AI驱动的竞品分析多Agent协作系统设计理论
项目总览
┌─────────────────────────────────────────────────────────────┐
│ 前端层:React │
│ ├─ 竞品分析配置台:关键词录入、数据源范围自定义配置 │
│ ├─ 实时协作看板:DAG流程图可视化、Agent运行状态、中间产物预览 │
│ └─ 报告展示页:结构化报告渲染、信息溯源标注、多格式导出 │
├─────────────────────────────────────────────────────────────┤
│ 后端层:FastAPI │
│ ├─ REST API:任务提交、任务状态查询、报告拉取、结果下载 │
│ └─ SSE:Agent执行进度、实时日志流式推送 │
├─────────────────────────────────────────────────────────────┤
│ Agent调度引擎层:LangGraph │
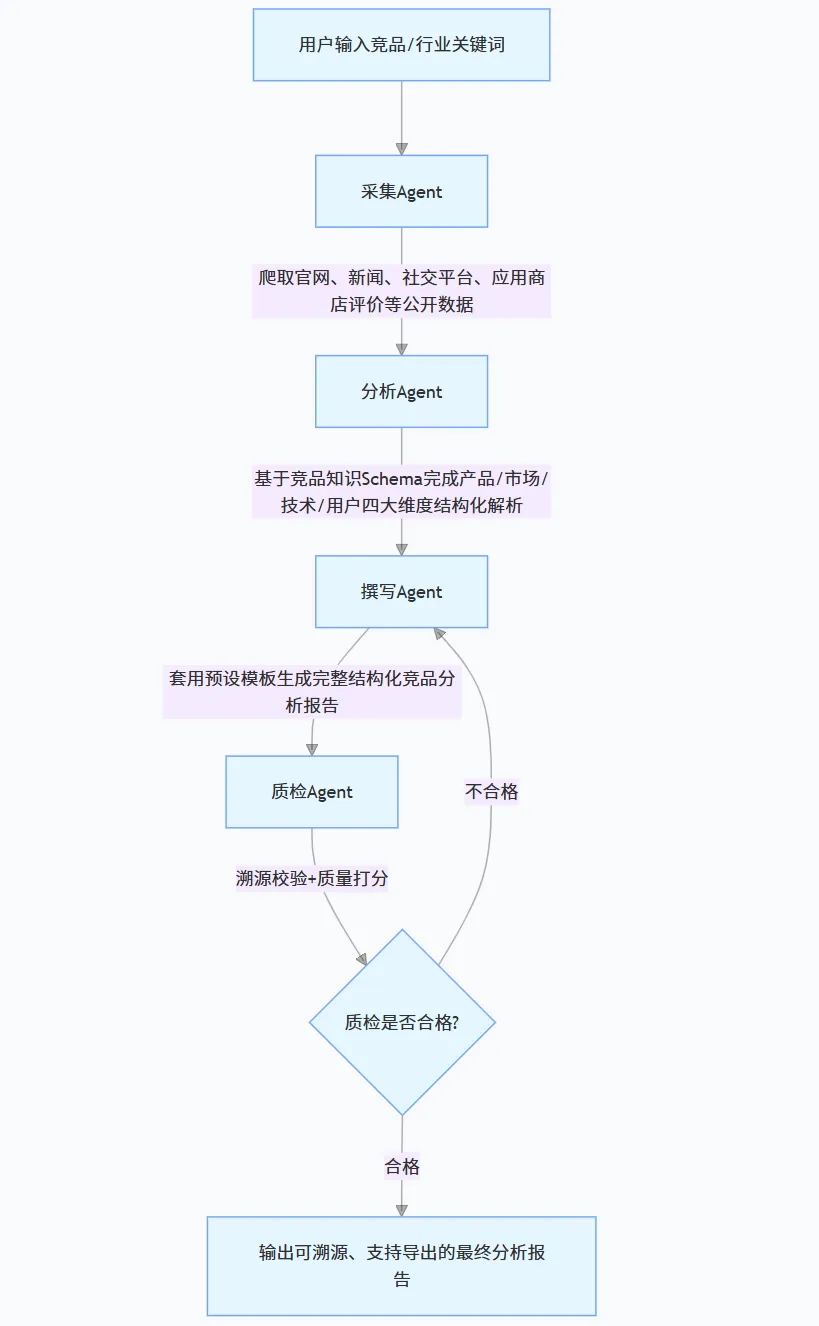
│ ├─ 采集Agent:搜索引擎API调用 + 定向网页内容抓取 │
│ ├─ 分析Agent:LLM + RAG检索增强 + 标准化知识Schema解析 │
│ ├─ 撰写Agent:LLM内容生成 + 固定报告模板渲染 │
│ └─ 质检Agent:LLM-as-Judge打分 + 原文溯源校验、不合格回滚 │
├─────────────────────────────────────────────────────────────┤
│ 持久化存储层 │
│ ├─ PostgreSQL:任务记录、Agent运行轨迹、最终分析报告持久化 │
│ └─ pgvector:存储抓取文本,支撑RAG检索 │
└─────────────────────────────────────────────────────────────┘
一、概述
Agent 应用工程实战阶段,核心命题是:Agent 代码写出来只完成了 30%,剩下 70% 是把它变成生产级服务。本阶段以"竞品分析多 Agent 协作系统"为案例,横跨 RAG 生产落地、Prompt 工程化、Agent 服务化、可观测性和评估体系五大模块,覆盖 Agent 应用从 POC 到上线的完整工程链路。
五大模块全景
┌──────────────────────────────────────────────────────────────────┐
│ L4-A Agent 应用工程实战 │
├──────────────────────────────────────────────────────────────────┤
│ │
│ M1 RAG 生产落地 M2 Prompt 工程化 M3 Agent 服务化 │
│ ├ BGE-M3 Embedding ├ 模板化框架 ├ FastAPI 异步服务 │
│ ├ 语义分块 ├ Few-shot 正负例 ├ 三层限流降级 │
│ ├ 混合检索+RRF ├ LLM-as-Judge ├ SSE 流式推送 │
│ ├ Multi-Query 改写 ├ 打回重写闭环 ├ Checkpoint 持久化 │
│ └ RAGAS 评估 └ 版本管理 └ 部署拓扑 │
│ │
│ M4 Agent 可观测性 M5 Agent 评估体系 │
│ ├ 三层金字塔 ├ Golden Dataset │
│ ├ 30+ 关键指标 ├ RAGAS+Judge 双轨 │
│ ├ Trace 链路回溯 ├ 回归测试自动化 │
│ ├ Grafana 六面板 ├ 决策门禁(≥0.85通过) │
│ └ 日志方案(3种) └ 线上评估闭环 │
│ │
└──────────────────────────────────────────────────────────────────┘二、Module 1:RAG 生产落地
2.1 架构设计
竞品分析系统在采集 30+ 网页后,通过 RAG 管线为 LLM 提供精准上下文:
采集数据 → 语义分块 → BGE-M3 Embedding → Chroma/pgvector 入库
↓
用户请求 → Multi-Query 改写 → 混合检索 Top-K → Prompt 组装 → LLM 输出2.2 关键设计决策
Embedding 选型:BGE-M3
| 维度 | BGE-M3 | OpenAI text-embedding-3-large |
|---|---|---|
| 中文效果 | 优(中文训练数据充分) | 良 |
| 维度 | 1024(存取平衡) | 3072(维度高、存储大) |
| 成本 | 自部署免费 | 按 token 计费 |
| 吞吐 | 本地推理,不受 API 限流 | 受 API rate limit |
分块策略:语义边界分块
- 块大小:800-1200 token(不是固定长度,按语义边界切割)
- 切割边界:段落、标题、列表、代码块
- 重叠:10-15% 的 overlap 窗口,防止关键信息被切断在两块之间
- 反面案例:固定 500 token 切分 → "飞书企业版定价为 200 元/人/年"被切成"飞书企业版定价为"和"200 元/人/年"两块 → 检索"定价"命中前半段但关键数字在后半段
混合检索:Vector + BM25 + RRF
纯向量检索的问题:向量相似度会召回"语义相关但内容无用"的片段(如导航栏文字、页脚)。
混合检索流程:
1. 向量检索:cosine_similarity(query_embedding, chunk_embedding) → Top-20
2. BM25 全文检索:tsvector @@ tsquery → Top-20
3. RRF 融合:score = Σ 1/(k + rank),k=60
4. 取 RRF Top-5 作为最终上下文
召回率:纯向量 ~75%,混合检索 ~90-95%Query 改写:Multi-Query 策略
一个用户输入"分析飞书功能"拆成 3-5 个变体:
原始 Query:"飞书产品功能分析"
→ Q1: "飞书 核心功能 特色"
→ Q2: "飞书 差异化功能 竞品对比"
→ Q3: "飞书 功能更新 2025 2026"
→ Q4: "飞书 文档 会议 日历 多维表格"
→ Q5: "飞书 产品功能 用户评价"
各变体独立检索 → 合并去重 → Top-K2.3 架构约束
- 检索延迟控制在 200ms 以内
- 混合检索的 RRF k 值设为 60(标准推荐值)
- BGE-M3 约 2GB,首次调用懒加载
- 向量存储:PostgreSQL + pgvector(与 Checkpoint、日志共用一套数据库)
三、Module 2:Prompt 工程化
3.1 核心思路
竞品分析系统的四个 Agent(采集/分析/撰写/质检)各有独立的 Prompt 设计模式。同一个 System Prompt 模板要对飞书/钉钉/Notion 等不同竞品都输出正确的五维 Schema。
3.2 关键设计
模板化 + 动态注入
分析 Agent Prompt 结构:
角色设定(System) "资深竞品分析专家"
硬约束 不编造 / 标注来源 / 区分事实与推测
动态占位符 {current_dimension_schema}
{retrieved_context}
输出格式控制 [已确认] vs [推测]
来源标注格式 [来源:URL]五个维度共用一套 Prompt 框架,DIMENSION_SCHEMAS 字典按维度注入不同的 Schema JSON。天然支持 A/B 测试:同一竞品跑不同 Schema 版本对比。
Few-shot 正负例
为什么需要负例?LLM 默认倾向是"填空"而非"留白"------只给正例,信息不足时 LLM 依然会编造。
两个最容易翻车的维度:
- 市场定位:LLM 倾向编造份额数据("市占率约 35%"------实际上找不到)
- 用户评价:5 条差评被 LLM 放大为"口碑崩塌"
正例展示"信息充足时的理想输出",负例展示"信息不足时正确留白:信息不足 + 已确认部分"。
质检 Agent 的 Judge Prompt(LLM-as-Judge)
- 质检用独立模型,不与分析 Agent 共用(防"自己出卷自己批")
- 五维子项评分:完整性 30% / 准确性 30% / 溯源力 20% / 可读性 10% / 客观性 10%
- LLM 不打总分,子项各自独立打分后加权计算(方差比直接让 LLM 打总分低 60%+)
- 打回阈值 70 分硬编码(不用 LLM 判断"需要重写吗",二值判断不稳定)
critical_issues字段列出具体问题 → 注入撰写 Agent 的重写 Prompt
打回重写反馈闭环
不是"质量不行,重新生成",而是精准反馈:
"市场定位维度:缺少竞品对比数据。
建议补充:与钉钉/飞书在目标客群上的区分;定价策略对比表。
[来源标注] 第3条结论'中小企业首选'缺 URL 引用。"版本管理
prompts/
analysis/
v1_system.md # 初版
v2_system.md # +市场定位负例
v3_system.md # +来源格式约束
current.txt # 符号链接 → v3_system.md
发版规则:
旧版保留 7 天可回滚
10 个测试用例验证
质量分提升 < 3 分不发布
变更日志必写四、Module 3:Agent 服务化
4.1 服务架构
前端 (Vue)
POST /api/analyze → 开始分析
GET /api/analyze/{task_id}/stream → SSE 进度
GET /api/analyze/{task_id}/report → 最终报告
GET /health → 健康检查
FastAPI 服务层
POST /analyze: 参数校验 → 限流检查 → 创建task_id(202) → BackgroundTasks
GET /stream: StreamingResponse → SSE 实时推状态
GET /report: JSON/Markdown 报告
LangGraph Agent 引擎
采集Agent → 分析Agent → 撰写Agent → 质检Agent4.2 异步化与并发控制
采集 Agent 需要并发抓取 30+ URL,用 asyncio.Semaphore(10) 控制并发度:
- Semaphore(10):实测超过 15 并发部分网站返回 429
asyncio.wait_for(url, timeout=8):5 秒太紧(国外网站慢),15 秒太松- 失败自动重试 1 次,避免一次网络波动报告"采集失败"
- 汇总用
asyncio.gather(*tasks),全部并发执行
4.3 三层限流 & 降级
| 层级 | 限制对象 | 工具 | 阈值 | 触达行为 |
|---|---|---|---|---|
| 入口层 | 用户请求频率 | TokenBucket | 100 QPS | 返回 429 |
| Agent 层 | 单任务并发分析数 | Semaphore(3) | 3 个同时 | 排队等待 |
| 外部层 | LLM API 速率 | 指数退避 | DeepSeek 60 RPM | 1s→2s→4s→降级 |
降级策略:五个维度独立处理。某维度 LLM 超时/限流 → 标记 [信息不足],写日志,继续下一个维度。4/5 维度完整 ≠ 整体失败。
4.4 SSE 流式推送
LangGraph 的 astream() 天然支持流式:每完成一个节点 yield 当前状态。FastAPI 包装成 SSE:
python
async def event_stream(task_id):
async for event in graph.astream({"task_id": task_id}):
yield f"data: {json.dumps(event)}\n\n"
yield f"data: {json.dumps({'type': 'done'})}\n\n"前端 EventSource 接收 → 进度条 + 当前步骤描述,消除"页面卡 2 分钟突然蹦报告"的体验。
4.5 Checkpoint 持久化
| 方案 | 适用阶段 | 特点 |
|---|---|---|
| MemorySaver | 开发 | 进程重启丢失 |
| SQLiteSaver | 单机生产 | 文件持久化,重启保留 |
| PostgreSQLSaver | 多实例生产 | 多实例共享状态 |
Checkpoint 目录结构:
checkpoint/{task_id}/
state.json # LangGraph 状态快照
evidence/ # 原始采集数据
report_v1.json # 初版报告
report_v2.json # 质检打回后版本
quality_score.json # 质检打分明细4.6 部署拓扑
Nginx :80 (反向代理 + 限流 100rps)
↓
FastAPI Uvicorn workers=2 (:8000 :8001)
↓
PostgreSQL + pgvector (一体化存储:Checkpoint + 向量 + 日志)
↓
DeepSeek API (限流 60 RPM)五、Module 4:Agent 可观测性
5.1 三层金字塔模型
Badcase 归因层 ← "出事了,根因是什么?" → 需要 Trace
业务指标层 ← "系统健康吗?" → 质量分/打回率
基础设施层 ← "活着吗?" → CPU/QPS/延迟5.2 关键指标体系(30+ 指标)
采集阶段:collection_success_rate、collection_latency_p95、source_type_distribution
分析阶段:dimension_success_rate、dimension_insufficient_rate(核心)、rag_recall_top5_hit、llm_call_count_per_task
质检阶段:avg_quality_score、retry_rate、quality_score_variance
端到端:task_duration_p95、task_success_rate
基线方法:上线前跑 50 个样本算均值,阈值 = 基线 ± 30%,超限告警。
5.3 Trace 链路回溯
每条日志必含:timestamp、task_id、agent、stage、dimension、metrics(duration_ms/token_count/chunk_count/sources_found)、error。
task_id 串联完整链路。出 Badcase 时沿 Trace 一步步回溯------不是模糊猜"可能是 LLM 的问题",而是精准定位到"chunk_17 是 2024 年升级公告,LLM 把新闻报道中重提的旧功能当成了差异化卖点"。
5.4 Grafana 监控大盘(六面板)
| 面板 | 回答的问题 | 受众 | 异常排查 |
|---|---|---|---|
| ① 链路耗时(堆叠面积图) | 哪个阶段是瓶颈? | on-call | 分析阶段从 26s→60s |
| ② 五维度完成率(柱状图) | 哪些竞品类型难分析? | PM | "商业表现"长期 <50% |
| ③ 采集源类型分布(饼图) | 采集结果是否多样? | 开发 | 官网占比 >70% |
| ④ 质检分趋势(折线+移动平均) | Prompt 改动是否有效? | 开发 | 连续 3 点下降 → 回滚 |
| ⑤ Badcase 表格(可展开) | 当前已知问题? | 全员 | 按分桶聚合看最突出问题 |
| ⑥ Token 用量 & 成本 | 烧了多少钱? | TL | 日成本超预算 |
5.5 告警体系
| 等级 | 触发条件 | 响应时间 |
|---|---|---|
| P3 🟢 | dimension_insufficient_rate > 基线+30% 持续 3h | 工作时间 |
| P2 🟡 | collection_success_rate < 0.70 或 API 错误率 > 5% | 当天处理 |
| P1 🔴 | task_success_rate < 0.50 持续 5min 或 健康检查连续失败 | 立刻叫醒 |
5.6 日志方案
三种方案覆盖不同阶段:
| 方案 | 适用 | 额外组件 | 查询能力 |
|---|---|---|---|
| A: 文件 + 轮转 | POC/开发 | 0 | grep |
| B: 文件 + Loki + Promtail | 多服务生产 | 2 | LogQL |
| C: PostgreSQL 直接存储 | 单机生产(推荐) | 0(复用 PG) | SQL JOIN |
推荐 C:agent_logs 表(JSONB metrics 列 + pg_cron TTL 30 天),SQL JOIN 可直接关联 checkpoints/reports 做 Trace 关联查询。
六、Module 5:Agent 评估体系
6.1 评估难点
Agent 输出是自然语言报告,不能套传统 ML 分类指标(准确率/F1)。核心矛盾:
- 局部正确、局部错误怎么加权?
- 不同竞品信息量差异巨大,不能一个分数线套所有
- 措辞不同但意思相同("4000 万用户" ≈ "用户量约 4000 万")怎么判断?
6.2 Golden Dataset
10 个竞品 × 手写标准报告,覆盖 easy/medium/hard 三个难度梯度:
| 竞品 | 选择原因 | 难度 | 覆盖场景 |
|---|---|---|---|
| 飞书 | 成熟 SaaS,信息丰富 | easy | 信息充足标准 case |
| 钉钉 | 同市场竞品 | easy | 差异化分析能力 |
| Notion | 海外产品 | medium | 英文源 + 跨市场 |
| Figma | 垂直领域 | medium | 专业术语处理 |
| 墨刀 | Figma 替代 | hard | 小众产品采集 |
| 小鹅通 | B+C 混合 | medium | 复杂商业模式 |
| 剪映 | C 端产品 | medium | B 端 vs C 端源差异 |
| 腾讯问卷 | 免费增值 | medium | 定价模式识别 |
| 石墨 | 新兴产品 | hard | 信息不足边界 |
| 蓝湖 | 设计协作 | medium | 跨维度信息关联 |
四个要求:人工确认(Golden 不能 LLM 生成)、覆盖难度梯度、覆盖边界 case、版本可更新。
6.3 双轨评估管线
Track 1:RAGAS 检索质量
- Faithfulness > 0.90:每句话能否在检索上下文找到支撑?
- Answer Relevancy > 0.85:内容是否紧扣当前维度?
- Context Precision > 0.80:召回 chunk 中有用比例
- Context Recall > 0.85:Golden 重要信息是否被召回到?
Track 2:LLM-as-Judge 报告质量
- 维度对齐率 40%:逐字段比对 Golden
- 事实准确率 40%:数字/日期/定价一致性(允许模糊等价)
- 溯源覆盖率 20%:结论标注来源的比例
6.4 决策门禁
综合分 ≥ 0.85 → 🟢 通过,上线
综合分 0.70~0.85 → 🟡 预警,人工 review
综合分 < 0.70 → 🔴 阻断,必须修复
阻断性错误:
数字差一个数量级 / 维度内容混乱 / 严重幻觉 / 定价错误6.5 回归测试自动化
每次 Prompt 改动、模型升级、分块策略调整后,跑全量 Golden Dataset,与上一版对比:
- diff < -0.05 → REGRESSION,不能上线
- diff > +0.03 → IMPROVEMENT
- 综合评估报告输出,每条 Golden 的 v3 分 vs v4 分 diff 一览
6.6 线上评估
离线评估决定"能不能上线",线上评估决定"上线后好不好"。质检 Agent 持续实时打分,质量波动 + Badcase 五维分桶触发告警,驱动修复迭代。
七、存储架构演进:PostgreSQL + pgvector 一体化
竞品分析系统最终采用 PostgreSQL + pgvector 一体化存储方案,替代分散的 SQLite + Chroma:
PostgreSQL + pgvector (一个数据库)
schema: competitive_analysis
├── tasks 任务表
├── checkpoints LangGraph 状态(JSONB)
├── documents 采集原始文档
├── chunks 分块后文本
├── chunk_embeddings 向量 (pgvector, 1024d, HNSW 索引)
├── reports 分析报告(多版本)
├── evidence_map 溯源数据
├── quality_scores 质检打分明细
└── agent_logs 结构化日志(JSONB, pg_cron TTL)
一个连接池 → 全部操作
ACID 事务 → Checkpoint + Embedding 原子写入
tsvector → 全文检索 (BM25)
pgvector cosine_distance → 向量检索
混合检索 → 一个 SQL 搞定 RRF 融合优势:少一个组件少一个故障点;事务保证 Checkpoint 和 Embedding 要么全成功要么全回滚;SQL JOIN 自然实现 Trace 关联;全文检索不额外引入 ES。
八、面试核心话术合集
Q1:你做的竞品分析 Agent 系统用了什么技术栈?
"后端 FastAPI + LangGraph Agent 编排,存储层用 PostgreSQL + pgvector 一体化方案(Checkpoint 持久化 + 向量检索 + 日志全在一个数据库)。四个专职 Agent 协作------采集 Agent 用 asyncio.Semaphore 并发抓取 30+ 源,分析 Agent 走 BGE-M3 嵌入 + 混合检索(向量+BM25+RRF)的 RAG 管线,撰写 Agent 用模板化 Prompt + Schema 动态注入组织报告,质检 Agent 用 LLM-as-Judge 五维评分 + Badcase 分桶。前端用 SSE 实时推送进度。基础设施层有三层限流降级、Checkpoint 持久化、三级告警和 Grafana 六面板监控。"
Q2:RAG 你们是怎么做的?
"分块用语义边界切割,800-1200 token + 10-15% 重叠,避免了固定长度切断关键信息。Embedding 选 BGE-M3,1024 维,中文效果好且自部署免费。检索用向量 + BM25 的混合检索,RRF 融合后召回率比纯向量高 15-20%。Query 做了 Multi-Query 改写,一个输入拆 3-5 个变体独立检索合并。检索质量用 RAGAS 四维评估------Faithfulness > 0.9、Context Precision > 0.8、Context Recall > 0.85。"
Q3:Prompt 工程你们是怎么做的?
"分析 Agent 的 Prompt 是模板化框架 + 五个维度的 Schema 变量注入。关键设计是 Few-shot 给了正例和负例------负例展示信息不足时如何正确留白,防止 LLM 编造。质检 Agent 用的是 LLM-as-Judge 模式,跟分析 Agent 用不同模型,五维子项打分加权计算------不直接让 LLM 打总分,方差低 60%+。打回重写不是简单'重新生成',而是把质检的结构化反馈注入 Prompt,精准指出哪里需要改。Prompt 版本有管理机制:旧版保留 7 天可回滚、10 个用例验证、提升 < 3 分不发布。"
Q4:Agent 系统怎么服务化上线的?
"FastAPI 做服务层------采集 Agent 并发用 asyncio + Semaphore(10)。三层限流保障稳定性:入口 TokenBucket 100QPS 返回 429、Agent 层 Semaphore(3) 排队、LLM API 指数退避 3 次后降级标记'信息不足'。前端用 SSE 流式推送 Agent 进度,不是黑盒等 2 分钟。Checkpoint 用 PostgreSQL 持久化,中间崩溃从断点继续而不是重跑。部署 FastAPI Uvicorn 2 workers + Nginx 反向代理,全链路异步 IO。"
Q5:Agent 系统的监控和可观测性怎么做?
"建了三层。基础层 Prometheus 收 CPU/QPS/延迟。业务层定义了 30+ Agent 专属指标------dimension_insufficient_rate 是最核心的,每个指标有基线和告警阈值(跑 50 个样本算出来的)。链路层在每个 Agent 节点出入口埋结构化日志,task_id 串联 Trace。出 Badcase 时沿 Trace 一步步回溯到具体 chunk 误导了分析,不是模糊猜。告警分了 P1/P2/P3 三级。Grafana 六面板大盘,每块有明确受众和异常排查路径。"
Q6:Agent 输出质量怎么评估?
"建了双轨评估体系。离线层做了 Golden Dataset------10 个竞品手写标准报告,覆盖 easy/medium/hard 三个难度。每次发版跑 RAGAS 查检索质量 + 独立 Judge LLM 对比输出和 Golden,综合分 ≥ 0.85 才放行。有阻断性错误(数字差数量级、严重幻觉)直接卡住。线上用质检 Agent 持续打分,评分波动配了告警。黄金数据集让 Prompt 改动有据可依------不是'感觉更好',是'数据更好'。"
九、关键设计原则
- 一体化优于多组件:PostgreSQL + pgvector 同时承担 Checkpoint、向量存储、全文检索、日志------组件数不超过团队人数
- 降级优于崩溃:某维度分析失败 ≠ 整体任务失败,标记 信息不足 后继续
- 事务保证状态一致性:Checkpoint 标记完成必须与实际数据写入在同一事务
- 基线驱动告警:不拍脑袋设阈值,跑样本算基线
- 评估双轨制:RAGAS 评估输入质量,Judge 评估输出质量,两者互补
- Prompt 版本可管理:不是存一个文件,有回滚、验证、发版规则
- Trace 可回溯:每个 Badcase 必须回答根因是什么、修复方案、验证方法