企业运维团队今天并不缺工具。Prometheus、Grafana、Coroot、DeepFlow、Jaeger、日志平台、Kubernetes 控制台、CI/CD 和工单系统都在工作。真正困难的是:这些工具产生了大量事实,但事实没有自动汇聚成判断;团队积累了大量经验,但经验没有沉淀成可复用资产;自动化脚本越来越多,但脚本是否适用于当前现场、是否还能安全执行,往往缺少验证机制。
所以 AIOPS 要解决的不是"让 AI 回答一次运维问题",而是构建一套自治运维平台:把监控事实、Agent 推理、运维经验、执行编排、安全治理和回归验证连接起来,让系统在日常巡检、告警响应、知识沉淀和策略自愈中持续变得更可靠。
从技术视角看,AIOPS 的核心不是单个 Agent,而是五层能力的协同:
text
交互层:AI Chat / 群聊 / API / cron / 事件触发
证据层:Prometheus / Coroot / Logs / Traces / K8s / CI-CD / CMDB
Agent 层:自主规划、专业 Agent、RCA、工具调用、参数解析
知识资产层:记忆系统、OpsGraph、运维手册、Runner Workflow、Run Record
验证治理层:容器矩阵、Eval、Prompt Trace、Policy、Approval、ActionToken这篇文章会围绕这套架构展开:用户打开页面能看到什么,系统如何保存和复用运维经验,记忆系统、运维手册和 Workflow 的边界是什么,容器矩阵如何保证每次优化有效,最后再用几个典型场景说明它如何落地。
智能运维展示
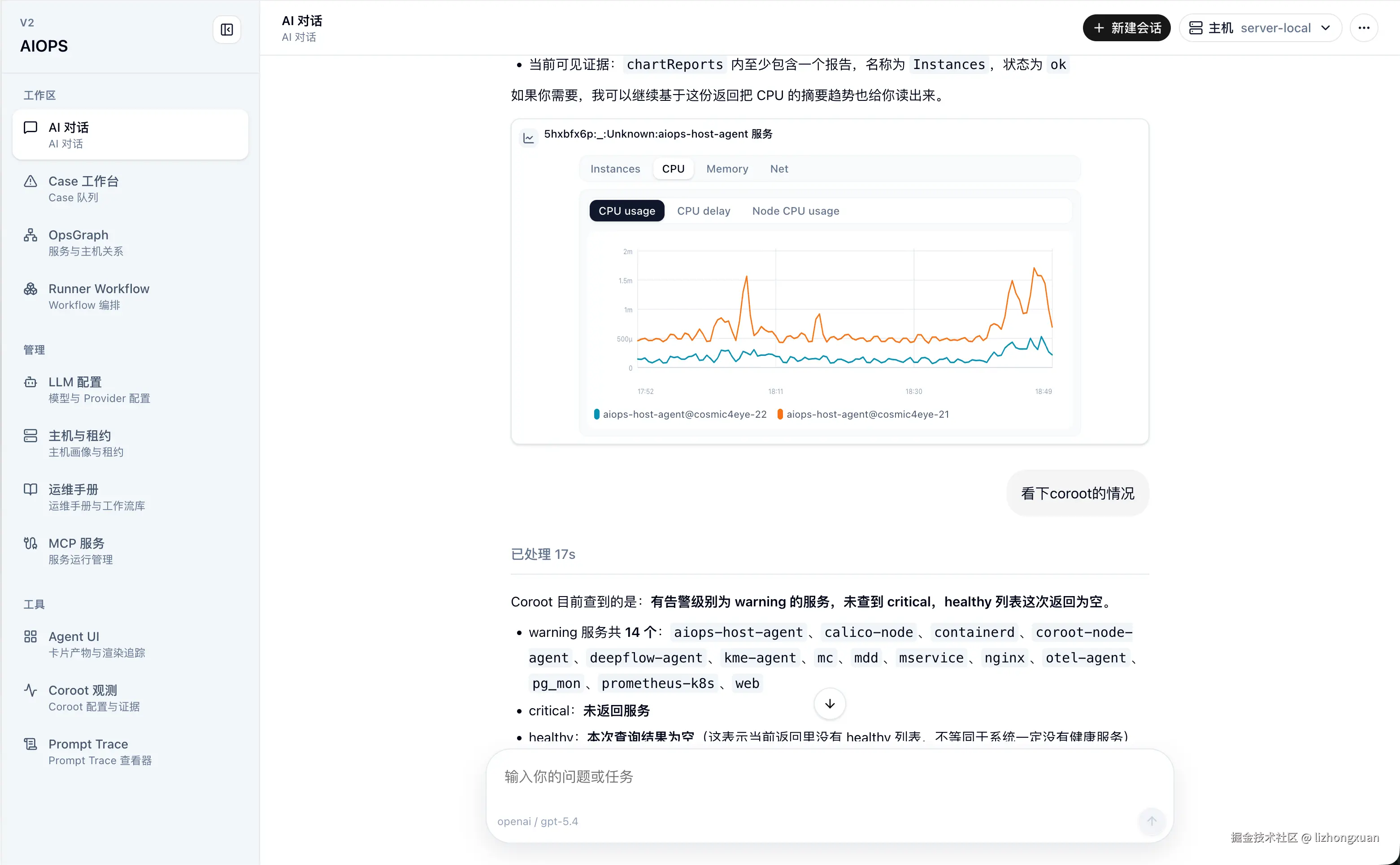
1. RCA 证据链
AI Chat 是排查入口,但不是普通问答。用户用自然语言描述问题后,Agent 会解析目标对象、环境、时间窗口和风险边界,再调用 Coroot、Prometheus、Logs、Traces、Kubernetes Events 等工具采集 Evidence。Coroot 的 Agent-to-UI 图表用于展示服务拓扑、异常依赖边和资源异常,LLM 负责把这些结构化证据组织成 RCA 假设、支持证据、反证和下一步建议。
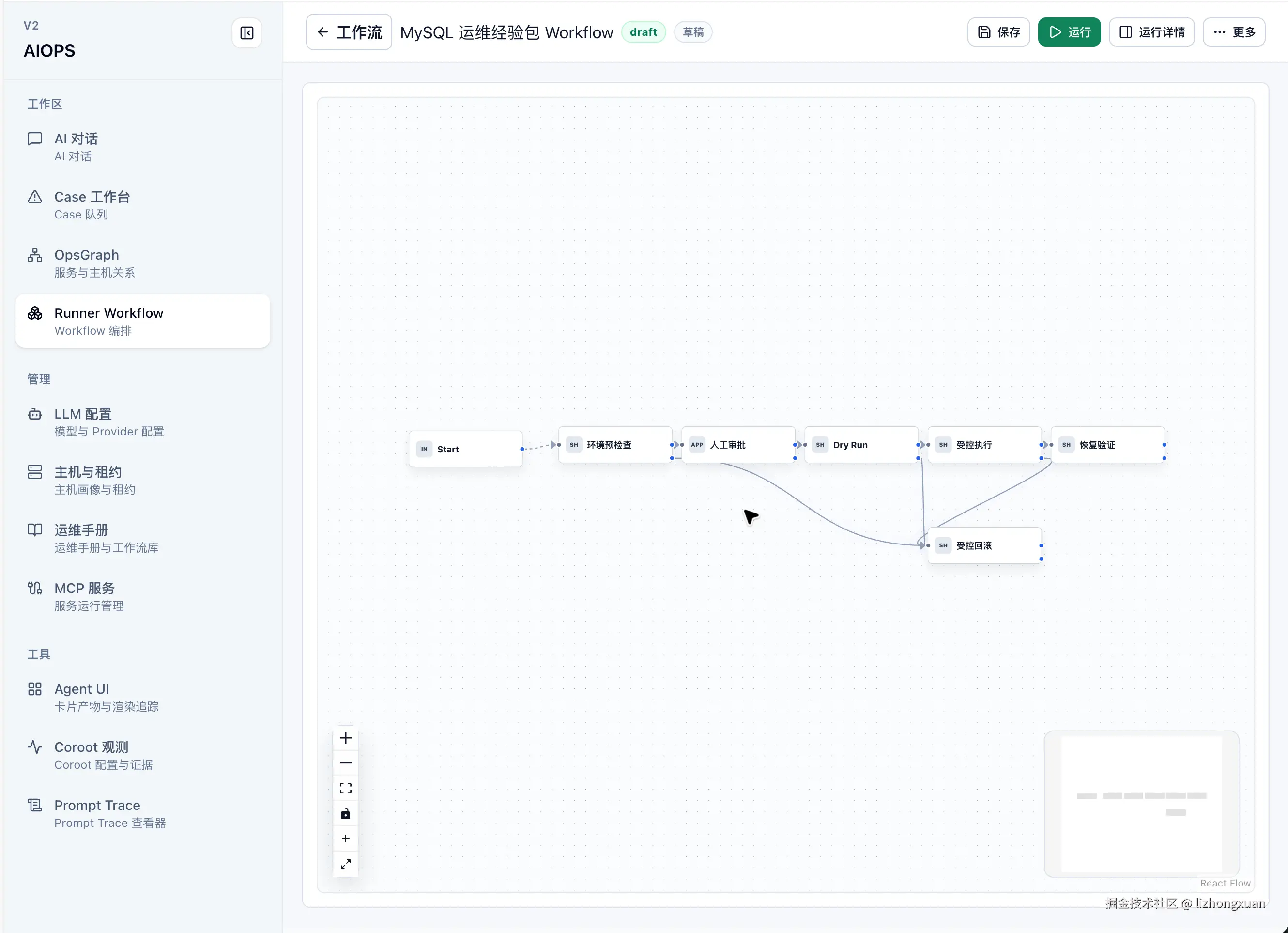
2. 从标准操作到可验证 Workflow
当一个排查或恢复动作稳定后,它不应该继续停留在口头经验或散落脚本里。Runner 会把标准操作编排成可运行、可调试、可审计的 Workflow,并将节点拆成 preflight、execute、verify、rollback 等阶段。每个节点都返回统一参数,例如 status、evidence_ref、risk_level、changed、next_action 和 artifacts,这样后续节点、RCA 报告、审批系统和 Run Record 都能消费同一套结构化结果。
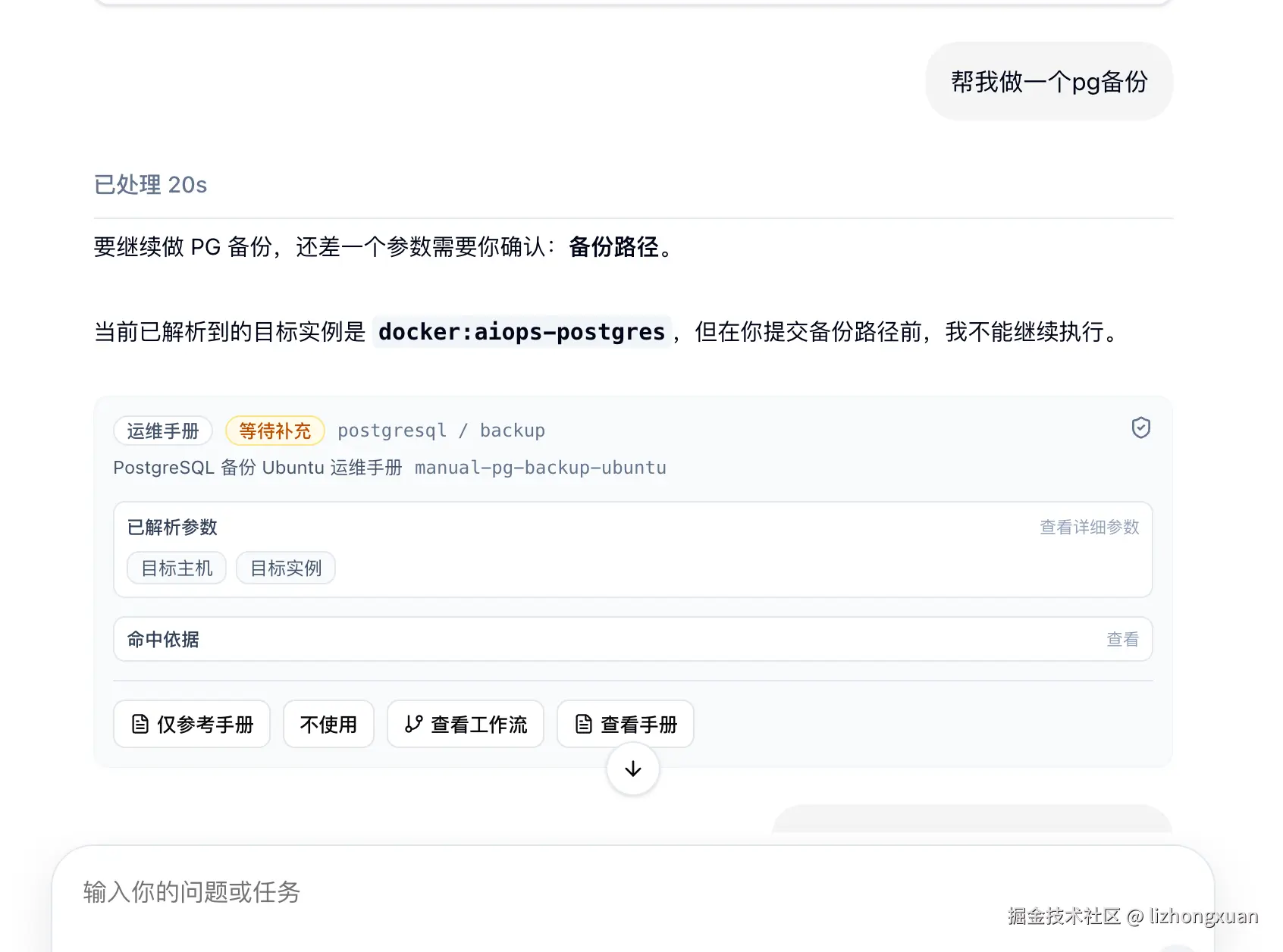
3. 运维手册:复杂任务的知识召回
当用户发起复杂运维任务时,系统会先检索运维手册和记忆系统,判断是否存在经过验证的经验资产。命中手册后,页面会根据当前上下文自动填充确定参数;对不确定参数,用下拉框、输入框或审批项交给用户确认。这样用户面对的不是一篇静态文档,而是一个能结合现场信息、历史经验和执行边界的交互式操作入口。
平台主线:从数据接入到知识资产
AIOPS 的第一步不是让模型直接下结论,也不是替换现有监控平台,而是通过接口组合把分散事实整理成可追溯证据。用户的自然语言、告警事件、cron 巡检结果、CI/CD 变更、Kubernetes 事件和监控指标,都会先进入统一的 Case / Evidence 语义。
一个典型链路如下:
text
用户问题 / 告警 / 巡检事件
-> 创建或关联 Case
-> 解析目标对象、环境、时间窗口和风险边界
-> 调用观测工具采集 Metrics / Logs / Traces / Topology / Events
-> 生成 RCA 候选、支持证据、反证和缺失证据
-> 判断是否命中运维手册或需要生成候选资产
-> 进入预检、审批、执行、验证或人工协同
-> 写入 Run Record,并反哺记忆、手册、Workflow 和 Eval这里有一个重要设计:AIOPS 不把"模型回答"当成最终事实。模型可以规划和解释,但关键证据、执行状态、审批状态和验证结果必须进入结构化对象。这样系统才能复盘、回放、评测,也才能长期进化。
这些结构化对象还会持续写入 OpsGraph。服务、Pod、中间件、告警、变更、手册、Workflow 和 Run Record 都可以成为图上的节点或关系。OpsGraph 的价值不是"多一张图",而是让 Agent 能回答更复杂的问题:这个告警可能影响哪些上游业务?这个手册适用于哪些服务?某个 Workflow 过去在哪些环境里成功过、又在哪些条件下失败过?
运维经验如何沉淀:四类资产各司其职
很多系统会把"知识库""记忆""脚本""自动化流程"混在一起,最后导致两个问题:历史经验被误当成当前事实,文档步骤被误当成可执行流程。AIOPS 把这些对象拆开。
1. Run Record:真实运行反馈
Run Record 记录一次运维任务的完整过程。它不是普通日志,而是结构化事实:
- 用户意图和触发来源。
- 目标服务、主机、Pod、中间件实例或业务能力。
- 证据来源和时间窗口。
- Agent 调用过的工具和参数。
- RCA 假设、支持证据、反证和缺失证据。
- 是否命中手册,是否生成 Workflow,是否需要审批。
- preflight、execute、verify、rollback 的节点状态。
- 人工审批、拒绝或升级记录。
- 验证结果和失败原因。
- Prompt Trace 引用。
Run Record 是后续学习的事实来源。它回答的是:这个流程真实跑过吗?在哪个环境跑过?成功还是失败?失败是因为权限、参数、环境漂移,还是手册本身不适用?
2. 记忆系统:帮助 Agent 更快想到方向
记忆系统保存轻量经验,例如:
- 某个服务历史上多次因为 JVM 参数触发 OOM。
- 某个团队偏好先只读排查,再进入修复。
- 某个 Redis 实例常见慢查询来自某类 key。
- 某个数据库切换策略在备库延迟过高时失败过。
记忆可以提高排查效率,但不能直接授权执行。它只是候选线索和排序信号。当前观测证据永远优先于历史记忆。
3. 运维手册:经过审核的标准化知识
运维手册保存的是可复用判断和处置知识。它必须包含结构化字段,而不是只有 Markdown:
- 适用对象和操作类型。
- 适用环境和执行面。
- 必需参数和必需证据。
- 预检探针。
- 风险策略。
- 不能使用条件。
- 验证方法。
- 绑定 Workflow 的版本和 digest。
生成运维手册 Tool 可以从 RCA、Run Record、现有 Workflow 和相似手册中生成候选手册。但候选手册不能直接成为生产资产,必须经过校验、审核和必要的矩阵验证。
4. Runner Workflow:真正的执行载体
Workflow 不是文档,它是可执行图。生产级 Workflow 至少要分成四段:
text
preflight:只读检查目标、权限、环境和风险
execute:执行受控变更或恢复动作
verify:独立验证业务和系统是否恢复
rollback:失败时回滚或进入人工降级路径生成工作流 Tool 可以把稳定流程转成候选 Workflow。系统会检查参数是否 schema 化,是否写死生产目标,preflight 是否只读,execute 是否声明风险,verify 是否独立,rollback 是否存在。
如果根因是配置漂移或代码缺陷,Workflow 的输出也不一定是直接修改生产。更安全的方式是生成配置补丁或代码补丁,自动创建 Pull Request,并把 PR、diff、验证结果和审批记录写回 Run Record。这样 AIOPS 具备"写"的能力,但写操作仍然在代码评审、CI 和审批链路之内完成。
简单说:记忆负责提示方向,手册负责沉淀知识,Workflow 负责执行动作,Run Record 负责反馈真实效果。
这四类资产的关系可以理解成一条闭环,而不是四个孤立模块:
text
一次任务执行
-> Run Record 记录真实过程和验证结果
-> Memory 提炼轻量经验,提升下次检索和排序
-> Ops Manual Candidate 固化可复用判断、适用条件和风险边界
-> Workflow Candidate 承载可执行步骤和统一节点返回
-> Container Matrix 复现现场并验证候选资产
-> Verified Manual / Verified Workflow 进入后续检索和执行| 阶段 | 写入对象 | 作用 | 是否可直接执行 |
|---|---|---|---|
| 采证和 RCA | Run Record / Evidence | 保存事实、证据和判断过程 | 否 |
| 经验提示 | Memory Hint | 提升相似事件召回和 Agent 排查优先级 | 否 |
| 标准化沉淀 | Ops Manual Candidate | 形成适用条件、操作步骤、禁用条件和验证方法 | 否,需审核和验证 |
| 执行编排 | Workflow Candidate | 把步骤转成 preflight / execute / verify / rollback | 否,需策略检查和矩阵验证 |
| 复用资产 | Verified Manual / Verified Workflow | 进入页面检索、Runner 执行和策略自愈 | 按权限和风险等级执行 |
可验证进化:不是模型自己改自己
AIOPS 的自进化不是让模型自己改 prompt、自己发布手册、自己上线 Workflow,而是把运行中产生的数据转成候选资产,再经过确定性 gate 和验证环境。
以 Java OOM 场景为例,系统可能从历史记录中生成三类候选结果:
text
Memory Hint:
该服务历史上出现过 JVM 参数与容器 memory limit 不匹配导致的 OOM。
Ops Manual Candidate:
Java 服务 OOM 诊断手册,包含适用条件、不能使用条件、必需证据和验证方法。
Workflow Candidate:
JVM 参数和 GC 日志只读诊断 Workflow,包含 preflight、采证、诊断报告和验证节点。这些内容最初都是 candidate。系统会先检查 schema、风险字段、敏感信息、参数完整性、Workflow digest、审批要求和验证路径。如果候选手册缺少"不能使用条件",或者 Workflow 把生产服务名写死,或者高风险节点没有审批要求,就会被挡在审核前。
容器矩阵:复现用户现场,验证优化是否有效
自动生成手册和 Workflow 最大的风险,是"看起来对,但只在某个偶然现场里对"。因此 AIOPS 的每次优化都要经过容器矩阵验证。
容器矩阵的目标是还原用户现场的关键变量。以 Java OOM 场景为例,矩阵可以覆盖:
text
JDK 版本:8 / 11 / 17
部署方式:Docker / Kubernetes
容器内存限制:512Mi / 1Gi / 2Gi
JVM 参数:Xmx 合理 / Xmx 超过容器限制 / 未显式设置
故障注入:堆内存上涨 / GC 延迟 / OOMKilled / 正常基线
权限条件:只读权限 / 缺少日志权限 / 缺少 K8s Events 权限
网络条件:正常 / 抖动 / 依赖不可达系统会在这些组合中启动沙箱容器或本地测试环境,运行候选 Workflow,并检查四件事:
- preflight 能否识别目标、权限和风险。
- execute 或诊断节点是否只做被允许的动作。
- verify 能否独立判断问题是否恢复或证据是否充分。
- rollback 或 fallback 是否能在失败时给出安全路径。
矩阵测试失败不会进入 verified,而是生成改进建议。例如:
- 某个节点依赖
jcmd,但基础镜像里没有安装。 - 某个 Workflow 在缺少 K8s Events 权限时误判为健康。
- 某个手册没有声明"无法读取 GC 日志时不能给确定结论"。
- 某个验证节点只检查进程存活,没有检查业务延迟恢复。
这些失败会反过来更新候选手册、Workflow 或测试用例。只有通过矩阵验证和人工审核的资产,才会成为后续可检索、可执行、可复用的 verified 资产。
三个场景:平台能力如何落地
场景一:一线 SRE 只说"系统变慢了"
凌晨一点,值班 SRE 收到业务响应慢的告警。传统做法是打开 Grafana 看延迟曲线,再去 Prometheus 查指标,去 Jaeger 找慢 Trace,去 Coroot 看服务拓扑,去 DeepFlow 查网络,再去 Kubernetes 看 Pod 状态。问题还没定位,人已经在多个面板之间切了十几次。
在 AIOPS 里,值班人员可以直接说:
text
现在系统变慢了,帮我排查一下。Agent 会先规划证据路径,而不是套用固定脚本:
text
理解用户意图
-> 查询 Prometheus 指标,定位慢请求集中在哪个服务
-> 调用 Coroot 拉取服务依赖拓扑
-> 查询 Trace,定位慢 span 和异常依赖边
-> 检索 DeepFlow 网络数据,确认是否存在容器网卡丢包
-> 汇总 Metrics / Logs / Traces / 网络证据,输出 RCA最终 SRE 看到的是带证据的结论,而不是一堆原始图表。用户不用先判断该查哪个面板,系统先把取数、时间窗对齐、噪声过滤和证据组织做完。
场景二:中间件慢查询经验被新人复用
资深 SRE 曾处理过一次 Redis 延迟飙升:根因不是 Redis 本身故障,而是某次业务发布后开始高频扫描大 key,导致 slowlog 增加、连接数占用上升,最终拖慢下游请求。几周后,另一个服务出现接口 P99 升高、Redis CPU 抬升和 slowlog 异常。
AIOPS 会通过"结构化事实 + 向量相似度"的双轨记忆检索历史事件,并把问题交给中间件 Agent 做专业化采证:
text
这次现象与历史 Redis 慢查询事件高度相似。
相似点:P99 上升、Redis CPU 升高、slowlog 命中 SCAN / HGETALL,大 key 访问集中在同类接口。
建议优先检查:slowlog、hot key / big key、调用方 Trace、最近发布变更。
注意:仍需采集当前证据,不能直接假设根因相同。新人得到的不是泛泛的 Redis 文档,而是团队过去真实解决过的问题线索。如果本次处置也被验证有效,系统会继续更新记忆,必要时生成或修正 Redis 慢查询诊断手册和只读采证 Workflow,并补充容器矩阵里的 Redis 版本、数据规模、key 分布和权限条件。
场景三:SRE Manager 定义策略,系统按边界自治
运维经理不应该每天在几十个告警群里判断每条告警是否重要。更合理的方式是把判断标准写成策略:
text
生产环境网络延迟波动在 5ms 内可以忽略。
数据库连接池打满时,按照方案 B 执行切流。
备库复制延迟超过 30 秒时,禁止自动切主。策略写入系统后,Agent 24 小时巡检容器、服务、中间件和 SLO。网络出现 3ms 抖动时,系统只记录,不打扰人。凌晨 2 点某容器数据库连接池 100% 占满时,系统会创建 Case、调用中间件 Agent 做只读 RCA、检查方案 B 的适用条件、运行 preflight、执行切流 Workflow,并验证 SLO 是否恢复。
如果 preflight 失败、备路不健康、策略冲突或验证失败,系统立即升级人工。也就是说,AIOPS 的自治边界是"标准之内自动处理,标准之外请示人"。
安全和可信:自进化系统最容易被忽视的部分
企业用户最担心两件事:AI 会不会乱执行,AI 会不会瞎判断。
AIOPS 的安全边界是:AI 可以主动排查和提案,但不能绕过治理直接改变生产。诊断脚本、临时命令和高风险探测优先在动态创建的沙箱容器里运行;需要影响线上状态的动作,必须走统一执行链路:
text
ToolDispatcher
-> PolicyEngine / OPA 类策略
-> Permission
-> Approval
-> ActionToken
-> Runner Workflow
-> Run Record
-> VerificationAIOPS 的可信边界是:所有结论都必须有证据链。RCA 报告必须列出 Metrics、Logs、Traces、拓扑、事件、变更和历史经验。证据不足时,系统必须说"不确定,还缺什么",不能强行给确定根因。
Prompt Trace 负责解释模型侧行为:当时模型看到了什么 prompt、哪些工具可见、哪些证据进入上下文、上下文是否压缩、为什么调用某个工具。它让 AIOPS 的判断可以被复盘,而不是事后只能猜。
结语:AIOPS 的关键是平台化进化
如果只看单个 Agent,AIOPS 像一个会自主排查的助手;如果看平台能力,它更像一个持续学习的运维系统。
巡检、告警、排障、发布、修复、复盘都会留下结构化记录;有效经验进入记忆系统;稳定流程变成候选运维手册和 Workflow;每次优化经过容器矩阵复现场景并验证;每次执行都被审计和回放。
这才是 AIOPS 与传统自动化最大的区别。传统自动化强调"把步骤写成脚本",AIOPS 强调"把现场经验变成经过验证的资产"。它不是让 AI 自由发挥,而是让 AI 在证据、策略、审核和测试的框架里持续进化。