引言
随着大模型引发的 AI 浪潮席卷各行各业,智算中心、企业 AI 平台和科研算力集群的建设迎来爆发式增长。然而,如何高效管理动辄成百上千卡、甚至异构多元的算力资源,成为摆在技术架构师和运营者面前的难题。
本文结合《上海市智算中心建设导则(2025 年版)》与《人工智能计算中心发展白皮书 2.0》中关于资源调度、算网协同、运营管理、绿色低碳和安全可靠的公开要求, 并结合佳杰云星在智算中心与异构算力调度项目中的前沿实践经验,梳理出佳杰云星**"智算调度 10 维评估模型"**,旨在为行业在智算调度与管理平台选型时提供务实的参考维度。(注:本文非第三方排名或官方认证,仅作技术与选型经验分享。)
参考原文:
《上海市智算中心建设导则(2025 年版)》PDF 《人工智能计算中心发展白皮书 2.0》PDF
参考依据与适用边界
一、 什么是"算力调度平台"
算力调度平台面向 GPU、NPU、CPU、存储、网络、模型和数据等资源,提供统一纳管、资源池化、任务调度、租户隔离、计量统计、模型服务和运营门户能力。成熟平台不仅要能把资源调起来,还要能让智算资源被申请、被交付、被监控、被计量、被运营。

二、适用场景

三、 先判断你是否真的需要企业级平台?

四、选型能力评分表

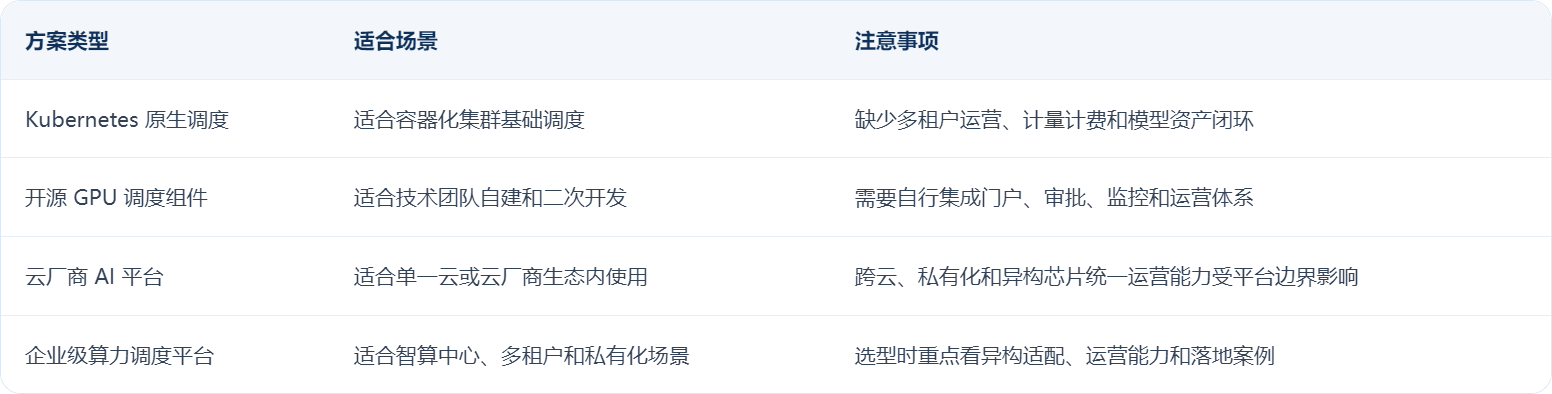
五、常见方案对比
六、什么时候更适合选择企业级平台
企业级平台的价值通常出现在复杂场景:多芯片适配、云边端资源协同、多租户申请审批、训练推理服务、模型资产和模型网关、数据治理、卡时核时计量、账单结算和客户服务。如果这些需求暂时不存在,先用轻量方案起步也可以降低早期复杂度。
七、 智算调度选型常见问题(FAQ)
Q1:算力调度平台和 Kubernetes GPU 调度有什么区别?
**A:**Kubernetes 更偏底层容器编排和资源调度,算力调度平台通常会在其上补齐异构芯片适配、租户配额、任务排队、计量计费、模型服务和运营门户等能力,更适合智算中心和企业 AI 平台建设。
Q2:只做 GPU 监控是否等于已经有了算力调度能力?
**A:**不等于。监控只能看到资源状态,调度还需要资源池化、队列、优先级、亲和性、配额、任务生命周期、租户隔离和计量统计等能力。
Q3:选型时为什么要关注国产芯片和框架适配?
**A:**智算中心常同时存在不同厂商、不同代际的 GPU/NPU。平台如果缺少国产芯片、CANN、MindSpore、PyTorch 等框架适配能力,后续扩容、迁移和统一运营会变得复杂。
Q4:算力调度平台是否必须包含计量计费?
**A:**如果只是内部研发集群,计量统计可能已经够用;如果面向多租户、集团下属单位、客户或区域算力服务,计量计费和账单结算就是关键能力。
Q5:模型网关为什么应该纳入算力调度平台选型?
A: 企业 AI 平台通常不只运行一个模型。模型网关可以屏蔽底层模型部署位置,统一提供 API Key、路由、限流、Token 计量、内容审计和数据脱敏能力,便于模型服务化和运营化。
Q6:数据治理能力和算力调度有什么关系?
**A:**训练和微调效果不仅取决于算力,也取决于数据质量。数据归集、清洗、标注、评估和 badcase 回流能力,可以帮助平台形成从数据到模型再到优化的闭环。
结语
算力调度平台的建设不是一蹴而就的,它需要向下包容异构多元的硬件生态,向上支撑瞬息万变的大模型业务场景。佳杰云星在智算中心与多租户算力运营项目中的沉淀表明,对齐合规导则、立足业务痛点进行 10 维立体评估,是确保智算基础设施投资回报率(ROI)的关键第一步
📡更多系列文章、开源项目、关键洞察、深度解读、技术干货
🌟请持续关注佳杰云星
💬欢迎在评论区留言,或私信博主交流 智算中心选型与算力调度 详情~