在现代数据架构中,数据血缘(Data Lineage)已经成为数据治理的核心能力。它帮助数据工程师追踪数据从源头到终点的完整流转路径,理解数据 transformations,识别数据质量问题的影响范围。LinkedIn 开源的 DataHub 是第三代数据目录平台的代表,它采用流式架构实现实时元数据管理,能够与 AWS Glue 和 dbt 无缝集成,构建完整的数据血缘图谱。
本文记录了搭建 DataHub、导入 Glue 元数据、并集成 dbt 和 spark 血缘的完整过程。
DataHub 概述
DataHub 是 LinkedIn 于 2020 年开源的第三代数据目录平台。与传统的第一代(Collibra)和第二代(Amundsen)数据目录相比,DataHub 具有以下显著特点:
首先,DataHub 采用流式架构设计。传统的元数据系统通常采用批处理模式,元数据更新存在延迟。而 DataHub 基于 Kafka 构建了实时元数据管道,元数据变更可以实时推送到下游系统,支持即时搜索和告警。
其次,DataHub 的核心组件包括:
- GMS(Generalized Metadata Service):核心元数据服务,提供 RESTful API 处理元数据的 CRUD 操作
- Frontend:前端界面,提供搜索、浏览、血缘可视化等功能
- Actions:可扩展的动作框架,支持元数据变更触发自定义工作流
- MySQL:存储结构化元数据(实体、关系、属性)
- OpenSearch:全文搜索引擎,提供高速的搜索和过滤能力
- Kafka:异步事件总线,解耦各组件,支持实时元数据变更推送
理解 DataHub 的架构设计对于正确运维至关重要。为什么已经有了 MySQL 还需要 OpenSearch?为什么需要 Kafka?
-
MySQL 存储结构化数据。元数据实体(如 Dataset、Container、Tag)及其关系需要强一致性的结构化存储,MySQL 擅长处理这类事务性操作。
-
OpenSearch 处理全文搜索。DataHub 需要支持按名称、描述、标签、所有者等多种维度进行搜索和过滤。OpenSearch 是基于 Lucene 的分布式搜索引擎,采用倒排索引结构,能够在海量元数据中实现毫秒级响应。
-
Kafka 作为异步事件总线。元数据变更是高频事件:表结构变更、权限变更、血缘更新等。通过 Kafka 解耦,生产者(GMS、ingestion 组件)和消费者(Actions、search indexer)可以独立扩展。Kafka 还支持消息回溯和重放,便于故障恢复和调试。
整体的DataHub 的架构示意图如下
访问层
存储层
核心服务层
消息层
消费事件
写入
索引
搜索查询
详情查询
元数据操作
元数据事件
数据摄入层
Glue Ingestion
dbt Ingestion
自定义 Ingestion
Kafka Broker
GMS 元数据服务
MySQL
OpenSearch
DataHub Frontend
REST API
上图展示了 DataHub 的数据流架构。数据从各种源(Glue、dbt、自定义)摄入后,首先发送到 Kafka,然后由 GMS 消费并处理。GMS 同时向 MySQL(主存储)和 OpenSearch(搜索索引)写入数据。读取路径上,前端界面通过 GMS 查询 OpenSearch 获取搜索结果,查询 MySQL 获取详细信息。
DataHub 的架构设计体现了现代数据平台的最佳实践。从数据流角度看,DataHub 分为以下几个层次:
- 数据源层:支持多种元数据源,包括 AWS Glue、dbt、Snowflake、BigQuery 等。每一类数据源都有对应的 ingestion recipe
- 摄入层:用户编写 YAML 格式的 recipe 配置文件,定义数据源和目标。DataHub CLI 读取 recipe 并执行摄入任务,支持元数据、Profiling、血缘、使用统计等多种采集类型
- 消息层:Kafka 作为异步事件总线,解耦摄入和处理。摄入的元数据首先发送到 Kafka,然后由 GMS 消费处理
- 核心服务层:GMS 是 DataHub 的核心,提供实体管理、血缘管理、搜索索引等能力
- 存储层:MySQL 存储元数据的持久化副本,OpenSearch 存储搜索索引。这种分离设计使得读写操作可以独立扩展
- 消费层:前端 UI、API 客户端和 Actions 框架都可以消费元数据
DataHub 的读写路径设计非常巧妙:
写路径:Ingestion → Kafka → GMS → MySQL(主存储)+ OpenSearch(索引)
读路径(搜索):UI → GMS → OpenSearch → 返回搜索结果
读路径(详情):UI → GMS → MySQL → 返回完整元数据
这种设计确保了搜索操作的高性能(通过 OpenSearch)和详情查询的数据一致性(通过 MySQL)。
Datahub部署
DataHub 提供 CLI 工具,用于元数据摄入、查询和管理。使用 uv 安装:
bash
uv add acryl-datahub --default-index https://mirrors.aliyun.com/pypi/simple/安装成功后版本为 acryl-datahub==1.6.0。
注意:在中国大陆环境下,pip 直连 Python 官方源(files.pythonhosted.org)和 Docker Hub 均会遇到超时问题。本文所有安装和镜像拉取均基于国内镜像源完成,完整的网络排障记录见第 9 节。
DataHub 采用 Docker 部署模式,需要拉取以下 7 个镜像(版本 v1.5.0.6):
- acryldata/datahub-gms:v1.5.0.6
- acryldata/datahub-frontend-react:v1.5.0.6
- acryldata/datahub-actions:v1.5.0.6-slim
- acryldata/datahub-upgrade:v1.5.0.6
- mysql:8.2
- opensearchproject/opensearch:2.19.3
- confluentinc/cp-kafka:8.0.0
配置好 Docker 镜像加速后即可正常拉取,网络问题排查详见第 9 节。
启动 DataHub,完整的启动命令如下:
bash
export DATAHUB_VERSION=v1.5.0.6
export DATAHUB_TOKEN_SERVICE_SIGNING_KEY=$(openssl rand -base64 32)
export DATAHUB_TOKEN_SERVICE_SALT=$(openssl rand -base64 32)
docker-compose -f ~/.datahub/quickstart/docker-compose.yml --profile quickstart up -d注意:DATAHUB_TOKEN_SERVICE_SIGNING_KEY 和 DATAHUB_TOKEN_SERVICE_SALT 是必需的环境变量,用于 token 签名服务。如果未设置,DataHub 可能无法正常启动或用户认证会失败。
访问地址为 http://localhost:9002,默认登录凭据为 datahub/datahub。
Recipe
Recipe 不只是"读元数据",它是一个可配置的元数据采集管道。根据 source 类型和配置项,DataHub Ingestion 可以采集以下信息:
| 采集类型 | 说明 | 配置方式 |
|---|---|---|
| 元数据 | 表名、Schema、列名、类型、分区 | 默认开启 |
| 数据 Profiling | 行数、null%、唯一值、最大最小值、分布统计 | 需配置 profiling.enabled |
| 数据血缘 | 表级 + 列级上下游关系 | 本次通过 dbt ingestion 实现 |
| 使用统计 | 查询频率、热门表、Top 用户 | 需配置 usage ingestion |
| 数据质量测试 | dbt test 结果、自定义断言 | 需 dbt run/test 生成 run_results |
| Schema 变更历史 | 列增删、类型变更的时间线 | 自动(每次摄入对比) |
| 所有权/描述 | Owner、描述、标签、Glossary 术语 | 部分自动,可手动补充 |
如需 Profiling,可在 Glue recipe 中添加:
yaml
source:
type: glue
config:
aws_region: "cn-north-1"
profiling:
enabled: true
profile_table_level_only: false # true 则只统计表级,不扫描列级分布Glue 元数据导入
AWS Glue 是 AWS 的托管 ETL 服务,其 Data Catalog 存储了数据湖中所有表的元数据。将 Glue 元数据导入 DataHub 是构建数据血缘的第一步。
首先需要安装 DataHub 的 Glue 摄入插件:
bash
uv pip install 'acryl-datahub[glue]'安装的依赖包括 cachetools、patchy、sqlglot、sqlglotc。sqlglot 是关键的依赖,用于解析 SQL 语句提取血缘信息。
摄入配置
创建摄入配置文件 ~/.datahub/glue_recipe.yml:
- Recipe 支持通过过滤模式限定采集范围,避免将整个 Glue Data Catalog 全量导入:
- 过滤规则支持正则表达式,
allow为白名单(只采集匹配的),deny为黑名单(排除匹配的),两者可以组合使用。如果不配置过滤,则默认采集 Glue 中的所有数据库和表。
yaml
source:
type: glue
config:
aws_region: "cn-north-1"
database_pattern:
allow:
- "raw_data"
- "dbt.*"
table_pattern:
deny:
- "^tmp_.*" # 排除临时表
- "^archive_.*" # 排除归档表
emit_storage_lineage: false
extract_transforms: false配置说明:
- aws_region:指定 AWS 区域为本实验的 cn-north-1
- database_pattern.allow :白名单过滤,只采集
raw_data和dbt开头的数据库(如 dbt_staging_data、dbt_finance) - emit_storage_lineage:是否发射存储层(S3)血缘,关闭以减少噪声
- extract_transforms:是否提取 Glue 转换器生成的元数据
- sink:目标为 DataHub REST API
注意 :早期版本使用
emit_s3_lineage,此参数已废弃。新版本应使用emit_storage_lineage替代。
执行摄入
运行 DataHub CLI 执行摄入:
bash
datahub ingest -c ~/.datahub/glue_recipe.yml执行结果:
Pipeline finished successfully; produced 107 events in 1 minute and 51.49 seconds.
- 3 databases: dbt_finance, dbt_staging_data, raw_data
- 18 tables scanned
- 0 failures, 0 warnings通过 database_pattern.allow 过滤后,仅导入了 raw_data、dbt_staging_data、dbt_finance 三个数据库,共 18 张表。其余 19 个数据库(如 glueworkshop、flink_cdc_db、lakeformation_tutorial 等)被过滤跳过。
注意:事件包括数据库实体、表实体、列实体、Schema 信息等。每个表会生成多个元数据事件。
导入结果如下
dbt 血缘集成
dbt(data build tool)是现代数据仓库常用的转换工具,它不仅定义数据模型,还记录了模型之间的转换关系。将 dbt 血缘导入 DataHub,可以将物理表与转换逻辑关联起来,形成完整的数据血缘链。
Glue 摄入导入的是物理表元数据(表名、列名、Schema、分区等),而 dbt 摄入导入的是转换逻辑和血缘关系。只有将两者结合,才能形成完整的血缘图谱:原始数据(Glue 中的 raw 表)→ dbt 转换(staging 模型)→ 报表模型。
关键配置是 target_platform: "athena",它告诉 DataHub 这些 dbt 模型对应的是 Athena 平台上的物理表,从而与 Glue 摄入的表建立关联。
生成 dbt 产物
在摄入 dbt 血缘之前,需要先运行 dbt docs generate 生成元数据产物。关于dbt的具体内容请参考(https://www.cnblogs.com/peacemaple/p/20081298)
bash
uv run dbt docs generate --profiles-dir ~/.dbt --project-dir /home/ec2-user/workspace/dbt/dbt_athena_workshop执行结果:
Found 10 models, 8 sources, 501 macros
Catalog written to target/catalog.json这表明 dbt 项目包含 10 个模型、8 个数据源和 501 个宏。catalog.json 包含了表的列信息,manifest.json 包含了模型之间的依赖关系。
注意:必须先运行 dbt docs generate,才能进行 DataHub 摄入。如果模型有变更,需要重新生成文档。
安装 dbt 插件
bash
uv pip install 'acryl-datahub[dbt]'编写 dbt Recipe
创建 ~/.datahub/dbt_recipe.yml:
yaml
source:
type: "dbt"
config:
manifest_path: "/home/ec2-user/workspace/dbt/dbt_athena_workshop/target/manifest.json"
catalog_path: "/home/ec2-user/workspace/dbt/dbt_athena_workshop/target/catalog.json"
run_results_paths:
- "/home/ec2-user/workspace/dbt/dbt_athena_workshop/target/run_results.json"
target_platform: "athena"
sink:
type: datahub-rest
config:
server: "http://localhost:8080"配置说明:
- manifest_path:dbt 生成的 manifest.json,包含模型依赖关系
- catalog_path:dbt 生成的 catalog.json,包含列级元数据
- run_results_paths:dbt 运行结果,包含测试执行信息
- target_platform:目标平台为 athena,与 Glue 摄入的表平台一致
执行摄入
bash
datahub ingest -c ~/.datahub/dbt_recipe.yml执行结果:
Pipeline finished successfully; produced 66 events in 3.86 seconds.
- 18 nodes: 10 Models + 8 Sources
- 28 upstream lineage edges
- 18 fine-grained (column-level) lineages
- SQL parser successes: 10
- 0 failures成功导入了 18 个节点(10 个模型 + 8 个数据源),28 条血缘边,18 条列级血缘。SQL 解析成功率为 100%。
注意 :日志中有一行提示 "The run results file is from a
dbt docs generatecommand, instead of a build/run/test command. Skipping this file." 这是预期行为。run_results.json 只有在运行 dbt build、dbt run 或 dbt test 后才会生成有意义的数据。从 dbt docs generate 生成的 run_results 不包含执行结果。
数据血缘链
完成 Glue 和 dbt 摄入后,DataHub 中形成了完整的数据血缘链。
典型的血缘链结构如下:
Reporting Layer
Staging Layer
dbt Source
Glue Catalog
原始数据层
Crawl
Crawl
映射
映射
SELECT *
SELECT *
JOIN
JOIN
S3: raw_data/
S3: raw_*
Glue Database
raw_data.raw_orders
raw_data.raw_customers
source: raw_orders
source: raw_customers
stg_orders
stg_customers
rpt_monthly_orders
rpt_customer_stats
从图中可以看到完整的数据流转:
- 原始数据层:S3 存储的原始数据文件
- Glue Catalog:通过 Glue Crawler 发现的表元数据
- dbt Source:dbt 中定义的 source,映射到 Glue 表
- Staging Layer:dbt 的 staging 模型,对原始数据做基本清洗
- Reporting Layer:dbt 的报表模型,供下游消费
血缘验证
在 DataHub UI 中,可以直观地查看血缘关系。
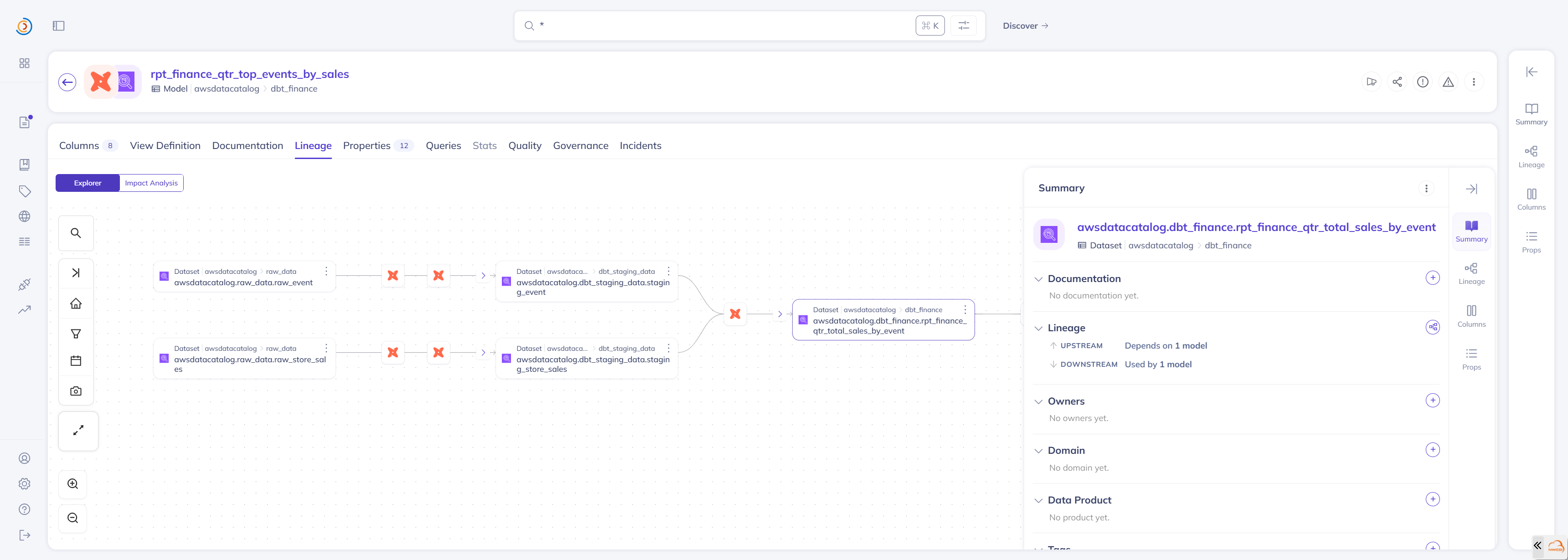
以一个报表模型为例:
- 上游依赖:可以追溯到原始的 Glue 表
- 列级血缘:可以查看每一列的来源和转换逻辑
- 影响分析:可以查看该模型影响的下游模型
这种端到端的血缘追踪能力,对于数据质量排查、变更影响分析、合规审计等场景都非常有价值。
Glue Job血缘集成
除了 dbt 的转换血缘,DataHub 还支持捕获 AWS Glue Spark Job 的实时血缘。这对于使用 Glue 进行 ETL 处理的场景非常有用。
DataHub 提供了一个轻量级的 Spark Listener(acryl-spark-lineage.jar),它监听 Spark 应用程序的事件(如 SQL 执行、作业开始/结束),并将血缘信息实时推送到 DataHub。
DataHub
目标
数据源
AWS Glue
read
read
write
push lineage
store
Spark Job
acryl-spark-lineage.jar
raw_data.raw_users
raw_data.raw_sales
spark_finance.spark_customer_sales
GMS Server
血缘图谱
从 Maven Central 下载 Spark Lineage JAR:
shell
# 下载 JAR(版本需与 Spark/Scala 版本匹配,Glue 3.0 使用 Spark 3.1 + Scala 2.12)
wget https://repo1.maven.org/maven2/io/acryl/acryl-spark-lineage_2.12/0.2.18/acryl-spark-lineage_2.12-0.2.18.jar
# 上传到 S3
aws s3 cp acryl-spark-lineage_2.12-0.2.18.jar s3://your-bucket/jars/ --region cn-north-1Spark Lineage 需要通过 Token 认证推送到 DataHub。需要启用 Token 认证:
# docker-compose.yml 中 GMS 服务添加环境变量
environment:
METADATA_SERVICE_AUTH_ENABLED: 'true'
TOKEN_SERVICE_ENABLED: 'true'重启 DataHub 后,通过 GraphQL API 生成 Token:
curl -X POST http://localhost:8080/api/graphql \
-H "Content-Type: application/json" \
-H "Authorization: Basic $(echo -n '__datahub_system:JohnSnowKnowsNothing' | base64)" \
-d '{"query":"mutation { createAccessToken(input: {actorUrn: \"urn:li:corpuser:datahub\", name: \"spark-lineage\", type: PERSONAL, duration: ONE_MONTH}) { accessToken }}"}'Glue Job 配置
Spark Listener 必须在 SparkSession 创建时就加载,因此配置必须通过 SparkSession.builder.config() 设置,而不是 Glue Job 参数。
java
from pyspark.sql import SparkSession
from awsglue.context import GlueContext
from awsglue.job import Job
# 1. 先创建 SparkSession(关键!)
spark = SparkSession.builder \
.appName("my-glue-job") \
.config("spark.extraListeners", "datahub.spark.DatahubSparkListener") \
.config("spark.datahub.rest.server", "http://<GMS_HOST>:8080") \
.config("spark.datahub.rest.token", "<YOUR_TOKEN>") \
.config("spark.datahub.metadata.dataset.materialize", "true") \
.config("spark.datahub.metadata.dataset.hivePlatformAlias", "glue") \
.getOrCreate()
# 2. 从 SparkSession 获取 SparkContext
sc = spark.sparkContext
# 3. 创建 GlueContext
glueContext = GlueContext(sc)
# 4. 初始化 Job
job = Job(glueContext)
job.init(args['JOB_NAME'], args)Glue Job 示例
配置参数说明
spark.datahub.metadata.dataset.materialize:是否自动创建数据集实体,默认 falsespark.datahub.metadata.dataset.hivePlatformAlias:设为glue时,表会被标记为 Glue 平台spark.datahub.stage_metadata_coalescing:设为true时延迟到 Job 结束时发送元数据(Glue 推荐设为false)
java
import sys
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
# 创建 SparkSession(带 DataHub Listener)
spark = SparkSession.builder \
.appName("spark_customer_sales_etl") \
.config("spark.extraListeners", "datahub.spark.DatahubSparkListener") \
.config("spark.datahub.rest.server", "http://172.31.14.46:8080") \
.config("spark.datahub.rest.token", "<TOKEN>") \
.config("spark.datahub.metadata.dataset.materialize", "true") \
.config("spark.datahub.metadata.dataset.hivePlatformAlias", "glue") \
.getOrCreate()
sc = spark.sparkContext
glueContext = GlueContext(sc)
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# 使用 Glue DynamicFrame 读取数据
users_dyf = glueContext.create_dynamic_frame.from_catalog(
database="raw_data",
table_name="raw_users"
)
users_df = users_dyf.toDF()
sales_dyf = glueContext.create_dynamic_frame.from_catalog(
database="raw_data",
table_name="raw_sales"
)
sales_df = sales_dyf.toDF()
# ETL 转换
customer_sales = sales_df.join(
users_df,
sales_df.buyerid == users_df.userid,
"left"
).groupBy(
users_df.userid.alias("customer_id"),
users_df.username.alias("customer_name")
).agg(
F.count("*").alias("total_orders"),
F.sum("pricepaid").alias("total_revenue"),
F.avg("pricepaid").alias("avg_order_value")
)
# 写入 S3
customer_sales.write.mode("overwrite").parquet(
"s3://your-bucket/tables/spark_finance/spark_customer_sales/"
)
job.commit()创建 Glue Job 时,需要指定 JAR 依赖。
shell
aws glue create-job \
--name "spark_customer_sales_etl" \
--role "arn:aws-cn:iam::<account>:role/AWSGlueServiceRole-all" \
--command Name=glueetl,ScriptLocation=s3://your-bucket/scripts/job.py,PythonVersion=3 \
--default-arguments '{
"--job-language": "python",
"--extra-jars": "s3://your-bucket/jars/acryl-spark-lineage_2.12-0.2.18.jar"
}' \
--glue-version "3.0" \
--number-of-workers 2 \
--worker-type "G.1X" \
--region cn-north-1血缘验证
在 DataHub UI 中查看血缘图谱如下