第七章 指令微调学习(五)
7.7 Extracting and saving responses
在对指令数据集的训练部分完成LLM的微调后,现在评估其在保留测试集 上的性能。首先,我们提取测试集中每个输入对应的模型生成响应并进行人工分析 ;随后通过图7.18所示方法对LLM进行评估,以量化响应的质量。
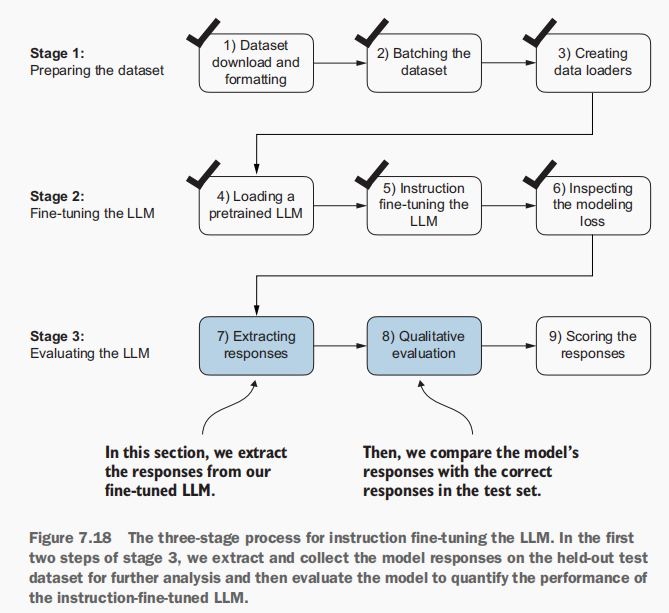
1.测试集指令响应
为完成响应指令步骤,我们使用 generate 函数。随后,我们将模型的响应结果与前三个测试集条目对应的预期测试集答案并排输出,以便进行对比:
python
torch.manual_seed(123)
for entry in test_data[:3]:
input_text = format_input(entry)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"],
eos_id=50256
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = (
generated_text[len(input_text):]
.replace("### Response:", "")
.strip()
)
print(input_text)
print(f"\nCorrect response:\n>> {entry['output']}")
print(f"\nModel response:\n>> {response_text.strip()}")
print(print("-------------------------------------"))如前所述,generate函数会返回输入文本与输出文本的组合结果;因此,我们通过对generated_text内容进行切片处理并使用 .replace() 方法来提取模型的响应。
结果:
bash
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence using a simile.
### Input:
The car is very fast.
Correct response:
>> The car is as fast as lightning.
Model response:
>> The car is as fast as a cheetah.
-------------------------------------
None
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What type of cloud is typically associated with thunderstorms?
Correct response:
>> The type of cloud typically associated with thunderstorms is cumulonimbus.
Model response:
>> The type of cloud associated with thunderstorms is a cumulus cloud.
>### Instruction:
Name the author of 'Pride and Prejudice'.
Correct response:
>> Jane Austen.
Model response:
>> The author of 'Pride and Prejudice' is Jane Austen.
-------------------------------------从结果可以看出,该模型表现相对良好 。首条和末条指令的答案明显正确,而第二条答案虽接近正确但并不完全准确------模型选择了"积云"而非"积雨云"。不过需要指出的是,积云确实可能发展为积雨云,而积雨云具备引发雷暴的能力。
1.最重要的是,模型评估并不像完成度微调那样简单直接:在完成度微调中,我们只需计算正确分类(垃圾邮件/非垃圾邮件)标签的比例即可得出分类准确率。
2.模型评估
在实际应用中,经过指令微调的大语言模型(LLM),会通过多种方法进行评估 :
(1)简答题 与多项选择题 基准测试(例如衡量大规模多任务语言理解能力的 MMLU ;https://arxiv.org/abs/2009.03300),用于评估模型的通用知识水平;
(2)人类对其他大语言模型(LLM)的偏好比较 ,如 LMSYS 聊天机器人竞赛平台(https://arena.lmsys.org);
(3)自动化对话基准测试 ,其中使用GPT-4等大语言模型来评估对话响应质量,例如AlpacaEval(https://tatsu-lab.github.io/alpaca_eval/)。
在实际应用中,综合考虑三种评估方法会更为有效:多项选择题作答 、人工评估 以及衡量对话表现的自动化指标 。然而,由于我们的主要关注点在于评估对话表现本身,而非单纯考察回答多项选择题的能力,因此人工评估和自动化指标可能更具参考价值。但人工评估耗时所以使用自动化评估。
3.自动化评估
让我们采用一种受AlpacaEval启发的方法,使用另一个大语言模型来评估我们微调后的模型响应。不过,与依赖公开基准数据集不同,我们采用了自定义测试集 。这种定制化设计使得我们能够更精准、相关地评估模型在目标应用场景(即我们的指令数据集中所体现的场景)下的性能表现。为准备本次评估所需的响应数据,我们将生成的模型响应追加到test_set字典中,并将更新后的数据保存为"instruction-data-with-response.json"文件以供记录。此外,通过保存该文件,可以加载并分析这些响应。
以下代码清单沿用之前的generate方法;但此次我们遍历了整个test_set集合。同时,我们不再直接打印模型响应,而是将其添加到test_set字典中。最后输出字典中的一个条目查看是否正确添加。
python
from tqdm import tqdm
for i, entry in tqdm(enumerate(test_data), total=len(test_data)):
input_text = format_input(entry)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"],
eos_id=50256
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = (
generated_text[len(input_text):]
.replace("### Response:", "")
.strip()
)
test_data[i]["model_response"] = response_text
with open("instruction-data-with-response.json", "w") as file:
json.dump(test_data, file, indent=4)
print(test_data[0])结果:

最后,保存模型:
python
import re
file_name = f"{re.sub(r'[ ()]', '', CHOOSE_MODEL) }-sft.pth"
torch.save(model.state_dict(), file_name)
print(f"Model saved as {file_name}")输出: 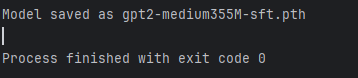
总结:
完整代码如下:
python
#Insturction_fine-tuning_pretrained_LLM_5_20
import json
import torch
from pre_training import calc_loss_loader
from Download_instruction_dataset5_9 import train_loader, val_loader
from Training_an_LLM_3_16 import train_model_simple
from load_pretrained_model5_20 import val_data, test_data, CHOOSE_MODEL
from load_pretrained_model5_20 import model, generate, text_to_token_ids, token_ids_to_text, BASE_CONFIG
import tiktoken
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
torch.manual_seed(123)
with torch.no_grad():
train_loss = calc_loss_loader(
train_loader, model, device, num_batches=5
)
val_loss = calc_loss_loader(val_loader, model, device,num_batches=5)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = (
f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
)
return instruction_text + input_text
import time
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(
model.parameters(), lr=0.00005, weight_decay=0.1
)
num_epochs = 2
tokenizer = tiktoken.get_encoding("gpt2")
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context=format_input(val_data[0]), tokenizer=tokenizer
)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.")
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
def plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):
fig, ax1 = plt.subplots(figsize=(5, 3))
ax1.plot(epochs_seen, train_losses, label="Training loss")
ax1.plot(
epochs_seen, val_losses, linestyle="-.", label="Validation loss"
)
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.legend(loc="upper right")
ax1.xaxis.set_major_locator(MaxNLocator(integer=True))
ax2 = ax1.twiny()
ax2.plot(tokens_seen, train_losses, alpha=0)
ax2.set_xlabel("Tokens seen")
fig.tight_layout()
plt.show()
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
#5.22
torch.manual_seed(123)
for entry in test_data[:3]:
input_text = format_input(entry)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"],
eos_id=50256
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = (
generated_text[len(input_text):]
.replace("### Response:", "")
.strip()
)
print(input_text)
print(f"\nCorrect response:\n>> {entry['output']}")
print(f"\nModel response:\n>> {response_text.strip()}")
print(print("-------------------------------------"))
from tqdm import tqdm
for i, entry in tqdm(enumerate(test_data), total=len(test_data)):
input_text = format_input(entry)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"],
eos_id=50256
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = (
generated_text[len(input_text):]
.replace("### Response:", "")
.strip()
)
test_data[i]["model_response"] = response_text
with open("instruction-data-with-response.json", "w") as file:
json.dump(test_data, file, indent=4)
print(test_data[0])
import re
file_name = f"{re.sub(r'[ ()]', '', CHOOSE_MODEL) }-sft.pth"
torch.save(model.state_dict(), file_name)
print(f"Model saved as {file_name}")完成了(1)生成测试集的响应;(2)并进行人工分析;(3)自动化评估。