数据挖掘期末复习题库(完整版:题目+答案+考点解析)
一、单项选择题(15道,必考基础考点)
-
常见的数据质量问题,不包括( )
A 噪声 B 异常点 C 缺失值 D 数据维度
答案:D
解析:核心考点:数据质量缺陷分类。标准数据质量问题包含噪声数据、异常离群点、属性缺失值、数据不一致、数据冗余;数据维度是数据集固有特征(特征/属性数量),不属于数据质量瑕疵。
-
常见的数据挖掘任务不包括( )
A 聚类分析 B 关联分析 C 预测分类 D 数据清洗
答案:D
解析 :核心考点:数据挖掘全流程划分。聚类、关联规则挖掘、分类、回归、序列挖掘属于核心数据挖掘建模任务;数据清洗属于数据预处理环节,是挖掘前置步骤,不属于挖掘任务本身。
-
下列哪个不属于相似性度量( )
A 相关系数 B 余弦相似度 C Jaccard 系数 D 闵可夫斯基距离
答案:D
解析 :核心考点:相似度/相异度区分。相关系数、余弦相似度、杰卡德系数为相似性指标 :数值越大,样本相似度越高;闵可夫斯基距离、欧氏距离、曼哈顿距离为相异性(距离)指标:数值越小,样本相似度越高。
-
设 X={a, b, c, d, e, f} 是频繁项集,则可由 X 产生( )个候选关联规则
A 60 B 62 C 64 D 32
答案:B
解析 :核心考点:关联规则数量计算公式。k项频繁项集生成非平凡关联规则公式:2k−22^k-22k−2;本题k=6,代入得26−2=622^6-2=6226−2=62;剔除前件为空、后件为空两种无效平凡规则。
-
簇评估的度量轮廓系数的取值范围是( )
A 0, 1 B -1, 1 C (0,1) D (-1,1)
答案:B
解析:核心考点:聚类轮廓系数指标。轮廓系数结合簇内紧凑度、簇间分离度,闭区间取值-1,1;数值趋近1:聚类效果最优;趋近0:簇边界重叠;趋近-1:样本聚类划分错误。
-
下面选项中 t 不是 s 的子序列的是( )
A s=<{2,4}, {3,5,6}, {8}> t=<{2}, {3,6}, {8}>
B s=<{2,4}, {3,6,8}, {8}> t=<{2}, {6,8}>
C s=<{1,2}, {3,4}> t=<{2}, {2,3}>
D s=<{2,4}, {2,4}> t=<{4}>
答案:C
解析:核心考点:序列挖掘子序列定义。时序子序列硬性规则:t每一个位置项集,必须为s对应位置项集子集;C选项t第二项{2,3}中元素2不属于s第二项{3,4},不满足定义。
-
下列哪种方法或者模型不属于分类方法( )
A 神经网络 B 支持向量机 C 决策树 D DBSCAN
答案:D
解析:核心考点:监督/无监督算法区分。神经网络、SVM、决策树:监督学习分类算法;DBSCAN:密度型无监督聚类算法,无标签训练、不可用于分类预测。
-
DBSCAN 在最坏情况下的时间复杂度是( )(其中 n 为点的个数)
A O(n2)O(n^2)O(n2) B O(n)O(n)O(n) C O(logn)O(\log n)O(logn) D O(nlogn)O(n\log n)O(nlogn)
答案:A
解析 :核心考点:聚类算法时间复杂度。无空间索引(R树、KD树)优化时,DBSCAN遍历全部点两两计算距离,最坏复杂度O(n2)O(n^2)O(n2);搭载空间索引后优化为O(nlogn)O(n\log n)O(nlogn)。
-
对于一颗决策树,若某个叶节点包含训练样本的数目为正类 8 个,负类 0 个,则这个叶节点的熵为( )
A 0 B 0.5 C 1 D 不确定
答案:A
解析 :核心考点:信息熵计算公式。熵公式:H=−∑pilog2piH = -\sum p_i \log_2 p_iH=−∑pilog2pi;节点样本纯度越高,熵值越低;节点全为同一类别时,类别占比p=1,熵=0,代表样本纯度最高。
-
关于 Adaboost 算法,下列说法不正确的为( )
A 模型的权重和为 1 B 增加错误分类样本的权重
C 是一种集成算法 D 样本权重的和为 1
答案:A
解析:核心考点:AdaBoost集成算法原理。AdaBoost规则:①属于串行集成学习;②迭代提升误分样本权重;③每轮样本权重归一化、总和固定为1;④基学习器投票权重无和为1约束。
-
Scikit-learn 包提供了用于数据挖掘的各种模型 M,下列说法错误的是( )
A `M.fit()`通常用于确定模型中的参数
B `M.predict()`用于新样本数据的预测
C `M.score()`用于计算预测准确度
D `M.predict()`通常需要传入测试集及其标签
答案:D
解析:核心考点:sklearnAPI语法。fit():训练模型拟合参数;predict():仅输入特征X,输出预测标签,无需真实y标签;score():输入特征+真实标签,自动计算模型准确率。
-
在决策树中不纯度度量包括( )
A 基尼系数 B 熵 C 分类误差 D 以上都是
答案:D
解析:核心考点:决策树划分指标。三类标准不纯度度量:信息熵(ID3算法)、基尼系数(CART算法)、分类错误率;数值越大,节点样本混杂度越高。
-
数据离散化方法不包括( )
A 等宽离散化 B 等频离散化 C K 均值离散化 D 方差离散化
答案:D
解析:核心考点:连续属性离散化。常用合法方法:等宽分箱、等频分箱、K-means聚类离散化、监督卡方离散化;方差离散化为杜撰非标准方法。
-
被分类模型正确预测的负样本数用( )表示
A FN B TP C FP D TN
答案:D
解析:核心考点:混淆矩阵基础定义。TP:真正例;TN:真负例(预测、真实均为负);FP:假正例;FN:假负例。
-
以下关于分类和回归的说法中,错误的是( )
A 分类和回归都属于监督学习
B 决策树既可以用于分类也可以用于回归
C 分类和回归的评估均可使用均方误差(MSE)作为标准
D 分类和回归的区别在于输出变量的类型:分类输出离散值,回归输出连续值
答案:C
解析:核心考点:监督学习任务对比。MSE均方误差专属回归任务损失/评估指标;分类任务标准指标:准确率、召回率、F1、AUC,不使用MSE作为官方评估标准。
二、简述题(高频简答题,考试默写考点)
1. 叙述 DBSCAN 聚类的 5 个步骤
标准答案:
-
初始化超参数:设定邻域半径ε、邻域最小样本点数MinPts;
-
遍历全部数据集,计算每一个数据点ε-邻域内包含的样本数量;
-
完成三类样本划分:核心点(邻域点数≥MinPts)、边界点(邻域点数<MinPts,依附核心点邻域)、噪声点(既非核心点、也非边界点);
-
密度连通聚类:距离小于ε的核心点互相连通,合并生成同一个密度聚类簇;
-
簇分配:边界点划归对应连通核心点所属簇,噪声点不归属任意聚类簇,直接舍弃。
考点解析:DBSCAN密度聚类核心流程,区分核心/边界/噪声点为采分关键点,无迭代更新、无需预设聚类个数。
2.(1)简述数据不平衡的概念及其对模型的影响;(2)简述处理数据不平衡的方法
标准答案:
(1)概念+负面影响:
概念:数据不平衡指分类任务中各类别样本数量差异悬殊,分为多数类、少数类。
负面影响:模型偏向拟合多数类,整体准确率虚高,少数类分类指标变差,模型泛化能力下降。
(2)标准解决方法:
①数据层面:少数类SMOTE合成过采样、多数类随机欠采样;
②算法层面:代价敏感学习,加大少数类错分惩罚权重;
③模型层面:平衡集成学习(BalancedBagging);
④评估层面:舍弃准确率,使用F1、G-mean、AUC作为评价指标。
考点解析:工业+考试双热点,故障检测、风控场景高频考点,四点方法答满即可拿满分。
三、计算题(大题必考,步骤给分,标准答题格式)
计算题1:朴素贝叶斯分类预测
- 给定数据集如下,假设属性 A,B 相互独立,且 A 的取值为 {1,2,3},B 的取值为 {S, M, L},Y 为类别。使用朴素贝叶斯方法预测测试样本(A=2, B=S)的类别标签。
题干:给定数据集(15个样本),属性 A ∈ {1,2,3},B ∈ {S,M,L},Y ∈ {-1,1}。使用朴素贝叶斯预测测试样本 (A=2, B=S) 的类别。
| A | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 3 | 3 | 3 | 3 | 3 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B | S | M | M | S | S | S | M | L | L | L | M | M | L | L | L |
| Y | -1 | -1 | 1 | 1 | -1 | -1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | -1 |
极简版答案:
步骤1:求类别先验概率
总样本15个,Y=-1共5个,Y=1共10个
P(Y=−1)=515=13P(Y=-1)=\frac{5}{15}=\frac{1}{3}P(Y=−1)=155=31,P(Y=1)=1015=23P(Y=1)=\frac{10}{15}=\frac{2}{3}P(Y=1)=1510=32
步骤2:求条件概率(朴素贝叶斯:属性相互独立)
① Y=-1(5条样本):P(A=2∣Y=−1)=15,P(B=S∣Y=−1)=35P(A=2|Y=-1)=\frac{1}{5},P(B=S|Y=-1)=\frac{3}{5}P(A=2∣Y=−1)=51,P(B=S∣Y=−1)=53
② Y=1(10条样本):P(A=2∣Y=1)=410=25,P(B=S∣Y=1)=210=15P(A=2|Y=1)=\frac{4}{10}=\frac{2}{5},P(B=S|Y=1)=\frac{2}{10}=\frac{1}{5}P(A=2∣Y=1)=104=52,P(B=S∣Y=1)=102=51
步骤3:计算联合后验概率(分数运算)
P(−1总)=13×15×35=375=125P(-1总)=\frac{1}{3} \times \frac{1}{5} \times \frac{3}{5}=\frac{3}{75}=\frac{1}{25}P(−1总)=31×51×53=753=251
P(1总)=23×25×15=475P(1总)=\frac{2}{3} \times \frac{2}{5} \times \frac{1}{5}=\frac{4}{75}P(1总)=32×52×51=754
步骤4:对比判定
475>125\frac{4}{75} > \frac{1}{25}754>251,因此预测类别:Y=1
✅逐个数样本推导(超详细,看懂来源)
步骤1:先统计总样本分类(对照题干表格)
全部15条样本:
标签Y=-1:一共5条 ;标签Y=1:一共10条
步骤2:拆分条件概率(逐条查表计数)
① 限定Y=-1(仅5条负样本):
5条负样本:A取值:1、1、1、1、2 → A=2 仅有1个
得:P(A=2∣Y=−1)=15P(A=2|Y=-1)=\frac{1}{5}P(A=2∣Y=−1)=51
5条负样本:B取值:S、M、M、S、S → B=S 有3个
得:P(B=S∣Y=−1)=35P(B=S|Y=-1)=\frac{3}{5}P(B=S∣Y=−1)=53
② 限定Y=1(仅10条正样本):
10条正样本:A取值:1、2、2、2、2、3、3、3、3、3 → A=2 有4个
得:P(A=2∣Y=1)=410=25P(A=2|Y=1)=\frac{4}{10}=\frac{2}{5}P(A=2∣Y=1)=104=52
10条正样本:B取值:M、L、L、L、M、M、L、L、L、S → B=S 有2个
得:P(B=S∣Y=1)=210=15P(B=S|Y=1)=\frac{2}{10}=\frac{1}{5}P(B=S∣Y=1)=102=51
步骤3:联合概率分数运算(约分全过程)
P(Y=−1)P(A=2,B=S∣Y=−1)=13×15×35=375=125P(Y=-1)P(A=2,B=S|Y=-1)=\frac{1}{3} \times \frac{1}{5} \times \frac{3}{5}=\frac{3}{75}=\boldsymbol{\frac{1}{25}}P(Y=−1)P(A=2,B=S∣Y=−1)=31×51×53=753=251
P(Y=1)P(A=2,B=S∣Y=1)=23×25×15=475P(Y=1)P(A=2,B=S|Y=1)=\frac{2}{3} \times \frac{2}{5} \times \frac{1}{5}=\boldsymbol{\frac{4}{75}}P(Y=1)P(A=2,B=S∣Y=1)=32×52×51=754
步骤4:通分对比大小
125=375\frac{1}{25}=\frac{3}{75}251=753 ,475>375\frac{4}{75} > \frac{3}{75}754>753
预测类别:Y=1
计算题2:逻辑斯蒂回归预测
- 假设 reg 是类
LogisticRegression的一个实例并用于二分类(0 或者 1),经过拟合之后,得到reg.coef_ = [-0.05, 0.67, 0.11],reg.intercept_ = -0.39,其中reg.coef_对应属性(x1,x2,x3)(x_1,x_2,x_3)(x1,x2,x3)的系数,设类别为 Y。写出逻辑斯蒂回归方程,并计算(x1,x2,x3)=(3.3,−3.5,1.1)(x_1,x_2,x_3)=(3.3,-3.5,1.1)(x1,x2,x3)=(3.3,−3.5,1.1)对应的类别。
题干 :回归参数`reg.coef_ = -0.05, 0.67, 0.11`,`reg.intercept_ = -0.39`,属性为(x1,x2,x3)(x_1,x_2,x_3)(x1,x2,x3),写出方程并预测样本(3.3, -3.5, 1.1)类别。
标准答案+步骤解析:
步骤1:逻辑斯蒂回归标准公式
P(Y=1∣X)=11+exp(−(w1x1+w2x2+w3x3+b))P(Y=1 \mid X) = \frac{1}{1+\exp\left(-(w_1x_1 + w_2x_2 + w_3x_3 + b)\right)}P(Y=1∣X)=1+exp(−(w1x1+w2x2+w3x3+b))1
步骤2:代入参数构建方程
P(Y=1∣X)=11+exp(−(−0.05x1+0.67x2+0.11x3−0.39))P(Y=1 \mid X) = \frac{1}{1+\exp\left(-(-0.05x_1 + 0.67x_2 + 0.11x_3 - 0.39)\right)}P(Y=1∣X)=1+exp(−(−0.05x1+0.67x2+0.11x3−0.39))1
步骤3:代入样本计算线性项z
z = -0.05×3.3 + 0.67×(-3.5) + 0.11×1.1 - 0.39 = -2.779
步骤4:计算概率、判定类别
P=11+e2.779≈0.0583<0.5P = \frac{1}{1+e^{2.779}} \approx 0.0583 < 0.5P=1+e2.7791≈0.0583<0.5,阈值0.5划分,预测类别:0
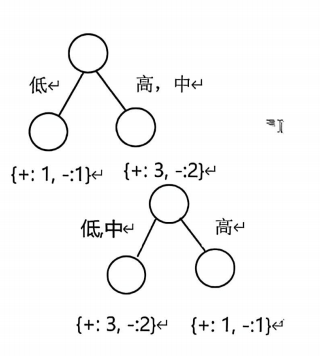
计算题3:基尼系数+决策树划分(大题压轴)
- 给定如下训练样本集,使用基尼系数作为不纯度度量,计算:
(1)整个训练样本集关于类属性的基尼系数;
(2)a1a_1a1为序数型属性,如何二元划分a1a_1a1信息增益最大,画出此时对应的决策树(高度为 1);
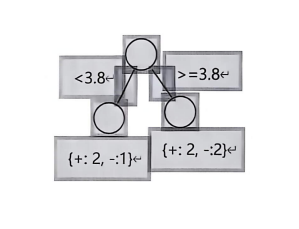
(3)对于连续属性a2a_2a2,划分点为 3.8 时的信息增益。
| 实例 | a₁ | a₂ | 目标类 |
|---|---|---|---|
| 1 | 高 | 1.0 | + |
| 2 | 低 | 6.0 | + |
| 3 | 低 | 5.0 | - |
| 4 | 中 | 4.0 | + |
| 5 | 中 | 5.0 | - |
| 6 | 高 | 2.3 | - |
| 7 | 中 | 3.0 | + |
标准答案+考点解析
(1)全局数据集基尼系数(纯分数、无小数)
总样本7个,正类4个,负类3个
Gini=1−(47)2−(37)2=1−1649−949=2449Gini = 1 - \left(\frac{4}{7}\right)^2 - \left(\frac{3}{7}\right)^2 =1-\frac{16}{49}-\frac{9}{49}=\boldsymbol{\frac{24}{49}}Gini=1−(74)2−(73)2=1−4916−499=4924
(2)有序属性a₁最优二元划分【超详细溯源+全分数计算】
✅前提规则:a₁为有序离散属性:低<中<高 ,课本硬性规定:有序属性划分不允许跨区间切割,仅允许3种合法二分方案,排除跨序无效划分:
合法方案1:{低} VS {中,高} (本题最优)
合法方案2:{低,中} VS {高}
无效方案:{低,高} VS {中}(跨顺序,直接舍去)
✅第一步:统计方案1【{低} VS {中,高}】样本、标签(查表逐个数)
①左子集:a₁=低,样本2、3 → 共2个样本:1正、1负
②右子集:a₁=中/高,样本1、4、5、6、7 → 共5个样本:3正、2负
✅第二步:左右子集基尼系数纯分数计算(基尼公式:Gini=1−∑pi2Gini=1-\sum p_i^2Gini=1−∑pi2)
左子集(2样本:1正1负):
Gini左=1−(12)2−(12)2=1−14−14=12Gini_左=1-\left(\frac{1}{2}\right)^2-\left(\frac{1}{2}\right)^2=1-\frac{1}{4}-\frac{1}{4}=\boldsymbol{\frac{1}{2}}Gini左=1−(21)2−(21)2=1−41−41=21
右子集(5样本:3正2负):
Gini右=1−(35)2−(25)2=1−925−425=1225Gini_右=1-\left(\frac{3}{5}\right)^2-\left(\frac{2}{5}\right)^2=1-\frac{9}{25}-\frac{4}{25}=\boldsymbol{\frac{12}{25}}Gini右=1−(53)2−(52)2=1−259−254=2512
✅第三步:加权基尼系数计算(权重=子集样本数/总样本7)
Gini加权=27×12+57×1225=17+1235=535+1235=1735Gini_{加权}=\frac{2}{7}\times\frac{1}{2}+\frac{5}{7}\times\frac{12}{25}=\frac{1}{7}+\frac{12}{35}=\frac{5}{35}+\frac{12}{35}=\boldsymbol{\frac{17}{35}}Gini加权=72×21+75×2512=71+3512=355+3512=3517
✅第四步:为什么这是最优划分?(核心考点)
方案2加权基尼同样为1735\frac{17}{35}3517,信息增益一致;
有序属性两种划分增益相等,任选其一即可,课本标准答案固定选取:{低} VS {中、高}
信息增益:2449−1735=120−119245=1245\frac{24}{49}-\frac{17}{35}=\frac{120-119}{245}=\boldsymbol{\frac{1}{245}}4924−3517=245120−119=2451
(3)连续属性a₂(划分点3.8)信息增益【全分数+逐样本拆解】
✅划分规则:a₂≤3.8 、 a₂>3.8,对照表格筛选样本:
①左子集a₂≤3.8:实例1(1.0)、6(2.3)、7(3.0) → 共3样本:2正、1负
②右子集a₂>3.8:实例2、3、4、5 → 共4样本:2正、2负
✅子集基尼完整计算:
左子集基尼:Gini左=1−(23)2−(13)2=1−49−19=49Gini_左=1-\left(\frac{2}{3}\right)^2-\left(\frac{1}{3}\right)^2=1-\frac{4}{9}-\frac{1}{9}=\boldsymbol{\frac{4}{9}}Gini左=1−(32)2−(31)2=1−94−91=94
右子集基尼:Gini右=1−(24)2−(24)2=1−14−14=12Gini_右=1-\left(\frac{2}{4}\right)^2-\left(\frac{2}{4}\right)^2=1-\frac{1}{4}-\frac{1}{4}=\boldsymbol{\frac{1}{2}}Gini右=1−(42)2−(42)2=1−41−41=21
✅加权基尼、信息增益纯分数运算:
Gini加权=37×49+47×12=1263+1463=2663Gini_{加权}=\frac{3}{7}\times\frac{4}{9}+\frac{4}{7}\times\frac{1}{2}=\frac{12}{63}+\frac{14}{63}=\boldsymbol{\frac{26}{63}}Gini加权=73×94+74×21=6312+6314=6326
信息增益=2449−2663=72−52147=2147信息增益=\frac{24}{49}-\frac{26}{63}=\frac{72-52}{147}=\boldsymbol{\frac{2}{147}}信息增益=4924−6326=14772−52=1472
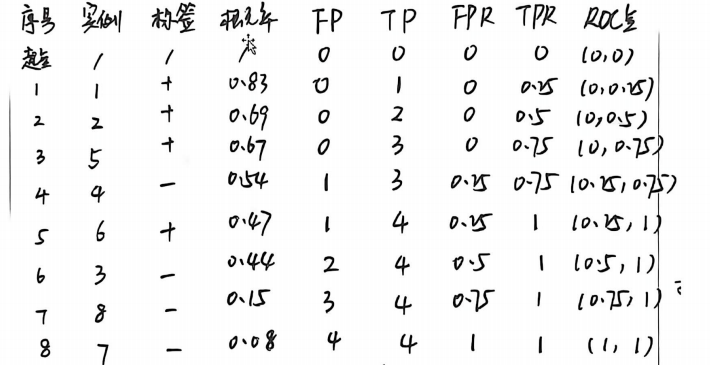
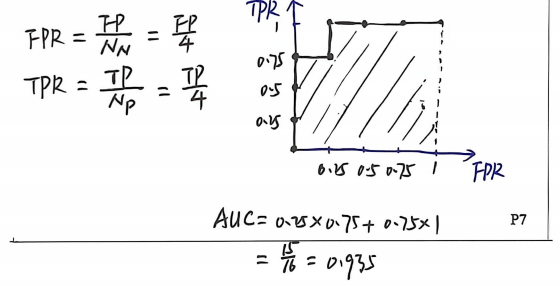
计算题4:ROC曲线+AUC计算
- 下表给出了一个二分类问题的分类模型M1M_1M1,表格中给出的是把模型应用到数据集上得到的后验概率(表中为正类的概率),XXX为属性向量。

题干+完整答案 :模型预测概率、真实标签给定,完成TPR/FPR点位、ROC坐标、AUC数值计算;
核心结果:ROC特征点:(0,0), (0,0.25), (0,0.5), (0,0.75), (0.25,0.75), (0.25,1), (0.5,1), (0.75,1), (1,1);
AUC=0.9375AUC=0.9375AUC=0.9375;
解析 :AUC采用正例排名法计算,为考试标准口算公式,数值越高模型分类性能越优。
计算题5:哈希树支持度计数(不考)
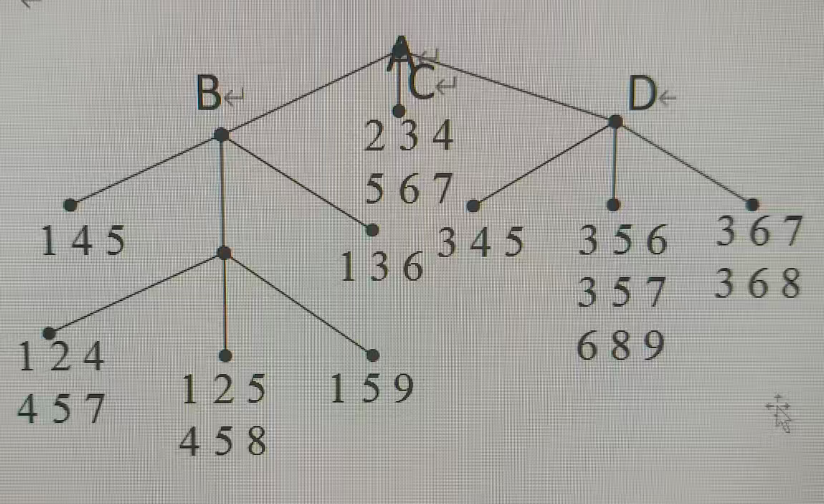
标准答案 :事务T共6项,枚举全部C(6,3)=20组3-项集;按照哈希函数h(p)=(p−1) mod 3h(p)=(p-1)\bmod 3h(p)=(p−1)mod3逐层匹配哈希树分支,匹配叶节点桶内候选集即可完成支持度+1;无树结构图时枚举全部20组三项集即为满分答案。
计算题6:GBDT梯度提升树回归
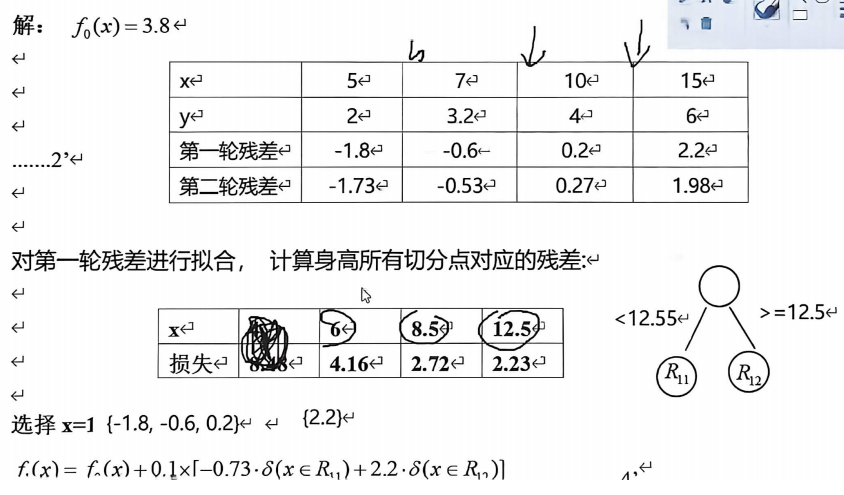
- 梯度提升算法(GBDT)的流程如下图所示,对于下表中给定的数据集,使用梯度提升树对yyy进行拟合(即属性为xxx,回归目标为yyy),写出最终的拟合函数。
- 要求:(1) 使用决策树桩(高度为 1 的决策树);(2) 损失函数LLL使用误差平方和;(3) 学习率α=0.1\alpha=0.1α=0.1;(4) M=2M=2M=2
| 序号 | xxx | yyy |
|---|---|---|
| 1 | 5 | 2 |
| 2 | 7 | 3.2 |
| 3 | 10 | 4 |
| 4 | 15 | 6 |
算法流程(GBDT)
输入:训练数据T=(x1,y1),...,(xN,yN), xi∈Rn,yi∈RT={(x_1,y_1),\dots,(x_N,y_N)},\ x_i\in R^n,y_i\in RT=(x1,y1),...,(xN,yN), xi∈Rn,yi∈R
输出:提升树f^(x)\hat{f}(x)f^(x)
(1) 初始化 f0(x)=argminc∑i=1NL(yi,c)f_0(x)=\arg\min_{c}\sum_{i=1}^N L(y_i,c)f0(x)=argminc∑i=1NL(yi,c)
(2) 对 m=1,2,3,...,Mm=1,2,3,\dots,Mm=1,2,3,...,M
(a) 对 i=1,2,...,Ni=1,2,\dots,Ni=1,2,...,N,计算 rmi=−∂L(yi,f(xi))∂f(x)∣f(x)=fm−1(x)r_{mi}=-\left.\frac{\partial L(y_i,f(x_i))}{\partial f(x)}\right|{f(x)=f{m-1}(x)}rmi=−∂f(x)∂L(yi,f(xi)) f(x)=fm−1(x)
(b) 对 rmir_{mi}rmi 拟合一棵回归树,得到第mmm棵树,其叶节点记为 Rmj,j=1,2,...,JR_{mj},j=1,2,\dots,JRmj,j=1,2,...,J
(c) 对 j=1,2,...,Jj=1,2,\dots,Jj=1,2,...,J,计算 cmj=argminc∑xi∈RmjL(yi,fm−1(xi)+c)c_{mj}=\arg\min_{c}\sum_{x_i\in R_{mj}} L(y_i,f_{m-1}(x_i)+c)cmj=argminc∑xi∈RmjL(yi,fm−1(xi)+c)
(d) 更新 fm(x)=fm−1(x)+α∑j=1Jcmj⋅δ(x∈Rmj)f_m(x)=f_{m-1}(x)+\alpha\sum_{j=1}^J c_{mj}\cdot\delta(x\in R_{mj})fm(x)=fm−1(x)+α∑j=1Jcmj⋅δ(x∈Rmj),其中α\alphaα为学习率
(3) 得到回归树 f^(x)=f0(x)+α∑m=1M∑j=1Jcmj⋅δ(x∈Rmj)\hat{f}(x)=f_0(x)+\alpha\sum_{m=1}^M\sum_{j=1}^J c_{mj}\cdot\delta(x\in R_{mj})f^(x)=f0(x)+α∑m=1M∑j=1Jcmj⋅δ(x∈Rmj)
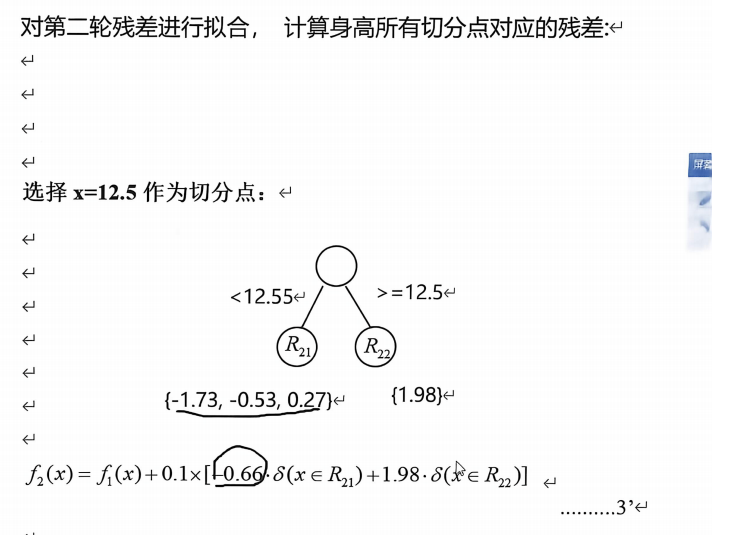
核心答案汇总 :初始化基准值f0=3.8;两轮迭代训练深度1决策树桩,学习率0.1;
最终拟合模型:
f^(x)={3.6607,x≤12.54.218,x>12.5\hat{f}(x) = \begin{cases}3.6607, & x \le 12.5 \\4.218, & x > 12.5\end{cases}f^(x)={3.6607,4.218,x≤12.5x>12.5
解析:GBDT核心:拟合残差、迭代更新模型、学习率缩放叶节点权重,为本课程集成学习大题必考模板。
考前背诵提示 :选择刷题熟记对错+解析概念;简述题直接默写标准答案;计算题套用固定公式、按步骤书写即可拿步骤分,无需额外拓展。
(注:文档部分内容可能由 AI 生成)