****论文题目:****GAN-based one dimensional medical data augmentation(基于GAN的一维医学数据增强)
****期刊:****Soft Computing (2023)
****摘要:****随着人类生活和社会的不断发展,医学领域也在不断完善。然而,现代医学仍然面临着许多限制,包括具有挑战性的和以前无法解决的问题。在这些情况下,人工智能(AI)可以提供解决方案。产生式对抗网络(GAN)的研究和应用就是一个明显的例子。虽然大多数研究人员关注的是图像增强,但一维数据增强的例子很少。从RT和CT图像中提取的放射组学特征是一维数据。据我们所知,我们是第一个将WGAN-GP算法应用于医学领域的放射组学数据生成的公司。在本文中,我们将一部分原始的真实数据样本输入到模型中。该模型学习输入数据样本的分布,生成与原始真实数据分布相似的合成数据样本,解决了获取标注医学数据样本的问题。我们已经在公共数据集心脏病克利夫兰和私人数据集上进行了实验。与传统的合成少数过采样技术(SMOTE)和普通GAN数据增强方法相比,我们的方法在不同数据比例下显著改善了AUC和SEN值。同时,我们的方法在ACC和SPE值方面也显示出不同程度的改善。这表明我们的方法是有效的和可行的。
训练自己的数据集代码可以从这里获取:(数据集以轴承故障诊断的CWRU为例)
用GAN解决医疗数据稀缺问题:WGAN-GP在一维影像组学数据增强中的应用
一、背景:医疗AI面临的"数据荒"
人工智能在医疗影像分析领域展现出巨大潜力,但训练一个可靠的深度学习模型往往需要海量标注数据。以图像识别领域的基准数据集为例,ImageNet 拥有超过 1400 万张图像,COCO 数据集也有约 30 万张。然而,在医学领域,这样规模的数据几乎是奢望------数据收集过程复杂昂贵,需要专业放射科医生参与标注,且涉及严格的患者隐私保护要求。
以本文的核心应用场景放射性肺炎(Radiation Pneumonitis, RP)诊断为例,研究团队收集到的真实世界数据集仅包含 300 名患者,其中阳性病例(RP 患者)仅 66 人,占比约 22%。这带来了两个核心问题:
- 样本稀少:总体数据量不足,难以训练鲁棒的深度学习模型;
- 样本不均衡:阴阳性样本比例悬殊,模型容易偏向多数类,对少数类(即阳性患者)的识别能力很差。
这种情况在医疗诊断中普遍存在,尤其是罕见病或并发症的诊断场景。如何在有限数据下训练出高性能分类模型,是本文要解决的核心问题。
二、现有方案的局限
2.1 传统过采样:SMOTE 的瓶颈
面对数据不均衡问题,最常用的传统方法是SMOTE(Synthetic Minority Oversampling Technique,合成少数类过采样技术)。其基本原理是:在真实少数类样本及其最近邻样本之间的连线上插值,生成新的合成样本,从而扩充少数类数量、平衡数据集。
然而,SMOTE 存在明显的局限性:
- 忽略多数类分布:合成样本时只考虑少数类的局部邻域,不考虑多数类的分布情况;
- 边界样本问题:当少数类样本位于两类边界时,合成样本容易落入多数类区域,造成类别重叠,反而降低分类精度;
- 噪声敏感:若少数类中存在噪声样本,SMOTE 会将噪声方向也纳入插值,生成质量低劣的样本。
2.2 GAN 的潜力与困境
生成对抗网络(GAN)由 Goodfellow 等人于 2014 年提出,由生成器(Generator, G)和判别器(Discriminator, D)组成,两者在对抗博弈中相互促进,最终使 G 能够生成与真实数据分布高度吻合的合成样本。
近年来,GAN 在医学图像增强领域取得了丰硕成果,包括肺结节合成、皮肤病变增强、胃癌内镜图像生成等。但这些工作几乎都聚焦于二维或三维图像数据。
本文关注的是另一种重要的医学数据形式------影像组学(Radiomics)特征 。影像组学是从 CT、MRI 等医学图像中提取的高通量定量特征,本质上是一维数值向量。与图像数据相比,一维数据中每个数值都有明确的临床含义,不能简单地像图像像素一样处理。此外,GAN 在处理一维低维数据时容易过拟合,普通 GAN 在小样本场景下性能会显著下降。
对于这一研究空白,据作者所知,此前尚无基于深度学习的影像组学数据增强研究,更无 GAN 方法的尝试。
三、本文方案:WGAN-GP 用于一维医学数据增强
3.1 从 GAN 到 WGAN-GP 的演进
为解决普通 GAN 训练不稳定的问题,研究者们提出了一系列改进:
- WGAN :用 Wasserstein 距离(地球移动距离,Earth-Mover Distance)替代 JS 散度来衡量真实分布与生成分布之间的差异。Wasserstein 距离的优势在于,即使两个分布几乎不重叠,它仍然能提供有效的梯度信号,从根本上解决了梯度消失问题。但 WGAN 通过权重裁剪来满足 Lipschitz 约束,这会导致:判别器参数堆积在边界值(如 0.01 或 −0.01),浪费模型拟合能力;还容易引发梯度爆炸。
- WGAN-GP :Gulrajani 等人提出用**梯度惩罚(Gradient Penalty, GP)**替代权重裁剪。GP 将判别器对输入的梯度 L2 范数约束在 1 附近,既保证了 Lipschitz 连续性,又避免了权重裁剪的缺陷,使训练更稳定、收敛更快。
本文正是将 WGAN-GP 应用于一维影像组学数据的生成增强。
3.2 网络结构设计
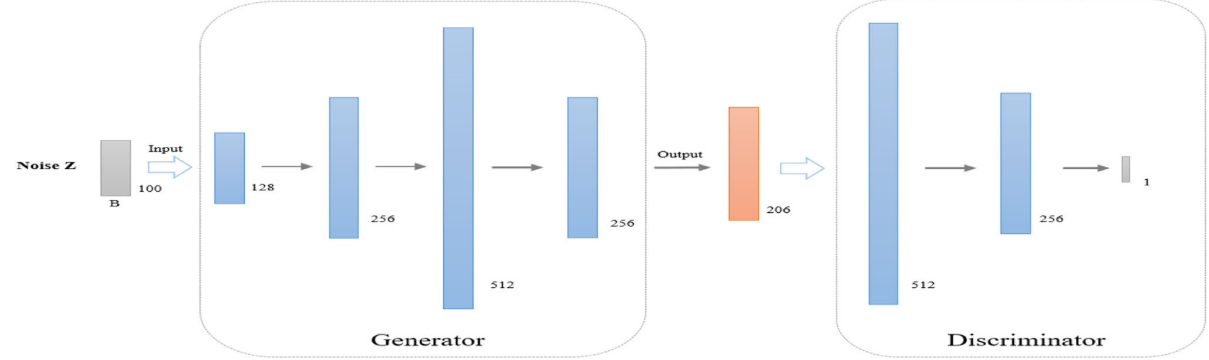
【 Fig. 1:WGAN-GP 网络结构图,展示生成器与判别器的全连接层组成及各层维度】
生成器(Generator) 的结构设计遵循"先扩张、后压缩"的思路:
- 输入:100 维随机噪声向量 z;
- 逐层扩展维度(100 → 128 → 256 → 512 → 256),保证所有特征都能充分表达;
- 再压缩至输出维度 206(即影像组学特征数量),提取最有效的特征表示;
- 每层之间加入 Batch Normalization(BN)层 和 LeakyReLU 激活函数;
- 输出层使用 Sigmoid 激活函数,将生成值压缩至 0, 1 范围。
判别器(Discriminator) 相对简单,考虑到数据集规模较小,采用三层全连接网络:
- 输入维度为 206,输出维度为 1;
- 层间使用 LeakyReLU 激活函数;
- 最后一层不含任何激活函数(这是 WGAN 系列的关键设计);
- 损失函数中加入 GP 项,约束梯度 L2 范数在 1 附近。
3.3 损失函数与梯度惩罚
WGAN-GP 使用 Wasserstein 距离衡量真实分布 Pr 与生成分布 Pg 之间的差异:
根据 Kantorovich-Rubinstein 对偶理论,等价形式为:
由此得到判别器损失:
梯度惩罚项定义为:
其中 为超参数(本文设为 100),通过惩罚梯度偏离 1 的程度,将判别器的梯度约束在合理范围内,避免梯度爆炸或消失。
3.4 训练流程
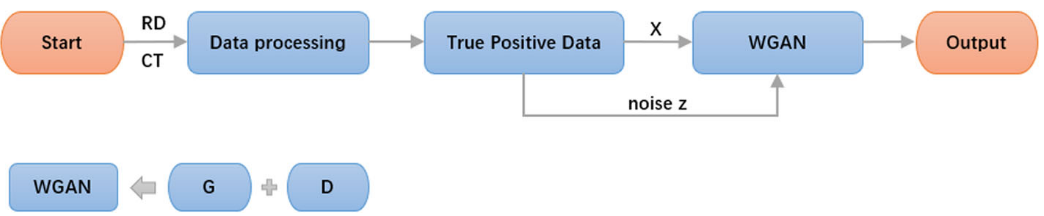
【Fig. 2:训练流程图,从数据预处理、真实阳性数据输入到 WGAN 模型训练和输出合成样本的完整流程】
训练策略为:先训练判别器,每 5 轮再训练一次生成器。具体步骤如下:
- 预处理:将原始 CT 影像组学特征和放疗计划剂量文件转换为数值特征并归一化;
- 判别器训练:将真实阳性样本和生成器产生的假阳性样本同时送入判别器,计算损失并反向传播;
- 生成器训练(每 5 轮执行一次):将随机噪声生成的假阳性样本送入判别器,根据判别结果更新生成器;
- 模型保存 :以判别器损失与 Wasserstein 距离之和的绝对值最小时保存最优模型(这与普通 GAN 仅看收敛曲线的策略不同)。
关键超参数设置:Epochs = 1000,学习率 = 0.0002,Batch_size = 16,Latent_dim = 100,Lambda_gp = 100。
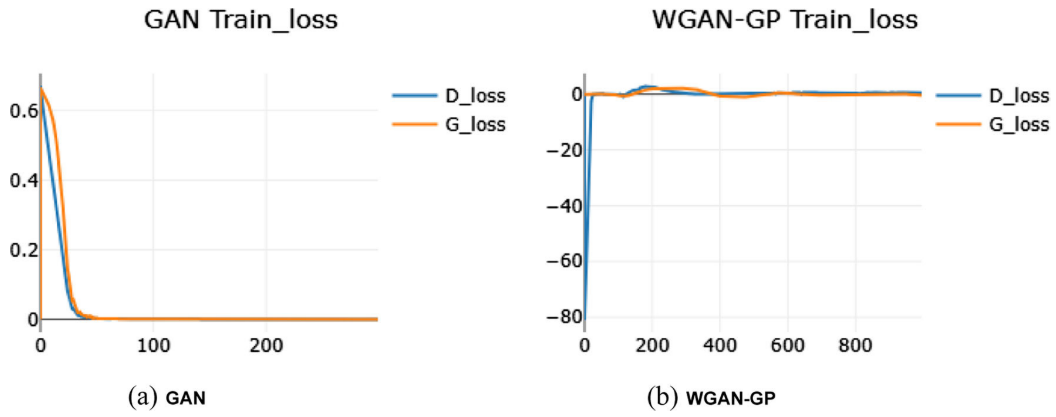
【 Fig. 3:GAN 与 WGAN-GP 训练损失曲线对比图,可直观看出 WGAN-GP 训练更平稳】
四、实验设置
4.1 数据集
数据集一:Heart Disease Cleveland(公开数据集) UCI 机器学习库中最常用的心脏病预测数据集,包含 76 个属性,实验中使用其中 14 个关键属性。目标标签为二值变量:0 表示低心脏病风险,1 表示高风险。
数据集二:Radiation Pneumonitis(放射性肺炎,私有数据集) 真实世界临床数据集,共 300 名患者,其中 66 人(22%)为放射性肺炎阳性。特征来源包括 CT 影像组学特征和放疗计划剂量文件(RD 文件),共提取 206 维特征。数据集存在明显的类别不均衡问题。
4.2 评估指标
研究采用四项分类性能指标,基于真阳性(TP)、真阴性(TN)、假阳性(FP)、假阴性(FN)定义如下:
- AUC:ROC 曲线下面积,综合反映分类器区分能力;
- ACC(准确率):(TP + TN) / (TP + TN + FP + FN);
- SEN(敏感性/召回率):TP / (TP + FN),反映对阳性患者的识别能力;
- SPE(特异性):TN / (TN + FP),反映对阴性患者的识别能力。
所有实验采用十折交叉验证,训练集与测试集比例为 2:8,每个逻辑回归模型重复训练测试 10 次取平均。对比方法包括 WGAN-GP、SMOTE、普通 GAN,以及无增强的真实数据基线。
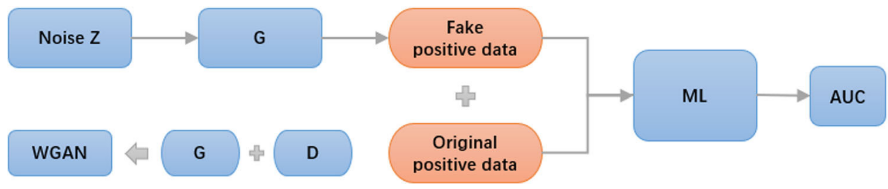
【Fig. 4:测试流程示意图,展示 Noise Z → G → 假阳性数据与原始阳性数据合并 → ML 分类器 → AUC 评估的完整测试流程】
五、实验结果
5.1 AUC 综合对比

【Table 1:四种方法在两个数据集上的 AUC ± 标准差对比表】
在Heart Disease Cleveland 公开数据集 上,WGAN-GP 取得了 0.902 ± 0.016 的 AUC,明显优于 SMOTE(0.874 ± 0.019)、真实数据基线(0.877 ± 0.023)和普通 GAN(0.837 ± 0.023)。
在放射性肺炎私有数据集 上,WGAN-GP 同样表现最优,AUC 达到 0.606 ± 0.009,高于 SMOTE(0.585 ± 0.012)、真实数据(0.584 ± 0.015)和普通 GAN(0.572 ± 0.014)。
值得特别关注的是,WGAN-GP 的标准差在两个数据集上均为最小,说明其生成结果最稳定、方差最小。统计检验显示 WGAN-GP 与各方法的 P 值分别为 0.498(vs SMOTE)、0.232(vs 真实数据)、0.440(vs GAN),虽未达到统计显著性(可能因样本量较小),但 WGAN-GP 的数值优势仍然明显。
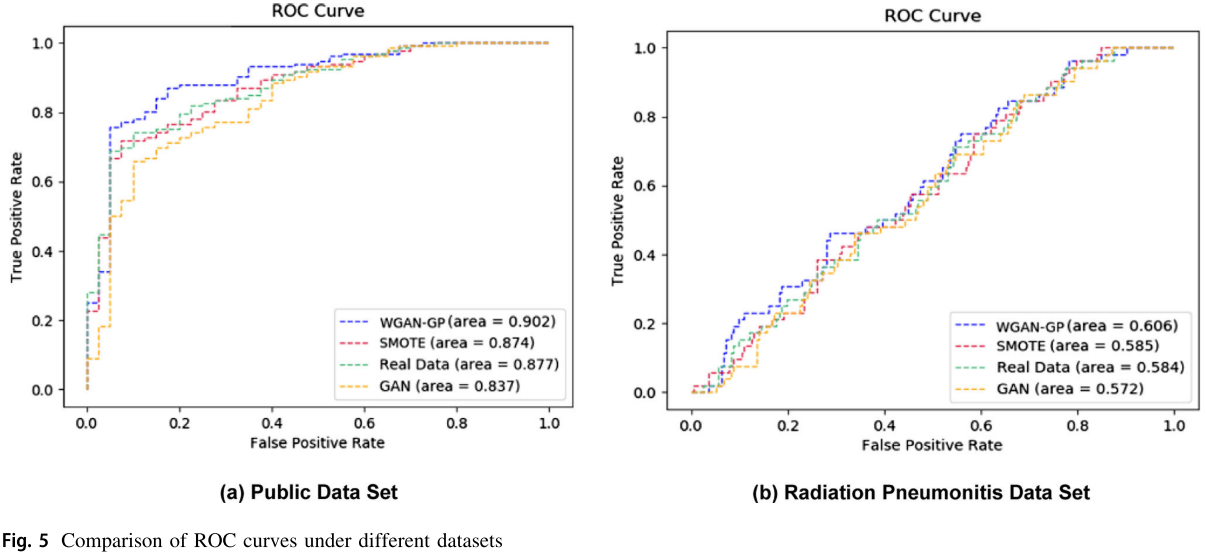
【Fig. 5:两个数据集上的 ROC 曲线对比图,(a) 公开数据集,(b) 放射性肺炎数据集,WGAN-GP 曲线在两张图中均位于最上方】
5.2 不同训练集比例下的表现
为验证方法在不同数据量条件下的鲁棒性,研究者将放射性肺炎数据集按 10%~90% 的比例划分训练集,分别评估四种方法的 AUC、ACC、SEN 和 SPE。
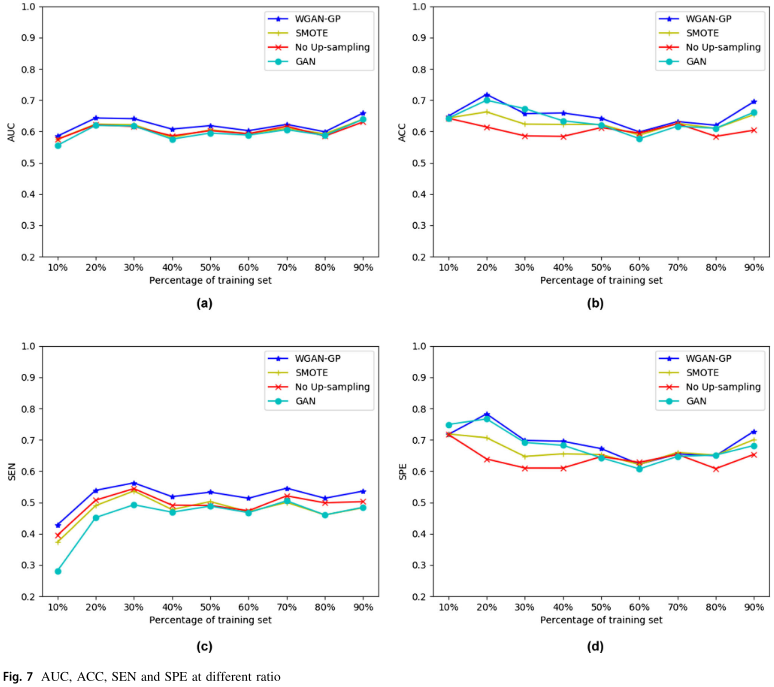
【Fig. 7:四个子图 (a)(b)(c)(d) 分别展示 AUC、ACC、SEN、SPE 在不同训练集比例(10%~90%)下的变化曲线,四条线分别对应 WGAN-GP、SMOTE、No Up-sampling、GAN】
实验结果揭示了几个重要规律:
- 小数据优势最显著:当训练集比例低于 30% 时,WGAN-GP 相对于 SMOTE 和 GAN 的提升幅度最大,这正是医学场景中最常见的困难情形;
- 数据量增加时差距收窄:随着训练集比例增大,各方法的差异逐渐缩小------这符合预期,因为数据充足时过采样的必要性降低;
- AUC 和 SEN 全面领先:WGAN-GP 在所有训练集比例下,AUC 和 SEN 均优于其他三种方法;
- ACC 和 SPE 也有提升:在大多数训练集比例下,ACC 和 SPE 也表现出不同程度的改善。
5.3 生成数据的分布可视化
研究使用 t-SNE(t-distributed Stochastic Neighbor Embedding) 将 206 维的高维特征降至二维,直观对比真实数据与三种方法生成数据的分布特征。
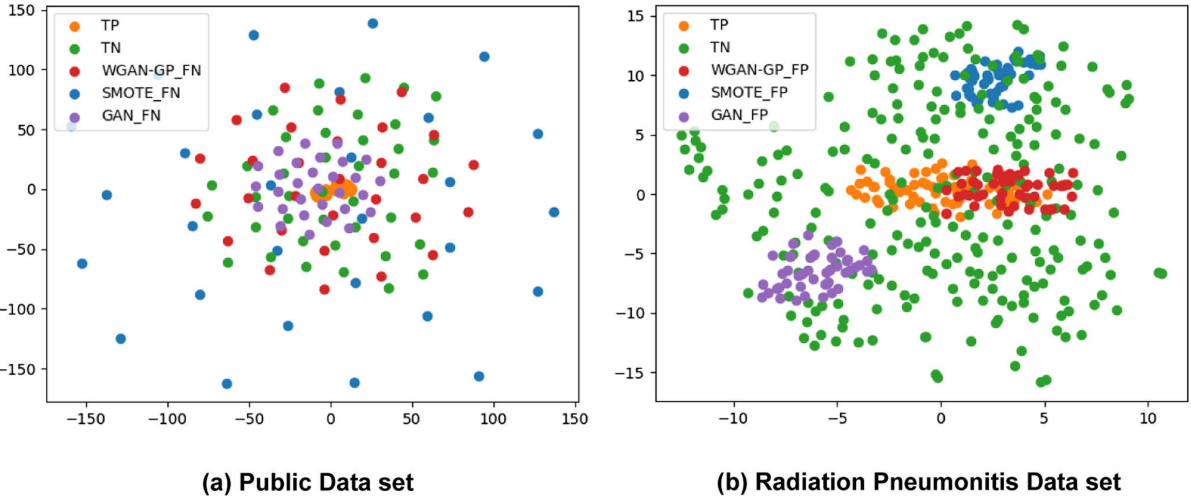
【Fig. 6:t-SNE 数据分布可视化图,(a) 公开数据集,(b) 放射性肺炎数据集,展示真实样本(TP/TN)与 WGAN-GP/SMOTE/GAN 生成样本的二维分布】
在公开数据集的降维分布图中,WGAN-GP 生成的假阴性样本(WGAN-GP_FN)相比 GAN 生成的样本,分布更宽、更接近真实阴性样本(TN);相比 SMOTE,WGAN-GP 生成的分布更内聚,说明它的样本空间更大但也更贴近真实分布。
在放射性肺炎数据集中,WGAN-GP 生成的假阳性样本(WGAN-GP_FP)集中分布在真实阳性样本(TP)附近,而 SMOTE 和 GAN 生成的样本则偏离真实正样本分布较远。
这一可视化结果从分布层面直观证明:WGAN-GP 能够更准确地学习并再现真实数据的分布特征,生成质量明显优于对比方法。
六、总结与展望
6.1 核心贡献
本文的核心价值可归纳为以下三点:
- 首创性:据作者所知,这是医学领域首次将 WGAN-GP 应用于影像组学一维数据增强,填补了该领域的研究空白;
- 实用性:方法直接面向医学数据稀缺与不均衡的真实痛点,在公开和私有两个数据集上均验证了有效性;
- 稳定性:相比 SMOTE 和普通 GAN,WGAN-GP 生成数据的方差更小、分布更接近真实数据,在小样本场景下(训练集 < 30%)优势尤为突出。
6.2 局限与未来方向
作者也坦承了现有方法的不足,并指出了两个值得继续探索的方向:
- 算法优化:进一步优化 WGAN-GP 在少样本一维数据集上的扩展能力,以实现更好的性能;
- 新型 GAN 架构:普通 GAN 在小样本低维数据场景下表现不佳,未来可探索新的 GAN 变体,结合 WGAN-GP 的稳定性优势,同时解决小样本低维数据的特殊挑战。
6.3 启示
这项工作的意义不仅在于技术本身,更在于它拓展了 GAN 在医疗 AI 中的应用边界------从视觉图像延伸到结构化的临床数值数据。随着医疗数字化深入推进,如何充分挖掘稀缺的临床数据价值,将是医疗 AI 落地的关键挑战之一。WGAN-GP 为这一挑战提供了一个有力的工具。