"在真实软件开发与部署环境中,同一份源代码可能因编译器版本、优化级别或目标架构的不同,而生成差异显著的中间表示或汇编代码。这种"编译差异"会导致现有漏洞检测模型在一个编译配置下有效,却在另一个配置下迅速失效。针对这一问题,研究团队提出了一种面向多编译结果的鲁棒漏洞检测方法,系统比较了LLVM-IR与 Assembly两种表示在跨编译场景下的稳定性,并基于 Transformer 架构构建统一检测模型,为"编译无关漏洞检测"提供了新的实证与方法论支撑。
📄 论文标题:Robust Vulnerability Detection across Compilations: LLVM-IR vs. Assembly with Transformer Model
📅 发表时间:Proceedings of the ACM on Software Engineering, ISSTA ,2025
🏫 作者单位:内盖夫本古里安大学
💡开源代码:
https://github.com/rvdac/rvdacLLVMIR_Assembly
01
---
方法介绍
该研究从"编译变化是否会破坏漏洞语义"这一核心问题出发,构建了统一的 Transformer 漏洞检测框架,并系统比较不同程序表示在多编译场景下的表现。
① 多编译版本构建
对同一漏洞样本在不同 优化级别(O0--O3)、不同目标平台下生成 LLVM-IR 与 Assembly。
② 程序表示建模
分别将 LLVM-IR 与汇编指令序列化为 token 序列,作为 Transformer 输入。
③ 编译鲁棒性评估
在"训练/测试编译配置不一致"的条件下评估模型性能下降情况。
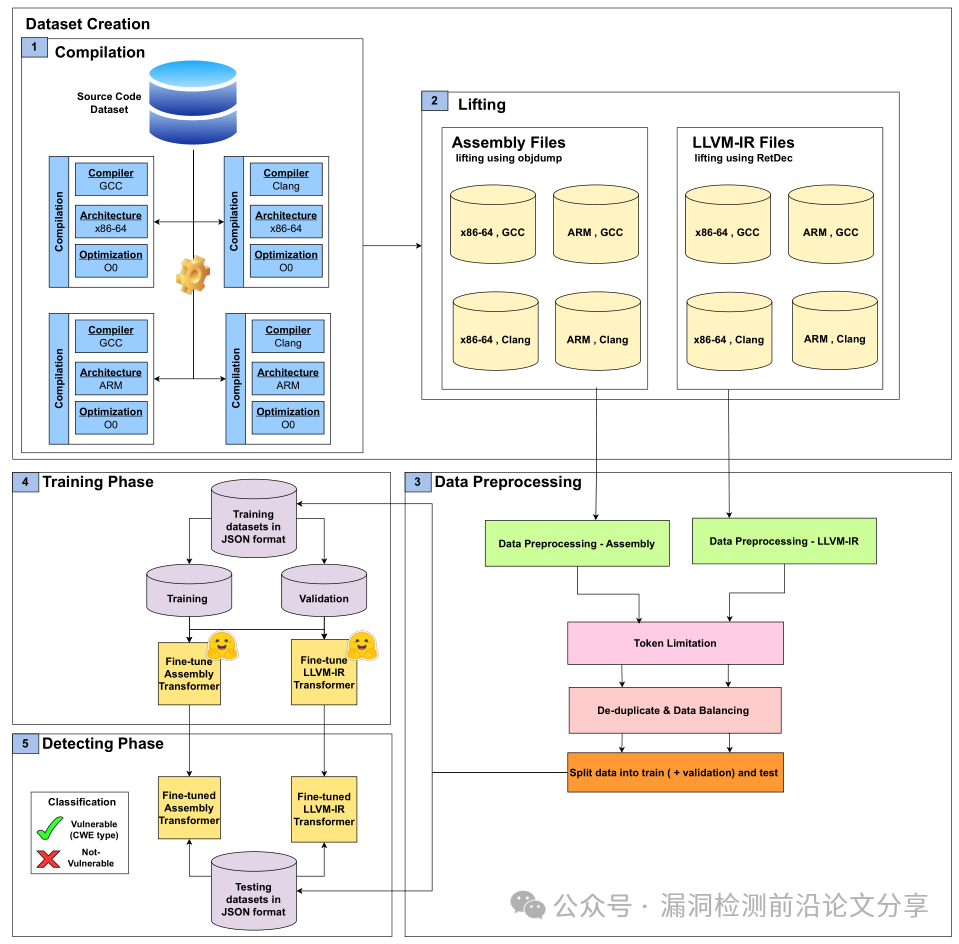
图 1. 方法框架
小结:该工作并非单纯提出新模型,而是系统回答了一个关键问题:哪种程序表示在跨编译场景下更稳定?
02
---
关键机制
1.LLVM-IR 显著优于 Assembly,在跨编译场景下,IR 表现出更强的语义稳定性。
2.编译优化是性能杀手,O0 → O3 会显著破坏基于汇编的漏洞模式。
3.Transformer 的优势,相比 CNN/RNN,更能适应指令级长程变化。
4.评估范式创新,强调"跨编译泛化"而非单一配置下的最高分数。
| 模块 | 实现方式 | 主要作用 |
|---|---|---|
| 多编译样本生成 | 不同编译优化级别生成 LLVM-IR 与 Assembly | 模拟真实部署中的编译差异 |
| 指令级序列建模 | IR / 汇编指令线性化为 token 序列 | 保留底层操作语义 |
| Transformer 编码器 | 多头自注意力建模长程依赖 | 捕获跨指令的漏洞语义模式 |
| 跨编译评估协议 | 训练与测试使用不同编译配置 | 衡量真实鲁棒性而非表面精度 |
小结:相比传统"同分布训练-测试",该评估方式更贴近工业实际。
03
---
实验结果
实验在Linux x86-64环境下进行,采用四种编译配置。其中两种配置基于x86-64架构,分别使用GCC和Clang进行编译,在多架构与多编译器环境下生成四套独特的编译配置,从而创建了四组不同的ELF数据集。实验比较了 LLVM-IR 与 Assembly 在跨编译场景下的检测效果(F1 / Accuracy)。
表1. 采用平衡方法(22个标签)后,Longformer与CodeBERT模型在LLVM-IR和汇编数据集上的性能对比

表2.Longformer与CodeBERT模型在LLVM-IR和汇编数据集上的性能对比(采用不同标记长度限制,共24个标签)
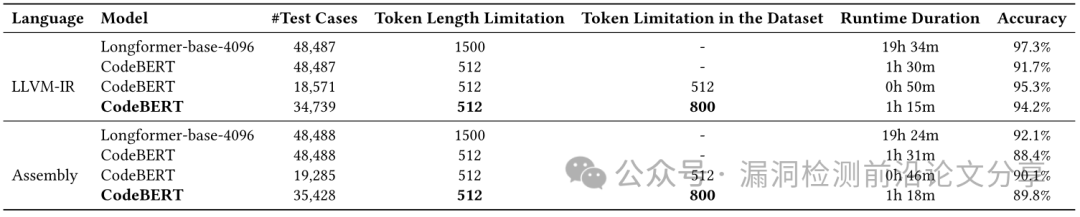
小结**: LLVM-IR 在漏洞检测中始终优于汇编语言,凸显其强大的鲁棒性。相比之下,800令牌限制使CodeBERT在保持高准确率(94.2%)的同时,将训练运行时间控制在合理范围(1小时15分钟),彰显其在效率与数据完整性之间实现最优权衡的能力。**
📌 总结
本文系统揭示了一个在漏洞检测领域长期被低估的问题:编译差异会显著影响模型可靠性 。通过实证分析,论文表明:1)LLVM-IR 是更适合鲁棒漏洞检测的中间表示。2)仅在单一编译配置下评估模型存在明显误导性。3)Transformer 架构在低层程序语义建模中具有明显优势。该工作为未来构建编译无关(compiler-agnostic)漏洞检测系统 提供了重要参考。
📣 欢迎留言讨论
-
你认为未来漏洞检测应更多依赖 LLVM-IR 这类中间表示,还是直接面向二进制?
-
跨编译评估是否应该成为漏洞检测论文的"标配实验"?
📌 点赞 + 收藏 + 分享,你的支持,是我们持续解析高水平软件安全论文的最大动力!