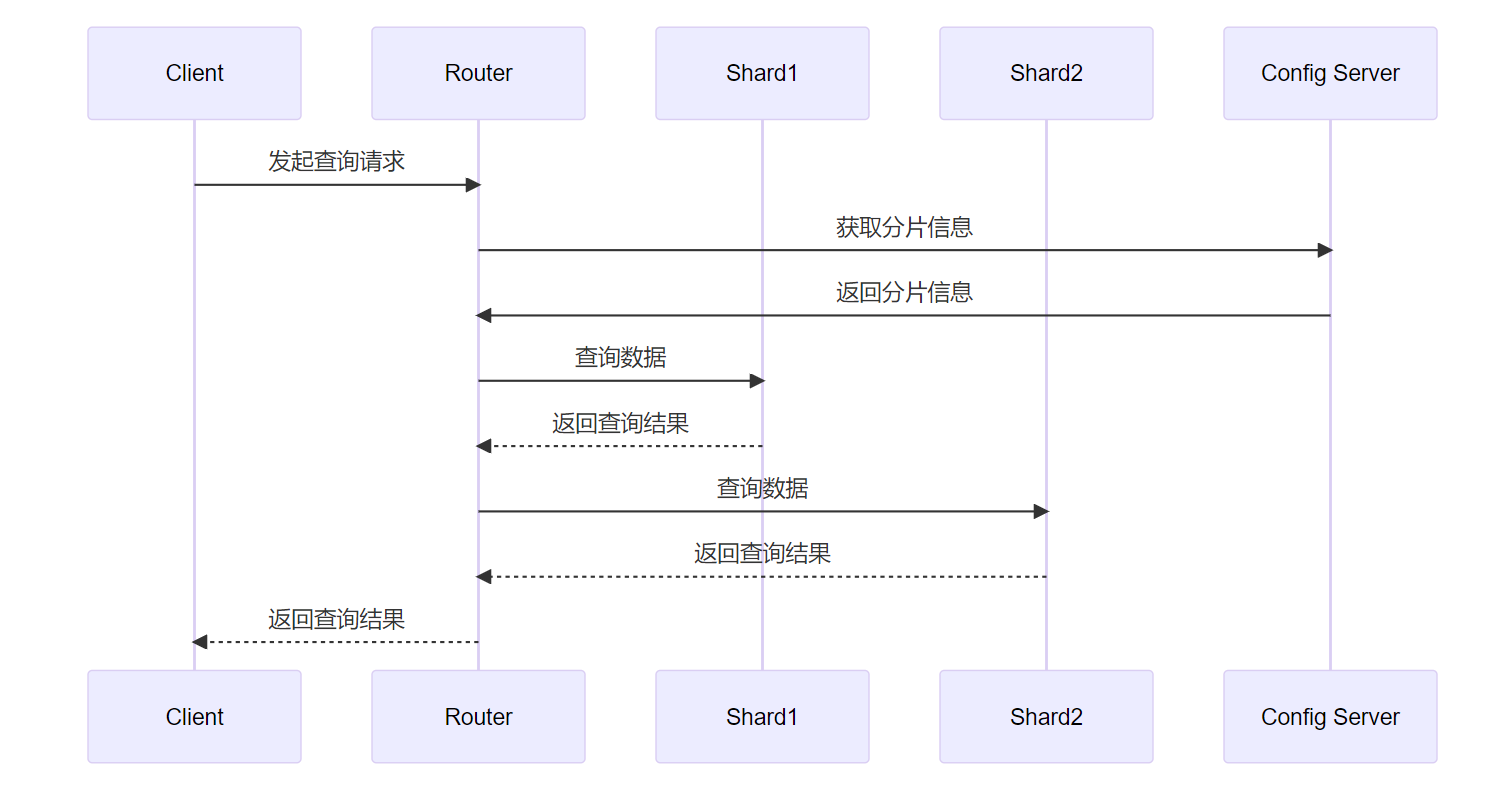
集群读取流程(3 分片 2 副本共 6 个节点)
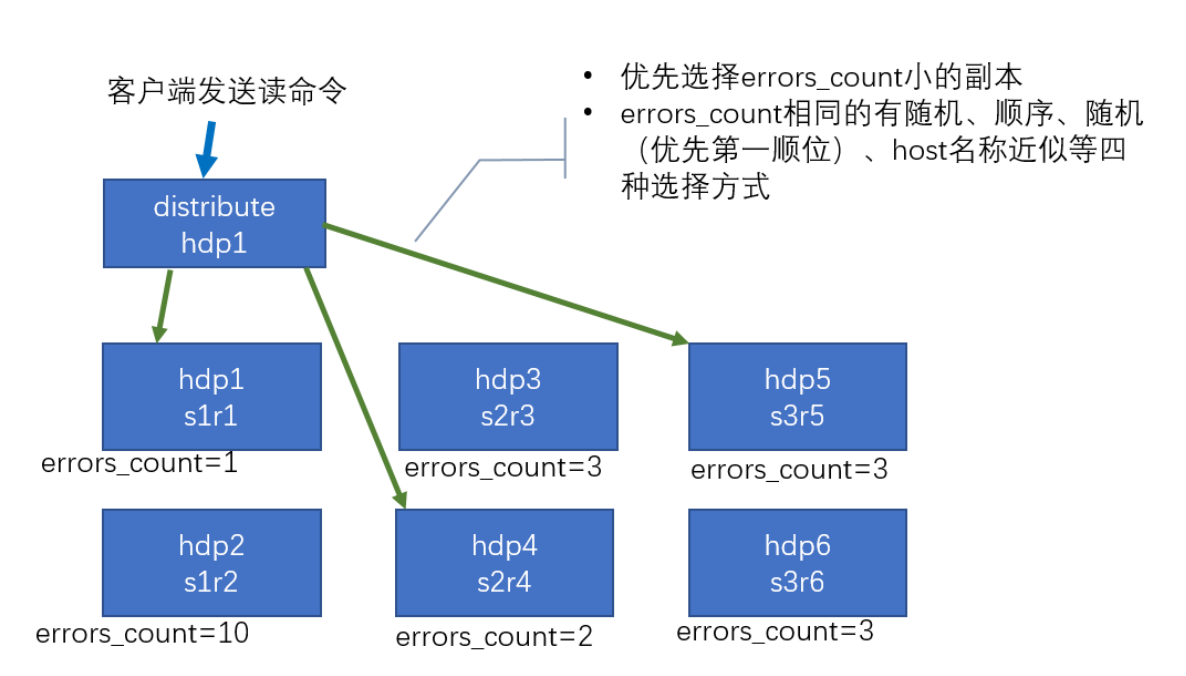
分布式表收到读取命令后,选择从哪个分片里获取数据。当定位到分片后,通过errors_count参数选择使用哪个副本。errors_count的含义是分布式表从某个分片的某个副本拉取数据时,由于网络问题,数据问题等等问题造成报错后,这个副本的errors_count就加1。分布式表每次都从errors_count最小的副本拉取数据。
当副本之间的errors_count相同时,分布式表有随机,顺序,host名次近似等方式来选择副本。
副本集群
每个 Shard 内包含一定数量的节点(Node,即进程),同一 Shard 内的节点互为副本,保障数据可靠。ClickHouse 中副本数可按需建设,且逻辑上不同 Shard 内的副本数可不同。
副本的目的主要是保障数据的高可用性,即使一台 ClickHouse 节点宕机,那么也可以从其他服务器获得相同的数据。