本文基于 Docker 环境下的 Elasticsearch 8.12 + Logstash 8.12 + MySQL 8.0 技术栈,详细介绍 ES 的核心功能、数据同步原理及最佳实践。
目录
- [Elasticsearch 简介与优势](#Elasticsearch 简介与优势)
- 适用场景分析
- 快速部署
- 核心概念解读
- 索引管理
- 文档操作
- 全文搜索
- 中文分词器配置
- 聚合分析
- 数据同步原理与实践
- 总结
- 演示系统使用指南
1. Elasticsearch 简介与优势
1.1 什么是 Elasticsearch
Elasticsearch 是一个基于 Lucene 构建的分布式、RESTful 风格的搜索和数据分析引擎。它能够近乎实时地存储、搜索和分析大量数据。
1.2 核心优势
| 优势 | 说明 |
|---|---|
| 实时性 | 数据写入后可在秒级甚至毫秒级被检索到 |
| 分布式架构 | 支持横向扩展,可处理 PB 级数据 |
| 全文检索 | 内置强大的全文搜索引擎,支持复杂查询 |
| 高可用 | 支持副本机制,数据冗余容错 |
| RESTful API | 提供完整的 HTTP API,便于集成 |
| 聚合分析 | 支持复杂的 bucket 和 metric 聚合 |
| 多租户 | 支持在同一集群上运行多个索引 |
1.3 与关系型数据库对比
| 维度 | MySQL | Elasticsearch |
|---|---|---|
| 数据模型 | 行存储 | 文档存储 (JSON) |
| 查询类型 | SQL | Query DSL |
| 事务支持 | ACID | 最终一致性 |
| 写入性能 | 较快 | 极快 |
| 复杂查询 | 一般 | 强大 |
| 聚合分析 | 支持但较慢 | 强大且高效 |
| 数据量级 | 亿级 | PB 级 |
2. 适用场景分析
2.1 适合使用 ES 的场景
- 全文搜索:电商商品搜索、站内搜索、日志搜索
- 日志分析:ELK 技术栈的核心组件
- 应用性能监控 (APM):分布式追踪和性能分析
- 安全分析:安全日志分析和威胁检测
- 业务分析:用户行为分析、BI 报表
- 地理空间查询:LBS 应用、地图相关服务
2.2 不适合使用 ES 的场景
- 事务性要求高的场景:金融交易、库存扣减
- 频繁更新的小事务:ES 适合批量写入
- 简单 KV 查询:直接用 Redis 更合适
- 数据结构频繁变化的场景
3. 快速部署
3.1 Docker Compose 配置
yaml
version: '3.8'
services:
elasticsearch:
image: elasticsearch:8.12.0
container_name: elasticsearch
environment:
- discovery.type=single-node
- xpack.security.enabled=false
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ports:
- "9200:9200"
- "9300:9300"
volumes:
- es-data:/usr/share/elasticsearch/data
networks:
- es-net
kibana:
image: kibana:8.12.0
container_name: kibana
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
ports:
- "5601:5601"
networks:
- es-net
logstash:
image: logstash:8.12.0
container_name: logstash
volumes:
- ./logstash/pipeline:/usr/share/logstash/pipeline
- ./logstash/jdbc-driver:/usr/share/logstash/jdbc-driver
ports:
- "9600:9600"
networks:
- es-net
mysql:
image: mysql:8.0
container_name: mysql
environment:
- MYSQL_ROOT_PASSWORD=123123
- MYSQL_DATABASE=elasticsearch_demo
ports:
- "3306:3306"
networks:
- es-net
networks:
es-net:
driver: bridge
volumes:
es-data:3.2 启动服务
bash
docker-compose up -d
# 验证 ES 启动
curl http://localhost:9200
# 验证 Logstash API
curl http://localhost:96004. 核心概念解读
4.1 术语对照
| Elasticsearch | 关系型数据库 | 说明 |
|---|---|---|
| Index (索引) | Database (数据库) | 逻辑数据容器 |
| Document (文档) | Row (行) | 可被索引的基本单位 |
| Field (字段) | Column (列) | 文档中的属性 |
| Mapping (映射) | Schema (表结构) | 字段类型定义 |
| Shard (分片) | - | 数据分片 |
| Replica (副本) | - | 数据副本 |
4.2 数据类型
json
{
"mappings": {
"properties": {
"customer_id": { "type": "keyword" },
"customer_name": {
"type": "text",
"analyzer": "ik_max_word"
},
"city": { "type": "keyword" },
"contact_person": {
"type": "text",
"fields": {
"keyword": { "type": "keyword" }
}
},
"customer_num": { "type": "integer" },
"created_at": { "type": "date" }
}
}
}字段类型选择建议:
keyword:精确匹配、分桶聚合、排序text:全文搜索,会被分词integer/long:数值范围查询、聚合date:日期范围查询、 histogramgeo_point:地理位置
5. 索引管理
5.1 创建索引
bash
curl -X PUT "http://localhost:9200/customers" -H 'Content-Type: application/json' -d'
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"analysis": {
"analyzer": {
"ik_analyzer": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["standard"]
}
}
}
},
"mappings": {
"properties": {
"customer_id": { "type": "keyword" },
"customer_name": {
"type": "text",
"analyzer": "ik_max_word"
},
"address": { "type": "text" },
"city": { "type": "keyword" },
"credit_code": { "type": "keyword" },
"contact_person": { "type": "text" },
"contact_phone": { "type": "keyword" },
"customer_num": { "type": "integer" },
"registration_date": { "type": "date" },
"created_at": { "type": "date" }
}
}
}'5.2 索引操作
bash
# 查看所有索引
curl "http://localhost:9200/_cat/indices?v"
# 查看索引信息
curl "http://localhost:9200/customers"
# 删除索引
curl -X DELETE "http://localhost:9200/customers"
# 检查索引是否存在
curl -I "http://localhost:9200/customers"6. 文档操作
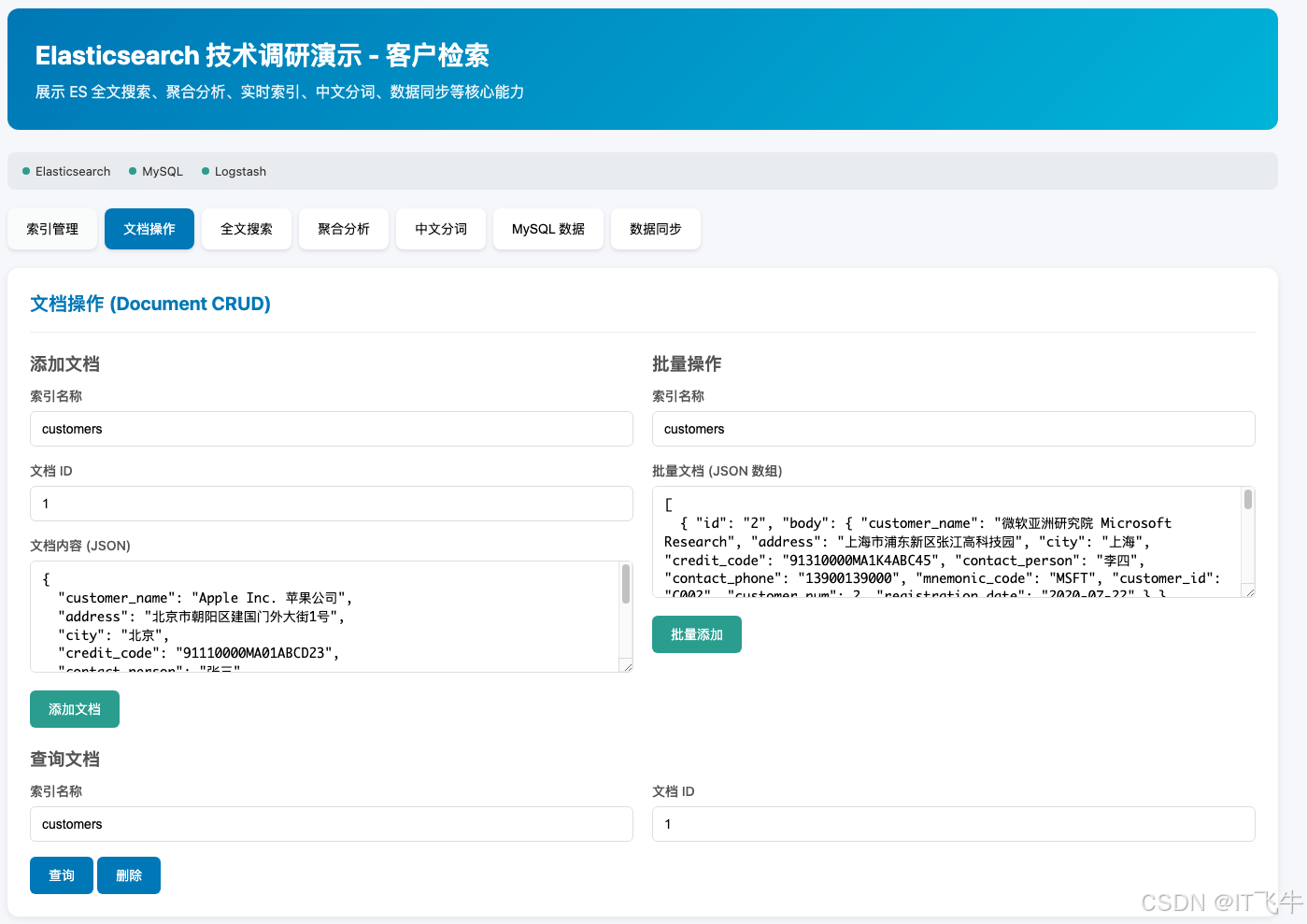
6.1 新增文档
bash
curl -X POST "http://localhost:9200/customers/_doc/C001" -H 'Content-Type: application/json' -d'
{
"customer_id": "C001",
"customer_name": "Apple Inc.",
"city": "北京",
"contact_person": "张三",
"customer_num": 1
}'6.2 批量写入
bash
curl -X POST "http://localhost:9200/customers/_bulk" -H 'Content-Type: application/json' -d'
{"index":{"_id":"C002"}}
{"customer_id":"C002","customer_name":"Microsoft","city":"上海","customer_num":2}
{"index":{"_id":"C003"}}
{"customer_id":"C003","customer_name":"Huawei","city":"深圳","customer_num":3}
'6.3 查询文档
bash
# 根据 ID 查询
curl "http://localhost:9200/customers/_doc/C001"
# 搜索全部
curl "http://localhost:9200/customers/_search"6.4 更新文档
bash
# 全量更新
curl -X PUT "http://localhost:9200/customers/_doc/C001" -H 'Content-Type: application/json' -d'
{
"customer_id": "C001",
"customer_name": "Apple Inc. Updated"
}'
# 增量更新 (update API)
curl -X POST "http://localhost:9200/customers/_update/C001" -H 'Content-Type: application/json' -d'
{
"doc": {
"customer_name": "Apple Inc. Updated"
}
}'6.5 删除文档
bash
curl -X DELETE "http://localhost:9200/customers/_doc/C001"7. 全文搜索
7.1 基础查询
bash
# match 查询 - 分词后匹配
curl -X POST "http://localhost:9200/customers/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"customer_name": "华为技术"
}
}
}'
# match_phrase 查询 - 短语匹配
curl -X POST "http://localhost:9200/customers/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match_phrase": {
"customer_name": "华为技术有限公司"
}
}
}'
# multi_match 查询 - 多字段匹配
curl -X POST "http://localhost:9200/customers/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"multi_match": {
"query": "华为",
"fields": ["customer_name", "address"]
}
}
}'7.2 布尔查询
bash
curl -X POST "http://localhost:9200/customers/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{ "match": { "customer_name": "科技" } }
],
"filter": [
{ "term": { "city": "深圳" } }
]
}
}
}'7.3 模糊查询
bash
# fuzzy 查询 - 纠错搜索
curl -X POST "http://localhost:9200/customers/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"fuzzy": {
"customer_name": {
"value": "华为技",
"fuzziness": "AUTO"
}
}
}
}'7.4 高亮显示
bash
curl -X POST "http://localhost:9200/customers/_search" -H 'Content-Type: application/json' -d'
{
"query": {
"match": { "customer_name": "科技" }
},
"highlight": {
"fields": {
"customer_name": {}
},
"pre_tags": ["<em>"],
"post_tags": ["</em>"]
}
}'8. 中文分词器配置
8.1 分词器选择
| 分词器 | 特点 | 适用场景 |
|---|---|---|
| IK | 中文支持好,社区活跃 | 中文全文搜索 |
| HanLP | 多模式,词性标注 | 语义分析 |
| jieba | Python 友好 | 社交媒体分析 |
| THULAC | 清华团队,效率高 | 学术文本 |
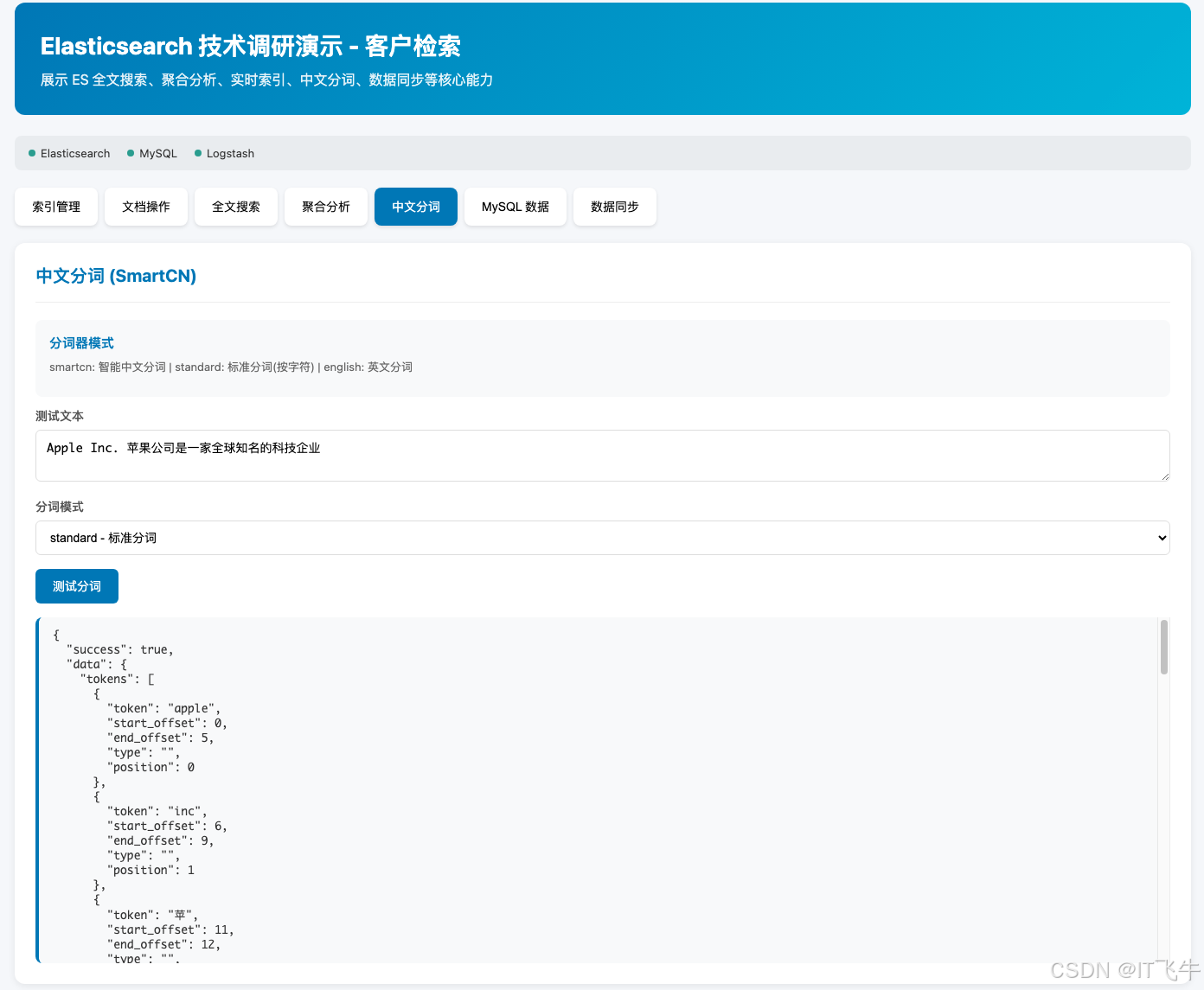
8.2 IK 分词器配置
IK 提供两种分词模式:
- ik_max_word:细粒度分词,覆盖更多词条
- ik_smart:粗粒度分词,更快更准确
json
{
"settings": {
"analysis": {
"analyzer": {
"ik_max": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["standard"]
},
"ik_smart": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": ["standard"]
}
}
}
},
"mappings": {
"properties": {
"customer_name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}8.3 中英文混合策略
json
{
"settings": {
"analysis": {
"analyzer": {
"mixed_analyzer": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["lowercase", "asciifolding"]
}
}
}
},
"mappings": {
"properties": {
"customer_name": {
"type": "text",
"analyzer": "mixed_analyzer",
"fields": {
"keyword": { "type": "keyword" }
}
},
"english_content": {
"type": "text",
"analyzer": "standard"
}
}
}
}策略建议:
- 中文内容:使用 IK 分词器
- 英文内容:使用 standard 或 whitespace 分词器
- 中英文混合:可配置多字段或自定义组合分词器
- 需要排序/聚合的字段:添加
.keyword子字段
9. 聚合分析
9.1 聚合类型
┌─────────────────────────────────────────────────┐
│ Aggregations │
├─────────────────┬───────────────────────────────┤
│ Bucket │ Metric │
│ 桶聚合 │ 指标聚合 │
├─────────────────┼───────────────────────────────┤
│ terms │ avg, sum, min, max │
│ range │ stats, extended_stats │
│ histogram │ percentiles │
│ date_histogram │ cardinality │
└─────────────────┴───────────────────────────────┘9.2 桶聚合示例
bash
# 按城市分组统计
curl -X POST "http://localhost:9200/customers/_search" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"by_city": {
"terms": {
"field": "city",
"size": 10
}
}
}
}'
# 按客户编号区间分组
curl -X POST "http://localhost:9200/customers/_search" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"num_ranges": {
"range": {
"field": "customer_num",
"ranges": [
{ "to": 10 },
{ "from": 10, "to": 20 },
{ "from": 20 }
]
}
}
}
}'9.3 指标聚合示例
bash
# 统计数值字段
curl -X POST "http://localhost:9200/customers/_search" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"stats": {
"stats": { "field": "customer_num" }
},
"avg_num": {
"avg": { "field": "customer_num" }
}
}
}'9.4 嵌套聚合
bash
# 先按城市分桶,再统计每个城市的客户数量
curl -X POST "http://localhost:9200/customers/_search" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"by_city": {
"terms": {
"field": "city",
"size": 20
},
"aggs": {
"count": {
"value_count": { "field": "customer_id" }
},
"avg_num": {
"avg": { "field": "customer_num" }
}
}
}
}
}'10. 数据同步原理与实践
10.1 同步方案对比
| 方案 | 实时性 | 复杂度 | 数据量 | 延迟 |
|---|---|---|---|---|
| Logstash JDBC | 近实时 (5s) | 低 | 中等 | 秒级 |
| Canal | 准实时 | 中 | 大 | 毫秒级 |
| Debezium | 准实时 | 高 | 大 | 毫秒级 |
| 定时全量 | 低 | 低 | 小 | 分钟级 |
本项目采用 Logstash JDBC:配置简单,与 ELK 技术栈无缝集成。
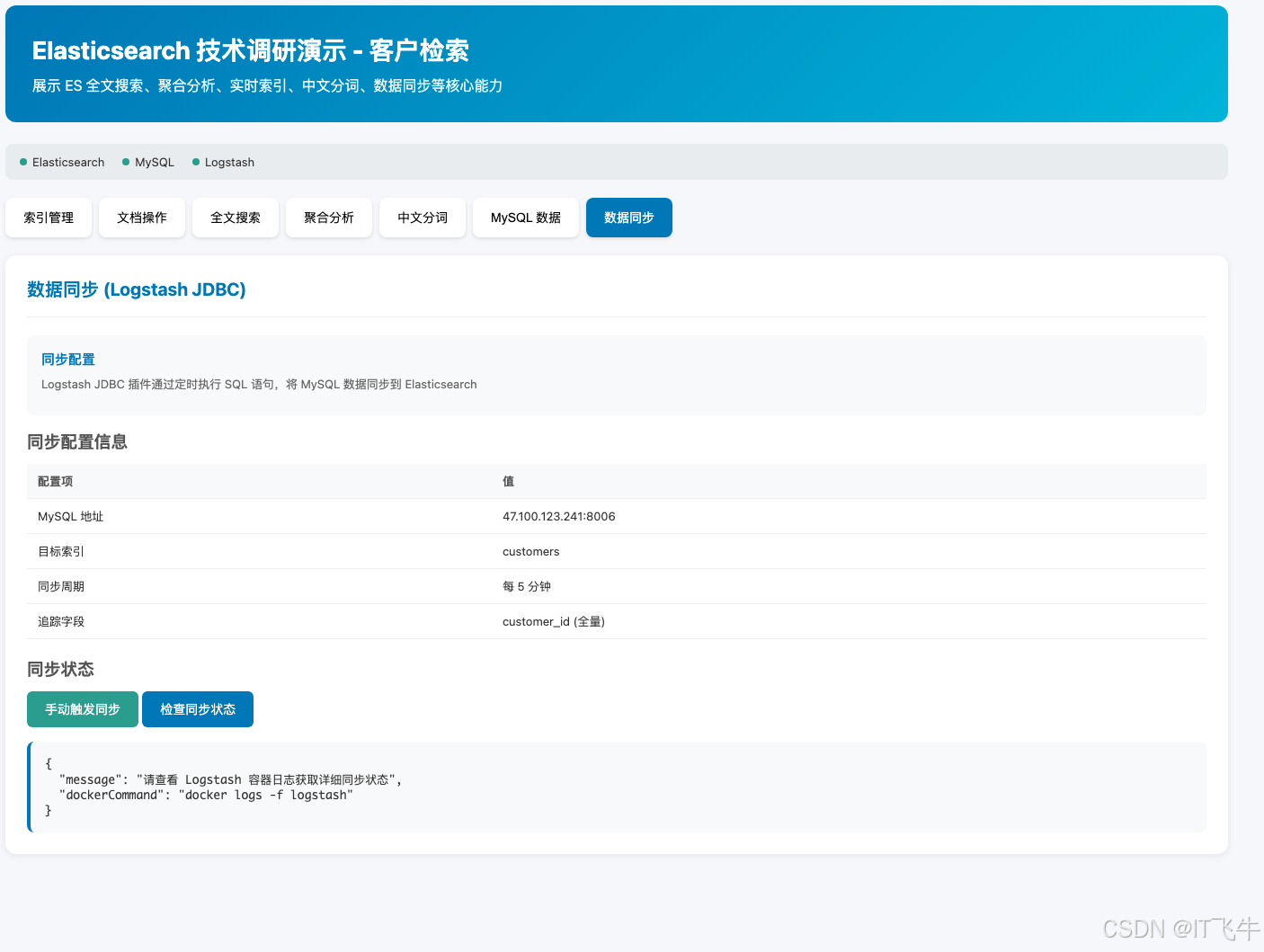
10.2 Logstash JDBC 工作原理
┌─────────────┐ ┌──────────────┐ ┌───────────────┐
│ MySQL │────▶│ Logstash │────▶│ Elasticsearch │
│ 数据源 │ │ JDBC Input │ │ 目标库 │
└─────────────┘ └──────────────┘ └───────────────┘
│
┌──────┴──────┐
│ sql_last_value│ (上次查询时间戳)
│ 记录在本地文件 │
└─────────────┘核心概念:
tracking_column:跟踪的时间戳字段sql_last_value:上次执行的时间戳值last_run_metadata_path:存储上次执行时间的位置
10.3 完整配置示例
conf
# Logstash 配置 - MySQL 到 Elasticsearch 数据同步
input {
jdbc {
# MySQL JDBC 连接信息
jdbc_driver_library => "/usr/share/logstash/jdbc-driver/mysql-connector-java-8.0.33.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://mysql:3306/elasticsearch_demo?useUnicode=true&characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai"
jdbc_user => "root"
jdbc_password => "123123"
# 定时执行 SQL(每 5 秒)
schedule => "*/5 * * * * *"
use_column_value => true
tracking_column => "updated_at"
tracking_column_type => "timestamp"
last_run_metadata_path => "/usr/share/logstash/data/.logstash_jdbc_last_run"
# 增量查询 SQL
statement => "SELECT * FROM customers WHERE updated_at >= :sql_last_value ORDER BY updated_at"
# 配置
record_last_run => true
clean_run => false
# 分页
jdbc_paging_enabled => true
jdbc_page_size => 1000
}
}
filter {
# 清理无用字段
mutate {
remove_field => ["@version", "@timestamp"]
}
# 字符串去空格
mutate {
strip => ["customer_name", "address", "contact_person"]
}
# 标记软删除记录
if [is_deleted] == 1 {
mutate {
add_tag => ["deleted"]
}
}
}
output {
# 软删除 -> 从 ES 删除
if "deleted" in [tags] {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "customers"
document_id => "%{customer_id}"
action => "delete"
manage_template => false
}
} else {
# 正常记录 -> 写入 ES
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "customers"
document_id => "%{customer_id}"
action => "index"
manage_template => false
}
}
}10.4 增删改操作同步
10.4.1 新增 (INSERT)
MySQL 表需要触发器确保 updated_at 在 INSERT 时被设置:
sql
-- 添加 updated_at 字段
ALTER TABLE customers ADD COLUMN updated_at timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP AFTER created_at;
-- INSERT 触发器
CREATE TRIGGER before_insert_customers
BEFORE INSERT ON customers
FOR EACH ROW
SET NEW.updated_at = NEW.created_at;效果 :INSERT 新记录时,updated_at = created_at,Logstash 检测到后同步到 ES。
10.4.2 更新 (UPDATE)
sql
UPDATE customers SET city = '广州', updated_at = NOW() WHERE customer_id = 'C001';效果 :UPDATE 修改记录时,updated_at 自动更新为当前时间,Logstash 检测到后同步到 ES。
10.4.3 删除 (DELETE) - 软删除
sql
UPDATE customers SET is_deleted = 1, updated_at = NOW() WHERE customer_id = 'C001';效果:
updated_at更新,Logstash 能检测到这条记录- Filter 判断
is_deleted == 1,打上deletedtag - Output 判断有
deletedtag,执行action => "delete"从 ES 删除
10.4.4 软删除表结构
sql
-- 添加软删除字段
ALTER TABLE customers ADD COLUMN is_deleted tinyint NOT NULL DEFAULT 0 AFTER updated_at;10.5 同步延迟配置
| 配置 | 说明 | 建议值 |
|---|---|---|
schedule |
执行周期 cron 表达式 | 5s ~ 1min |
jdbc_page_size |
分页大小 | 1000 ~ 5000 |
jdbc_paging_enabled |
是否分页 | true |
延迟调优:
- 实时性要求高:
*/5 * * * * *(5秒) - 一般场景:
*/30 * * * * *(30秒) - 低频同步:
0 * * * * *(1小时)
10.6 故障恢复
当 Logstash 重启后,会从 last_run_metadata_path 读取上次执行时间,继续增量同步。
手动重置同步位置:
bash
# 重置为指定时间,重新同步该时间之后的记录
echo "--- 2026-01-01 00:00:00.000000000 Z" > /usr/share/logstash/data/.logstash_jdbc_last_run
# 触发全量同步(设置为很久以前的时间)
echo "--- 2020-01-01 00:00:00.000000000 Z" > /usr/share/logstash/data/.logstash_jdbc_last_run11. 总结
11.1 技术栈总结
| 组件 | 版本 | 作用 |
|---|---|---|
| Elasticsearch | 8.12 | 分布式搜索引擎 |
| Logstash | 8.12 | 数据采集、转换、输出 |
| Kibana | 8.12 | 可视化管理界面 |
| MySQL | 8.0 | 业务数据源 |
| IK Analyzer | - | 中文分词器 |
11.2 核心要点
- 索引设计:根据查询需求合理设计 mapping,选择合适的字段类型
- 分词策略:中文用 IK,英文用 standard,中英文混合做好字段规划
- 数据同步:增量同步依赖时间戳字段,软删除需特殊处理
- 性能优化 :
- 合理设置分片数
- 使用 filter 替代 query 提高性能
- 大数据量开启分页
11.3 适用场景
✅ 适合的场景 ❌ 不适合的场景
─────────────────────────────────────────────────
全文搜索 (电商、门户) 强事务 (金融交易)
日志分析 (ELK 栈) 高频小更新 (KV 存储)
业务分析 (聚合统计) 频繁 schema 变更
地理空间查询 (LBS) 简单等值查询12. 演示系统使用指南
12.1 项目简介
本项目是一个完整的 Elasticsearch 技术调研演示系统,展示了 ES 的核心功能、数据同步方案及最佳实践。
演示功能清单:
| 功能模块 | 展示内容 |
|---|---|
| 索引管理 | 创建、删除、查看、设置 |
| 文档操作 | CRUD、批量操作 |
| 全文搜索 | match、match_phrase、multi_match、bool、fuzzy、高亮 |
| 中文分词 | IK 分词器配置、中英文混合 |
| 聚合分析 | terms、range、histogram、stats 等 |
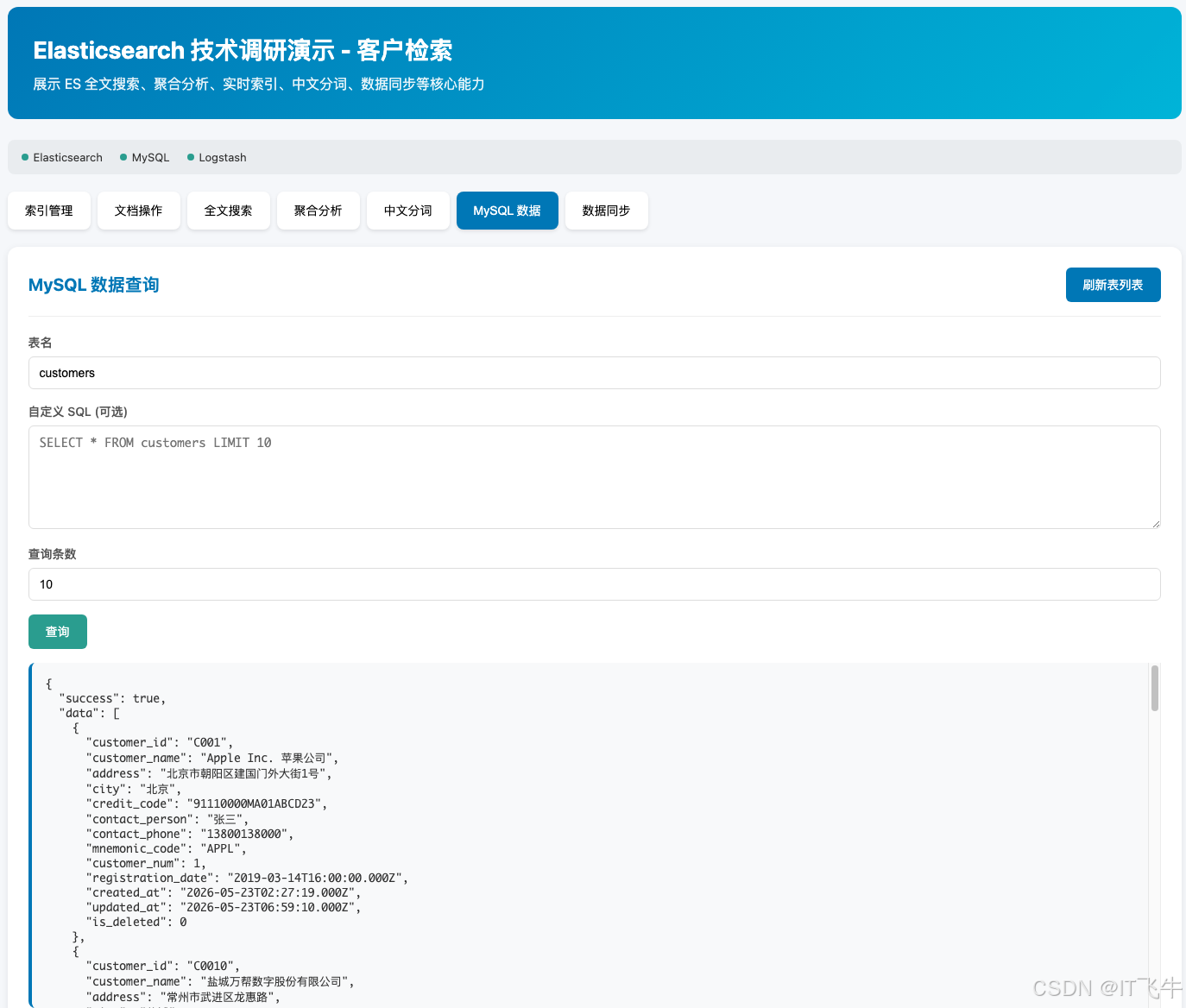
| 数据同步 | MySQL → ES 增量同步(增删改监听) |
12.2 获取源码
bash
# 克隆项目
git clone https://gitee.com/6feel/ElasticsearchDemo.git
# 进入项目目录
cd ElasticsearchDemo12.3 环境要求
| 组件 | 版本要求 |
|---|---|
| Docker | 20.10+ |
| Docker Compose | 2.0+ |
| Node.js | 16+ (后端服务) |
| 浏览器 | Chrome/Firefox/Safari |
12.4 目录结构
ElasticsearchDemo/
├── backend/ # Node.js + Express 后端
│ ├── src/
│ │ ├── config/ # 配置文件
│ │ ├── controllers/ # 控制器
│ │ ├── routes/ # 路由
│ │ └── utils/ # 工具类
│ └── server.js
├── frontend/ # 前端页面
│ └── index.html
├── logstash/ # Logstash 配置
│ ├── pipeline/
│ │ └── mysql-to-es.conf # MySQL → ES 同步配置
│ └── jdbc-driver/ # JDBC 驱动
├── elasticsearch/ # ES 相关配置
├── docker-compose.yml # 容器编排
└── README.md # 项目说明12.5 快速启动
12.5.1 配置数据库连接
首次使用前,请修改 docker-compose.yml 中的数据库连接信息:
yaml
mysql:
image: mysql:8.0
environment:
- MYSQL_ROOT_PASSWORD=your_password # 修改为您的密码
- MYSQL_DATABASE=elasticsearch_demo同时修改 logstash/pipeline/mysql-to-es.conf 中的连接信息:
conf
jdbc_connection_string => "jdbc:mysql://your_mysql_host:3306/elasticsearch_demo"
jdbc_user => "your_username"
jdbc_password => "your_password"12.5.2 启动所有服务
bash
# 启动 Docker 服务
docker-compose up -d
# 启动后端服务(在新窗口)
cd backend
npm install
npm start12.5.3 验证服务
| 服务 | 地址 |
|---|---|
| Elasticsearch | http://localhost:9200 |
| Kibana | http://localhost:5601 |
| Logstash API | http://localhost:9600 |
| 后端 API | http://localhost:3000 |
| 前端页面 | http://localhost:3000 |
12.6 功能演示
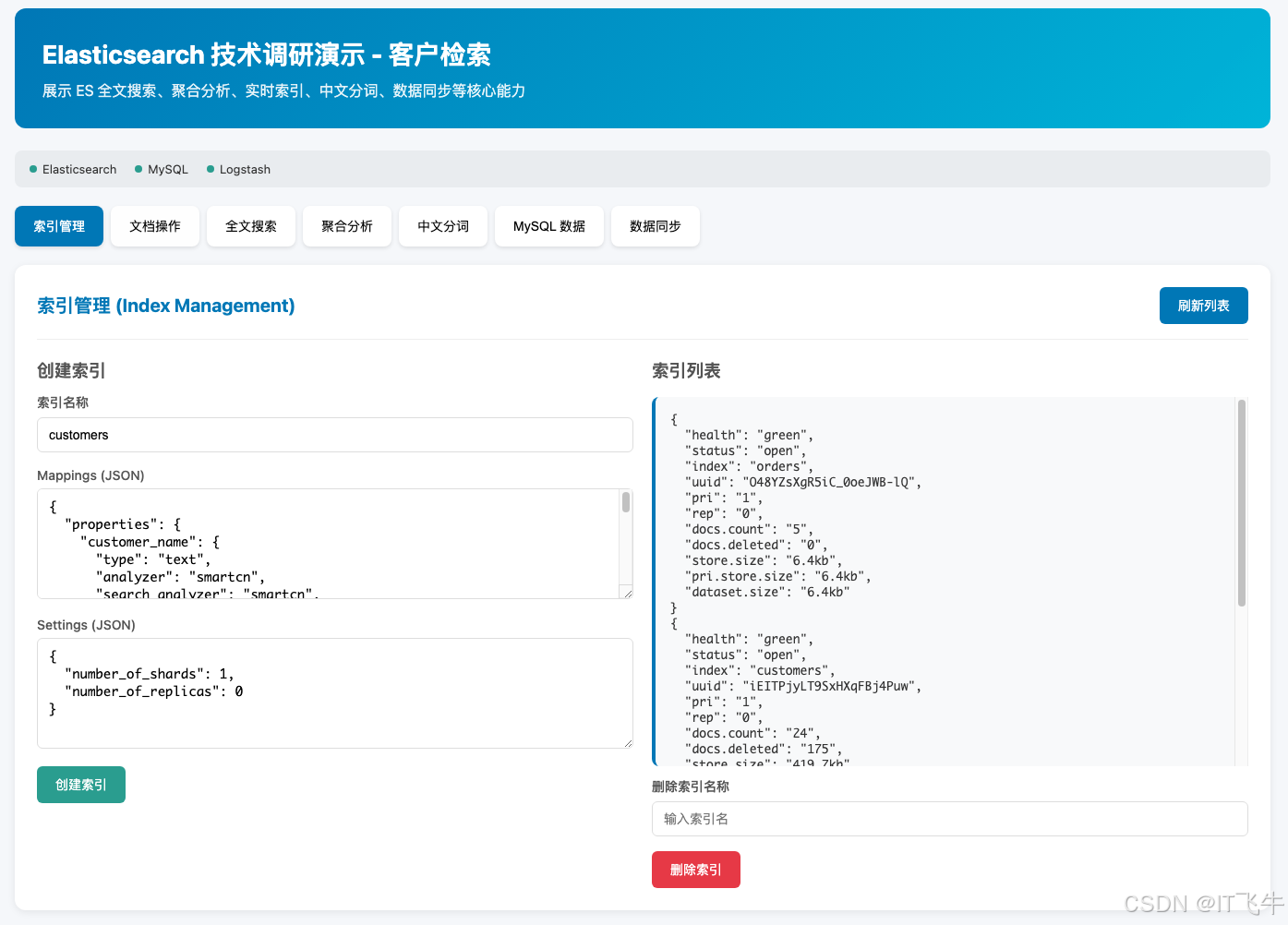
12.6.1 索引管理
访问前端页面 http://localhost:3000 ,使用索引管理功能:
- 创建
customers索引(使用 IK 分词器) - 查看索引列表
- 删除不需要的索引
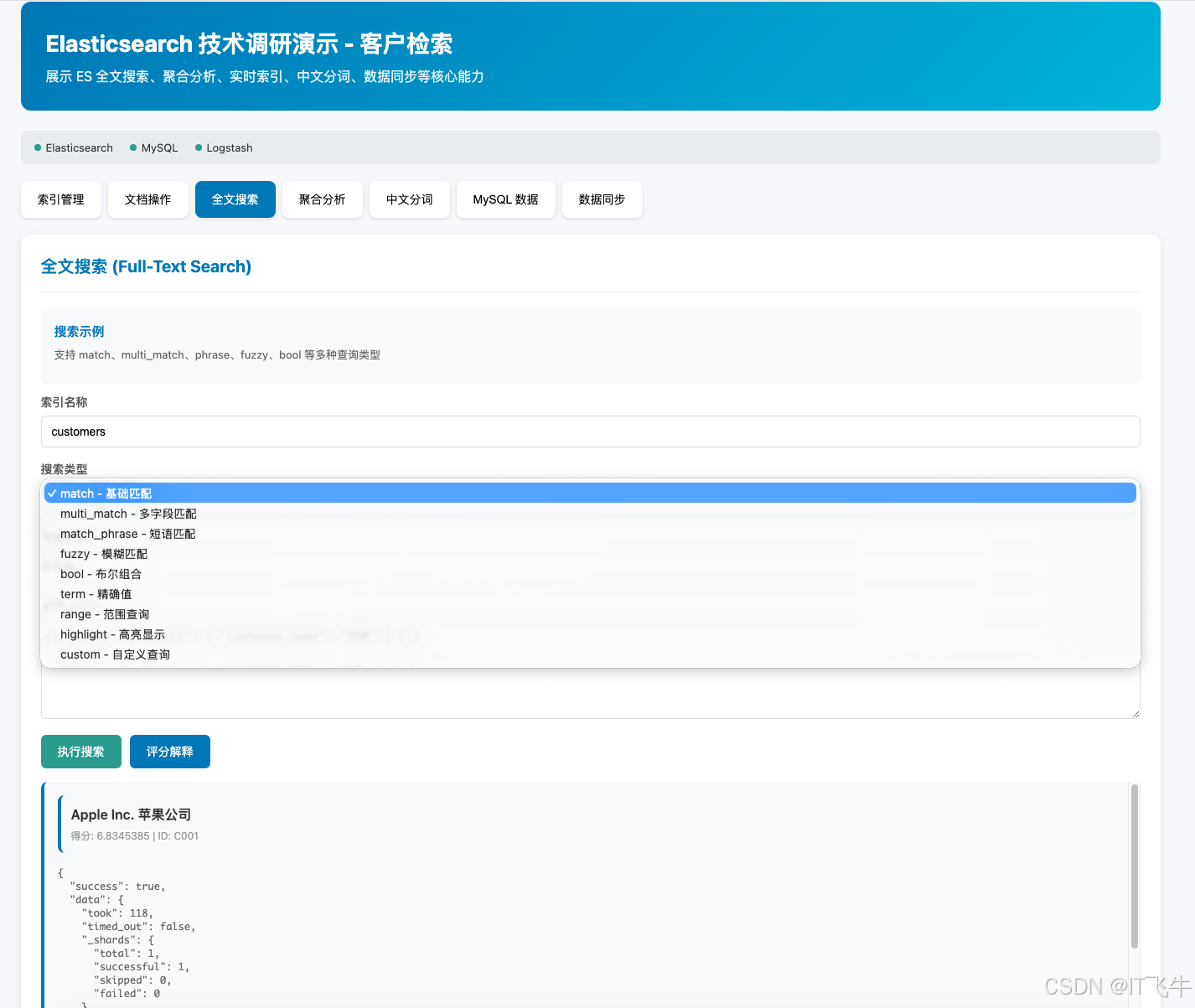
12.6.2 全文搜索演示
- 基础搜索:在搜索框输入 "华为"、"科技" 等关键词
- 短语搜索:使用 match_phrase 查询完整短语
- 多字段搜索:同时搜索公司名和地址
- 组合查询:结合城市过滤
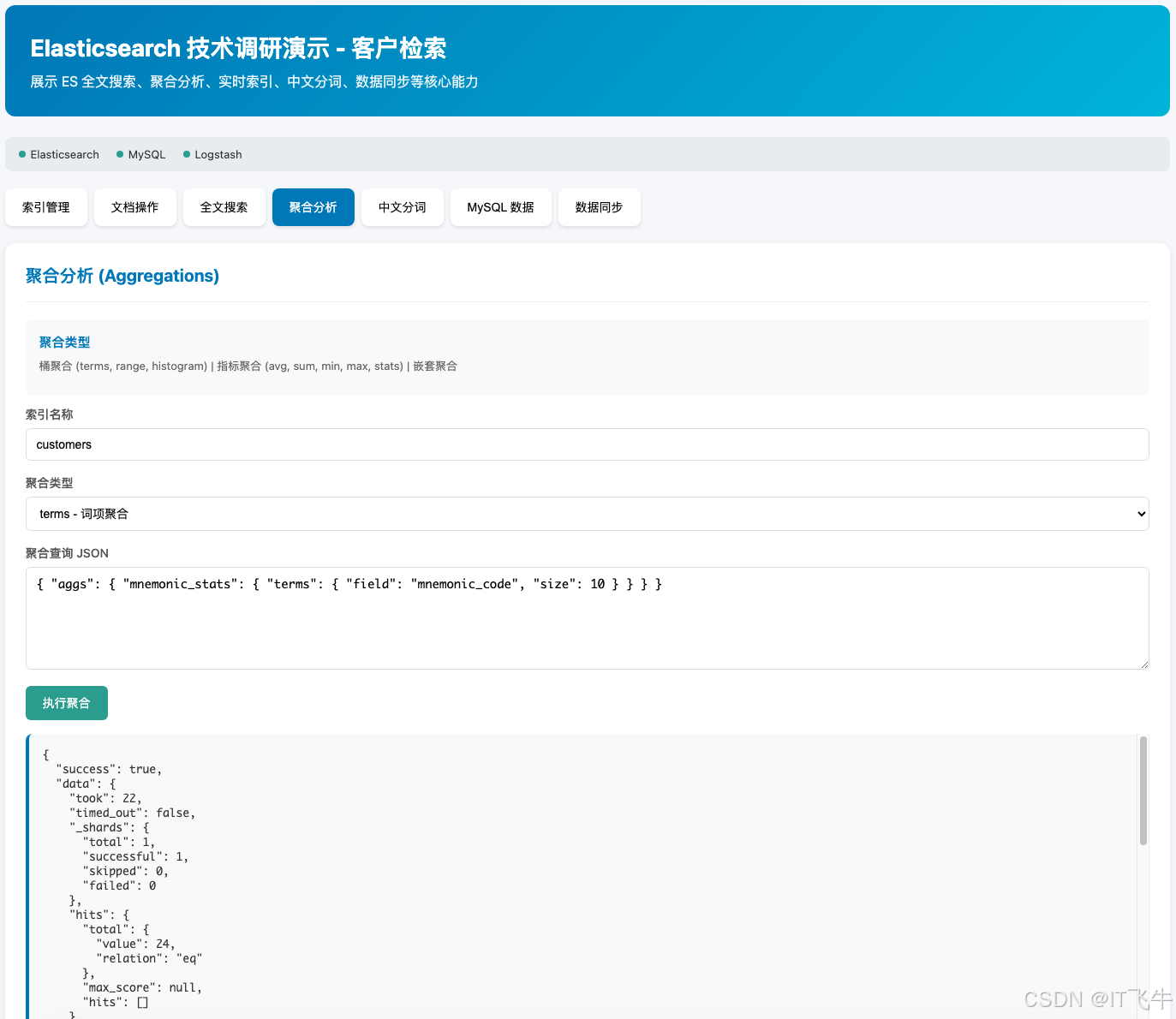
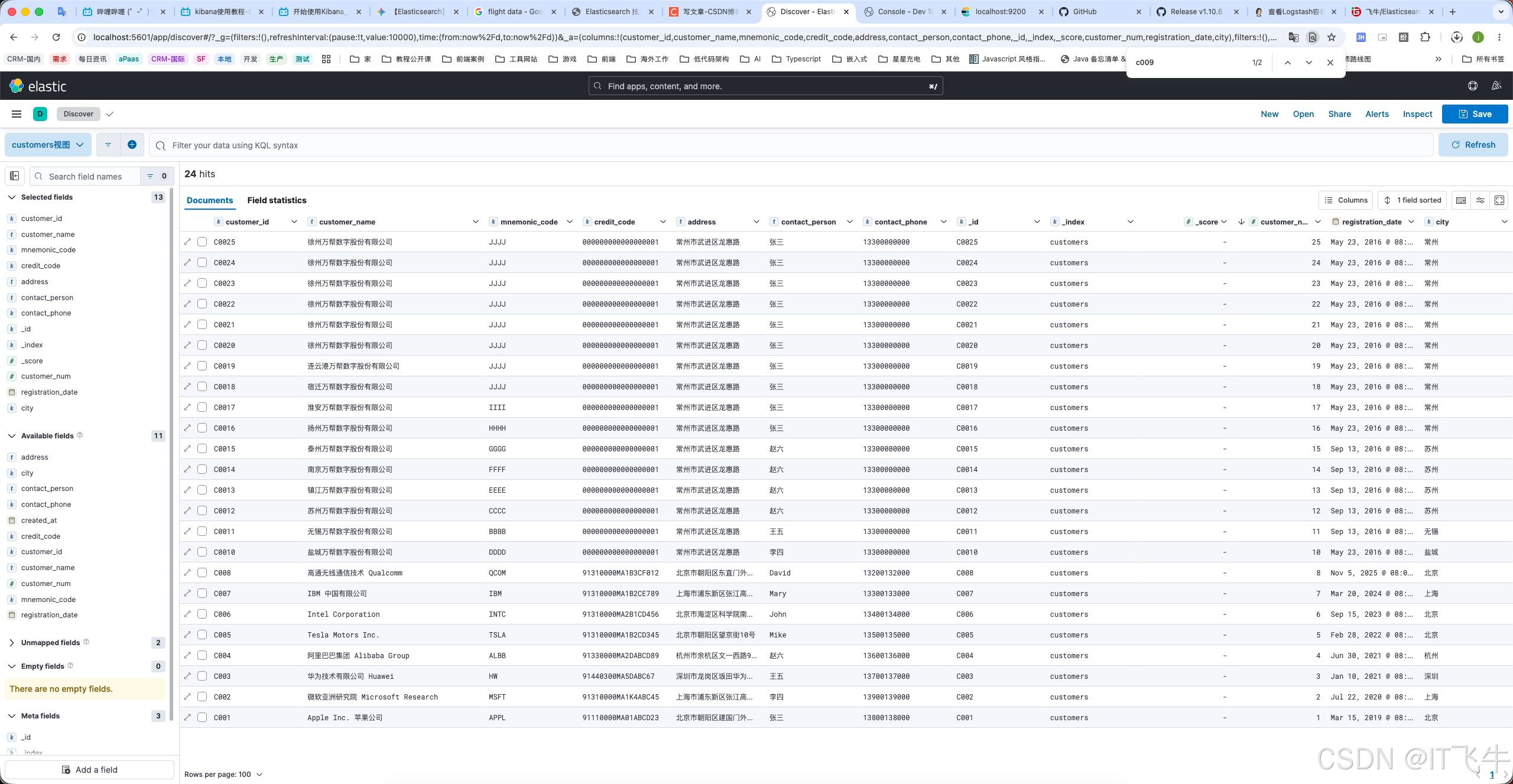
12.6.3 聚合分析
使用聚合功能:
- 按城市统计客户数量
- 按客户编号区间分组
- 嵌套聚合(城市 → 客户数 → 平均编号)
12.6.4 数据同步演示
准备工作:
sql
-- 创建演示表
CREATE TABLE customers (
customer_id VARCHAR(20) PRIMARY KEY,
customer_name VARCHAR(200),
city VARCHAR(50),
contact_person VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
is_deleted TINYINT DEFAULT 0
);
-- 创建 INSERT 触发器
CREATE TRIGGER before_insert_customers
BEFORE INSERT ON customers
FOR EACH ROW
SET NEW.updated_at = NEW.created_at;
-- 插入演示数据
INSERT INTO customers (customer_id, customer_name, city, contact_person) VALUES
('C001', '华为技术有限公司', '深圳', '张三'),
('C002', '阿里巴巴集团', '杭州', '李四'),
('C003', '腾讯科技', '深圳', '王五');增删改操作:
sql
-- 新增记录(自动同步)
INSERT INTO customers (customer_id, customer_name, city) VALUES ('C004', '字节跳动', '北京');
-- 修改记录(自动同步)
UPDATE customers SET city = '广州' WHERE customer_id = 'C001';
-- 软删除(从 ES 删除)
UPDATE customers SET is_deleted = 1, updated_at = NOW() WHERE customer_id = 'C002';查看同步状态:
bash
# 查看 Logstash 同步统计
curl http://localhost:9600/_node/stats
# 查看当前 last_run 值
docker exec logstash cat /usr/share/logstash/data/.logstash_jdbc_last_run12.7 配置说明
12.7.1 同步周期配置
修改 logstash/pipeline/mysql-to-es.conf:
conf
schedule => "*/5 * * * * *" # 每 5 秒执行常用配置:
| 表达式 | 含义 |
|---|---|
*/5 * * * * * |
每 5 秒 |
*/30 * * * * * |
每 30 秒 |
0 * * * * * |
每小时整点 |
12.7.2 分页配置
conf
jdbc_paging_enabled => true
jdbc_page_size => 1000 # 每页数量12.7.3 同步延迟
Logstash JDBC 的同步延迟 = 调度周期 + SQL 执行时间 + ES 写入时间。
- 5 秒周期:延迟约 5-15 秒
- 30 秒周期:延迟约 30-45 秒
12.8 故障排查
12.8.1 服务无法启动
bash
# 查看容器日志
docker-compose logs elasticsearch
docker-compose logs logstash
# 检查端口占用
lsof -i:9200
lsof -i:960012.8.2 数据不同步
-
检查 Logstash 是否正常运行:
bashcurl http://localhost:9600 -
检查 last_run 值:
bashdocker exec logstash cat /usr/share/logstash/data/.logstash_jdbc_last_run -
手动重置同步位置触发全量同步:
bashdocker exec logstash sh -c "echo '--- 2020-01-01 00:00:00.000000000 Z' > /usr/share/logstash/data/.logstash_jdbc_last_run" -
重启 Logstash:
bashdocker-compose restart logstash
12.8.3 ES 查询异常
bash
# 检查 ES 健康状态
curl http://localhost:9200/_cluster/health
# 查看索引文档数量
curl http://localhost:9200/customers/_count12.9 注意事项
⚠️ 数据库信息安全
本项目演示用的数据库连接信息存储在配置文件中。请勿将包含真实密码的配置文件提交到代码仓库。建议使用环境变量或 Docker Secrets 管理敏感信息。
⚠️ 生产环境建议
- 启用 ES 安全认证
- 使用单独的数据库账号,限制权限
- 配置定期备份策略
- 监控告警
12.10 系统截图
sh
# 常用DSL操作语法
# Click the Variables button, above, to create your own variables.
GET ${exampleVariable1} // _search
{
"query": {
"${exampleVariable2}": {} // match_all
}
}
// 1. 搜索"苹果" (多字段匹配)
GET /customers/_search
{
"query": {
"multi_match": {
"query": "苹果",
"fields": ["customer_name", "credit_code", "mnemonic_code", "customer_id"]
}
}
}
// 2. 搜索英文"Tesla" (多字段匹配)
GET /customers/_search
{
"query": {
"multi_match": {
"query": "Tesla",
"fields": ["customer_name", "credit_code", "mnemonic_code", "customer_id"]
}
}
}
// 3. 搜索助记码"TSLA"
GET /customers/_search
{
"query": {
"multi_match": {
"query": "TSLA",
"fields": ["customer_name", "credit_code", "mnemonic_code", "customer_id"]
}
}
}
// 4. 搜索客户ID"C001"
GET /customers/_search
{
"query": {
"multi_match": {
"query": "C001",
"fields": ["customer_name", "credit_code", "mnemonic_code", "customer_id"]
}
}
}
// 5. 模糊搜索"Intel" (可能有拼写错误)
GET /customers/_search
{
"query": {
"fuzzy": {
"customer_name": {
"value": "Intel",
"fuzziness": "AUTO"
}
}
}
}
// 6. 短语搜索"苹果公司"
GET /customers/_search
{
"query": {
"match_phrase": {
"customer_name": "苹果公司"
}
}
}
// 7. 布尔组合: 搜索"科技"且在北京的
GET /customers/_search
{
"query": {
"bool": {
"must": [
{ "match": { "customer_name": "科技" } }
],
"filter": [
{ "match": { "address": "深圳" } }
]
}
}
}
// 8. 多词搜索"无线通信" (OR逻辑)
GET /customers/_search
{
"query": {
"match": {
"customer_name": "无线通信"
}
}
}
// 9. 通配符搜索 以"苹果"开头的客户名称
GET /customers/_search
{
"query": {
"wildcard": {
"customer_name": "苹果*"
}
}
}
// 10. 范围搜索 客户ID在 C005-C010 之间
GET /customers/_search
{
"query": {
"range": {
"customer_id": {
"gte": "C005",
"lte": "C010"
}
}
}
}
// 11. 高亮显示搜索关键词
GET /customers/_search
{
"query": {
"multi_match": {
"query": "苹果",
"fields": ["customer_name", "credit_code", "mnemonic_code", "customer_id"]
}
},
"highlight": {
"fields": {
"customer_name": {}
}
}
}
// 12. 分页搜索 (第2页,每页5条)
GET /customers/_search
{
"from": 5,
"size": 5,
"query": {
"match_all": {}
}
}
// 13. 按相关性排序
GET /customers/_search
{
"query": {
"multi_match": {
"query": "苹果",
"fields": ["customer_name", "credit_code", "mnemonic_code", "customer_id"]
}
},
"sort": [
{ "_score": "desc" }
]
}
// 14. 查询所有客户
GET /customers/_search
{
"query": {
"match_all": {}
}
}参考资料
项目源码:https://gitee.com/6feel/ElasticsearchDemo
作者:IT飞牛
发布时间:2026年5月
原创声明:本文为技术调研实践记录,转载需注明出处。