LASSO回归学习笔记
前言
本笔记主要参考吕欣教授的《数据挖掘》教材,从几何直观到统计推断,全面解析LASSO回归(Least Absolute Shrinkage and Selection Operator)。不同于传统的岭回归,LASSO通过L1正则化实现了特征选择的"硬剪枝",在变量选择问题上展现出独特的优势。我们将从岭回归的局限性谈起,深入探讨L1正则化的几何意义、优化求解方法,并配合Python代码进行模型路径的可视化分析。
书籍学习开源代码:https://github.com/XL-lab-bigdata/DataMining
第一章:高维诅咒与岭回归的局限
1.1 线性回归在高维空间的困境
标准线性回归模型为: y = X β + ε y = X\beta + \varepsilon y=Xβ+ε
通过最小二乘估计,得到参数估计值: β ^ O L S = ( X T X ) − 1 X T y \hat{\beta}_{OLS} = (X^T X)^{-1} X^T y β^OLS=(XTX)−1XTy
然而,当特征维度 p p p接近或超过样本量 n n n时, X T X X^TX XTX接近奇异,导致参数估计极不稳定,方差急剧增大------这就是高维诅咒(Curse of Dimensionality)。
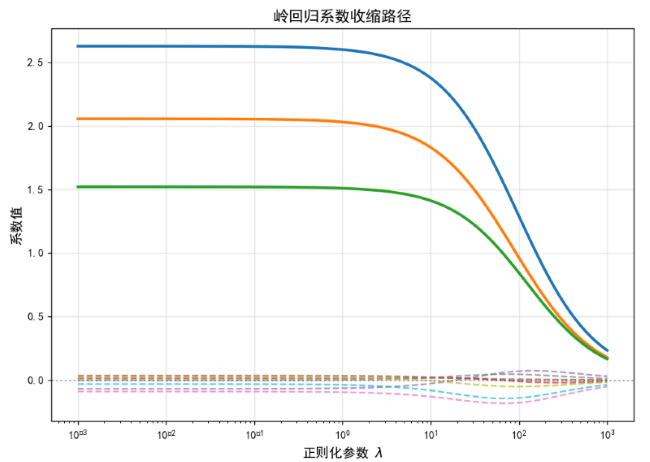
1.2 岭回归:L2正则化的平滑收缩
为应对多重共线性问题,岭回归引入L2正则化:
βridge=argminβ{∑i=1n(yi−xiTβ)2+λ∑j=1pβj2}*β*ri dge =argminβ {∑i =1n (y**i −xiT**β )2+λ ∑j =1pβj2}
等价于带约束的优化问题: min ∑ ( y i − x i T β ) 2 s . t . ∑ β j 2 ≤ t \min \sum (y_i - x_i^T \beta)^2 \quad s.t. \quad \sum \beta_j^2 \leq t min∑(yi−xiTβ)2s.t.∑βj2≤t
岭回归的特点:
- 所有系数被均匀收缩,但不会归零
- 有效降低方差,但引入偏差
- 无法进行特征选择(Feature Selection)
可视化:岭回归的收缩效应
以下代码展示了不同 λ \lambda λ值下岭回归系数的收缩路径:
第二章:LASSO的几何直观与特征选择
2.1 LASSO的数学形式
LASSO回归在最小二乘损失的基础上添加L1正则项:
βlasso=argminβ{12n∑i=1n(yi−xiTβ)2+λ∑j=1p∣βj∣}*β*lasso =argminβ {2n 1∑i =1n (y**i −xiT**β )2+λ ∑j =1p ∣β**j∣}
等价约束形式: min 1 2 n ∑ ( y i − x i T β ) 2 s . t . ∑ ∣ β j ∣ ≤ t \min \frac{1}{2n} \sum (y_i - x_i^T \beta)^2 \quad s.t. \quad \sum |\beta_j| \leq t min2n1∑(yi−xiTβ)2s.t.∑∣βj∣≤t
2.2 几何解释:为什么L1正则化能产生稀疏解
考虑二维情况( β 1 , β 2 \beta_1, \beta_2 β1,β2):
- 岭回归的约束域 :圆形 β 1 2 + β 2 2 ≤ t \beta_1^2 + \beta_2^2 \leq t β12+β22≤t(L2球)
- LASSO的约束域 :菱形 ∣ β 1 ∣ + ∣ β 2 ∣ ≤ t |\beta_1| + |\beta_2| \leq t ∣β1∣+∣β2∣≤t(L1球)
当最小二乘解(无约束最优)位于约束域外时,岭回归的最优解是圆与等高线的切点,通常不在坐标轴上。而LASSO的最优解很可能在菱形的顶点上,此时某些系数恰好为0。
可视化:L1与L2约束的几何对比
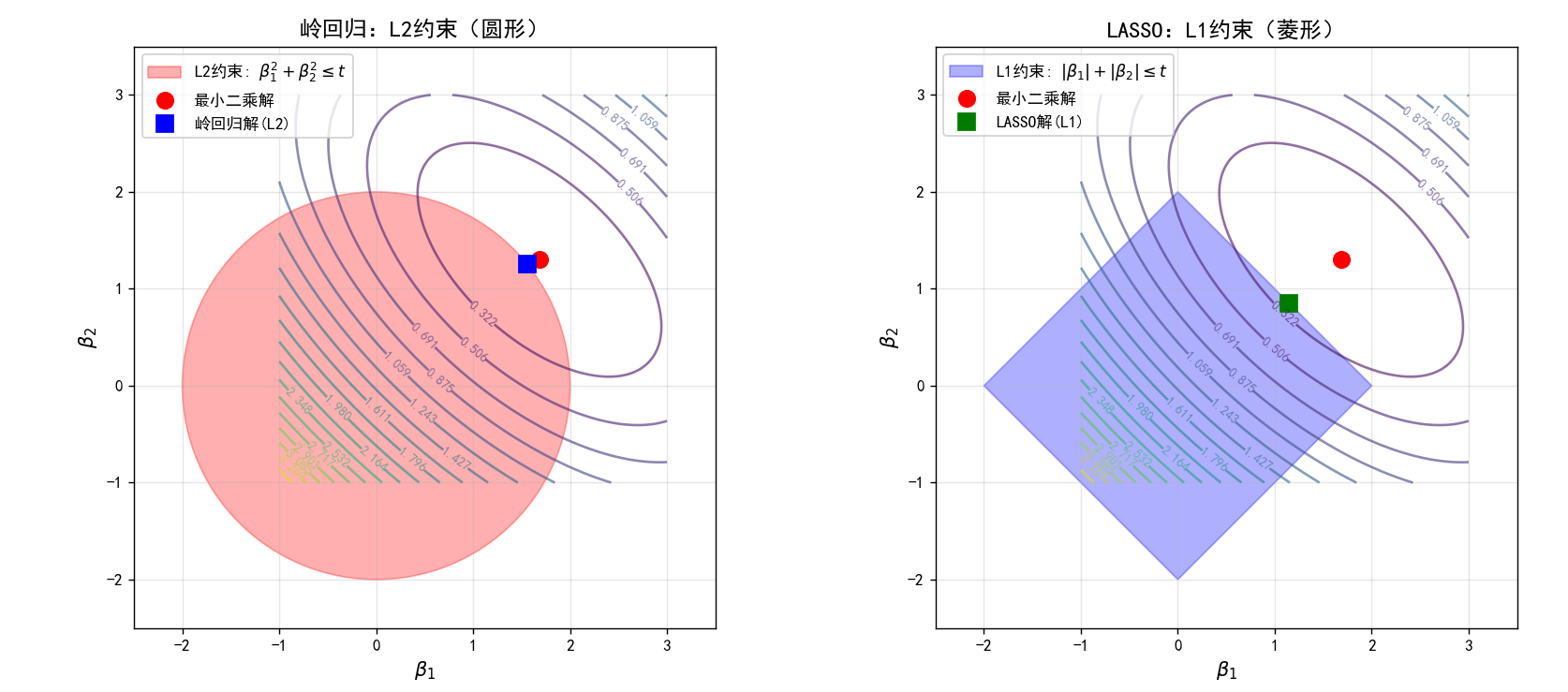
关键洞察:LASSO的菱形约束域有"尖角"(顶点在坐标轴上),当等高线与这些尖角相交时,最优解恰好落在坐标轴上,对应某些系数为零。这就是LASSO能产生稀疏解的根本原因。
第三章:优化算法与求解
3.1 坐标下降法(Coordinate Descent)
由于L1正则项在零点不可导,无法使用梯度下降法直接求解。坐标下降法通过固定其他坐标,每次只优化一个变量:
βj(k+1)=argminβj{12n∑i=1n(yi−∑l≠jxilβl(k)−xijβj)2+λ∣βj∣}β**j (k +1)=argminβ**j {2n 1∑i =1n (y**i −∑l =jx ilβ**l (k )−xijβ**j )2+λ ∣β**j∣}
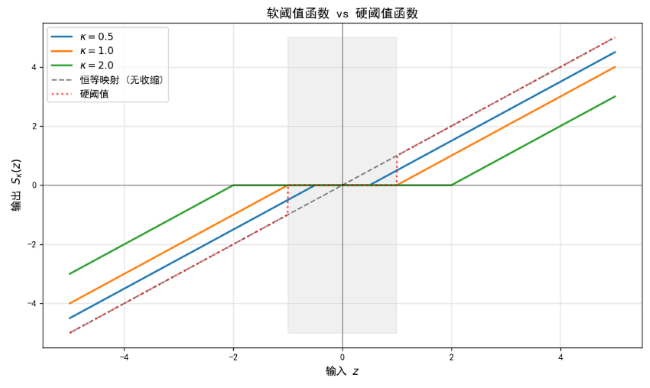
3.2 软阈值算子(Soft Thresholding)
上述单变量优化问题有解析解,称为软阈值算子:
βj(k+1)=Sλ/n(zj)β**j (k +1)=S**λ /n (z**j)
其中:
- z j = 1 n ∑ i = 1 n x i j ( y i − ∑ l ≠ j x i l β l ( k ) ) z_j = \frac{1}{n} \sum_{i=1}^n x_{ij} \left( y_i - \sum_{l \neq j} x_{il}\beta_l^{(k)} \right) zj=n1∑i=1nxij(yi−∑l=jxilβl(k))
- 软阈值函数: S κ ( z ) = sign ( z ) ⋅ ( ∣ z ∣ − κ ) + S_{\kappa}(z) = \text{sign}(z) \cdot (|z| - \kappa)_+ Sκ(z)=sign(z)⋅(∣z∣−κ)+
可视化:软阈值函数的特性
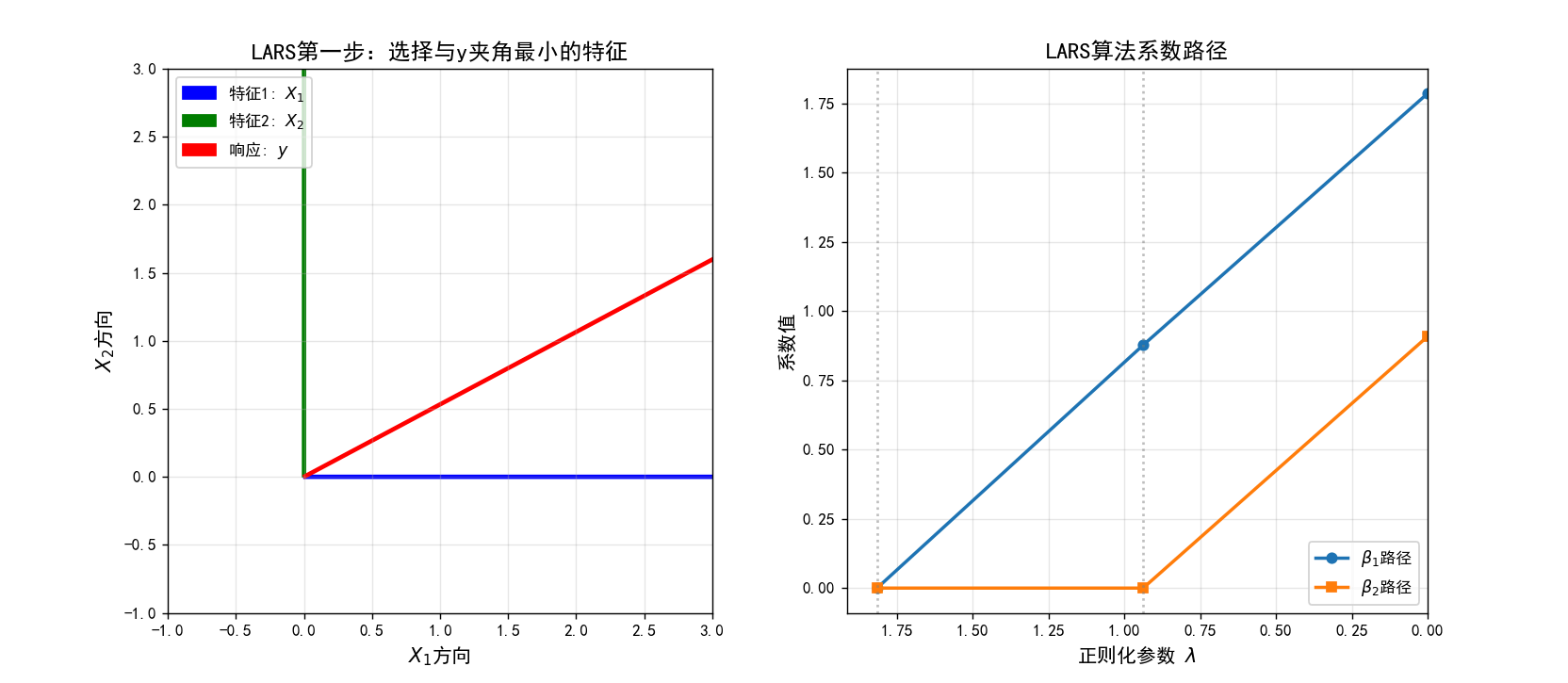
3.3 最小角回归(LARS)算法
另一种高效的LASSO求解算法是最小角回归(Least Angle Regression),其特点:
- 从所有系数为零开始
- 每次选择一个与当前残差相关性最大的特征
- 沿着该特征方向移动,直到另一个特征的相关性与其相等
- 同时沿着这两个特征的角平分线方向移动
- 重复直到所有特征都被纳入或达到停止条件
LARS算法的优势在于可以高效地计算整个正则化路径。
可视化:LARS算法的几何直观
第四章:正则化路径与特征选择
4.1 正则化路径分析
随着正则化参数 λ \lambda λ从 + ∞ +\infty +∞到 0 0 0变化,LASSO系数呈现出独特的路径特征:
- 当 λ \lambda λ很大时,所有系数被压缩至0
- 随着 λ \lambda λ减小,最相关的特征首先被激活(系数非零)
- 路径呈分段线性,转折点处有特征加入或退出模型
可视化:LASSO正则化路径
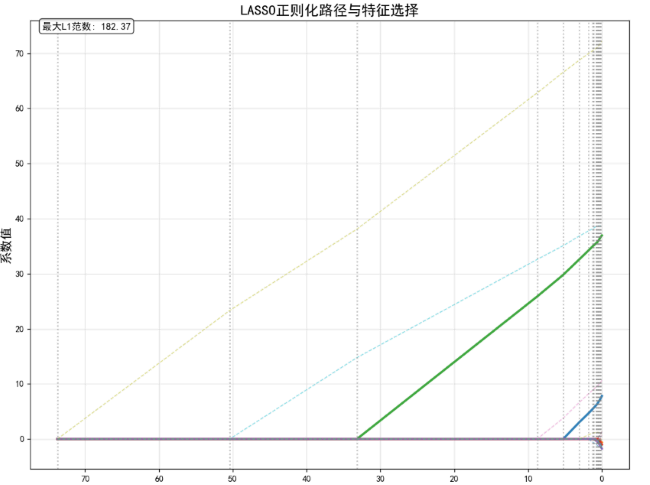
4.2 模型选择:交叉验证确定 λ \lambda λ
实践中,我们通过交叉验证选择最优的 λ \lambda λ值。通常考虑:
- λ min \lambda_{\min} λmin:最小化交叉验证误差
- λ 1 s e \lambda_{1se} λ1se:在一倍标准误差内的最稀疏模型
可视化:LASSO交叉验证误差曲线
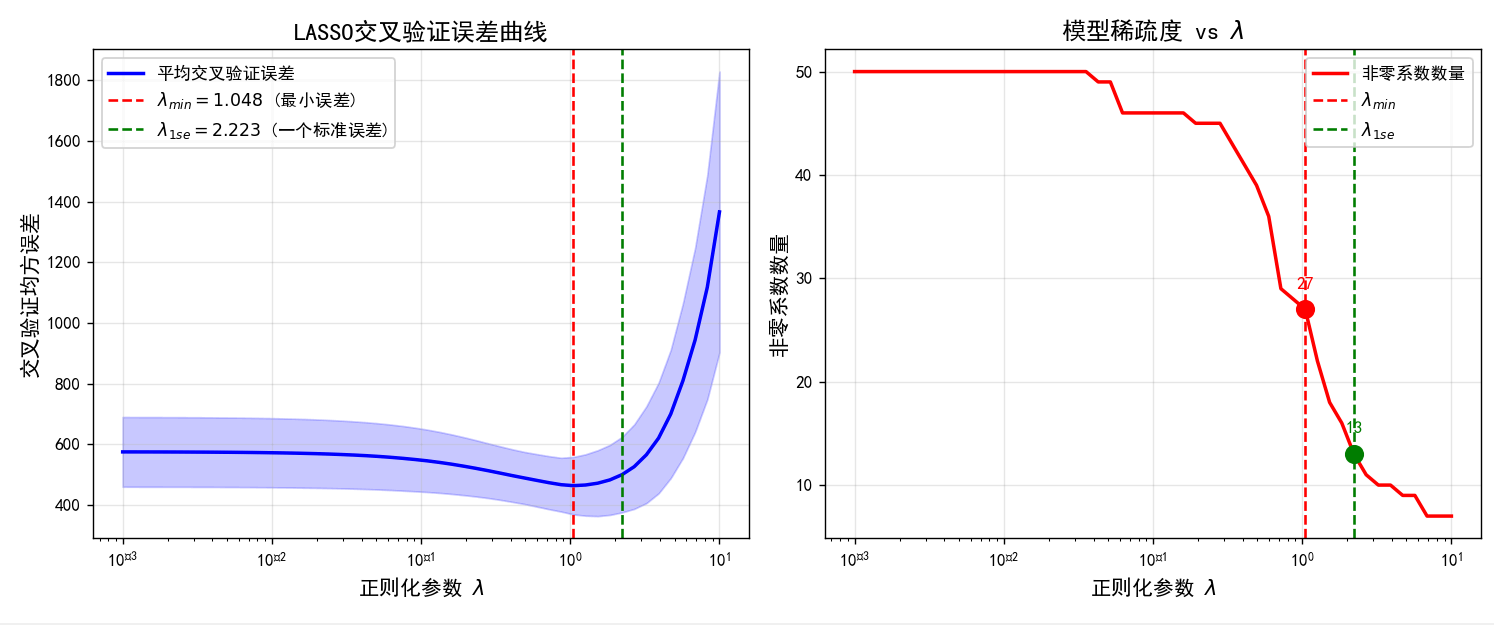
第五章:统计理论与Oracle性质
5.1 Oracle性质
一个理想的变量选择方法应具备Oracle性质:
- 选择一致性:以概率1正确识别真实模型(选择出真正非零的系数)
- 估计一致性:估计量的收敛速度与事先知道真实模型时相同
5.2 LASSO的Oracle性质
在适当的正则条件下,LASSO具备Oracle性质:
- 当 n → ∞ n \to \infty n→∞且 λ n → 0 \lambda_n \to 0 λn→0,但 n λ n → ∞ \sqrt{n}\lambda_n \to \infty n λn→∞时
- LASSO能一致地选择出真实模型
- 估计量满足渐近正态性
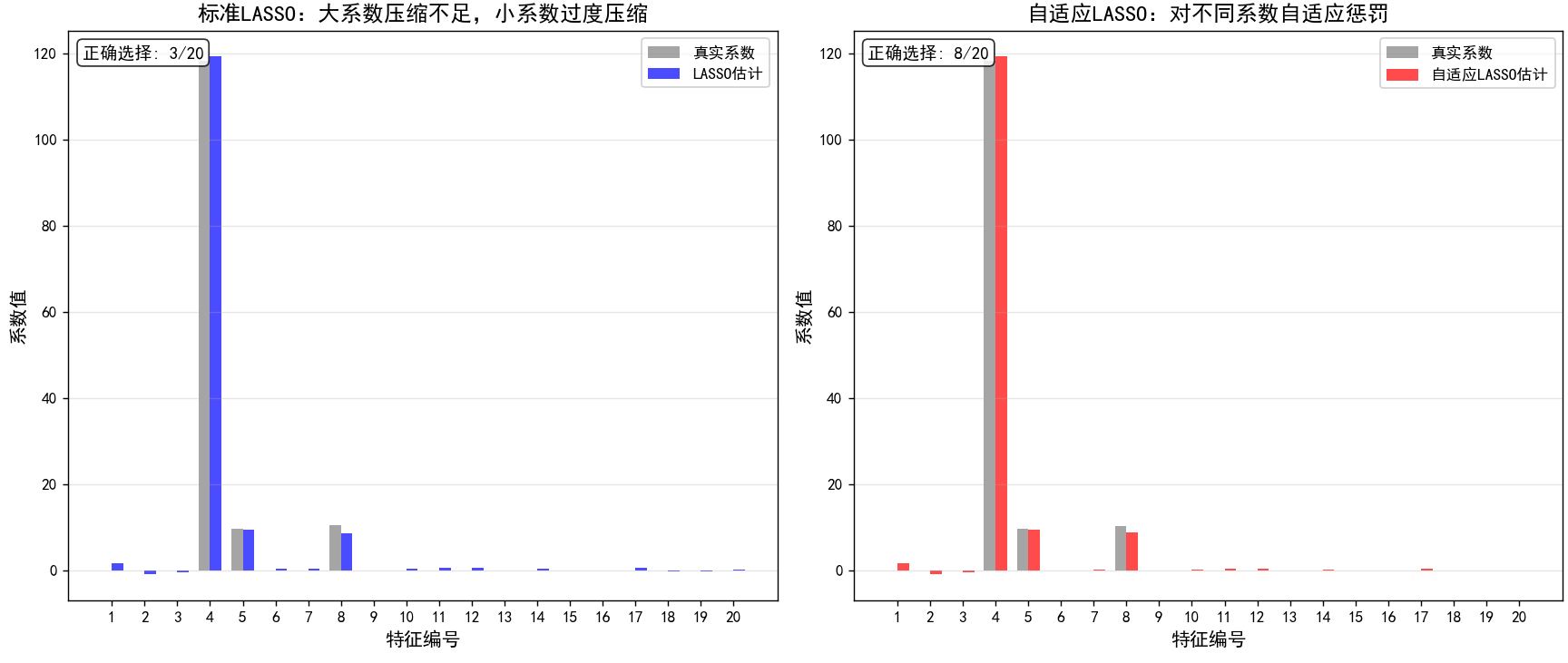
5.3 自适应LASSO
为改进LASSO的选择一致性,Zou (2006)提出了自适应LASSO:
βadap=argminβ{∑i=1n(yi−xiTβ)2+λ∑j=1pwj∣βj∣}*β*ada**p =argminβ {∑i =1n (y**i −xiT**β )2+λ ∑j =1pwj ∣β**j∣}
其中权重 w j = 1 / ∣ β ^ j ( i n i t ) ∣ γ w_j = 1 / |\hat{\beta}_j^{(init)}|^\gamma wj=1/∣β^j(init)∣γ,通常 γ = 1 \gamma=1 γ=1, β ^ ( i n i t ) \hat{\beta}^{(init)} β^(init)可以是OLS或岭回归估计。
自适应LASSO在理论上具有更好的Oracle性质。
可视化:自适应LASSO vs 标准LASSO
第六章:工程实践与调参指南
6.1 数据预处理
与SVM类似,LASSO对特征尺度敏感,必须进行标准化:
python
import numpy as np
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)6.2 超参数调优
6.2.1 网格搜索与交叉验证
python
import numpy as np
from sklearn.linear_model import LassoCV
from sklearn.model_selection import GridSearchCV
# 方法1: LassoCV(内置交叉验证)
lasso_cv = LassoCV(alphas=np.logspace(-4, 0, 100),
cv=5,
max_iter=10000,
random_state=42)
lasso_cv.fit(X_scaled, y)
best_alpha = lasso_cv.alpha_
# 方法2: GridSearchCV(更灵活)
param_grid = {'alpha': np.logspace(-4, 0, 50)}
lasso = Lasso(max_iter=10000, random_state=42)
grid_search = GridSearchCV(lasso, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_scaled, y)
best_alpha_grid = grid_search.best_params_['alpha']6.2.2 信息准则(AIC/BIC)
当样本量较大时,也可使用信息准则选择 λ \lambda λ:
python
import numpy as np
def lasso_aic_bic(lasso_model, X, y):
"""计算LASSO的AIC和BIC"""
n_samples = X.shape[0]
n_features = X.shape[1]
# 预测值
y_pred = lasso_model.predict(X)
# 残差平方和
rss = np.sum((y - y_pred)**2)
# 有效参数个数(非零系数)
k = np.sum(np.abs(lasso_model.coef_) > 1e-4) + 1 # +1 for intercept if used
# AIC和BIC
aic = n_samples * np.log(rss/n_samples) + 2 * k
bic = n_samples * np.log(rss/n_samples) + k * np.log(n_samples)
return aic, bic, k6.3 特征重要性分析
LASSO天然提供特征重要性排序:
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
def analyze_feature_importance(lasso_model, feature_names):
"""分析LASSO模型的特征重要性"""
coef = lasso_model.coef_
# 创建特征重要性DataFrame
importance_df = pd.DataFrame({
'feature': feature_names,
'coefficient': coef,
'abs_coefficient': np.abs(coef)
})
# 排序
importance_df = importance_df.sort_values('abs_coefficient', ascending=False)
# 可视化
plt.figure(figsize=(10, 6))
colors = ['red' if c > 0 else 'blue' for c in importance_df['coefficient']]
plt.barh(range(len(importance_df)), importance_df['abs_coefficient'], color=colors)
plt.yticks(range(len(importance_df)), importance_df['feature'])
plt.xlabel('系数绝对值', fontsize=12)
plt.title('LASSO特征重要性', fontsize=14)
plt.grid(True, alpha=0.3, axis='x')
plt.tight_layout()
return importance_df6.4 稳定性选择
LASSO的结果可能对数据扰动敏感,可通过稳定性选择提高鲁棒性:
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso
def stability_selection(X, y, n_bootstrap=100, alpha=0.05):
"""稳定性选择:多次重采样LASSO,统计特征被选中的频率"""
n_samples, n_features = X.shape
selection_freq = np.zeros(n_features)
for _ in range(n_bootstrap):
# 自助采样
indices = np.random.choice(n_samples, n_samples, replace=True)
X_boot = X[indices]
y_boot = y[indices]
# LASSO拟合
lasso = Lasso(alpha=alpha, max_iter=10000, random_state=42)
lasso.fit(X_boot, y_boot)
# 记录被选中的特征
selection_freq += (np.abs(lasso.coef_) > 1e-4)
# 计算选择频率
selection_freq = selection_freq / n_bootstrap
# 可视化稳定性选择结果
plt.figure(figsize=(10, 6))
plt.bar(range(n_features), selection_freq)
plt.axhline(y=0.8, color='r', linestyle='--', label='80%稳定性阈值')
plt.xlabel('特征编号', fontsize=12)
plt.ylabel('选择频率', fontsize=12)
plt.title('稳定性选择:特征被选中的频率', fontsize=14)
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
return selection_freq可视化:稳定性选择结果

第七章:案例实战:信用卡欺诈检测
7.1 数据探索与预处理
python
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def credit_card_fraud_case():
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Lasso, LassoCV
from sklearn.metrics import mean_squared_error, r2_score, classification_report, roc_auc_score
import numpy as np
# 加载信用卡欺诈数据集(这里使用模拟数据,因为真实数据集较大)
# 在实际应用中,可以使用Kaggle的信用卡欺诈数据集
np.random.seed(42)
n_samples = 10000
n_features = 30
# 生成模拟数据
X = np.random.randn(n_samples, n_features)
# 创建有意义的特征名称
feature_names = [f'V{i+1}' for i in range(n_features)]
# 添加一些噪声特征
X[:, 10:15] += np.random.randn(n_samples, 5) * 2 # 这些特征噪声更大
# 真实系数:只有前10个特征与目标相关
true_coef = np.zeros(n_features)
true_coef[:10] = np.random.randn(10) * 3
# 生成目标变量(欺诈概率)
log_odds = X @ true_coef + np.random.randn(n_samples) * 0.5
prob = 1 / (1 + np.exp(-log_odds))
y = (prob > 0.5).astype(int)
# 确保类别不平衡(欺诈案例通常很少)
fraud_indices = np.where(y == 1)[0]
non_fraud_indices = np.where(y == 0)[0]
# 只保留10%的欺诈案例,以模拟真实的不平衡数据
n_fraud = len(fraud_indices)
keep_fraud = int(n_fraud * 0.1)
fraud_to_keep = np.random.choice(fraud_indices, keep_fraud, replace=False)
# 创建平衡数据集
X_balanced = np.vstack([X[fraud_to_keep], X[non_fraud_indices[:keep_fraud*9]]])
y_balanced = np.hstack([y[fraud_to_keep], y[non_fraud_indices[:keep_fraud*9]]])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X_balanced, y_balanced, test_size=0.2, random_state=42, stratify=y_balanced
)
# 数据标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
return X_train_scaled, X_test_scaled, y_train, y_test, feature_names, true_coef
# 获取数据
X_train_scaled, X_test_scaled, y_train, y_test, feature_names, true_coef = credit_card_fraud_case()结果如下:
数据生成完成!
训练集形状: (3936, 30)
测试集形状: (984, 30)
特征数量: 30
正例比例: 10.01%
7.2 模型训练与比较
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
def compare_classification_models():
"""比较不同分类模型在信用卡欺诈检测上的性能"""
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, confusion_matrix
import pandas as pd
import seaborn as sns
models = {
'逻辑回归': LogisticRegression(penalty='l2', C=1.0, max_iter=1000, random_state=42),
'LASSO逻辑回归': LogisticRegression(penalty='l1', C=0.1, solver='liblinear', max_iter=1000, random_state=42),
'随机森林': RandomForestClassifier(n_estimators=100, random_state=42),
'SVM': SVC(probability=True, random_state=42)
}
results = []
plt.figure(figsize=(15, 10))
for idx, (name, model) in enumerate(models.items(), 1):
# 训练模型
model.fit(X_train_scaled, y_train)
# 预测
y_train_pred = model.predict(X_train_scaled)
y_test_pred = model.predict(X_test_scaled)
# 计算指标
train_acc = accuracy_score(y_train, y_train_pred)
test_acc = accuracy_score(y_test, y_test_pred)
precision = precision_score(y_test, y_test_pred)
recall = recall_score(y_test, y_test_pred)
f1 = f1_score(y_test, y_test_pred)
# 计算AUC(需要概率预测)
if hasattr(model, 'predict_proba'):
y_test_proba = model.predict_proba(X_test_scaled)[:, 1]
auc = roc_auc_score(y_test, y_test_proba)
else:
auc = 0
# 非零系数个数(对于LASSO逻辑回归)
if hasattr(model, 'coef_'):
n_nonzero = np.sum(np.abs(model.coef_) > 1e-4)
else:
n_nonzero = None
results.append({
'Model': name,
'Train_Acc': train_acc,
'Test_Acc': test_acc,
'Precision': precision,
'Recall': recall,
'F1': f1,
'AUC': auc,
'Nonzero_Coeff': n_nonzero
})
# 绘制特征重要性(对于LASSO逻辑回归)
if name == 'LASSO逻辑回归' and hasattr(model, 'coef_'):
plt.subplot(2, 2, idx)
coef = model.coef_[0]
coef_abs = np.abs(coef)
# 按重要性排序
sorted_idx = np.argsort(coef_abs)[::-1][:15] # 只显示前15个
sorted_coef = coef[sorted_idx]
sorted_names = [feature_names[i] for i in sorted_idx]
colors = ['red' if c > 0 else 'blue' for c in sorted_coef]
plt.barh(range(len(sorted_coef)), coef_abs[sorted_idx], color=colors)
plt.yticks(range(len(sorted_coef)), sorted_names)
plt.xlabel('系数绝对值', fontsize=12)
plt.title(f'{name}特征重要性 (非零系数: {n_nonzero})', fontsize=14)
plt.grid(True, alpha=0.3, axis='x')
else:
# 绘制混淆矩阵
plt.subplot(2, 2, idx)
cm = confusion_matrix(y_test, y_test_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('预测标签', fontsize=12)
plt.ylabel('真实标签', fontsize=12)
plt.title(f'{name}混淆矩阵\n准确率: {test_acc:.2%}', fontsize=14)
plt.tight_layout()
plt.savefig('./images/credit_card_model_comparison.png', dpi=300, bbox_inches='tight')
plt.show()
# 创建结果DataFrame
results_df = pd.DataFrame(results)
return results_df
results_df = compare_classification_models()
print(results_df)结果如下:
7.3 LASSO逻辑回归调参实战
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegressionCV, LogisticRegression
from sklearn.model_selection import learning_curve
from sklearn.metrics import roc_curve, auc, roc_auc_score
def lasso_logistic_tuning():
"""在信用卡欺诈数据上对LASSO逻辑回归进行调参"""
from sklearn.linear_model import LogisticRegressionCV
from sklearn.model_selection import learning_curve
from sklearn.metrics import roc_curve, auc
# 使用LogisticRegressionCV选择最优C(正则化强度的倒数)
lasso_cv = LogisticRegressionCV(
Cs=np.logspace(-4, 2, 20), # C值范围
penalty='l1', # L1正则化
solver='liblinear', # 支持L1正则化的求解器
cv=5, # 5折交叉验证
max_iter=1000,
scoring='roc_auc', # 使用AUC作为评估指标
random_state=42
)
lasso_cv.fit(X_train_scaled, y_train)
# 最优模型
best_lasso = LogisticRegression(
penalty='l1',
C=lasso_cv.C_[0], # 最优C值
solver='liblinear',
max_iter=1000,
random_state=42
)
best_lasso.fit(X_train_scaled, y_train)
# 绘制学习曲线
train_sizes, train_scores, test_scores = learning_curve(
best_lasso, X_train_scaled, y_train, cv=5,
train_sizes=np.linspace(0.1, 1.0, 10),
scoring='roc_auc'
)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.figure(figsize=(12, 10))
# 学习曲线
plt.subplot(2, 2, 1)
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1, color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="训练AUC")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="验证AUC")
plt.xlabel("训练样本数", fontsize=12)
plt.ylabel("AUC分数", fontsize=12)
plt.title(f"LASSO逻辑回归学习曲线 (C={lasso_cv.C_[0]:.4f})", fontsize=14)
plt.legend(loc="best")
plt.grid(True, alpha=0.3)
# 特征重要性
plt.subplot(2, 2, 2)
# 获取系数
coef = best_lasso.coef_[0]
coef_abs = np.abs(coef)
# 按重要性排序
sorted_idx = np.argsort(coef_abs)[::-1][:15] # 只显示前15个
sorted_coef = coef[sorted_idx]
sorted_names = [feature_names[i] for i in sorted_idx]
colors = ['red' if c > 0 else 'blue' for c in sorted_coef]
plt.barh(range(len(sorted_coef)), coef_abs[sorted_idx], color=colors)
plt.yticks(range(len(sorted_coef)), sorted_names)
plt.xlabel('系数绝对值', fontsize=12)
plt.title('LASSO逻辑回归特征重要性排序', fontsize=14)
plt.grid(True, alpha=0.3, axis='x')
# ROC曲线
plt.subplot(2, 2, 3)
# 计算ROC曲线
y_test_proba = best_lasso.predict_proba(X_test_scaled)[:, 1]
fpr, tpr, _ = roc_curve(y_test, y_test_proba)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC曲线 (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--', label='随机分类器')
plt.xlabel('假正率', fontsize=12)
plt.ylabel('真正率', fontsize=12)
plt.title('LASSO逻辑回归ROC曲线', fontsize=14)
plt.legend(loc="lower right")
plt.grid(True, alpha=0.3)
# 正则化路径
plt.subplot(2, 2, 4)
# 提取交叉验证结果
C_values = lasso_cv.Cs_
mean_scores = np.mean(lasso_cv.scores_[1], axis=0)
std_scores = np.std(lasso_cv.scores_[1], axis=0)
plt.plot(C_values, mean_scores, 'b-', lw=2, label='平均CV AUC')
plt.fill_between(C_values, mean_scores - std_scores, mean_scores + std_scores, alpha=0.2, color='blue')
plt.axvline(x=lasso_cv.C_[0], color='r', linestyle='--', label=f'最优C: {lasso_cv.C_[0]:.4f}')
plt.xscale('log')
plt.xlabel('正则化参数 C (1/λ)', fontsize=12)
plt.ylabel('交叉验证AUC', fontsize=12)
plt.title('LASSO逻辑回归正则化路径', fontsize=14)
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('./images/lasso_logistic_tuning.png', dpi=300, bbox_inches='tight')
plt.show()
# 打印结果
print(f"最优C值: {lasso_cv.C_[0]:.6f}")
print(f"非零系数个数: {np.sum(np.abs(best_lasso.coef_) > 1e-4)}")
print(f"训练集AUC: {roc_auc_score(y_train, best_lasso.predict_proba(X_train_scaled)[:, 1]):.4f}")
print(f"测试集AUC: {roc_auc:.4f}")
# 显示最重要的特征
print("\n最重要的5个特征:")
for i in range(min(5, len(sorted_idx))):
idx = sorted_idx[i]
print(f" {feature_names[idx]}: {best_lasso.coef_[0][idx]:.4f}")
# 与真实系数比较(仅限模拟数据)
if 'true_coef' in locals():
selected_features = np.where(np.abs(best_lasso.coef_[0]) > 1e-4)[0]
true_features = np.where(np.abs(true_coef) > 1e-4)[0]
correct_selected = np.intersect1d(selected_features, true_features)
false_selected = np.setdiff1d(selected_features, true_features)
missed_features = np.setdiff1d(true_features, selected_features)
print(f"\n特征选择性能:")
print(f" 正确选择的特征: {len(correct_selected)}/{len(true_features)}")
print(f" 错误选择的特征: {len(false_selected)}")
print(f" 漏选的真正特征: {len(missed_features)}")
return best_lasso, lasso_cv.C_[0]
best_lasso, best_C = lasso_logistic_tuning()结果如下:
第八章:总结与展望
8.1 LASSO的优势与局限
| 维度 | 优势 | 局限 |
|---|---|---|
| 特征选择 | 自动进行变量选择,产生稀疏解 | 当 p > n p>n p>n时,最多选择 n n n个变量 |
| 可解释性 | 模型简单,特征重要性明确 | 相关性强的特征中可能随机选择一个 |
| 计算效率 | 有高效算法(坐标下降、LARS) | 非凸推广(如SCAD)计算复杂 |
| 理论性质 | 在一定条件下具有Oracle性质 | 需要严格的"不可表示条件" |
8.2 LASSO的变体与扩展
- 弹性网络(Elastic Net) :结合L1和L2正则化,处理高度相关特征
minβ12n∥y−Xβ∥2+λ(α∥β∥1+12(1−α)∥β∥22)minβ 2n 1∥y −Xβ ∥2+λ (α ∥β ∥1+21(1−α )∥β∥22) - 分组LASSO(Group LASSO) :将变量分组,进行组级选择
minβ12n∥y−Xβ∥2+λ∑g=1Gpg∥βg∥2minβ 2n 1∥y −Xβ ∥2+λ ∑g =1G p**g ∥β**g∥2 - 稀疏组LASSO:同时进行组间和组内选择
- SCAD(Smoothly Clipped Absolute Deviation):非凸惩罚,具有更好的理论性质
8.3 何时使用LASSO?
- 高维数据(p≈n或p>n):特征选择至关重要时
- 可解释性要求高:需要知道哪些特征真正重要
- 多重共线性存在:但需要选择代表性特征而非全部压缩
- 实时预测系统:稀疏模型预测速度更快
8.4 实战建议
- 总是先进行特征标准化
- 使用交叉验证选择λ,考虑λ_min和λ_1se
- 对于高度相关特征,考虑弹性网络
- 使用稳定性选择提高鲁棒性
- 结合领域知识解释选择结果
8.5 前沿趋势
- 大数据下的分布式LASSO:应对海量特征
- 在线LASSO:流数据环境下的增量学习
- 深度学习与LASSO结合:神经网络中的稀疏连接
- 因果推断中的LASSO:高维因果模型选择
最终建议:LASSO不仅是回归工具,更是理解高维数据结构的窗口。通过稀疏性假设,它帮助我们透过噪声看到本质。在深度学习盛行的今天,LASSO所代表的稀疏建模思想仍在迁移学习、注意力机制等领域焕发新生。掌握LASSO,就是掌握了一种从复杂中寻找简洁的思维方式。
:将变量分组,进行组级选择
minβ12n∥y−Xβ∥2+λ∑g=1Gpg∥βg∥2minβ 2n 1∥y −Xβ ∥2+λ ∑g =1G*p g∥ β**g*∥2
-
稀疏组LASSO :同时进行组间和组内选择
-
SCAD(Smoothly Clipped Absolute Deviation):非凸惩罚,具有更好的理论性质
8.3 何时使用LASSO?
- 高维数据(p≈n或p>n):特征选择至关重要时
- 可解释性要求高:需要知道哪些特征真正重要
- 多重共线性存在:但需要选择代表性特征而非全部压缩
- 实时预测系统:稀疏模型预测速度更快
8.4 实战建议
- 总是先进行特征标准化
- 使用交叉验证选择λ,考虑λ_min和λ_1se
- 对于高度相关特征,考虑弹性网络
- 使用稳定性选择提高鲁棒性
- 结合领域知识解释选择结果
8.5 前沿趋势
- 大数据下的分布式LASSO:应对海量特征
- 在线LASSO:流数据环境下的增量学习
- 深度学习与LASSO结合:神经网络中的稀疏连接
- 因果推断中的LASSO:高维因果模型选择
最终建议:LASSO不仅是回归工具,更是理解高维数据结构的窗口。通过稀疏性假设,它帮助我们透过噪声看到本质。在深度学习盛行的今天,LASSO所代表的稀疏建模思想仍在迁移学习、注意力机制等领域焕发新生。掌握LASSO,就是掌握了一种从复杂中寻找简洁的思维方式。
笔记来源:段同学