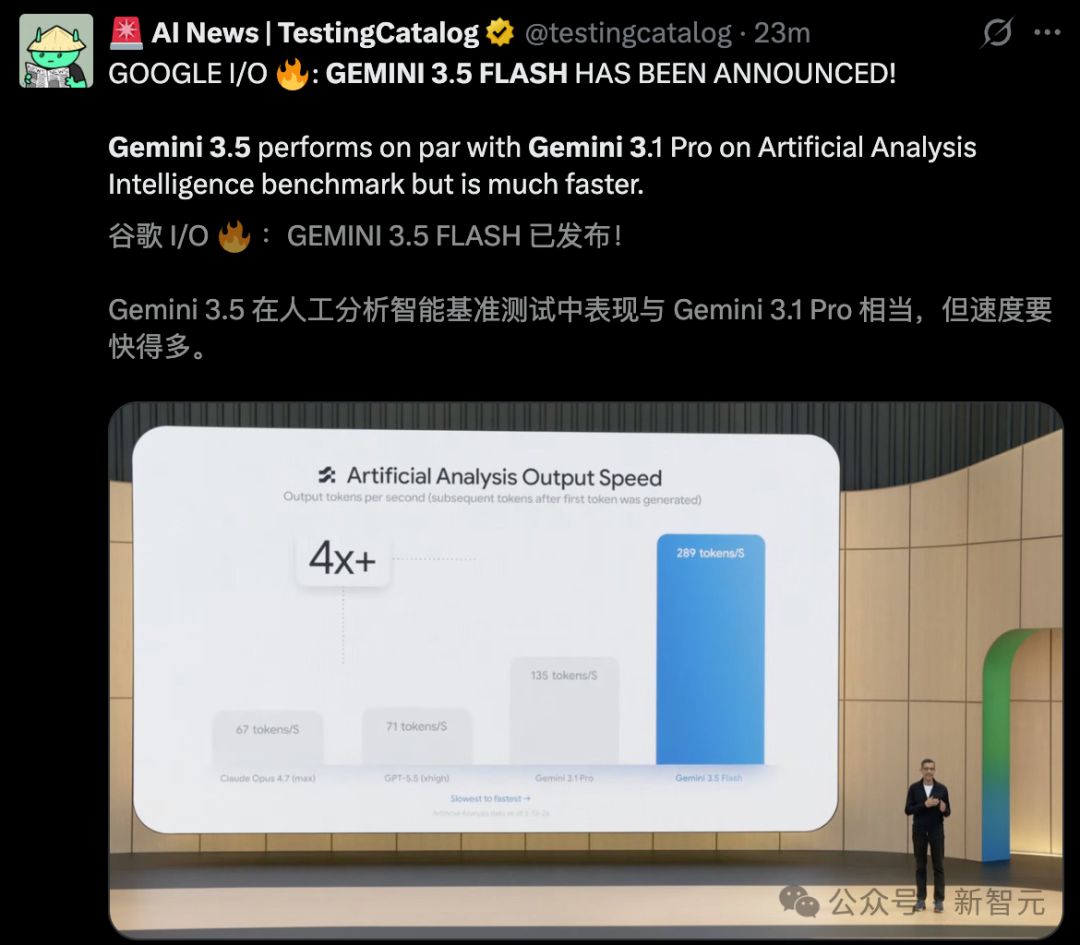
2026年5月,全球大模型赛道迎来密集重磅更新,阿里云与谷歌先后推出全新旗舰模型,彻底刷新中端旗舰与国产模型的能力天花板。5月20日阿里云峰会正式发布Qwen3.7-Max(千问3.7旗舰版) ,登顶国产大模型综合榜单;5月19日Google I/O 2026开发者大会上线Gemini 3.5 Flash,以越级性能、极致速度和超低成本重塑海外轻量化旗舰标准。
两款模型均主打**智能体优先(Agent-First)**设计、百万级超长上下文、顶级编程与自动化能力,同时面向开发者免费/低成本开放,成为当下个人创作、企业落地、智能体开发的最优选择之一。
本文将从模型基础介绍、核心能力拆解、双模型全方位对比、与全球顶级模型横向PK、实战使用方式、优劣势总结、场景选型建议七个维度,全方位解析两款新模型,帮你快速吃透核心差异、精准落地选型。
一、两款模型基础定位与发布背景
1. Qwen3.7-Max:国产全能智能体旗舰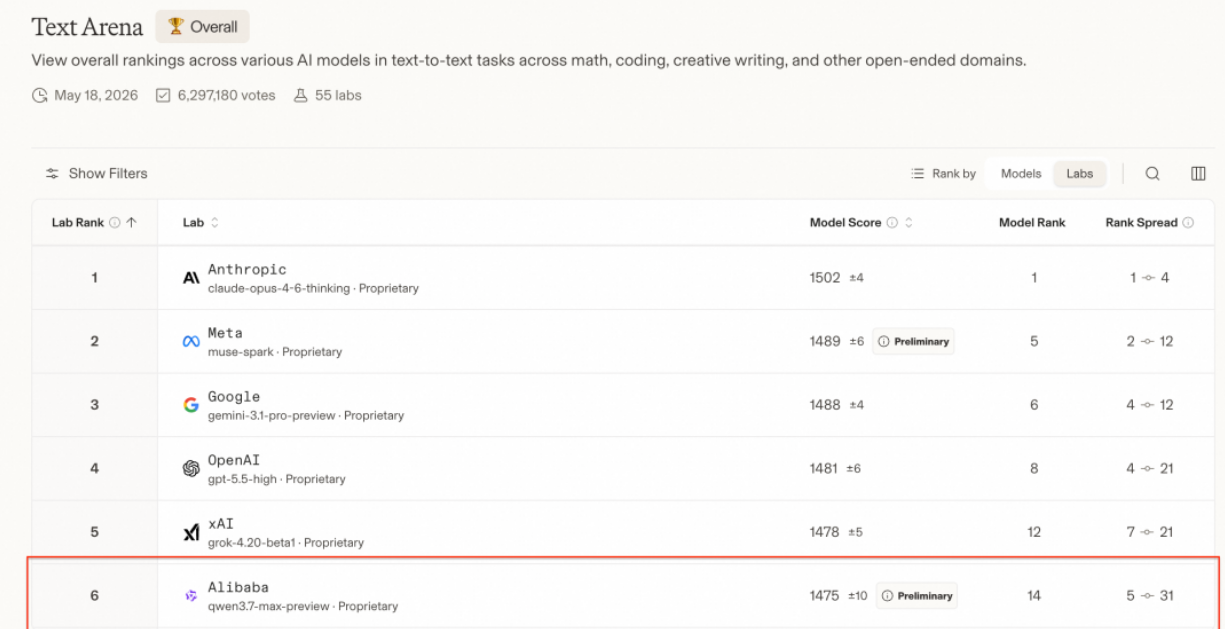
Qwen3.7-Max是阿里云百炼2026年重磅推出的新一代国产旗舰大模型,核心定位是面向超长复杂任务、全自主智能体、工程级编程的全能推理模型,对标GPT-5.5、Claude Opus 4.7等国际顶级闭源模型,是目前综合实力排名第一的国产大模型。
该模型核心突破在于长周期自主执行能力 与低幻觉精准推理 ,摒弃了传统模型"单次对话、单次任务"的局限,支持数十小时不间断自主任务迭代,完美适配复杂工程开发、企业工作流自动化、超长文档分析等硬核场景,同时深度适配国内网络、业务场景与合规要求。
2. Gemini 3.5 Flash:谷歌越级性价比极速模型
Gemini 3.5 Flash是Google I/O 2026主推的核心模型,定位为高速、低成本、强智能体的轻量化越级旗舰。打破了行业"轻量模型性能弱、旗舰模型成本高、速度慢"的固有认知,以中端模型的成本和速度,实现了前代旗舰Gemini 3.1 Pro 90%以上的综合能力,多项核心指标完成越级超越。
其核心优势聚焦极致推理速度、超低调用成本、原生多模态、标准化智能体能力 ,主打高频实时交互、大规模API批量调用、轻量化智能体部署,是海外开发者性价比首选模型,且面向全球用户免费开放基础能力。
二、两款模型核心能力深度拆解
1. Qwen3.7-Max 核心硬核能力
Qwen3.7-Max所有能力均围绕"复杂长任务自主落地"打造,主打稳定、精准、可落地,核心能力集中在四大维度:
-
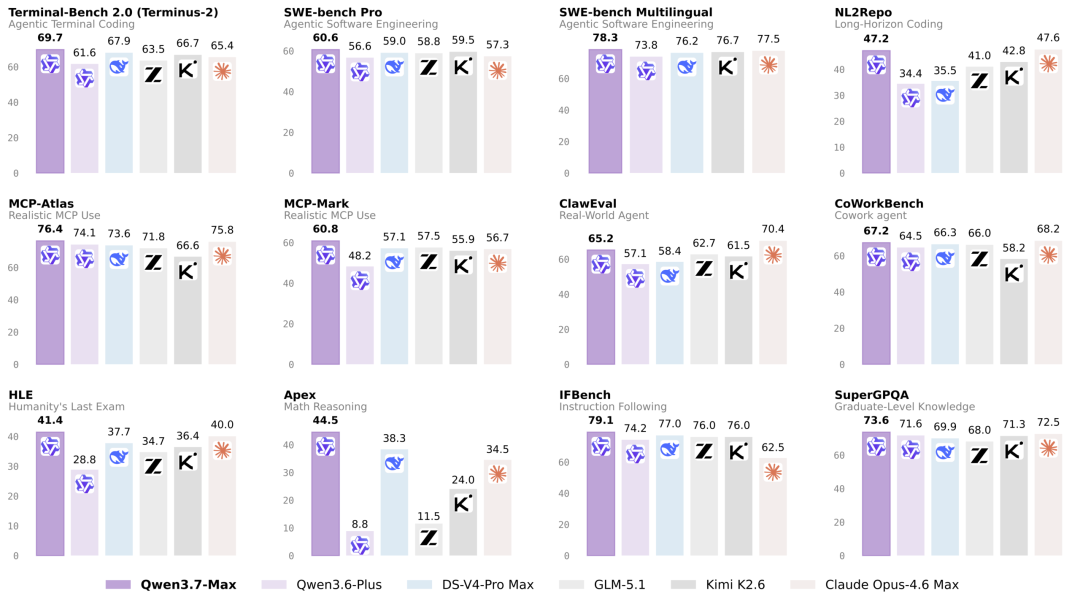
超长周期自主智能体能力(行业顶尖):支持35小时不间断全自主任务执行,可完成超1000次工具调用、数百次自我迭代优化。官方实测中,可在零人工干预的空白环境下,自主完成内核代码分析、编写、编译、测试、迭代全流程,最终实现推理速度10倍优化,是目前国产模型中唯一具备超长程工程级自主优化能力的模型。原生支持MCP协议、多智能体编排,可无缝对接Claude Code、OpenClaw等主流框架。
-
顶级工程编程能力:在Terminal Bench 2.0-Terminus编码基准测试中得分69.7,超越DeepSeek-v4-pro-Max、Claude Opus 4.6等主流旗舰模型,可独立完成前端开发、后端工程搭建、多文件协同开发、代码调试与性能优化,适配企业级完整项目开发场景。
-
百万级超长上下文+低幻觉优化:支持100万Token超长上下文窗口,可一次性处理75万字文本、数万行完整代码库、数十小时视频脚本,无需拆分文档、分段处理。同时完成幻觉大幅优化,幻觉率下降21.3个百分点,从44.2%降至22.9%,长文本精准度、事实性准确率大幅提升,解决了大模型长文本上下文失真、逻辑断裂的痛点。
-
双推理模式适配全场景:内置Thinking深度推理模式与Non-Thinking极速模式。深度模式专攻复杂推理、数学计算、工程编码、多步骤复杂任务;极速模式适配日常对话、轻量办公、快速检索,兼顾精度与效率。同时强化多语言、科学推理、数据分析能力,适配科研、办公、商业分析等多元场景。
2. Gemini 3.5 Flash 核心硬核能力
Gemini 3.5 Flash以"极速、便宜、能打、通用"为核心亮点,能力全面均衡,无明显短板,主打规模化落地,核心能力如下:
-
极致推理速度,碾压同级旗舰:推理速度达到280-300 tokens/s,是GPT-5.5、Claude Opus 4.7的4倍,较上一代Gemini 3.1 Pro提速40%,可实现对话、代码生成、内容创作秒级响应,完美适配实时交互、高并发API调用场景。
-
越级编码与智能体能力:Terminal-Bench 2.1编码得分76.2%,超越前代旗舰Gemini 3.1 Pro(70.3%);MCP-Atlas智能体基准得分83.6%,领先GPT-5.5(75.3%)、Claude Opus 4.7(79.1%),工具调用、子任务编排、上下文管理能力行业顶尖,适配各类智能体工作流开发。
-
百万上下文+大输出窗口:同样支持100万Token超长输入上下文,输出窗口最高可达64K Token,可一次性输出完整长文、全套代码方案、长篇报告,无需分段生成,大幅提升内容生产效率。
-
全模态覆盖+低成本规模化:原生支持文本、图片、音频、视频多模态输入输出,图文理解、视频内容解析、音频转写分析能力全面升级。同时成本大幅下调,较Gemini 3.1 Pro成本降低35%,API调用性价比极高,适合企业大规模批量部署、高频调用场景。
-
三档推理模式灵活切换:提供Low(极速)、Medium(均衡默认)、High(深度推理)三档模式,分别适配轻量日常任务、常规智能体开发、高难度数理科研任务,场景适配性极强。
三、Qwen3.7-Max vs Gemini 3.5 Flash 全方位对比
为方便直观对比,我从定位、性能、速度、成本、上下文、智能体、编程、适配场景、优缺点9个核心维度整理详细对比表:
| 对比维度 | Qwen3.7-Max | Gemini 3.5 Flash |
|---|---|---|
| 模型定位 | 国产全能工程级智能体旗舰,重复杂长任务落地 | 全球高性价比极速越级模型,重规模化通用场景 |
| 推理速度 | 均衡稳定,长任务连贯性极强,瞬时速度略低 | 极致极速,300tokens/s,碾压主流旗舰模型 |
| 调用成本 | 国内免费试用,企业API平价,合规成本低 | 全球低价,输入1.5/百万token、输出9/百万token,性价比极高 |
| 上下文窗口 | 100万Token输入,超长文本稳定处理 | 100万Token输入,64K Token超大输出 |
| 核心优势 | 35小时超长自主任务、低幻觉、国产适配、工程级编程、企业工作流自动化 | 极速响应、多模态均衡、智能体基准领先、低成本、高并发适配 |
| 核心短板 | 瞬时推理速度不及Flash,海外生态较弱 | 超长程复杂任务自主迭代能力弱于Qwen3.7-Max,长任务稳定性一般 |
| 编程能力 | 工程落地更强,适合完整项目开发、内核优化 | 代码生成更快,适合快速写代码、脚本开发、问题调试 |
| 智能体能力 | 长周期多步骤自主执行、自我迭代优化顶尖 | 短平快智能体工作流、工具调用精准度行业领先 |
| 最佳场景 | 企业级自动化、复杂工程开发、超长文档分析、国产合规项目 | 个人实时交互、高并发API部署、多模态创作、轻量化智能体 |
四、与全球顶级大模型横向对比(2026最新梯队)
两款新模型发布后,直接冲击GPT-5.5、Claude Opus 4.7、DeepSeek-v4、GLM5.1等顶级模型的市场格局,我们按综合能力分层对比:
1. 综合性能梯队定位
第一梯队(顶级旗舰):GPT-5.5、Claude Opus 4.7
第二梯队(越级新旗舰):Qwen3.7-Max、Gemini 3.5 Flash(接近第一梯队90%+能力)
第三梯队(传统旗舰):Gemini 3.1 Pro、DeepSeek-v4-pro-Max、GLM5.1、Kimi-K2.6
2. 核心维度横向PK亮点
-
智能体能力:Gemini 3.5 Flash(83.6分)> Claude Opus 4.7 > GPT-5.5 > Qwen3.7-Max > 其他国产模型
-
工程编程能力:Qwen3.7-Max 超越 Claude Opus 4.6、DeepSeek-v4-pro-Max,逼近GPT-5.5工程落地水平
-
长任务稳定性:Qwen3.7-Max 独占一档,35小时超长自主迭代能力碾压所有同级模型
-
推理速度&性价比:Gemini 3.5 Flash 全方位领先所有顶级旗舰模型,成本仅为GPT-5.5的1/15~1/20
-
幻觉控制:Qwen3.7-Max 优化显著,幻觉率大幅降低,长文本事实性优于多数海外旗舰
五、两款模型实战使用方式(零门槛上手)
1. Qwen3.7-Max 使用渠道
-
免费在线使用:千问APP、千问网页端、阿里云百炼平台已全面上线,个人用户可直接切换3.7-Max模型免费体验
-
开发者接入:支持OpenAI兼容接口,无需大幅修改代码即可快速迁移,适配国内服务器部署,合规性拉满
-
场景适配:优先用于企业办公自动化、代码工程开发、超长合同/论文/代码库分析、国产AI项目落地
2. Gemini 3.5 Flash 使用渠道
-
免费在线使用:Gemini APP、网页端直接下拉选择「3.5 Flash」模型,全球用户免费开放全基础能力
-
API接入:Google Cloud、OpenRouter同步上线,低价按量计费,支持高并发批量调用
-
场景适配:优先用于实时对话、多模态创作、短视频图文解析、轻量化智能体开发、大规模API集成项目
六、全面优劣势深度总结
1. Qwen3.7-Max 优势与劣势
核心优势:
-
超长程智能体能力独一档,支持数十小时自主任务迭代,零人工干预完成复杂工程优化;
-
幻觉控制大幅升级,长文本精准度、逻辑连贯性远超传统国产模型;
-
工程编程落地能力强,适配企业级完整项目开发,不止会写代码更会优化迭代;
-
纯国产模型,适配国内网络、合规要求,无访问壁垒,企业落地无风险;
-
双推理模式灵活适配,兼顾深度任务与日常使用场景。
核心劣势:
-
瞬时推理速度不及Gemini 3.5 Flash,高频秒级响应场景略有差距;
-
海外生态、开源社区活跃度弱于谷歌系列模型;
-
多模态能力相对均衡,无绝对碾压级优势。
2. Gemini 3.5 Flash 优势与劣势
核心优势:
-
速度与性价比天花板,极速响应+超低调用成本,适合规模化落地;
-
短周期智能体、工具调用、多模态综合能力越级,碾压前代旗舰;
-
百万上下文+超大输出窗口,内容生产效率极高;
-
全球生态完善,开源工具、开发文档丰富,开发者上手门槛低;
-
三档推理模式全覆盖,适配从日常对话到科研攻坚的全场景。
核心劣势:
-
超长程复杂任务稳定性不足,无法支撑数十小时自主迭代,长链路任务易出错;
-
深度工程落地、内核优化能力弱于Qwen3.7-Max;
-
国内访问存在网络壁垒,企业合规落地成本高于国产模型。
七、最终场景选型建议(精准避坑)
-
优先选 Qwen3.7-Max 的场景:国内企业落地、国产合规项目、复杂代码工程开发、超长文档处理、企业工作流自动化、需要长时间自主迭代的智能体任务、科研数据分析、涉密/本土业务场景。
-
优先选 Gemini 3.5 Flash 的场景:个人日常极速交互、多模态图文/视频创作、高并发API批量部署、轻量化智能体开发、海外业务项目、快速脚本开发、实时问答服务。
-
双模型组合最优方案:长周期复杂任务、工程落地用Qwen3.7-Max;日常交互、高频调用、多模态创作、轻量化部署用Gemini 3.5 Flash,互补覆盖全场景需求。
八、总结与行业展望
2026年5月的这一波模型更新,标志着大模型正式进入**「智能体规模化落地时代」。Qwen3.7-Max代表了 国产模型工程化、长任务落地的最高水平**,打破了海外模型在高端复杂场景的垄断;而Gemini 3.5 Flash则重新定义了通用大模型的性价比与速度标杆,让高阶AI能力可以低成本规模化普及。
两款模型各有擅长,不存在绝对的优劣:追求稳定落地、复杂攻坚、国产合规 ,Qwen3.7-Max是首选;追求极速响应、低成本、通用多场景、海外生态,Gemini 3.5 Flash无可替代。后续随着模型持续迭代,AI智能体、自动化工程、多模态生产力场景将迎来全面爆发。