今天,看b站的论文解读,Mamba涉及到了一个parallel scan,是一个并行计算的机制。
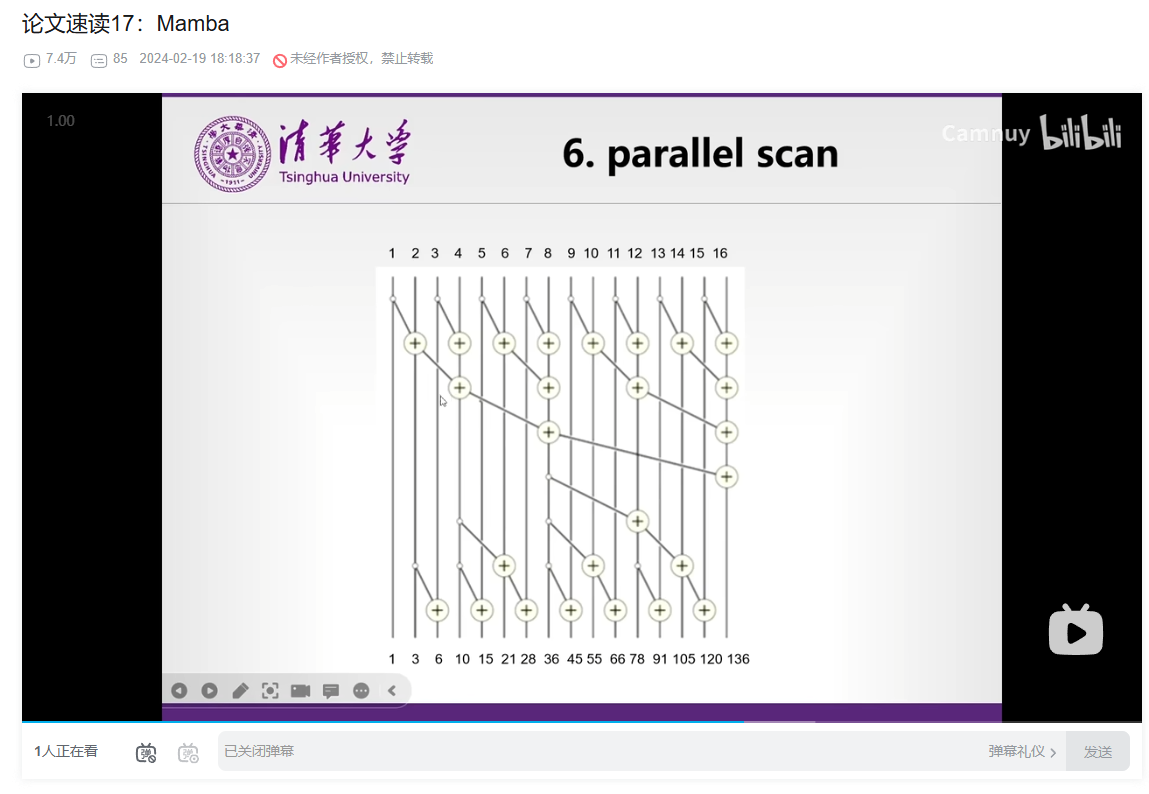
说实话,最开始这个点我确实没听懂。"这个加这个,然后再加那个"------这套逻辑从我个人视角看,不太容易转过来。我觉得主要原因在于人脑的思维习惯:人脑本身是一套极其复杂的并行系统,但注意力的切换和维持是有成本的1。正因如此,在面对某些具体的小问题时,人脑的思考路径和计算机的实际执行方式之间,会出现一种"割裂感"。理解 parallel scan 的过程,恰好就踩在了这道裂缝上。
拿一个简单的算术来说:1+1+2+4。我发现,不同人算这个的过程其实差异很大。有数字敏感的人可能不假思索就能说出结果;而像我这种对数字不太敏感的,就会下意识地去"凑对":先算 1+1=2,然后 2+2=4,再 4+4=8,最后得到 8。幼儿园的小朋友也许会依赖另一套更复杂的规则。这些是个体差异,但共同点在哪呢?------在具体执行这个加法任务时,人脑其实并不是并行处理,而是在串行地进行2。
再看计算机。多线程早已成为现代计算的亮点。只要设计得当,计算机处理并行问题时,"注意力成本"可以被压缩到极小。它完全可以同时进行 1+1=2 和 2+4=6,然后在下一步把这两个结果合起来 2+6=8。这时就会发现,计算机只用了两个时间步,而像我刚才那种串行凑对的算法用了三个时间步。差距就在这里体现出来。
那么 parallel scan 又是怎样在这个基础上继续加速的呢?
其实它做的事情,本质上就是把"很多个连续的加法步骤"重新组织,让它们能并行完成。还是用前面的加法序列,但这次我们算的是前缀和:给定输入 [1, 1, 2, 4],希望得到 [1, 2, 4, 8],其中每个位置都是前面所有数的累积和。如果完全串行计算,就需要一步步累加,时间步数等于序列长度。但并行扫描可以把这些步骤拆开、重新结合。例如 Blelloch 算法会分成两个阶段:先自底向上两两归并,让最后一个元素拿到总和;再从顶向下把部分和"分发"到前面的位置。这样一来,一个本来需要串行完成的计算,就可以在远少于序列长度的并行步数内完成。
Mamba 是怎么用上这个机制的? 这正是它既快又省的关键。
Mamba 是一种状态空间模型(SSM),它的核心递推公式可以简写成:
h[t] = Ā[t] * h[t-1] + B̄[t] * x[t]。
这里的 h[t] 是当前步的状态,x[t] 是输入,Ā[t] 和 B̄[t] 是根据输入动态生成的参数。
这个递推看起来和 RNN 几乎一样:要算 h[5] 就必须先算 h[4],要算 h[4] 就必须先算 h[3]......整个序列好像只能一个接一个地串行运算。如果按这个思路去训练,序列一长就完全无法并行,速度会极慢。
但 Mamba 的作者发现了一件很关键的事:尽管参数是时变的,这个递推运算依然满足结合律。也就是说,可以把每一步的运算抽象成一个"操作单元",例如把 (Ā[t], B̄[t] * x[t]) 看成一个可组合的二元组,定义一种新的"合并"操作,这个操作是满足结合律的。一旦满足结合律,就可以把整个序列上所有的递推步骤一起扔给并行扫描算法(比如 Blelloch 算法)去处理。并行扫描会把序列切分成小块,各自独立地计算出局部状态,再跨块合并,最后把所有中间状态一次性算出来。这样一来,原本 O(L) 的串行时间,理论上可以压缩到 O(log L) 的并行步数。训练的时候,整个序列的状态可以被高效并行地算出,彻底告别了 RNN 的串行瓶颈,吞吐量直接对齐 Transformer 的并行优势。
更妙的是,这还只是 Mamba 整体设计中的一环。它还配套了"硬件感知算法"------比如核融合和重计算。核融合会把离散化、状态更新等计算步骤合并成一个 GPU 核函数,尽量在高速的 SRAM 里完成,避免反复在缓慢的显存(HBM)间搬运数据。重计算则在前向传播时不保存巨大的中间状态,反向传播时再就地重算一遍,以计算换空间,把显存占用压得很低。这些技巧叠加在一起,让 Mamba 在训练时既有 Transformer 般的并行效率,在推理时又恢复了 RNN 式的优雅:只需要常数时间的状态更新,不用像 Transformer 那样保留整个上下文窗口。正是 parallel scan 这把钥匙,解开了"选择性 SSM 无法并行训练"这个死锁。
以上是我的一家之言。我觉得,想要创新神经网络,可能真的应该多去了解神经到底是怎么运算的。大脑的"硬件架构"决定了它在某些任务上高度并行,在某些任务上又落入串行瓶颈------而人工系统恰到好处的抽象与重组,也许就藏着下一次突破的线索。
1White AL, Runeson E, Palmer J, Ernst ZR, Boynton GM. Evidence for unlimited capacity processing of simple features in visual cortex. J Vis. 2017 Jun 1;17(6):19. doi: 10.1167/17.6.19. PMID: 28654964; PMCID: PMC5488877.
2Yue, Q., Newton, A.T. & Marois, R. Ultrafast fMRI reveals serial queuing of information processing during multitasking in the human brain. Nat Commun 16, 3057 (2025). https://doi.org/10.1038/s41467-025-58228-0
3 Gu, A., & Dao, T. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv preprint arXiv:2312.00752.