依旧参照该课程
概述
-
目的:弥补训练过程中模型知识的不足,提升模型在特定领域的表现,尤其涉及到了私有数据。
-
流程:
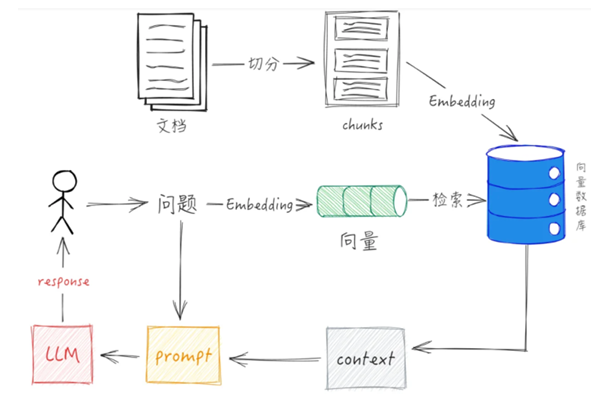
简言之就是:文本切分,向量化,存入库,查询时把问题向量化,按相似度查询,拿到相关文本输入到模型上下文中,生成回答。
- 如何向量化?有专用的embedding模型,其架构类似于transformer的编码器部分,输入文本,输出一个向量。(这里对应用来说不太重要)
准备工作
-
要在一个linux里安装docker,安装步骤:
- 首先需要一台虚拟机
CentOS7安装教程 - 然后windows远程连接测试
MobaXterm使用 - 安装
docker安装官方步骤 - 安装以后记得配置镜像
我用的毫秒镜像提供的脚本一键配置
- 首先需要一台虚拟机
-
然后选择一个向量数据库,可以选择
redis-stack,安装命令:
docker run -d --name redis-stack -p 6379:6379 -p 8001:8001 redis/redis-stack:latest在IDEAL中数据库新建一个redis数据源的,配置主机号(ifconfig查询),端口号(6379),用户密码都不用写,数据库写0,测试链接即可。
除了redis,还可以选择
elasticsearch、neo4j、oracle等向量数据库,springAI都提供了相应的starter依赖。 -
spring中引入 向量数据库 依赖:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-vector-store-redis</artifactId> </dependency> -
配置yml文件,连接向量数据库:
因为embedding模型deepseek没有,所以用的智谱的embedding模型,springai支持的embedding模型可以查阅官网
yamlspring: ai: zhipuai: api-key: 你的apikey embedding: options: model: embedding-3 dimensions: 256 deepseek: api-key: 你的apikey vectorstore: redis: initialize-schema: true prefix: "myrag:prefix" index-name: "myrag:index" data: redis: host: 你的主机号 port: 6379 password: 你的密码(如果有的话) server: port: 8080 servlet: encoding: charset: UTF-8 enabled: true force: true
VectorStore
通过流程发现,需要实现两个接口,一个是文本转向量加入数据库,一个是向量数据库的查询。引入了redis向量数据库依赖之后,自动在容器中添加了VectorStore的对象,这个对象可以实现这两个接口,直接调用即可。
java
package com.example.springai.controller;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
// 两个接口:文本转向量加入数据库,向量数据库的查询
@RestController
@RequestMapping("/rag")
public class RAGController {
// 引入了redis向量数据库依赖之后,自动在容器中添加了VectorStore的对象,这里直接注入即可
private final VectorStore vectorStore;
public RAGController(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
// 文本转向量加入数据库,调用vectorstore的add方法即可
@PostMapping("/add")
public String addTextToVectorStore(String text) {
Document document = Document.builder().text(text).build();
vectorStore.add(List.of(document));
return "added";
}
// 向量数据库的查询
@PostMapping("/query")
public List<Document> queryVectorStore(String query) {
SearchRequest searchRequest = SearchRequest.builder().topK(2).similarityThreshold(0.8) // 可以设置返回的结果数量和相似度阈值
.query(query).build();
List<Document> documents = vectorStore.similaritySearch(searchRequest); // 还可以继续.get(0).getText(),意思是获取list中第一个document的内容。
return documents;
}
}案例 - 智能客服
目标
准备一个csv文件作为知识库。把这个csv文件的每一行作为一个document对象,调用vectorStore.add()方法把它们加入向量数据库中,
构建一个advisor,在调用模型之前先从向量数据库中查询相关的document,把查询到的document加入到输入中,再调用模型生成回答。
准备
csv解析依赖、RAG依赖
这里我贴完csv之后不知道为什么org.apache.commons.csv.CSVFormat;里面csv或者CSVFormat交替爆红,怎么reload都不管用,后来发现把依赖删了重新再粘一下再reload就好了。。。
xml
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-csv</artifactId>
<version>1.10.0</version>
</dependency>
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>RAG实现
CoffeeController.java
java
package com.example.springai.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.ClassPathResource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.apache.commons.csv.CSVFormat;
import org.apache.commons.csv.CSVParser;
import org.apache.commons.csv.CSVRecord;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
@RestController
@RequestMapping("/coffee")
public class CoffeeController {
private final VectorStore vectorStore;
private final ChatClient chatClient;
public CoffeeController(
VectorStore vectorStore,ChatClient.Builder
chatClientBuilder)
{
this.vectorStore = vectorStore;
VectorStoreDocumentRetriever vectorStoreDocumentRetriever =
VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.topK(3)
.similarityThreshold(0.5)
.build();
RetrievalAugmentationAdvisor retrievalAugmentationAdvisor =
RetrievalAugmentationAdvisor.builder()
.documentRetriever(vectorStoreDocumentRetriever)
.build();
this.chatClient = chatClientBuilder
.defaultAdvisors(retrievalAugmentationAdvisor)
.build();
}
@GetMapping("/import")
public String importCSV() {
try {
// 读取classpath下的QA.csv文件
ClassPathResource resource = new ClassPathResource("QA.csv");
InputStreamReader reader = new
InputStreamReader(resource.getInputStream());
// 使用Apache Commons CSV解析CSV文件
CSVParser csvParser = CSVFormat.DEFAULT
.builder()
.setHeader() // 第一行作为标题
.setSkipHeaderRecord(true) // 跳过标题行
.build()
.parse(reader);
List<Document> documents = new ArrayList<>();
// 遍历每一行记录
for (CSVRecord record : csvParser) {
// 获取问题和回答字段
String question = record.get("问题");
String answer = record.get("回答");
// 将问题和回答组合成文档内容
String content = "问题: " + question + "\n回答: " + answer;
// 创建Document对象
Document document = new Document(content);
// 添加到文档列表
documents.add(document);
}
// 关闭解析器
csvParser.close();
// 将文档存入向量数据库
vectorStore.add(documents);
return "成功导入 " + documents.size() + " 条记录到向量数据库";
} catch (IOException e) {
e.printStackTrace();
return "导入失败: " + e.getMessage();
}
}
/**
* 新增的RAG问答接口,明确展示查询向量数据库的过程
* @param question 用户的问题
* @return AI基于检索到的信息生成的回答
*/
@GetMapping("/rag-ask")
public String ragAskQuestion(String question) {
// 先从向量数据库中检索相关信息
// 这里会使用RetrievalAugmentationAdvisor自动检索相关文档
// 将问题和检索到的上下文一起发送给AI模型生成回答
return chatClient.prompt()
.user(question)
.call()
.content();
}
}RetrievalAugmentationAdvisor流程:
- 构建初始 Query
从 ChatClientRequest 的用户消息、指令/历史和上下文构造一个 Query。 - 查询预处理:转换
按顺序应用 QueryTransformer 链对原始查询做转换(拼写、规范化、补充信息等)。 - 查询扩展
使用 QueryExpander 将一个查询扩展成多个候选查询(可选,多查询检索策略)。 - 并发检索
对每个扩展后的查询异步调用 DocumentRetriever.retrieve(通过 TaskExecutor 和 CompletableFuture 实现并发)。 getDocumentsForQuery 封装每个查询到文档集合的映射。 - 多源/多查询合并
将不同查询/数据源返回的文档集合交给 DocumentJoiner(默认 ConcatenationDocumentJoiner)合并成最终文档列表。 - 文档后处理
依次通过 DocumentPostProcessor 对文档做过滤、排序、去重或裁剪等处理。 把最终文档放入请求上下文(键为 rag_document_context)。 - 查询增强
使用 QueryAugmenter(默认 ContextualQueryAugmenter)把检索到的文档上下文注入到原始查询文本,生成增强后的用户提示。 - 更新请求并继续调用链
用增强后的文本构造新的 ChatClientRequest(通过 mutate()),并把文档上下文放入 context,然后返回给下游模型调用。 - 响应后处理(after)
在 after 中把上下文里的 rag_document_context 放入 ChatResponse.metadata,使得最终响应包含检索到的文档信息。