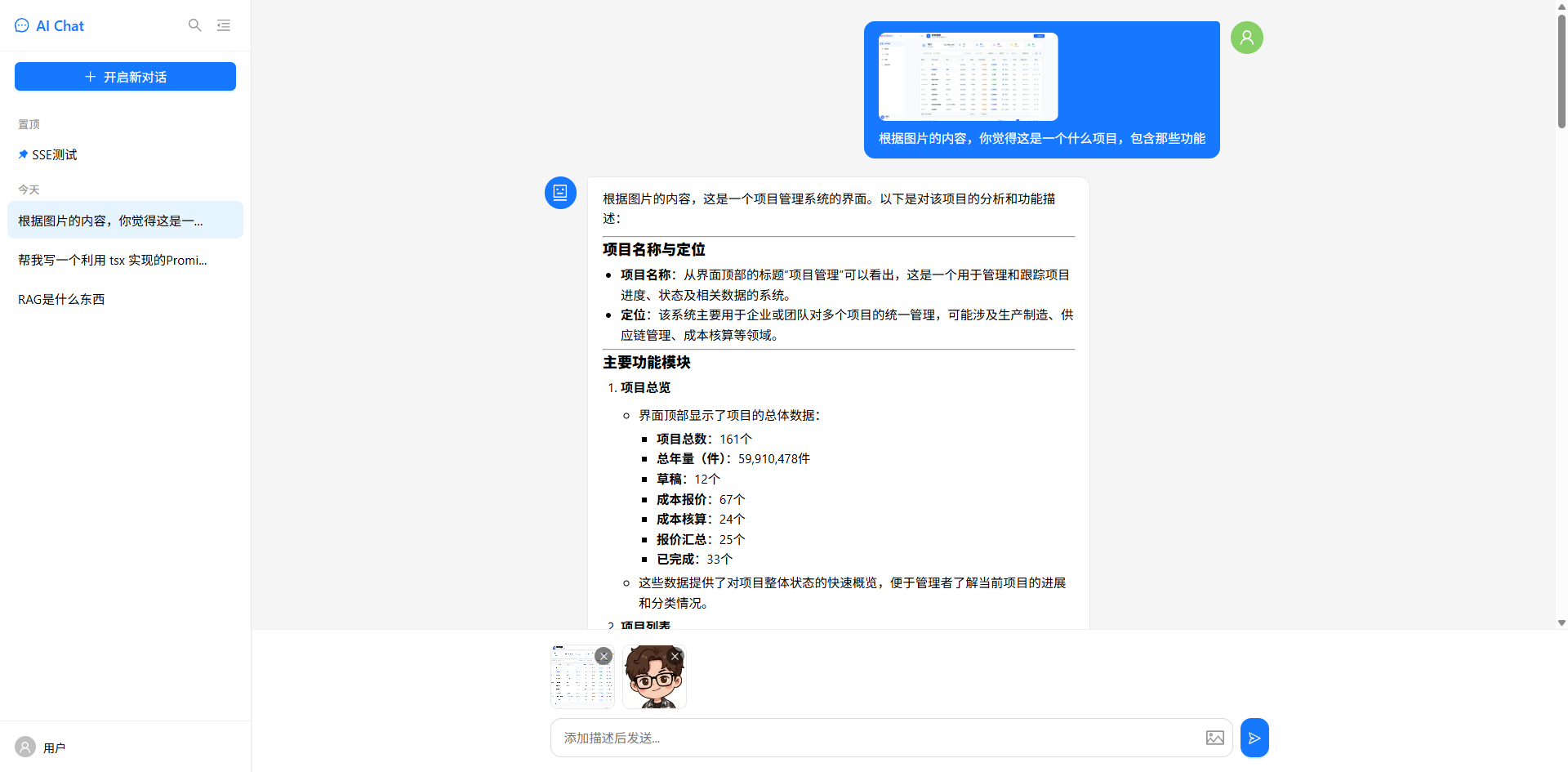
一、图片上传功能扩展
在流式对话的基础上,我们新增了图片上传与识别功能。用户可以在输入框中上传图片,配合文字描述一起发送,AI 会基于图片内容进行分析回答。
1.1 功能效果
- 输入框内部右侧显示上传图标,点击选择图片(支持多选)
- 上传后在输入框上方显示缩略图预览,支持逐张删除
- 发送后图片显示在用户消息气泡中,AI 流式输出图片分析结果
- 切换对话后,历史图片消息也能正常还原显示
1.2 整体数据流
用户点击上传图标
↓
FileReader.readAsDataURL() → base64 编码
↓
存入 pendingImages 状态(预览区显示缩略图)
↓
用户点击发送
↓
pendingImages + inputValue → 构造带 images 字段的消息
↓
chatService.streamChat(text, sessionId, useRag, callbacks, images)
↓ HTTP POST body: { message, images: ["data:image/...;base64,..."] }
↓
后端收到 images → 切换 qwen-vl-plus 视觉模型 → 构造多模态 HumanMessage
↓
SSE 流式返回 AI 对图片的分析结果1.3 输入框组件实现(ChatInput.jsx)
这是图片上传功能的核心,所有上传、预览、发送逻辑都在这个组件中。
状态定义
在原有基础上新增 pendingImages 状态,存储待发送的图片列表:
javascript
export default function ChatInput() {
const [inputValue, setInputValue] = useState('');
const [pendingImages, setPendingImages] = useState([]); // [{id, base64, name}]
const textareaRef = useRef(null);
const fileInputRef = useRef(null); // 隐藏的文件选择框引用
const abortRef = useRef(null);pendingImages是一个数组,每项包含id(唯一标识,用于删除)、base64(data URL 格式)、name(文件名)fileInputRef指向隐藏的<input type="file">,点击图标时触发它的 click
图片上传处理
javascript
const handleImageUpload = (e) => {
const files = Array.from(e.target.files || []);
files.forEach((file) => {
// 校验文件类型
if (!file.type.startsWith('image/')) {
message.warning(`${file.name} 不是图片文件`);
return;
}
// 校验文件大小(限制 10MB)
if (file.size > 10 * 1024 * 1024) {
message.warning(`${file.name} 超过 10MB 限制`);
return;
}
// 使用 FileReader 读取为 base64 Data URL
const reader = new FileReader();
reader.onload = (ev) => {
setPendingImages((prev) => [
...prev,
{
id: Date.now() + Math.random(), // 唯一 ID
base64: ev.target.result, // data:image/png;base64,...
name: file.name,
},
]);
};
reader.readAsDataURL(file);
});
// 重置 input,支持重复选择同一文件
if (fileInputRef.current) fileInputRef.current.value = '';
};关键点:
FileReader.readAsDataURL()将图片文件转为data:image/xxx;base64,...格式的字符串- 这个 base64 字符串可以直接作为
<img src>显示预览,也可以直接发给支持视觉的 LLM - 重置
input.value是因为浏览器在选了同一文件后不会触发onChange,清空后才能重复选择
删除已上传图片
javascript
const removeImage = (id) => {
setPendingImages((prev) => prev.filter((img) => img.id !== id));
};发送逻辑(改动部分)
发送时把 pendingImages 中的 base64 一并传给后端:
javascript
const handleSend = useCallback(() => {
const text = inputValue.trim();
const images = pendingImages.map((img) => img.base64);
if ((!text && images.length === 0) || isStreaming) return;
const displayText = text || '请描述这些图片的内容';
// 清空输入和预览
setInputValue('');
setPendingImages([]);
// 添加用户消息(带 images 字段)
addMessage({
id: Date.now(),
role: 'user',
content: displayText,
images: images.length > 0 ? images : undefined,
createdAt: new Date().toISOString(),
});
startStreaming();
// 调用流式接口,传入 images 数组
abortRef.current = chatService.streamChat(
displayText,
convId,
useRag,
{
onToken: (token) => appendStreamContent(token),
onDone: (sessionId) => { /* ... */ },
onError: (err) => { /* ... */ },
},
images, // 新增:图片 base64 数组
);
}, [inputValue, pendingImages, /* ... */]);JSX 结构
javascript
return (
<div className={styles.inputArea}>
{/* 图片预览区 ------ 输入框上方 */}
{pendingImages.length > 0 && (
<div className={styles.imagePreviewBar}>
{pendingImages.map((img) => (
<div key={img.id} className={styles.imagePreviewItem}>
<img src={img.base64} alt={img.name} />
<div className={styles.imageRemove} onClick={() => removeImage(img.id)}>
<CloseOutlined />
</div>
</div>
))}
</div>
)}
<div className={styles.inputWrapper}>
{/* 隐藏的文件选择 */}
<input ref={fileInputRef} type="file" accept="image/*" multiple
style={{ display: 'none' }} onChange={handleImageUpload} />
{/* 输入框容器(含内部图标) */}
<div className={styles.textareaWrap}>
<PictureOutlined
className={styles.innerUploadIcon}
onClick={() => !isStreaming && fileInputRef.current?.click()}
/>
<textarea
ref={textareaRef}
className={styles.textarea}
value={inputValue}
onChange={handleChange}
onKeyDown={handleKeyDown}
placeholder={pendingImages.length > 0
? "添加描述后发送..."
: "输入消息,Enter 发送,Shift+Enter 换行..."}
rows={1}
/>
</div>
{/* 发送/停止按钮 */}
{isStreaming
? <Button className={styles.sendBtn} danger icon={<StopOutlined />}
onClick={handleStop} />
: <Button className={styles.sendBtn} type="primary" icon={<SendOutlined />}
onClick={handleSend} disabled={!inputValue.trim() && pendingImages.length === 0} />
}
</div>
</div>
);1.4 上传图标定位(CSS 关键实现)
图标在输入框内部右侧,使用 position: absolute 叠加在 textarea 上:
css
.textareaWrap {
flex: 1;
position: relative; // 定位容器
display: flex;
align-items: flex-end;
}
.innerUploadIcon {
position: absolute;
right: 10px; // 固定在右侧
bottom: 12px; // 底部对齐
font-size: 20px;
color: #999;
cursor: pointer;
z-index: 1;
transition: color 0.2s;
&:hover {
color: #1677ff;
}
}
.textarea {
width: 100%;
padding: 10px 38px 10px 14px; // 右侧留 38px 给图标
// ...其他样式
}1.5 图片预览样式
css
.imagePreviewBar {
max-width: 800px;
margin: 0 auto 10px;
display: flex;
gap: 8px;
flex-wrap: wrap;
}
.imagePreviewItem {
position: relative;
width: 72px;
height: 72px;
border-radius: 8px;
overflow: hidden;
border: 1px solid #e8e8e8;
img {
width: 100%;
height: 100%;
object-fit: cover; // 裁剪填充
}
}
.imageRemove {
position: absolute;
top: 2px;
right: 2px;
width: 20px;
height: 20px;
background: rgba(0, 0, 0, 0.5);
border-radius: 50%;
display: flex;
align-items: center;
justify-content: center;
cursor: pointer;
color: #fff;
font-size: 10px;
&:hover {
background: rgba(0, 0, 0, 0.75);
}
}1.6 消息气泡中渲染图片(ChatMessages.jsx)
在用户消息气泡中,如果有 images 字段,在文字上方显示图片:
javascript
{msg.images && msg.images.length > 0 && (
<div className={styles.messageImages}>
{msg.images.map((src, idx) => (
<img key={idx} src={src} alt={`upload-${idx}`}
className={styles.messageImage} />
))}
</div>
)}
{msg.role === 'assistant'
? <ReactMarkdown>{msg.content}</ReactMarkdown>
: msg.content
}1.7 历史消息图片还原(Chat.jsx)
带图片的用户消息在后端以 JSON 格式存储({"text":"...", "images":["base64..."]}),加载历史时需要解析还原:
javascript
chatService.getMessages(currentConversationId)
.then((msgs) => {
setMessages(msgs.map((m) => {
let content = m.content;
let images = undefined;
// 检测是否为带图片的 JSON 消息
if (m.role === 'user' && m.content.startsWith('{')) {
try {
const parsed = JSON.parse(m.content);
if (parsed.text !== undefined && parsed.images) {
content = parsed.text;
images = parsed.images;
}
} catch { /* 非 JSON,按普通文本处理 */ }
}
return { id: m.id, role: m.role, content, images, createdAt: m.createdAt };
}));
})1.8 API 层改动(chatService.js)
streamChat 方法新增 images 参数,传给后端:
javascript
streamChat(message, sessionId, useRag, callbacks, images = []) {
// ...
fetch(`${BASE_URL}/api/chat/stream`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
message,
session_id: sessionId || null,
use_rag: useRag,
images, // base64 图片数组
}),
signal: controller.signal,
})
// ...
}1.9 后端(server.py)
python
def get_chat_model(vision=False):
"""创建聊天模型,vision=True 时使用支持图片的视觉模型"""
return ChatOpenAI(
model="qwen-vl-plus" if vision else "qwen-plus",
openai_api_key=os.getenv("DASHSCOPE_API_KEY"),
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
def _build_image_message(text, images):
"""构建多模态消息(文字 + 图片)"""
content = [{"type": "text", "text": text}]
for img in images:
content.append({
"type": "image_url",
"image_url": {"url": img},
})
return HumanMessage(content=content)
python
@app.route("/api/chat/stream", methods=["POST"])
def chat_stream():
"""SSE 流式聊天接口"""
data = request.json
user_message = data.get("message", "").strip()
session_id = data.get("session_id")
use_rag = data.get("use_rag", False)
images = data.get("images", []) # base64 图片列表
if not user_message and not images:
return jsonify({"error": "消息不能为空"}), 400
# 如果只有图片没有文字,给一个默认提示
if not user_message and images:
user_message = "请描述这些图片的内容"
def generate():
full_reply = ""
conv_id = None
try:
conv_id = get_or_create_conversation(session_id, use_rag=use_rag)
# 构建用于展示的 content(文字 + 图片 URL 标记)
display_content = user_message
if images:
display_content = json.dumps({"text": user_message, "images": images}, ensure_ascii=False)
save_message(conv_id, "user", display_content)
existing = get_messages(conv_id)
if len(existing) <= 1:
title = user_message[:20] + ("..." if len(user_message) > 20 else "")
update_title(conv_id, title)
if use_rag:
result = rag_query(user_message)
reply = result["reply"]
for char in reply:
full_reply += char
yield f"data: {json.dumps({'token': char}, ensure_ascii=False)}\n\n".encode("utf-8")
else:
# 构建消息历史
history = [SystemMessage(content=SYSTEM_PROMPT)]
for msg in existing:
if msg["role"] == "user":
# 尝试解析带图片的消息
try:
parsed = json.loads(msg["content"])
if isinstance(parsed, dict) and parsed.get("images"):
history.append(_build_image_message(parsed.get("text", ""), parsed["images"]))
else:
history.append(HumanMessage(content=msg["content"]))
except (json.JSONDecodeError, TypeError):
history.append(HumanMessage(content=msg["content"]))
elif msg["role"] == "assistant":
history.append(AIMessage(content=msg["content"]))
# 当前消息:如果有图片则用多模态格式
if images:
history.append(_build_image_message(user_message, images))
else:
history.append(HumanMessage(content=user_message))
llm = get_chat_model(vision=bool(images))
for chunk in llm.stream(history):
token = chunk.content
if token:
full_reply += token
yield f"data: {json.dumps({'token': token}, ensure_ascii=False)}\n\n".encode("utf-8")
if full_reply:
save_message(conv_id, "assistant", full_reply)
yield f"data: {json.dumps({'done': True, 'session_id': conv_id}, ensure_ascii=False)}\n\n".encode("utf-8")
except Exception as e:
import traceback
traceback.print_exc()
yield f"data: {json.dumps({'error': str(e)}, ensure_ascii=False)}\n\n".encode("utf-8")
resp = Response(
stream_with_context(generate()),
mimetype="text/event-stream",
)
resp.headers["Cache-Control"] = "no-cache"
resp.headers["X-Accel-Buffering"] = "no"
resp.headers["Connection"] = "keep-alive"
return resp2.0 小结
图片上传功能的前端核心实现可以归纳为以下几点:
| 环节 | 技术方案 |
|---|---|
| 图片读取 | FileReader.readAsDataURL() 转 base64 Data URL |
| 预览显示 | base64 直接作为 <img src> |
| 输入框内图标 | position: absolute 叠加在 textarea 右侧,padding-right 留空间 |
| 发送给后端 | base64 字符串数组放入 POST body 的 images 字段 |
| 消息中显示 | 消息对象带 images 字段,渲染时在文字上方展示图片 |
| 历史还原 | 后端 JSON 存储的文字 + 图片,加载时 JSON.parse 拆分还原 |
| 数据库适配 | content 列从 TEXT(64KB) 改为 MEDIUMTEXT(16MB),因为 base64 很大 |
注意⚠: 图片上传可通过上传到OSS实现存储、解析等操作,这样属于是规范的功能开发!!!
可见https://blog.csdn.net/qq_70172010/article/details/157650348?spm=1001.2014.3001.5501