文章目录
-
-
-
- 前言:数据洪流下的必然选择
- [一、 宏观视野:大数据视角下的时序数据库演进](#一、 宏观视野:大数据视角下的时序数据库演进)
- [二、 对标国际:与国外主流产品的横向对比](#二、 对标国际:与国外主流产品的横向对比)
- [三、 国产之光:Apache IoTDB 的技术优势](#三、 国产之光:Apache IoTDB 的技术优势)
- [四、 实战演练:Apache IoTDB 快速上手](#四、 实战演练:Apache IoTDB 快速上手)
- [五、 选型建议与总结](#五、 选型建议与总结)
-
-
前言:数据洪流下的必然选择
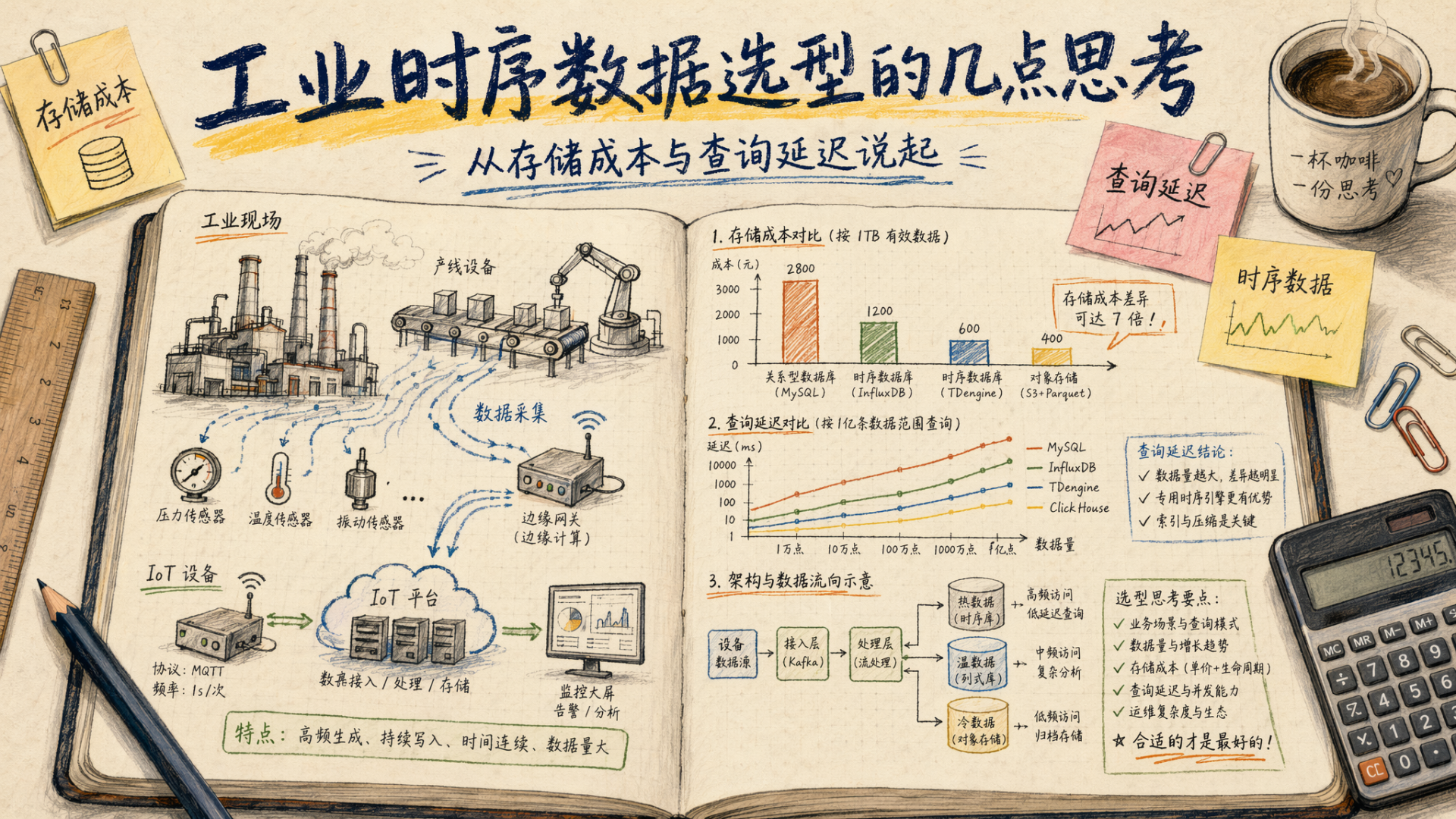
在数字化转型的浪潮中,我们正被淹没在数据的海洋里。据相关机构预测,到2025年,全球产生的数据总量将达到惊人的175 ZB(泽字节)。在这些海量数据中,有一种数据呈现出爆发式的增长,那就是时序数据。从工业物联网的设备传感器上报,到金融市场的毫秒级交易记录,再到城市交通的实时监控数据,它们都有一个共同的特征:以时间戳为核心,持续不断地产生,且写多读少。
面对如此海量的时序数据,传统的行式关系型数据库(如MySQL、Oracle)显得捉襟见肘,高昂的存储成本和低效的查询性能成为了业务发展的瓶颈。此时,时序数据库(Time Series Database, TSDB) 应运而生。它们专为处理时间序列数据而设计,通过列式存储、高压缩率、降采样等技术,极大地提升了写入和查询效率。
然而,面对市场上层出不穷的时序数据库产品,企业该如何选型?本文将站在大数据的视角,从技术演进和国外产品对比的角度出发,为您提供一份详尽的时序数据库选型指南,并重点介绍国产开源佼佼者------Apache IoTDB 的技术特性与实践应用。
一、 宏观视野:大数据视角下的时序数据库演进
在大数据的架构体系中,时序数据库通常扮演着"数据接入层"和"边缘计算层"的角色。它与传统的OLTP(在线事务处理)和OLAP(在线分析处理)有着本质的区别:
- 数据特征差异:时序数据具有冷热分明、数据量巨大、写入速度极快、按时间范围查询频繁等特点。
- 技术栈融合:在经典的Lambda架构或Kappa架构中,时序数据库往往作为Speed Layer(速度层),负责快速接收和查询最新数据,而将历史数据归档到Hadoop、Spark等Batch Layer(批处理层)中。
从技术演进来看,早期的时序数据库多为基于LevelDB、RocksDB等LSM-Tree存储引擎的二次开发(如InfluxDB、OpenTSDB)。随着云原生概念的普及,新一代的时序数据库开始深度拥抱云原生架构,支持容器化部署、微服务治理以及存算分离。
二、 对标国际:与国外主流产品的横向对比
要理解当前时序数据库的格局,不得不提国外的几款明星产品。它们代表了不同时序数据库的发展路线:

- InfluxDB:无疑是国际上最著名的开源时序数据库之一。它拥有丰富的生态和类SQL的查询语言(Flux/InfluxQL)。但在高基数(High Cardinality)场景下,其性能可能会出现断崖式下降,且集群版闭源,这在企业级应用中是一个痛点。
- TimescaleDB:基于PostgreSQL扩展而来,继承了PostgreSQL的强大功能和稳定性。它采用了超表(Hypertable)的概念来管理时序数据,非常适合那些对SQL兼容性要求极高、又有一定时序处理需求的混合负载场景。
- VictoriaMetrics:由Prometheus的作者开发,主打高性能和高性价比,常被用作Prometheus的长期存储后端,在云原生监控领域占据一席之地。
选型启示:国外的产品在成熟度和生态上确实有优势,但在面对国内特定的数据合规要求、国产化替代趋势以及某些特定工业场景(如极端高并发、强事务一致性要求)时,往往显得水土不服。我们需要寻找一款既能对标国际水平,又更懂中国本土业务场景的产品。
三、 国产之光:Apache IoTDB 的技术优势
在上述背景下,Apache IoTDB 的出现打破了国外的技术壁垒。作为Apache基金会的顶级项目,IoTDB 从诞生之初就聚焦于工业互联网场景,经过多年的打磨,已经成长为全球顶级的时序数据库项目。
IoTDB 的核心优势主要体现在以下几个方面:
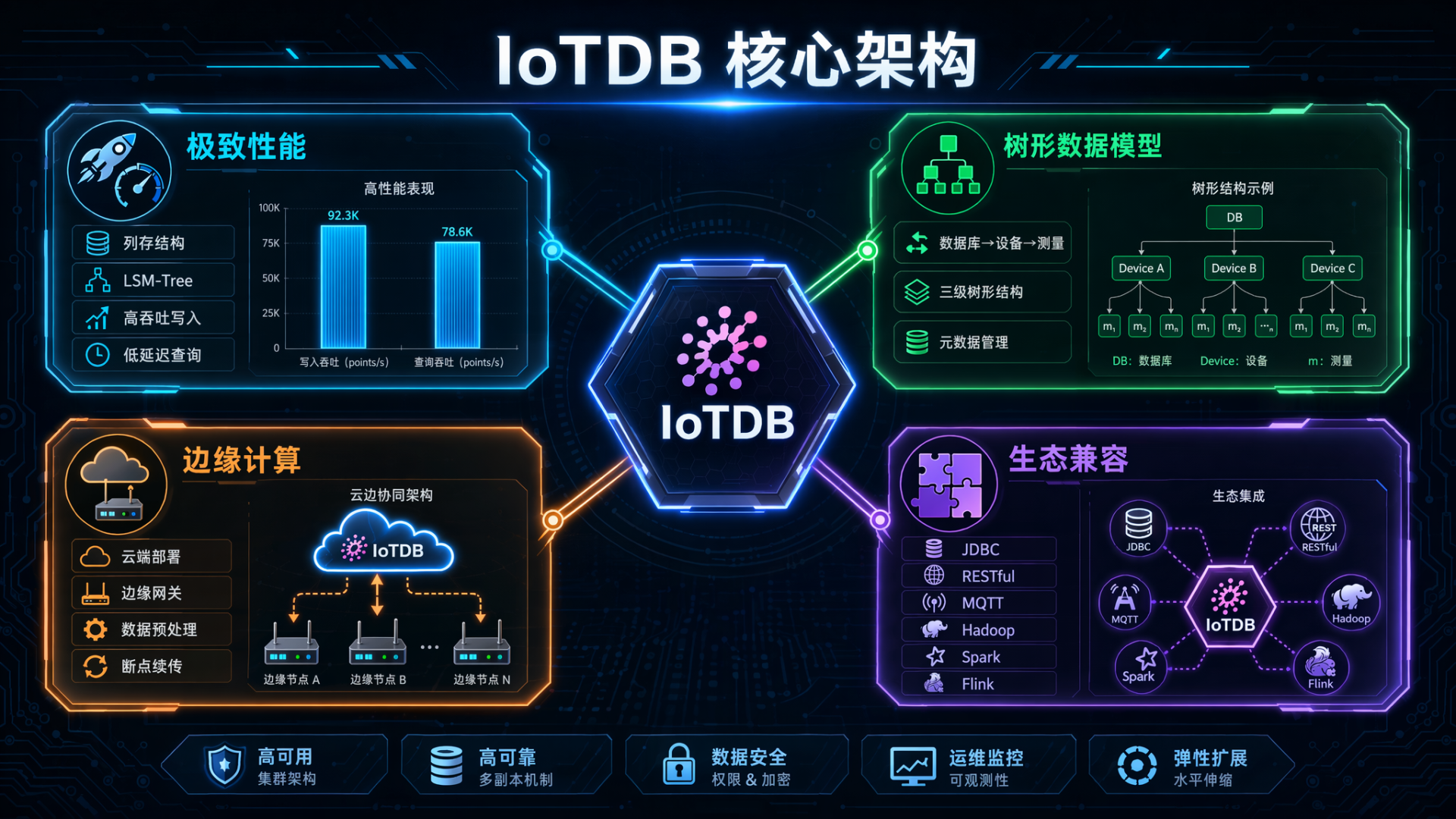
1. 极致的写入与查询性能
IoTDB 采用了专门为时序数据设计的列存结构和LSM-Tree优化算法。在公开的性能测试中,IoTDB 在相同的硬件条件下,其写入吞吐量和查询响应速度均处于世界领先水平。
2. 强大的树形数据模型与元数据管理
IoTDB 引入了类似于文件系统的"数据库-设备-测量"三级树形结构。这种结构非常契合工业现场的设备层级关系,使得数据组织更加直观,同时也极大地降低了元数据管理的开销。
3. 原生支持边缘计算
IoTDB 不仅可以在云端部署,还能直接在边缘网关设备上运行。它支持边缘侧的数据预处理、压缩和断点续传,实现了云边端一体化的数据管理。
4. 完善的生态兼容
IoTDB 提供了JDBC、RESTful、MQTT等多种接口,能够无缝对接Hadoop生态、Spark、Flink以及主流的工业组态软件。
四、 实战演练:Apache IoTDB 快速上手
光说不练假把式。下面我们通过一段实操代码,来感受一下 IoTDB 的魅力。
1. 环境准备与启动
首先,我们需要下载并安装 IoTDB。你可以通过以下链接获取官方安装包:
- 下载链接:https://iotdb.apache.org/zh/Download/
- 企业版官网链接:https://timecho.com (如需企业级支持与高级功能)
下载完成后,解压并启动单机版 IoTDB:
bash
# 解压下载的压缩包
tar -zxvf apache-iotdb-1.3.0-all-bin.tar.gz
cd apache-iotdb-1.3.0-all-bin
# 启动 IoTDB 服务
./sbin/start-server.sh
# 启动客户端连接服务
./sbin/start-cli.sh -h 127.0.0.1 -p 66672. 创建数据库与时序数据
启动成功后,你会看到 IoTDB 的命令行提示符 IoTDB>. 接下来,我们来创建一些时序数据。
假设我们要监控一个发电厂的设备,我们有"发电机组1"和"发电机组2",每台机组有"温度"和"压力"两个传感器。
sql
-- 创建一个名为 root.ln 的数据库(ln代表电力行业示例)
CREATE DATABASE root.ln;
-- 使用数据库
USE root.ln;
-- 创建时间序列:root.ln.wf01.wt01.temperature 和 root.ln.wf01.wt01.pressure
CREATE TIMESERIES root.ln.wf01.wt01.temperature WITH DATATYPE=FLOAT, ENCODING=RLE;
CREATE TIMESERIES root.ln.wf01.wt01.pressure WITH DATATYPE=FLOAT, ENCODING=RLE;
-- 插入数据(时间戳采用毫秒级时间戳)
INSERT INTO root.ln.wf01.wt01(timestamp, temperature, pressure) VALUES (1700000000000, 25.5, 101.3);
INSERT INTO root.ln.wf01.wt01(timestamp, temperature, pressure) VALUES (1700001000000, 26.2, 101.5);
INSERT INTO root.ln.wf01.wt01(timestamp, temperature, pressure) VALUES (1700002000000, 25.8, 101.4);3. 高效查询与聚合分析
IoTDB 支持丰富的时间序列查询和聚合函数。
sql
-- 查询某个时间范围内的温度数据
SELECT temperature FROM root.ln.wf01.wt01 WHERE time > 1700000000000 AND time < 1700002000001;
-- 查询一段时间内的平均温度和最大压力
SELECT AVG(temperature), MAX(pressure) FROM root.ln.wf01.wt01 WHERE time > 1700000000000;4. 与 Spark 集成进行大数据分析
IoTDB 可以轻松与 Spark 结合,进行更大规模的历史数据分析。首先,你需要添加 IoTDB 的 Spark 连接器依赖。然后,可以使用 Scala 或 Python 编写代码:
scala
// 伪代码示例:使用 Spark SQL 读取 IoTDB 数据
val df = spark.read
.format("org.apache.iotdb.spark.db")
.option("url", "jdbc:iotdb://localhost:6667/")
.option("sql", "SELECT * FROM root.ln.wf01.**")
.load()
df.show()五、 选型建议与总结
回到我们最初的话题------时序数据库选型。结合前面的分析,我们可以得出以下结论:
- 如果你追求极致的高基数性能和原生 SQL 体验,InfluxDB 或 TimescaleDB 是不错的选择,但需考虑其成本和企业版授权问题。
- 如果你身处工业制造、能源电力、车联网等领域 ,且面临复杂的设备层级管理和边缘侧部署需求,Apache IoTDB 无疑是当下的最优解。它不仅开源、自主可控,而且在工业互联网场景的适配性上远超国外同类产品。
- 对于企业级应用,如果对数据安全、国产化合规有硬性要求,建议优先考虑 IoTDB,并可以关注其企业版(Timecho)提供的增强功能,如更高级的安全审计、异地容灾备份和专业技术支持服务。
在大数据时代,数据就是资产。选择一款合适的时序数据库,不仅能让你的数据飞得更快、存得更省,更能为企业未来的智能化升级打下坚实的基础。Apache IoTDB 作为国产开源的杰出代表,正在用技术的力量,助力中国企业在数字化转型的道路上走得更稳、更远。