大清已经亡了,但是八股文该背还是要背啊,别的不说,可以在别人面前好好装杯不是。
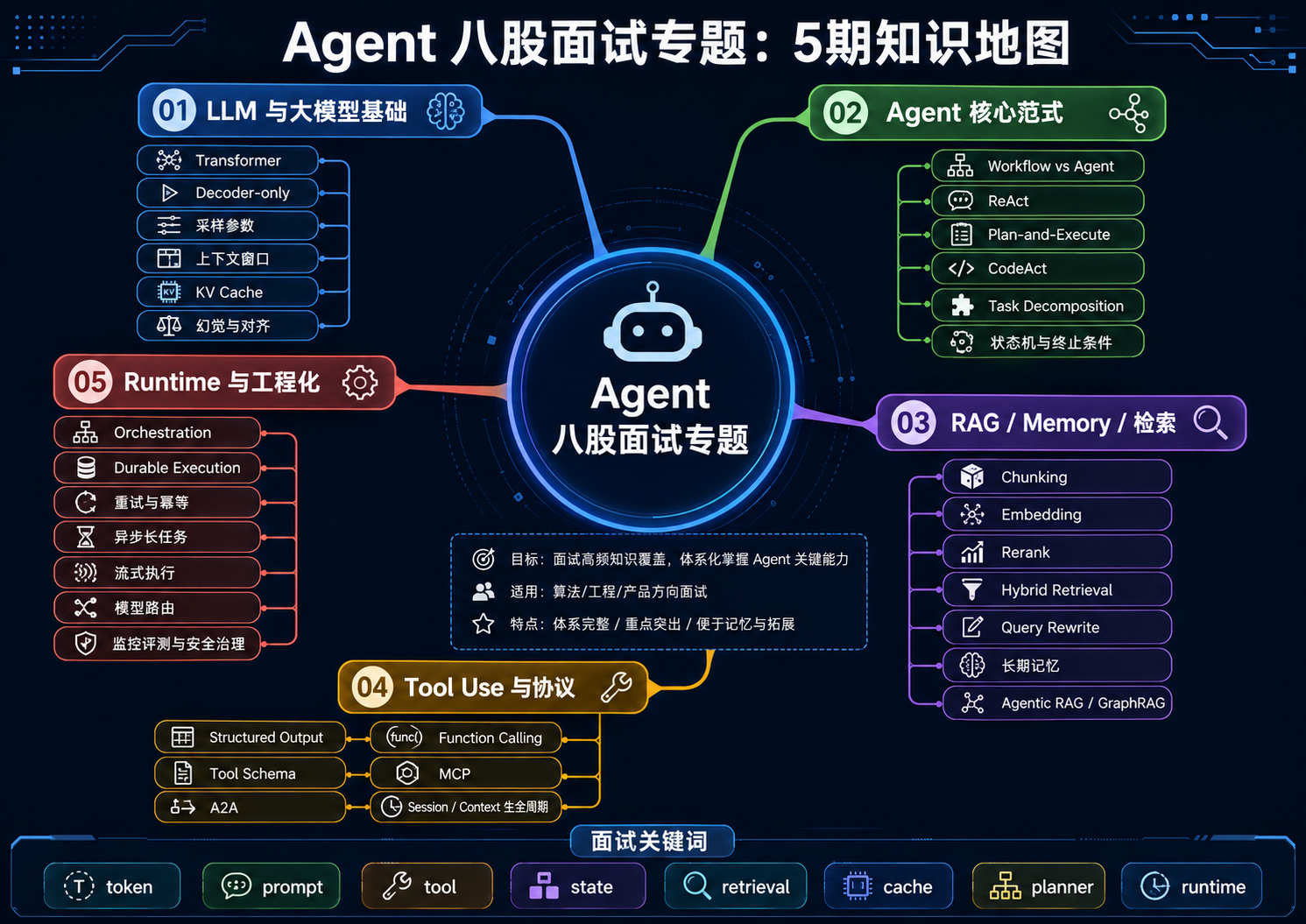
Agent 八股专题第二期:Agent 核心范式 10 连问
面向:Agent 工程师、大模型应用开发、RAG/Agent 平台开发、AI Infra 应用层岗位
风格:面试可讲,项目可用,代码能落地
目录
- 什么是 Agent?和普通 LLM Chatbot 有什么区别?
- Workflow 和 Agent 的边界是什么?
- ReAct 是什么?为什么它适合工具调用?
- ReAct 最大的问题是什么?
- Plan-and-Execute 是什么?比 ReAct 好在哪里?
- Plan-and-Execute 一定比 ReAct 更强吗?
- CodeAct 是什么?为什么软件工程 Agent 喜欢它?
- Agent 如何做 Task Decomposition?
- Agent Memory 到底解决什么问题?
- Agent 为什么必须有状态机和终止条件?
1. 什么是 Agent?和普通 LLM Chatbot 有什么区别?
一句话定义
Agent 不是"会聊天的大模型"。
Agent 更准确的定义是:
一个能基于目标,感知上下文,规划步骤,调用工具,根据反馈继续调整,并在满足终止条件后交付结果的系统。
普通 Chatbot 通常是:
text
用户输入 -> LLM 生成回答 -> 结束Agent 更像是:
text
用户目标
-> 理解任务
-> 规划步骤
-> 选择工具
-> 执行动作
-> 观察结果
-> 更新状态
-> 继续执行或终止普通 LLM 应用 vs Agent
| 维度 | 普通 LLM Chatbot | Agent |
|---|---|---|
| 核心能力 | 生成回答 | 完成任务 |
| 是否多步 | 通常单轮或短多轮 | 经常多步循环 |
| 是否调用工具 | 可选 | 通常是核心能力 |
| 是否维护状态 | 简单上下文 | 显式任务状态 |
| 是否有终止条件 | 通常没有复杂终止 | 必须设计终止条件 |
| 典型场景 | FAQ、闲聊、文本生成 | 数据分析、代码修复、搜索调研、自动化流程 |
面试回答模板
可以这样答:
普通 Chatbot 更像一个文本生成接口,而 Agent 是围绕目标执行的任务系统。它不仅调用 LLM,还需要工具、状态、观察、计划、记忆和终止条件。工程上,Agent 的难点不是让模型说得像人,而是让它在多步任务里可控、可恢复、可观测,并且不会无限循环或乱调用工具。
这句话要背下来。
别再说"Agent 就是大模型加工具"。这个回答太低级。
最小 Agent Loop 伪代码
python
def agent_loop(user_goal, tools, max_steps=8):
state = {
"goal": user_goal,
"steps": [],
"observations": [],
"final_answer": None
}
for step in range(max_steps):
action = llm_decide_next_action(state, tools)
if action["type"] == "final":
state["final_answer"] = action["answer"]
break
if action["type"] == "tool_call":
result = execute_tool(action["tool_name"], action["arguments"])
state["observations"].append(result)
state["steps"].append(action)
return state["final_answer"]这只是最小模型。真实生产系统还要加:
text
权限校验
参数校验
工具超时
失败重试
幂等控制
状态持久化
人工审批
trace 日志
终止条件2. Workflow 和 Agent 的边界是什么?
核心区别
Workflow 是确定性流程。
Agent 是不确定性决策。
Workflow 更像:
text
A -> B -> C -> DAgent 更像:
text
当前状态 -> 模型判断下一步 -> 执行 -> 根据结果继续判断对比表
| 维度 | Workflow | Agent |
|---|---|---|
| 路径 | 预先定义 | 运行时动态决定 |
| 控制权 | 工程师 | LLM + Runtime |
| 稳定性 | 高 | 较低,需要治理 |
| 可解释性 | 强 | 依赖 trace |
| 适合场景 | 固定业务流程 | 开放任务、多步探索 |
| 风险 | 灵活性不足 | 不可控、循环、误调用 |
面试官最想听的一句话
能用 Workflow 解决的,不要强行 Agent 化;只有当任务路径不固定、需要动态决策、需要根据观察结果调整策略时,才值得引入 Agent。
材料里也提到,Workflow 和 Agent 的边界是核心面试点:简单工作流能解决时,不要过度 Agent 化;复杂任务则需要把 Agent 和工作流编排结合起来。
真实业务例子
适合 Workflow 的任务
text
用户提交报销单
-> OCR 识别发票
-> 校验金额
-> 匹配审批人
-> 发送审批
-> 归档这个流程很固定,不需要 Agent 自由发挥。
适合 Agent 的任务
text
帮我分析这批用户投诉,找出主要原因,并给出整改建议。这个任务路径不固定:
text
可能要读文件
可能要分类
可能要聚类
可能要查历史工单
可能要生成统计图
可能要调用数据库
可能要写报告这时 Agent 才有意义。
工程上更成熟的设计
生产系统经常不是二选一,而是:
text
外层 Workflow 管可靠流程
内层 Agent 处理不确定步骤例如:
text
Workflow:
1. 接收任务
2. 文件解析
3. Agent 分析
4. 人工确认
5. 生成报告
6. 归档
Agent:
在第 3 步内部动态检索、调用工具、分析、反思3. ReAct 是什么?为什么它适合工具调用?
ReAct 的核心
ReAct = Reasoning + Acting。
它的基本循环是:
text
Thought -> Action -> Observation -> Thought -> Action -> Observation ...也就是:
text
想一下
-> 做一个动作
-> 看动作结果
-> 再决定下一步材料中对 ReAct 的描述也是:每一步交替进行 Reasoning 和 Acting,并利用 Observation 继续推进任务。
ReAct 示例
用户问:
text
帮我查一下杭州明天是否下雨,如果下雨,提醒我带伞。ReAct 过程可能是:
text
Thought: 我需要知道杭州明天的天气。
Action: call_weather_api(city="Hangzhou", date="tomorrow")
Observation: 明天杭州小雨,降水概率 70%。
Thought: 用户需要的是判断和提醒。
Final: 明天杭州大概率有小雨,建议带伞。简化实现
python
def react_agent(query, tools):
state = {
"query": query,
"history": []
}
while True:
model_output = llm_generate_react_step(state, tools)
if model_output["type"] == "final":
return model_output["answer"]
if model_output["type"] == "action":
tool_result = execute_tool(
model_output["tool_name"],
model_output["arguments"]
)
state["history"].append({
"thought": model_output.get("thought"),
"action": model_output,
"observation": tool_result
})为什么适合工具调用?
因为工具调用天然需要反馈:
text
模型不知道数据库结果
-> 调工具
-> 工具返回 Observation
-> 模型基于结果继续判断ReAct 刚好提供了这个结构。
面试表达
可以这样说:
ReAct 适合需要边探索边决策的任务。它的优势是简单、灵活,能把工具返回结果纳入下一步推理。但它的问题是容易局部贪心、循环调用工具,且缺少全局计划,所以长任务里通常要结合 planner、状态机和终止条件。
4. ReAct 最大的问题是什么?
核心问题
ReAct 的最大问题不是"不够聪明",而是:
text
局部贪心
容易循环
缺少全局计划
工具调用成本不可控
状态容易变脏材料里也总结得很直接:ReAct 的痛点是局部贪心和循环。
典型失败案例
用户说:
text
帮我总结这个项目最近三个月的技术风险。ReAct 可能这样跑:
text
Step 1: 搜索项目文档
Step 2: 看到一个日志错误,开始查日志
Step 3: 查到一个模块,继续查模块
Step 4: 发现另一个错误,继续查
Step 5: 跑偏,忘了用户要的是"三个月技术风险总结"这就是局部贪心。
它每一步看起来都合理,但整体偏离目标。
防止 ReAct 失控的工程手段
1. 最大步数
python
MAX_STEPS = 8但只靠 max_steps 很粗糙。
2. 工具调用预算
python
budget = {
"search": 5,
"database_query": 3,
"write_file": 1
}3. 重复动作检测
python
def is_repeated_action(action, history):
recent_actions = history[-3:]
return any(
action["tool_name"] == old["tool_name"] and
action["arguments"] == old["arguments"]
for old in recent_actions
)4. 目标一致性检查
python
def check_goal_alignment(goal, current_step):
prompt = f"""
Goal: {goal}
Current step: {current_step}
Is the current step still directly useful for the goal?
Answer only YES or NO.
"""
return llm(prompt)5. 显式终止条件
text
任务完成
信息不足
工具失败
预算耗尽
需要人工审批
风险过高面试回答模板
ReAct 的问题是每一步基于当前 observation 做局部决策,缺少全局任务视角。它适合短链路、反馈驱动的任务,但长任务容易循环、跑偏或过度调用工具。工程上要用 max steps、预算、重复检测、状态管理、目标对齐检查和 planner 来约束。
5. Plan-and-Execute 是什么?比 ReAct 好在哪里?
核心思想
Plan-and-Execute 是:
text
先整体规划,再逐步执行不是每一步都临时想,而是先得到一个全局路线。
基本结构
text
User Goal
-> Planner 生成计划
-> Executor 执行每一步
-> 每步记录状态
-> 必要时 Replan
-> Final Answer示例
用户任务:
text
帮我分析一个 GitHub 项目的代码质量,并给出改进建议。Plan 可能是:
text
1. 读取项目目录结构
2. 识别核心模块
3. 检查依赖和配置
4. 扫描常见代码坏味道
5. 运行测试
6. 汇总风险
7. 输出改进建议Executor 再一步步做。
简化代码
python
def plan_and_execute(goal):
plan = planner_llm(goal)
state = {
"goal": goal,
"plan": plan,
"completed_steps": [],
"artifacts": {}
}
for step in plan["steps"]:
result = execute_step(step, state)
state["completed_steps"].append({
"step": step,
"result": result
})
if result.get("need_replan"):
plan = replan_llm(state)
return final_summarize(state)相比 ReAct 的优势
| 维度 | ReAct | Plan-and-Execute |
|---|---|---|
| 决策方式 | 每步临时判断 | 先有全局计划 |
| 适合任务 | 短任务、探索任务 | 长任务、阶段明确任务 |
| 风险 | 容易跑偏 | 计划可能过时 |
| 控制性 | 中等 | 更强 |
| 中间产物管理 | 弱 | 更强 |
材料也明确指出:Plan-and-Execute 适合长链任务和阶段化管理。
面试回答模板
Plan-and-Execute 更适合长链任务,因为它先把目标拆成阶段,能更好管理中间产物、依赖关系和执行进度。相比 ReAct 的边走边看,Plan-and-Execute 有更强全局视角。但它不是万能的,因为计划可能随着新 observation 失效,所以通常需要动态 replan。
6. Plan-and-Execute 一定比 ReAct 更强吗?
不一定
这是一个很容易暴露水平的问题。
低水平回答:
Plan-and-Execute 更高级,所以更强。
错。
正确回答:
Plan-and-Execute 适合长任务,但会带来额外规划成本,并且计划可能过时。ReAct 适合短任务和强反馈任务。工程里通常混合使用。
材料中也总结:Plan-and-Execute 的痛点是计划失真和额外开销,工程里常见的是混合,而不是单选。
什么时候 ReAct 更合适?
text
任务短
反馈强
环境变化快
步骤不明确
试探成本低例如:
text
查一个订单状态
根据搜索结果回答一个问题
查询天气
根据数据库结果补充解释什么时候 Plan-and-Execute 更合适?
text
任务长
阶段清晰
中间产物多
需要全局路线
需要进度管理例如:
text
写一份行业调研报告
修复一个代码仓库里的 bug
分析一批日志并定位根因
生成完整项目方案混合模式
最常见的生产模式是:
text
先 Plan
每个 Step 内部用 ReAct
遇到复杂计算/代码任务用 CodeAct
高风险动作进入 Human-in-the-Loop伪代码:
python
def hybrid_agent(goal):
plan = create_plan(goal)
for step in plan:
if step["type"] == "simple_tool_task":
result = react_execute(step)
elif step["type"] == "code_task":
result = codeact_execute(step)
elif step["risk"] == "high":
approval = request_human_approval(step)
if not approval:
return "Stopped by human approval gate"
result = execute_step(step)
if result.get("plan_invalid"):
plan = replan(goal, current_state=result)
return summarize_results()7. CodeAct 是什么?为什么软件工程 Agent 喜欢它?
CodeAct 的核心
CodeAct 是把 Agent 的动作写成代码,而不是自然语言 tool call。
普通工具调用可能是:
json
{
"tool_name": "read_file",
"arguments": {
"path": "app.py"
}
}CodeAct 更像:
python
content = read_file("app.py")
print(content[:1000])为什么代码动作更强?
因为代码天然适合表达:
text
循环
条件判断
变量复用
文件处理
批量操作
复杂计算
异常捕获自然语言动作表达复杂逻辑时很容易啰嗦、模糊、不稳定。
材料中也提到:CodeAct 的动作以代码表达,适合精确执行与软件/数据任务,但痛点是执行安全与运行环境治理。
示例:自然语言工具调用很笨
任务:
text
读取 logs 目录下所有 .log 文件,统计 ERROR 出现次数最多的前 5 个文件。普通工具调用可能要多轮:
text
list_files
read_file
read_file
read_file
count
sort
...CodeAct 一段代码就可以:
python
from pathlib import Path
from collections import Counter
counter = Counter()
for file in Path("logs").glob("*.log"):
text = file.read_text(encoding="utf-8", errors="ignore")
counter[file.name] = text.count("ERROR")
print(counter.most_common(5))CodeAct 的风险
CodeAct 最大的问题不是能力,而是安全。
必须限制:
text
文件访问范围
网络访问权限
系统命令权限
执行时间
内存使用
敏感环境变量
危险 API简化沙箱策略
python
SAFE_BUILTINS = {
"len": len,
"range": range,
"print": print,
"sum": sum,
"min": min,
"max": max,
}
def safe_exec(code: str, sandbox_globals=None):
sandbox_globals = sandbox_globals or {}
sandbox_globals["__builtins__"] = SAFE_BUILTINS
exec(code, sandbox_globals)这个只是演示。生产环境不能这么简单,真实要用容器、权限隔离、资源限制和审计日志。
面试回答模板
CodeAct 不是 ReAct 的替代,而是动作表达形式的增强。对于代码修改、数据处理、文件批量操作、复杂计算,代码比自然语言 tool call 更精确。但 CodeAct 一定要配沙箱、权限、超时、审计和回滚,否则风险非常大。
8. Agent 如何做 Task Decomposition?
不要把任务拆解理解成"让模型列步骤"
这是新手最大误区。
真正的 Task Decomposition 至少要拆出:
text
子任务
依赖关系
输入输出
工具需求
成功标准
风险等级
是否需要人工审批材料也提醒,planning 不是一句"先让模型列个步骤",而是结构化系统能力。
差的计划
text
1. 分析需求
2. 查资料
3. 写结果废话,没有执行价值。
好的计划
json
{
"goal": "分析近三个月用户投诉并输出整改建议",
"steps": [
{
"id": "step_1",
"name": "加载投诉数据",
"tool": "query_database",
"input": {
"table": "complaints",
"date_range": "last_3_months"
},
"output": "complaint_records",
"success_criteria": "records_count > 0",
"risk": "low"
},
{
"id": "step_2",
"name": "投诉主题聚类",
"tool": "cluster_text",
"input": {
"source": "complaint_records"
},
"output": "topic_clusters",
"success_criteria": "at least 3 clusters with examples",
"risk": "medium"
},
{
"id": "step_3",
"name": "生成整改建议",
"tool": "llm_generate",
"input": {
"source": "topic_clusters"
},
"output": "improvement_report",
"success_criteria": "each suggestion maps to evidence",
"risk": "medium"
}
]
}Planner 输出结构建议
python
from pydantic import BaseModel
from typing import List, Optional
class PlanStep(BaseModel):
id: str
name: str
description: str
tool: Optional[str]
input_keys: List[str]
output_key: str
success_criteria: str
risk_level: str
class Plan(BaseModel):
goal: str
steps: List[PlanStep]面试回答模板
Task Decomposition 不是让模型随便列步骤,而是把目标拆成可执行、可验证、可恢复的子任务。每个子任务要有输入、输出、工具、依赖和成功标准。否则计划只是文本,看起来完整,实际上无法驱动系统执行。
这句话很关键。
9. Agent Memory 到底解决什么问题?
先说结论
Memory 不是把所有聊天记录永久塞回 prompt。
这是很多人最蠢的理解。
Agent Memory 解决的是:
text
跨轮次保留重要状态
减少重复询问
支持个性化
支持长期任务
保留任务进度
记录用户偏好
保存可复用经验Memory 和 Context Window 的区别
| 概念 | 作用 |
|---|---|
| Context Window | 当前请求能看到什么 |
| Memory | 系统长期保存什么 |
| State | 当前任务执行到哪一步 |
| Chat History | 原始聊天记录 |
| Summary | 压缩后的历史摘要 |
不要混在一起讲。
材料后面关于 Session-State 和 Context 生命周期也强调:长会话关键不是全保留,而是分层保存、按需注入、持续压缩;可靠 Agent 恢复执行依赖的是结构化状态,不只是聊天记录。
Memory 类型
1. Short-term Memory
当前任务内的上下文,例如:
text
用户这次要分析哪个文件
已经调用过哪些工具
当前执行到第几步2. Long-term Memory
跨会话信息,例如:
text
用户偏好 Markdown 输出
用户常用 Python
用户项目技术栈是 LangGraph + vLLM3. Episodic Memory
历史经验,例如:
text
上次处理类似日志问题时,是 Redis 超时导致的4. Semantic Memory
结构化知识,例如:
text
业务术语
组织架构
项目文档
API 说明Memory 注入策略
错误做法:
python
prompt = all_chat_history + all_user_memory + current_query这会让上下文越来越脏。
正确做法:
python
def build_context(query, task_state, memory_store):
relevant_memories = memory_store.search(query, top_k=5)
context = {
"current_query": query,
"task_state": task_state,
"relevant_memories": relevant_memories
}
return context面试回答模板
Memory 不是简单保存聊天记录,而是把对未来任务有价值的信息结构化保存,并在合适时机按需注入上下文。工程上要区分 session state、task state、user memory、chat history 和 external knowledge,否则 memory 会变成上下文污染源。
10. Agent 为什么必须有状态机和终止条件?
这是区分 Demo 和生产系统的核心
没有状态机的 Agent,通常是:
python
while True:
action = llm(...)
result = tool(action)这就是玩具。
生产系统必须知道:
text
现在处于什么阶段
下一步允许做什么
什么时候暂停
什么时候恢复
什么时候人工审批
什么时候重试
什么时候终止材料里也明确强调:Agent 一旦多步运行,就必须显式管理状态;终止条件应是多维的,不只是 max_steps;状态机是 HITL、重试、回滚、审批和幂等的共同基础。
一个简单状态机
text
CREATED
-> PLANNING
-> EXECUTING
-> WAITING_HUMAN_APPROVAL
-> COMPLETED
异常路径:
EXECUTING -> FAILED
EXECUTING -> NEED_RETRY
EXECUTING -> CANCELLEDPython 示例
python
from enum import Enum
class AgentStatus(str, Enum):
CREATED = "created"
PLANNING = "planning"
EXECUTING = "executing"
WAITING_APPROVAL = "waiting_approval"
COMPLETED = "completed"
FAILED = "failed"
CANCELLED = "cancelled"
class AgentState:
def __init__(self, goal: str):
self.goal = goal
self.status = AgentStatus.CREATED
self.current_step = None
self.completed_steps = []
self.error = None
self.tool_calls = []
self.budget_used = 0状态转移控制
python
VALID_TRANSITIONS = {
AgentStatus.CREATED: [AgentStatus.PLANNING],
AgentStatus.PLANNING: [AgentStatus.EXECUTING, AgentStatus.FAILED],
AgentStatus.EXECUTING: [
AgentStatus.WAITING_APPROVAL,
AgentStatus.COMPLETED,
AgentStatus.FAILED,
AgentStatus.CANCELLED
],
AgentStatus.WAITING_APPROVAL: [
AgentStatus.EXECUTING,
AgentStatus.CANCELLED
]
}
def transition(state: AgentState, next_status: AgentStatus):
allowed = VALID_TRANSITIONS.get(state.status, [])
if next_status not in allowed:
raise ValueError(
f"Invalid transition: {state.status} -> {next_status}"
)
state.status = next_status终止条件不能只有 max_steps
低级终止条件:
python
if step_count > 10:
stop()这只是保险丝,不是完整终止设计。
更完整的终止条件
text
1. 成功完成
2. 达到最大步数
3. 工具调用预算耗尽
4. 连续 N 次失败
5. 重复调用相同工具
6. 缺少必要信息
7. 需要人工审批
8. 检测到高风险动作
9. 用户取消任务
10. 当前目标无法完成终止判断示例
python
def should_stop(state):
if state.status in [
AgentStatus.COMPLETED,
AgentStatus.FAILED,
AgentStatus.CANCELLED
]:
return True
if len(state.completed_steps) >= 10:
return True
if state.budget_used > 100:
return True
if has_repeated_tool_calls(state.tool_calls):
return True
if state.error and state.error.get("retry_count", 0) >= 3:
return True
return False面试回答模板
Agent 必须有状态机和终止条件,因为多步执行不是一次模型调用,而是一个可中断、可恢复、可审批、可观测的流程。状态机解决当前任务处于什么阶段、允许什么转移;终止条件解决什么时候成功、失败、暂停或交给人工。没有这些,Agent 很容易死循环、重复调用工具、产生副作用或无法恢复。
第二期总结:Agent 核心范式的主线
这 10 题的底层主线是:
text
Agent 不是聊天机器人
-> Agent 是目标驱动的任务执行系统
-> Workflow 管确定流程
-> Agent 管不确定决策
-> ReAct 适合边想边做
-> Plan-and-Execute 适合长链任务
-> CodeAct 适合代码/数据/文件操作
-> Task Decomposition 要结构化
-> Memory 要按需注入
-> 状态机和终止条件保证可控真正的工程认知是:
Agent 的难点不在于"让模型会调用工具",而在于让整个多步执行过程可控、可恢复、可观测、可治理。
面试速记版
text
1. Agent = LLM + Goal + Tool + State + Observation + Control Loop。
2. Workflow 适合确定流程,Agent 适合不确定决策。
3. 能用 Workflow 解决的,不要强行 Agent 化。
4. ReAct = Thought + Action + Observation 循环。
5. ReAct 灵活,但容易局部贪心和死循环。
6. Plan-and-Execute 适合长链任务,但计划可能过时。
7. CodeAct 用代码表达动作,适合软件工程和数据处理。
8. Task Decomposition 要有输入、输出、依赖、工具和成功标准。
9. Memory 不是全量聊天记录,而是按需注入的长期状态。
10. 状态机和终止条件是 Agent 从 demo 走向生产的分水岭。第三期建议题目:RAG / Memory / Agentic RAG 方向
下一批 内容(还是再次求求各位高抬贵手点个赞点个转发,评论区写一个字就更好了,爱你们,比心!):
text
1. RAG 是什么?为什么不是简单向量搜索?
2. Chunking 为什么是 RAG 的核心难点?
3. 固定 token 切分有什么问题?
4. Embedding 和 Rerank 分别解决什么问题?
5. Hybrid Retrieval 为什么常比纯向量检索稳?
6. Query Rewrite 在 RAG 里有什么用?
7. RAG 和 Memory 有什么区别?
8. 长期记忆如何设计?
9. Agentic RAG 和普通 RAG 有什么区别?
10. GraphRAG 适合什么场景?