1. 原理介绍
什么是向量:一个有大小有方向的量。
向量化也叫 Embedding,是将文本、图片等非结构化数据,转换成固定维度浮点数字数组的过程。自然语言无法被计算机直接运算比对,转为向量数值后,就能通过数学算法计算文本间相似度。
核心原理:
- 把每一段文字,变成一组固定长度的数字比如 1024 个数字组成一个数组。
- 语义越接近的文字 → 数字排列越像
- 语义差别越大 → 数字差别越大
数组里每一个小数,对应文本某一类语义特征,维度越多,刻画特征越精细。以简化 4 维向量举例,预设维度对应含义:
- 第 1 位:场景建筑属性
- 第 2 位:环境破败程度
- 第 3 位:人物行动动作
- 第 4 位:氛围情绪感受
示例文本对应向量赋值:
- 主角走进了一间破旧的小屋
0.85, 0.92, 0.78, 0.61
- 主角进入了一间老旧的房子
0.83, 0.90, 0.80, 0.59
- 今日户外阳光明媚
0.10, 0.05, 0.22, 0.95
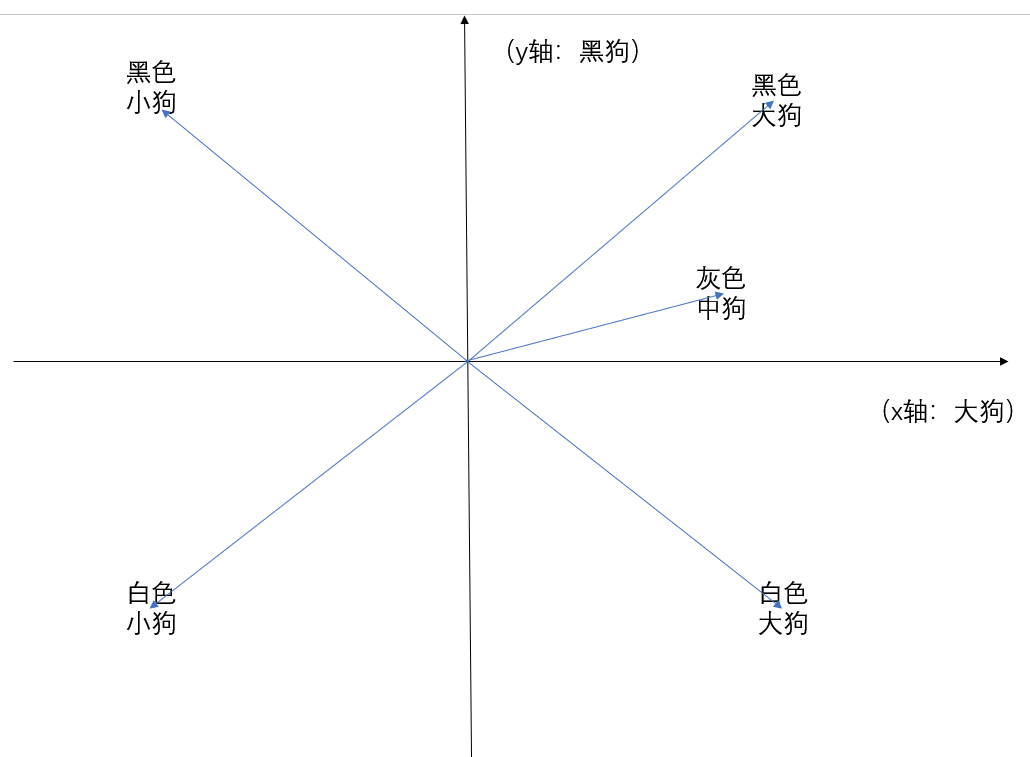
数值区间一般在 - 1, 1 之间,数值越趋近,代表对应特征高度吻合;数值偏差越大,特征差异越大。真实业务中是 1024 维向量,全方位覆盖人物、剧情、场景、情绪等海量特征。
行业通用余弦相似度计算,把向量看作空间坐标点,通过两点夹角判定相似程度。几何逻辑每一组向量,等同于多维空间里的一个点位。语义相近的文本,对应空间点位距离近、夹角小;语义无关文本,点位距离远、夹角大。
2. 向量数据库使用
这里我们使用redis stack
导入依赖:
XML
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>配置
XML
spring:
application:
name: SAA-08ChatMemory
ai:
dashscope:
base-url: https://dashscope.aliyuncs.com/
api-key: ${AliQWenAPIKey}
chat:
options:
model: qwen-plus
#用于向量化的大模型
embedding:
options:
model: text-embedding-v3
#Redis stack
vectorstore:
redis:
#启用初始化
initialize-schema: true
#索引名
index-name: custom-index
#数据前缀
prefix: custom-prefix
#reids
data:
redis:
host: 127.0.0.1
port: 6379
database: 0不同类型的大模型擅长领域不同,索引这里我们单独配置了一个用于文本向量处理的大模型
2.1 文本向量化
要存入向量数据库首先需要吧文本向量化:
java
@RestController
public class EmbedToVectorController {
@Autowired
private EmbeddingModel embeddingModel;
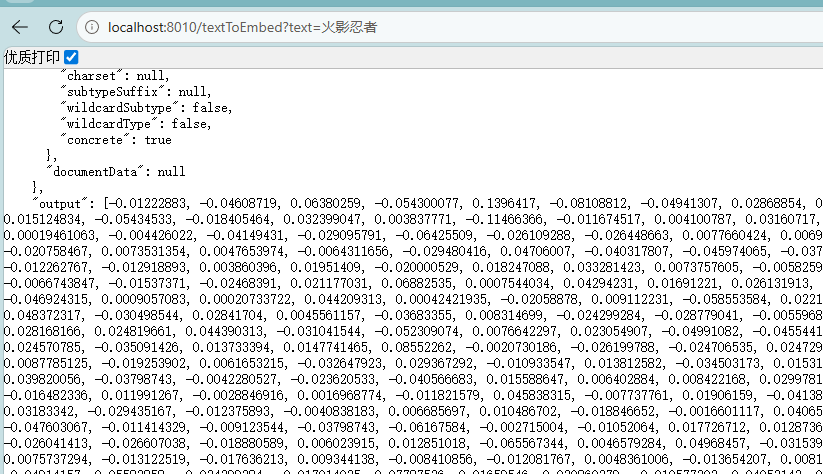
@GetMapping("/textToEmbed")
public EmbeddingResponse textToEmbed(String text) {
EmbeddingResponse embeddingResponse = embeddingModel
.call(
new EmbeddingRequest(
List.of(text),
DashScopeEmbeddingOptions
.builder()
.build()
)
);
System.out.println(Arrays.toString(embeddingResponse.getResult().getOutput()));
return embeddingResponse;
}
}这里直接注入embeddingModel,调用其call方法,传入一个EmbeddingRequest对象(包含需要向量化的文本,DashScopeEmbeddingOptions为额外可设置参数)
2.2 存储
java
@RestController
public class EmbedToVectorController {
@Autowired
private VectorStore vectorStore;
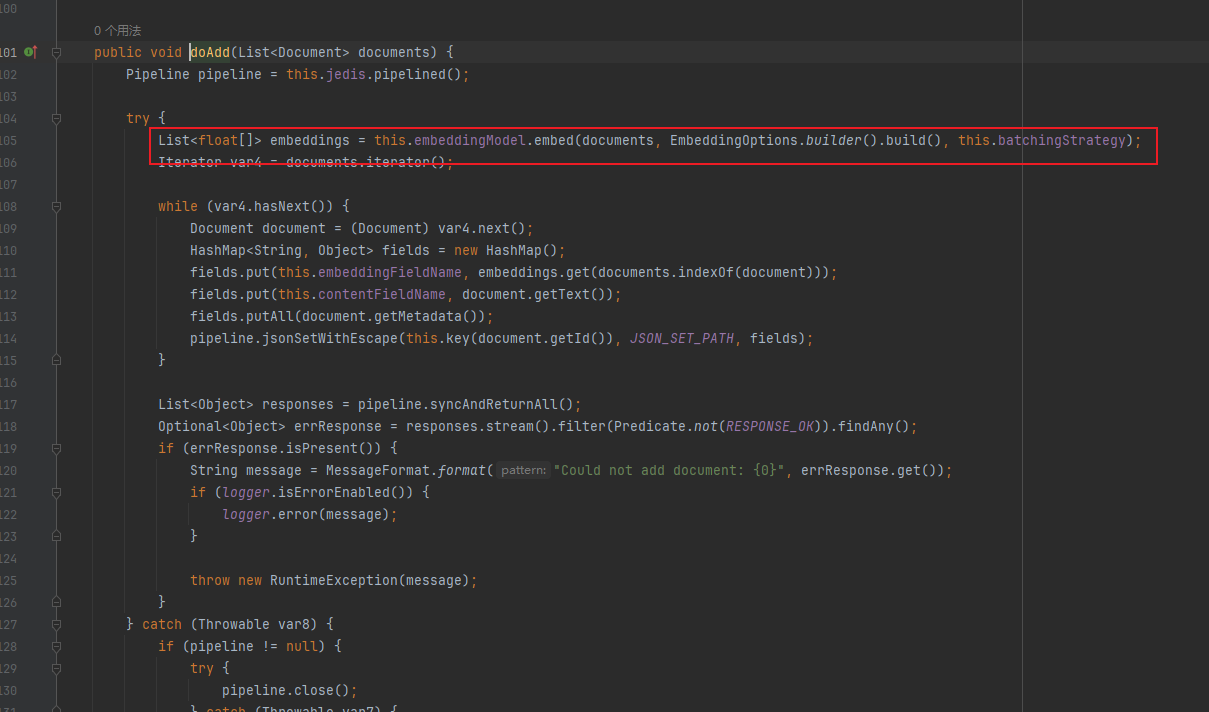
@GetMapping("/add")
public void add() {
List<Document> documents = List.of(
new Document("火影忍者"),
new Document("海贼王")
);
vectorStore.add(documents);
}
}这里VectorStore内部会自己先对数据向量化再存入:
调用之后可以看到redis中已经出现了key,类型是ReJSON
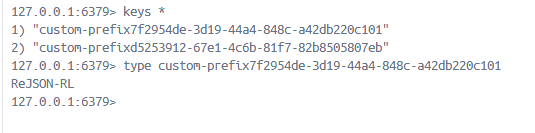
ReJSON常用命令:
- JSON.SET - 设置 JSON 值
- JSON.GET - 获取 JSON 值
- JSON.DEL - 删除 JSON 值
- JSON.MGET - 批量获取多个键的 JSON 值
- JSON.TYPE - 获取 JSON 值的类型
- JSON.NUMINCRBY - 对 JSON 中的数字进行增量操作
- JSON.STRAPPEND - 追加字符串到 JSON 字符串
- JSON.STRLEN - 获取 JSON 字符串的长度
2.3 查询
java
@RestController
public class EmbedToVectorController {
@Autowired
private VectorStore vectorStore;
@GetMapping("/get")
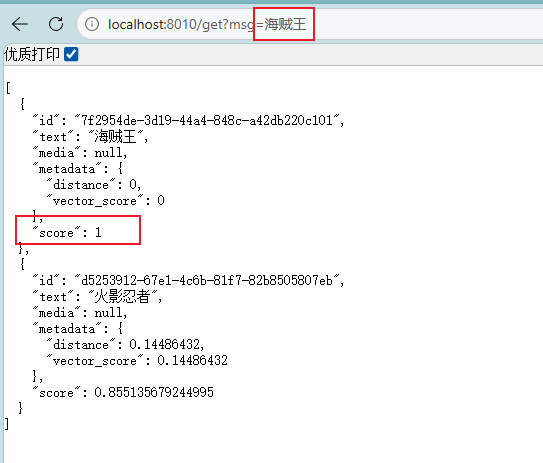
public List<Document> get(String msg) {
SearchRequest searchRequest = SearchRequest
.builder()
.query(msg)//查询词
.topK(2)//取前2个
.build();
List<Document> list = vectorStore.similaritySearch(searchRequest);
System.out.println(list);
return list;
}
}先使用SearchRequest创建一个查询对象,然后传入VectorStore的similaritySearch进行查询
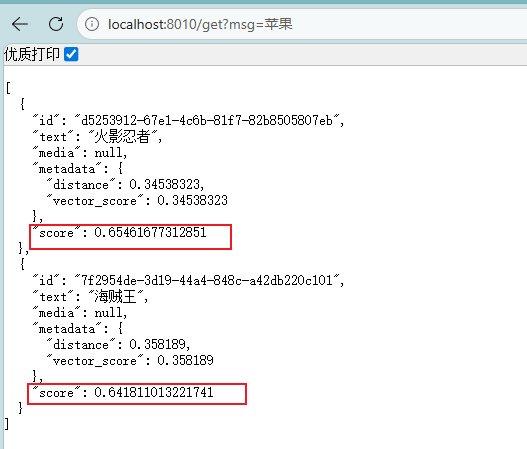
score代表相关性,数字越大,相关性越高: