文章上半部分:计算机视觉-Backbone超详细整理(上)-卷积时代
二 Transformer时代
深度学习中虽然网络模型众多,如FasterRCNN、LSTM等,现在也是每天都会有新的网络模型提出,但是所有深度学习模型整体可以归为4种架构:
1)前馈神经网络:FNN,也叫多层感知机(MLP),因为前馈神经网络就是由多个感知机堆叠形成的,可以解决感知机无法解决的异或问题,前馈神经网络的数学基础是通用近似定理"一个具有足够多神经元的前馈神经网络可以近似任意一个连续函数"
2)卷积神经网络:CNN,前面介绍的卷积神经网络结构
3)循环神经网络:RNN,循环神经网络如果深入介绍会涉及动力系统近似、图灵计算理论等,简单来说,RNN就是一个带有历史输入信息的FNN,普通FNN中,当前层的输入就是上一层的输出,但是RNN当前层的输入除了上一层输出外,还有一个历史信息输入"h",一般称h为隐状态,它是对所有历史输入的一种信息总结
4)Transformer:可以毫不夸张的说,近几年你能关注到的科技热点,如语言大模型、多模态、具身智能等,背后都有Transformer的影子。那么Transformer究竟是什么呢?Transformer其实就是一个带有多头注意力机制的FNN,Transformer强大的特征表达能力来自多头注意力机制
注意力机制计算过程如下:
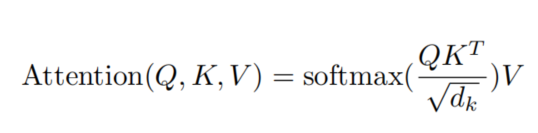
称Q为查询、K-V为索引-值对,Q、K、V的每行称作嵌入向量,是对外界对象的一种向量表示,一般维度是相同的dk,列的维度不一定,代表的是序列长度。注意力机制先计算Q和K的内积,得到注意力权重矩阵,注意力权重矩阵通过内积计算记录了查询Q和索引K的相关性,除以dk是为了防止方差过大信息发散,softmax()操作将注意力权重矩阵转换为注意力得分矩阵A,注意力得分矩阵A每一行的和为1,用A乘以V得到最终注意力计算结果。简单理解注意力机制就是一种"加权融合",能从输入信息中筛选出重要的信息进行接下来的处理,在不同领域,可以从不同视角来理解这种"加权融合"机制:
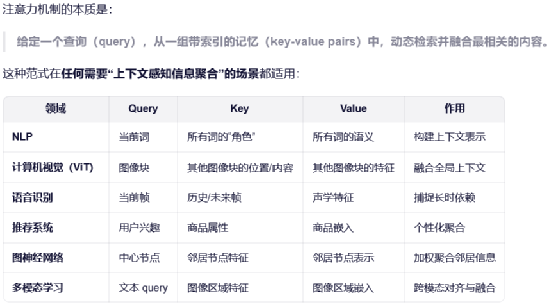
多头注意力机制就是做多次注意力计算,计算的次数称为"头",只不过每次计算注意力机制时,输入的Q、K、V不同,计算公式如下:
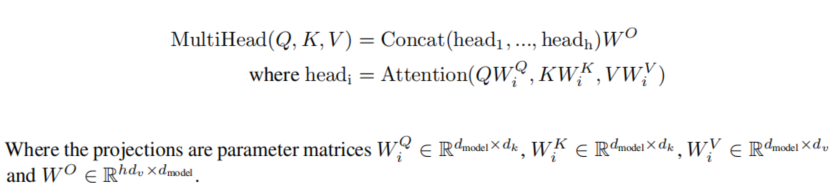
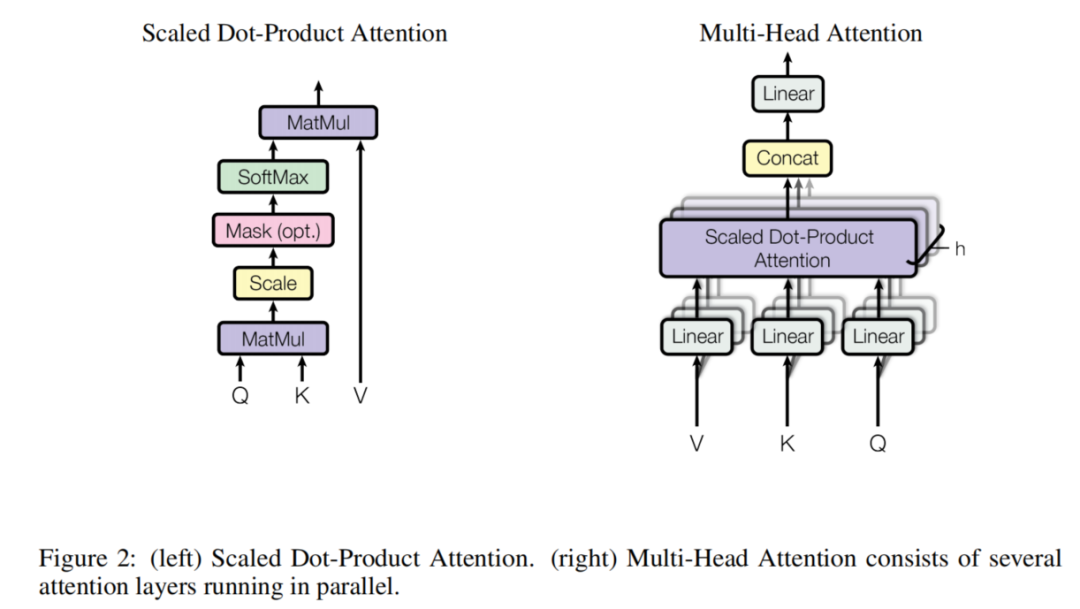
先利用投影矩阵将Q、K、V投影到h个不同的空间中,h就是多头注意力的头数,然后在每个空间中进行注意力机制计算,最后将h个不同空间的注意力结果进行拼接,得到最终多头注意力的计算结果,普通注意力机制和多头注意力机制计算对比如下图:
Transformer整体结构如下:
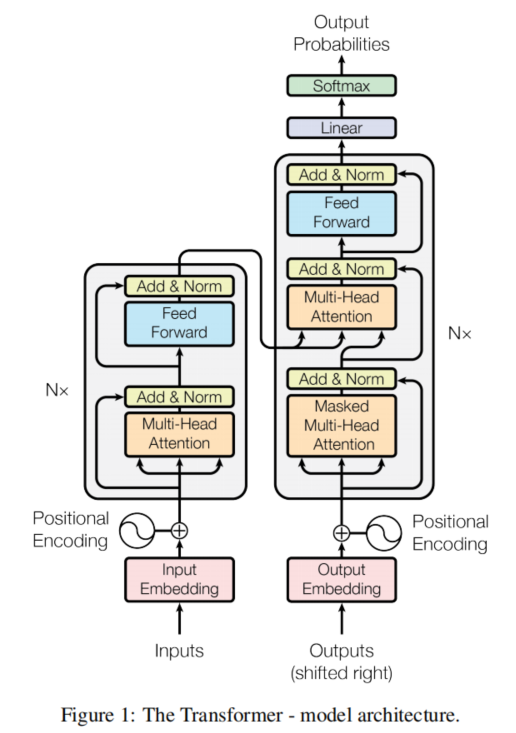
从中间一分为二,称左侧部分为编码器(Encoder),负责对输入进行特征提取,Bert类模型就是只使用Encoder这一部分。右侧部分为解码器(Decoder),负责根据输入,生成出我们想要的输出,GPT系列,我们现在使用的大模型就是只使用Decoder这一部分,这篇文章关注计算机视觉Backbone,Transformer的详细介绍就不展开了,可以看:深度学习基础-5 注意力机制和Transformer
2.1 奠基者:辉煌的2021年
2021年出现了大量计算机视觉Transformer工作,颠覆了以往卷积神经网络统治的计算机视觉时代,从ViT正式将Transformer融入计算机视觉处理,到Swin Transformer在多项计算机视觉任务上的刷榜,再到MAE、DINO语义级别的特征提取效果,都预示着Transformer在计算机视觉领域具有无限潜力,也为语言模型、视觉模型统一架构,多模态模型的发展拉开了帷幕。
ViT-Transformer正式进入CV领域
2021-《AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》
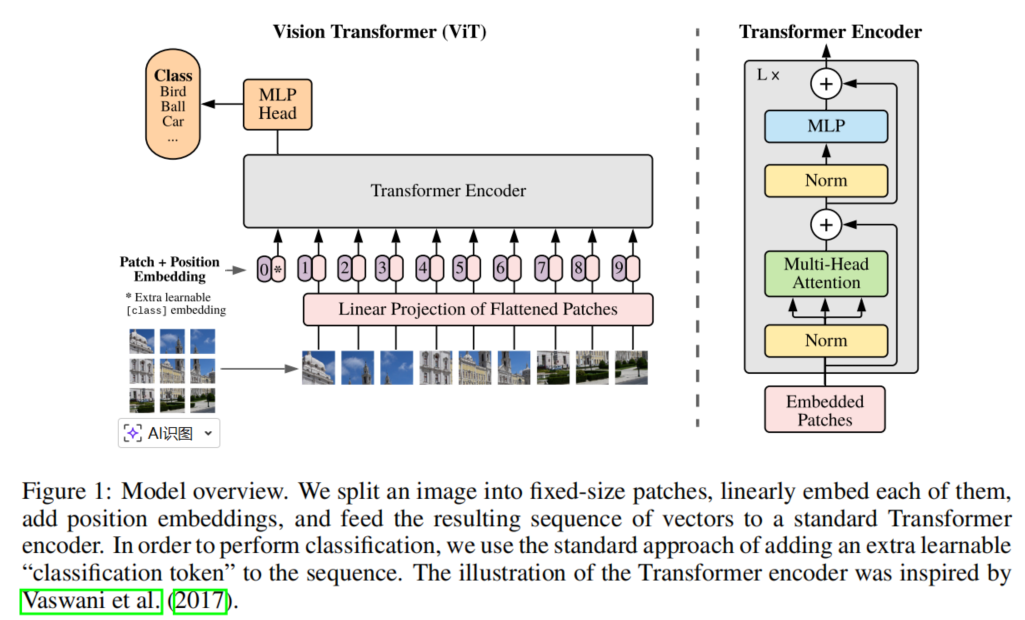
Transformer最初是为了解决自然语言处理领域中的问题而提出的,当时自然语言处理中最常使用的是RNN结构,Transformer重新审视了RNN结构存在的问题,提出了一种完全基于注意力机制的新架构替代RNN。Transformer的输入是一句话,如"今天天气真好啊",先利用分词器对这句话分词,获取这句话对应的词表ID序列,然后对词表ID序列进行词嵌入,生成词嵌入矩阵,词嵌入矩阵的维度是N,d-model,其中N是输入序列的长度,可以简单理解为是一句话中包含多少个词语(实际上是小于一句话词语个数的,因为分词器未必一定会一个词一分割,准确说是token数量的个数,但是这么理解没有影响),d-model是词嵌入向量的维度。
自然语言处理中的一句话可以像上述过程进行处理变换,输入到Transformer中进行处理,那么计算机视觉中的图像呢?如何将图像输入到Transformer中进行处理?
ViT提出的解决方案是:既然Transformer处理的是一个序列,那么我们就要想办法将图像进行序列化,ViT的序列化方式很简单,将图像切割为不同的块(论文中叫Patch),块的大小是16*16,将一幅图像类比为一句话,这些分割出来的块就是这句话中的词语,然后就可以利用Transformer对图像进行处理了。很自然的一个问题(这个问题想清楚才能理解ViT它的成功之处在哪里),我们不从输入的序列性角度看,而是从形式上看,自然语言处理输入的是N,d-model维度的词嵌入矩阵,一幅图像是一个c,H,W维度的矩阵,其中c是图像的通道数,H和W是图像的高度、宽度。既然输入都是一个矩阵,我直接将c,H,W变形为N,d-model形式的矩阵不就可以了,还至于分块吗?




ViT将图像分割为多个16*16大小的子图,将这些子图展平为一维的向量,输入到嵌入层,模仿自然语言处理中词嵌入的过程。举例来说,假设输入的图像大小是3,160,160,那就会分割为10个3,16,16的子图,将这些子图展平为一维向量,则变为10,3\*16\*16大小的矩阵,这个矩阵再输入到嵌入层进行嵌入表示,得到10,96大小的图像块嵌入矩阵,其中96是图像嵌入表示向量的维度。因为最后要进行图像分类任务,ViT模仿Bert的做法,在10,96的图像嵌入矩阵上添加了一个1,96的行向量,这个行向量符号标记是cls,这个cls向量通过Transformer的注意力机制会融合其它图像块的特征信息,也就是可以将cls看做以往卷积神经网络中提取到的特征图,最终ViT是利用这个cls向量,将其输入到一个前馈神经网络中进行图像分类的。
因为Transformer对位置信息不敏感,需要添加位置编码信息到图像嵌入矩阵中,ViT的做法是直接学习一个10,96大小的位置编码矩阵加到图像块嵌入矩阵上,这个位置编码矩阵随着Transformer的训练会逐渐学会应该给每个图像块添加什么位置编码信息,并且ViT通过实验发现这个位置编码矩阵很关键,如果不给图像块嵌入矩阵添加位置编码信息,最终模型性能会大打折扣。接下来ViT就是利用Transformer的Encoder结构对图像块进行特征提取,整体过程和以往的Encoder没有太大区别,ViT的详细介绍可以看:计算机视觉Transformer-1 基础结构
CLIP-多模态预训练的开端
2021-《Learning Transferable Visual Models From Natural Language Supervision》
我们希望有这样一种模型,它经过训练后,对于未在训练集中出现的类别也能做出准确的判断,学术上称这种能力为"Zero-Shot",CLIP就是这种模型。
传统判别式模型是从特征映射的角度处理识别问题,也就是"特征->识别结果",而CLIP是从语义相似性的角度来处理识别问题,也就是"(特征,识别结果)->最相似的是正确结果"。举例来说,输入一张"猫"的图片,传统判别式模型会对图片进行特征提取,根据提取到的特征进行判断,说"我认为这张图片90%是猫",而CLIP会分别对图片、所有类别"猫"、"狗"......,都进行特征提取,然后判断每个<图片特征,类别特征>相似度是多少,选相似度最大的作为当前图片的类别。CLIP的Zero-Shot能力就体现在如果'所有类别'哪天突然变了,传统判别式模型需要重新构建数据集->进行训练,但是CLIP只需要对新类别进行一次特征提取就可以,然后还是通过相似度比对就可以进行判断识别,CLIP整体结构如下:
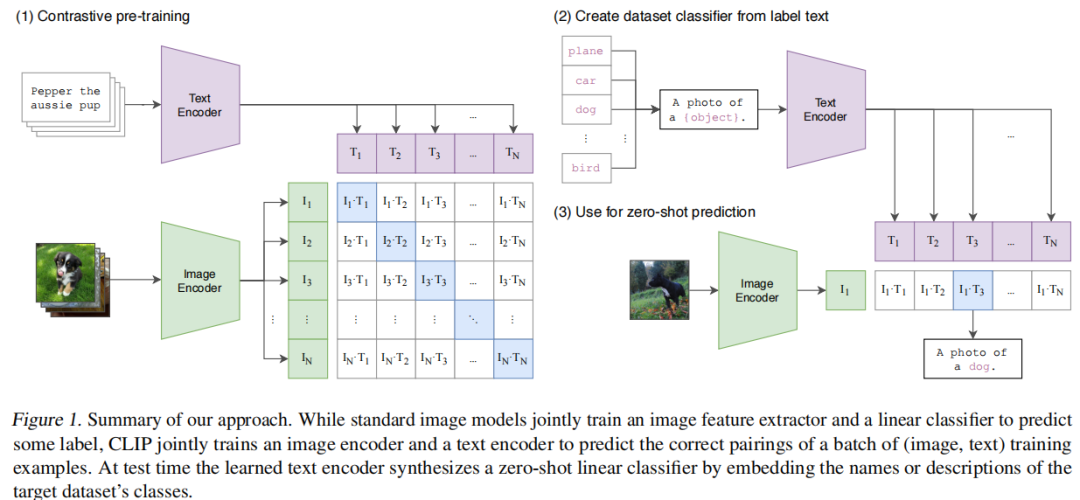
左侧是CLIP的训练过程,CLIP包含两个关键组件Image Encoder(图像编码器)、Text Encoder(文本编码器),最后的目标就是通过数据集训练这两个编码器,让它们提取到的特征具有语义相似性,也就是图像编码器对'猫图片'的特征编码输出和文本编码器对文本"猫"的特征编码输出具有最大的相似性。右侧是CLIP的推理过程,输入一张待识别的图片,利用训练完毕的图像编码器对其进行特征提取,利用文本编码器对所有类别标签文本进行特征提取,然后判断图像特征编码和类别标签文本特征编码的相似性,具有最大相似性结果的就是图像对应的类别。详细介绍可以看:多模态-2 CLIP
Swin Transformer-密集预测任务巅峰
2021-《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》
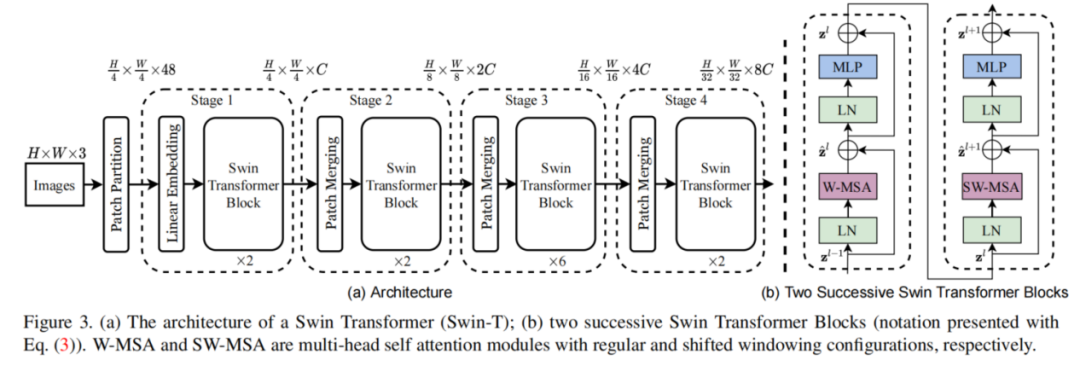
ViT能够利用Transformer解决图像分类这种高层次语义相关的计算机视觉任务,但是对于目标检测、图像分割这种密集预测任务效果较差,Swin Transformer借鉴卷积神经网络多尺度特征融合的思想,融合Transformer不同层级输出的特征进行密集任务处理,达到了当时各个计算机视觉任务的SOTA。Swin Transformer交替使用"窗口注意力层+移动窗口注意力层"对输入图像进行特征提取,窗口注意力模仿卷积操作,关注输入的局部细节特征,移动窗口注意力本身也是窗口注意力计算,但是在计算之前会移动窗口内token的相对位置,使不同窗口之间的信息可以进行交互融合,增强密集特征提取能力,这也体现了池化操作的思想,Swin Transformer详细介绍可以看:计算机视觉Transformer-1 基础结构
自监督的崛起
监督学习为每个数据x人工标记标签y,这些(x,y)作为训练数据集训练深度学习模型,y作为一种监督信号引导深度学习模型学习数据集中包含的规律f(x)=y,然后可以利用这个学习得到的f(x),对一个不在训练数据集中的新数据x'也能做出较为准确的预测y',监督学习这种方式致命的弱点就是依赖人工标注,模型的准确性依赖训练数据的规模和质量,数据越多才能越准,标记成本较高。
无监督学习不需要人工对数据x进行标记,而是让模型自己去学习数据具有的分布规律p(x),自监督是无监督学习方法中的一种,自监督会预先定义一个自监督学习任务,根据这个任务可以生成模型要学习的目标,也就是产生监督信号,一般称这个监督信号为伪标签(pseudo label),和真实人工标记标签进行区分。举个例子,在自然语言处理中,为了让语言模型学会语言的结构、语义等特征,可以在一句话中随机删除掉一些词语,然后将预测删除掉的词语作为一种自监督训练任务来训练模型,如"我今天早上吃的油条"变为"我今天早mask1吃的油mask2",模型要做的事就是正确预测出mask1='上'、mask2='条',随着模型预测越来越准,反面也说明了模型学会了语言结构、语义等信息,自监督学习过程相当于是一个自己出题,自己答的过程,常用的自监督任务如下:
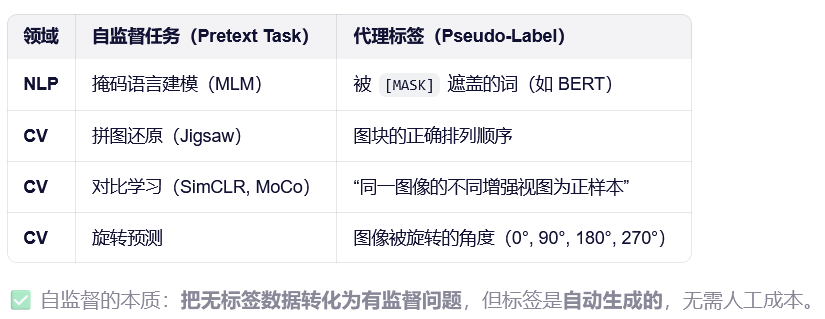
自监督预训练方法在自然语言处理领域取得了成功,计算机视觉借鉴这种方法提出了一系列基于自监督的Backbone模型。
MAE
2021-《Masked Autoencoders Are Scalable Vision Learners》
类似自然语言处理中"mask掉词语->预测被mask的词语",MAE将图像进行mask,然后让网络预测、还原出这些被mask掉的部分。
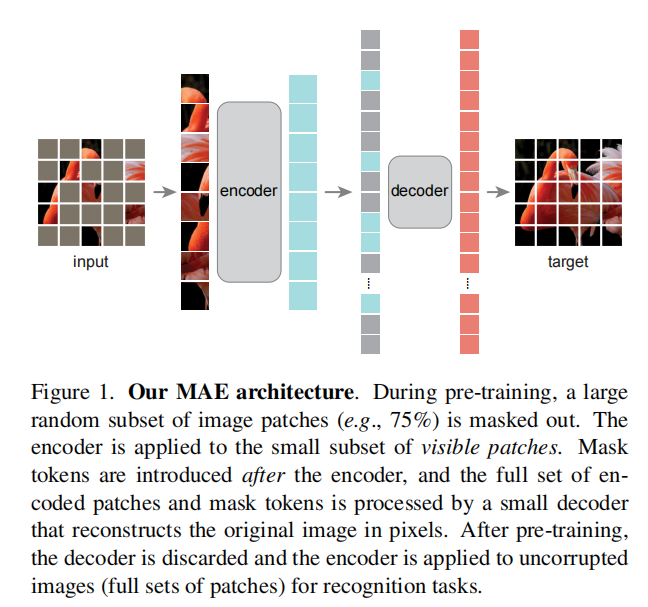
MAE整体结构采用的是ViT,作者尝试了以下几种mask方法:

1)Random:随机移除patch
2)Block:移除某个区域范围内的所有patch
3)Grid:按照网格的方式移除patch
实验表明随机移除的方式更好,所以MAE采取的是随机移除patch的mask策略,将未被移除的patch输入到Encoder中进行特征编码,然后让网络预测被mask的部分。Mask的目的是为了让模型能够学习到图像中具有的高层次语义特征,如果mask比例过小,模型会从邻近patch纹理、边缘的角度恢复被mask的区域,而不是从高层次的语义特征角度去恢复mask区域,也就是mask比例过低会导致模型"偷懒",但是如果mask比例过高,大部分的patch都mask掉,模型又会学习不到高层次的语义特征,因为你给的信息实在有限,作者通过实验发现Mask比例为75%时效果最好。
MAE整体流程如下:
1)输入图像分为固定大小的多个patch,随机mask,也就是按照一定比例移除掉一部分patch
2)将剩余的patch结合位置编码送到encoder中编码高层语义特征,位置编码也是ViT的1D可学习编码向量方式
3)为被mask掉的patch生成一个可学习的编码向量,和encoder的输出按照原来各个patch的位置排列,添加完1D位置编码后输入到decoder中进行整体图像解码
4)decoder解码出整个图像,求每个被mask部分的解码输出和真实图像像素值的均方误差,反向传播训练整个MAE网络
注意decoder中没有以往Transformer中的cross attention,只是根据encoder+mask编码向量解码出原图像,求损失时只求被mask掉patch位置和原图像的损失,使训练更加稳定,详细介绍可以看:计算机视觉Transformer-3 自监督模型
DINO
2021-《Emerging Properties in Self-Supervised Vision Transformers》
MAE通过复原图像mask掉的patch块方式,让Transforer从输入图像中提取高层次的语义特征,这相当于是一种细粒度的语义学习,因为它强迫模型学习不同patch之间的语义差异。DINO利用自蒸馏的方法让模型学习图像的全局语义信息表示,不对图像进行mask操作,最终模型会通过Transformer的注意力机制学习到图像中"关键物体"这种全局的信息表示,如下图:

DINO整体基于自蒸馏策略,自监督训练任务是让学生网络输出和教师网络输出之间的差距尽可能的小,整体过程如下:
1)初始化两个一模一样的网络,一个作为学生网络,一个作为教师网络,DINO用的是ViT结构的Transformer
2)对于输入的图像,使用大尺寸的裁剪作为图像的"全局视图"、小尺寸的裁剪作为"局部视图",分别对全局视图、局部视图进行数据增强、分割patch、添加位置编码,输入到学生网络、教师网络中,注意,学生网络输入所有视图,但是教师网络只输入全局视图
3)对学生网络cls、教师网络的cls利用FFN(前馈神经网络)再进行变换,教师网络cls向量变换的过程中会注入防坍塌机制
4)计算蒸馏损失,学生网络根据蒸馏损失进行梯度下降更新
5)教师网络进行指数移动平均更新

训练流程示意如下
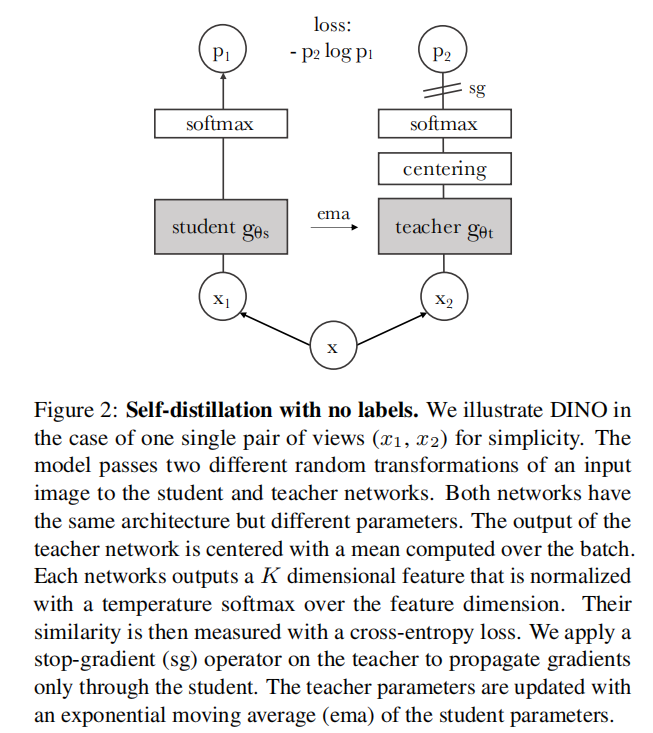
详细介绍可以看:计算机视觉Transformer-3 自监督模型
2.2 规模化与通用化(2022~至今)
凭借Transformer架构本身具有的高可拓展性,目前基于Transformer的Backbone一般会在超大规模数据集+超大规模算力集群上,拓展Transformer架构Backbone的上限,这是Transformer架构的Scaling Law。
2023 SigLIP
《Sigmoid Loss for Language Image Pre-Training》
以往的对比学习模型,如CLIP、ALION,使用基于softmax的对比损失(InfoNCE)进行模型训练,该损失需要计算batch内所有图像-文本对的相似度矩阵,并在图像维度和文本维度分别进行全局归一化,这会导致:
1)数值稳定性差:softmax需先减去最大值再归一化,需要两次全 batch扫描
2)内存开销大:全batch相似度矩阵大小与batch size平方成正比,限制了大batch size的训练
3)模型强依赖于大batch size:softmax对比损失需要足够多的负样本才能学到有效特征表示,小batch size条件下性能明显下降
SigLIP用Sigmoid逐对损失,替代以往的softmax全batch对比损失,无需全局归一化,降低了内存占用,支持更大的batch size训练,并且在小batch size下也表现良好,解决了对比学习对于大batch size的依赖。
以往基于SoftMax的对比学习损失函数如下:

SigLIP提出的对比损失如下:


不用计算整体batch size的对比损失,而是每两个图像编码、文本编码可直接进行计算,当图像编码和文本编码匹配时z=1,否则z=-1,t和b是可学习的参数,损失函数计算伪代码如下:

2025 SigLIP 2
《SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features》
SigLIP 2对过往Transformer架构Backbone方法的缺点加以改进,并进行了不同方法的融合。
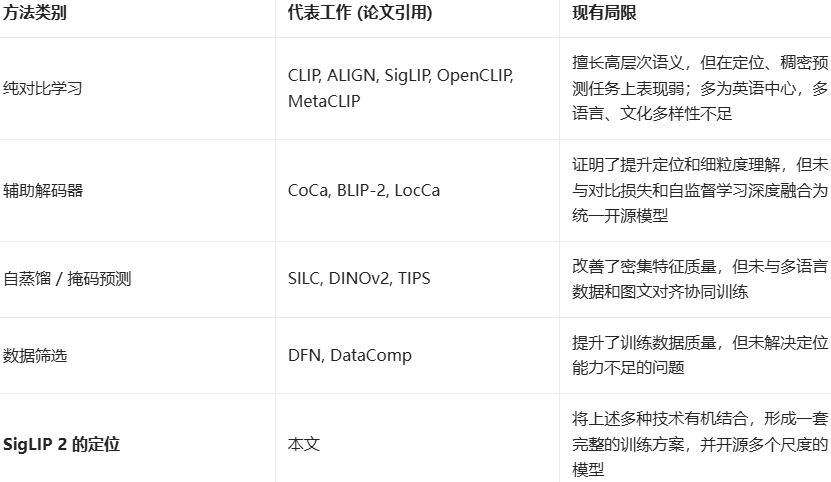
将Sigoid对比损失(SigLIP)、基于解码器的定位预训练(LocCa)、自蒸馏+掩码预测(SILC/TIPS)以及动态数据精选(ACID)整合到了一个统一的训练流程中,SigLIP 2整体训练流程和损失函数如下:
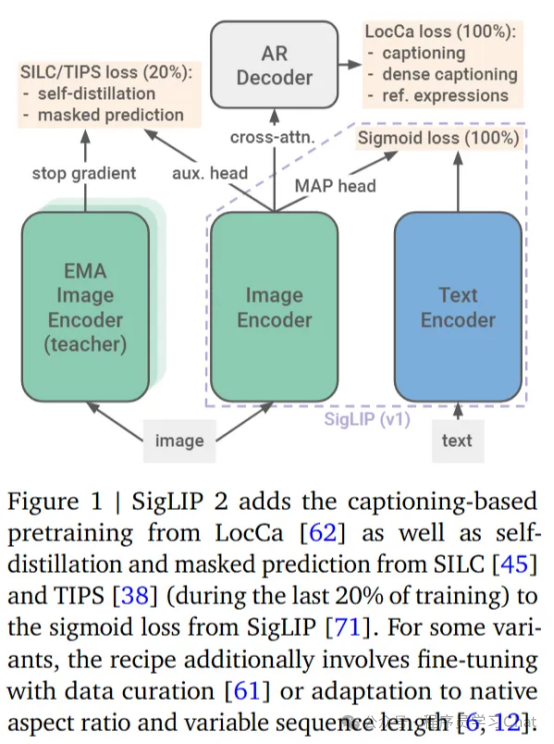

具体训练流程如下:

2024 DINO V2
《DINOv2: Learning Robust Visual Features without Supervision》DINO V2结合DINO全局建模和MAE细粒度语义提取的思想,在一个超大规模数据集上进行了训练,大幅提高了模型的语义特征提取能力。

数据集构建过程中,借助向量数据库,通过图像的嵌入向量进行数据清洗,构建高质量数据集:




DINO V2通过多任务学习,将DINO、MAE融和到了一起:

DINO损失


iBOT损失(类似于MAE的一种变体)


2025 DINO V3
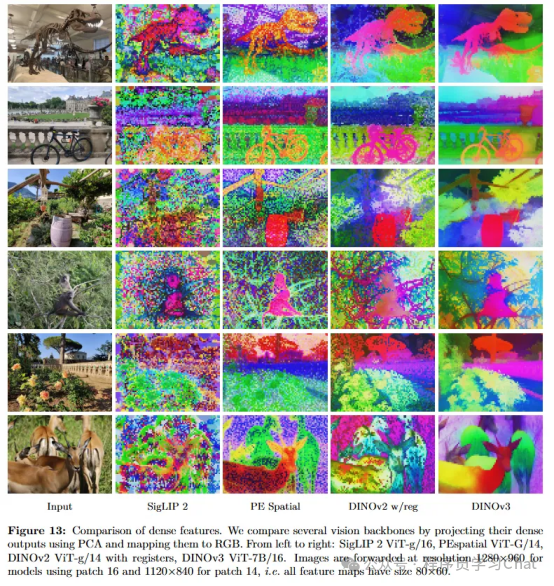
DINOV3对密集预测任务的特征提取能力做出了改进,以往的Transformer架构自监督模型(如DINOv2)在长时间、大规模数据训练后,虽然全局语义分类性能提升,但密集特征图提取能力会显著退化,表现为特征间的相似性图变得嘈杂、模糊,失去了局部定位能力,模型的全局语义表征能力与局部密集表征能力存在矛盾,模型训练早期密集特征提取效果好,但后期全局语义特征提取能力提升时,密集特征提取能力反而会下降,不同Backbone的特征提取效果对比如下:
DINO V3的训练整体分为大规模预训练和密集特征精调训练,预训练损失函数如下:

在模型经过预训练阶段学习到通用全局语义特征后,再添加Gram损失,进行密集特征精调训练,避免模型密集特征提取能力丢失:

2.4 Transformer时代Backbone小结
自2017年自然语言处理领域Transformer的提出,Transformer架构的自然语言处理模型在多个任务上达到了SOTA的效果,非常自然的想法就是能否将Transformer架构融入到计算机视觉领域,图像是一个全局整体对象,而Transformer的输入是序列化的局部对象,ViT利用图像分割Patch方法解决了这个问题,并且这种分割方式也一直延续至今。CLIP探讨了图文对比学习的可能,打开了Zero-shot、多模态方向的大门。Swin Transformer借鉴以往卷积神经网络中多尺度特征融合、卷积运算的局部性、池化的思想,赋予Transformer架构Backbone密集预测任务特征提取能力,在当时多项计算机视觉任务上刷榜。自然语言处理中大规模预训练范式的自监督思想启发了MAE和DINO,让计算机视觉脱离了以往过度依赖人工标注的工作模式。随着大语言模型的兴起,大规模数据+大规模算力集群能拓展Transformer能力上限的Scaling Law成为了人们的共识,这种共识体现在Transformer架构的Backbone上,诞生了SigLIP、TIPS、DINO V2/3这些模型,这些模型更具通用性和泛化性,能够在一次大规模预训练之后,迁移到不同的任务中。