目录
1.摘要
针对PSO易陷于局部最优且难应对动态环境的缺陷,本文提出一种融合QL-MOPSO与ADWA的移动机器人三维复杂地形路径规划算法(MOQLPSO-ADWA),通过Q-learning在线自适应调整MOPSO的惯性权重和加速因子以逼近Pareto前沿,基于全局优化动态设计DWA评价函数权重,使其随目标和障碍物信息实时调节,提取MOQLPSO规划的关键点作为ADWA阶段性目标,实现全局与局部动态避障深度融合。
2.问题表述
机器人工作空间建模

本节提出了一种粗糙地形建模方法,通过传感器数据获取高度图,利用线性映射公式将高度值
h ∈ h min , h max h\inh_{\\min},h_{\\max} h∈hmin,hmax转换为灰度值 a g r a y ∈ 0 , 255 : a_{gray}\in0,255: agray∈0,255:
a g r a y = h − h min h max − h min × 255 a_{gray}=\frac{h-h_{\min}}{h_{\max}-h_{\min}}\times255 agray=hmax−hminh−hmin×255
由此得到反映地形起伏的灰度矩阵,其中高值对应凸起,低值对应凹陷。基于工作区与机器人尺寸将灰度图划分为 n × n n\times n n×n 的网格序列,通过各网格内灰度极差量化地形起伏并识别障碍,构建出分割栅格图。设网格边长为 a a a,则第 i i i条规划路径可表示为:
p a t h i = ( x i 1 , y i 1 ) , ( x i 2 , y i 2 ) , ... , ( x i n , n a ) path_i=(x_{i1},y_{i1}),(x_{i2},y_{i2}),\\ldots,(x_{in},na) pathi=(xi1,yi1),(xi2,yi2),...,(xin,na)
目标函数与Pareto支配
多目标指标为路径长度决定时间和能耗成本:
O b j L ( p a t h i ) = ∑ j = 1 n a 2 + ( y i j − y i ( j − 1 ) ) 2 ObjL(path_i)=\sum_{j=1}^n\sqrt{a^2+(y_{ij}-y_{i(j-1)})^2} ObjL(pathi)=j=1∑na2+(yij−yi(j−1))2
地形粗糙度影响行驶平稳度,通过计算路径网格内的灰度极差 a g r a y i j a_{gray_{ij}} agrayij累加:
O b j R ( p a t h i ) = ∑ j n a g r a y i j ObjR(path_i)=\sum_j^na_{gray_{ij}} ObjR(pathi)=j∑nagrayij
避障操作
若路径 p a t h i path_i pathi的第 j j j个网格粗糙度 a g r a y i j a_{gray_{ij}} agrayij超过碰撞阈值 C m a x C_\mathrm{max} Cmax,则判定发生碰撞:
{ a g r a y k j > C max , collision occurs a g r a y i j ⩽ C max , no collision \begin{cases}a_{gray_{kj}}>C_{\max},&\text{collision occurs}\\a_{gray_{ij}}\leqslant C_{\max},&\text{no collision}\end{cases} {agraykj>Cmax,agrayij⩽Cmax,collision occursno collision
本文提出一种避障操作当在点 ( x i j , y i j ) (x_{ij},y_{ij}) (xij,yij)首次检测到碰撞时,根据前驱点坐标
按如下规则迭代调整其 y y y轴坐标,直至路径可行或达到最大尝试次数:
y i j = { y i j − a , y i ( j − 1 ) ≤ y i j y i j + a , y i ( j − 1 ) > y i j y_{ij}=\begin{cases}y_{ij}-a,&y_{i(j-1)}\leq y_{ij}\\y_{ij}+a,&y_{i(j-1)}>y_{ij}\end{cases} yij={yij−a,yij+a,yi(j−1)≤yijyi(j−1)>yij
3.MOQLPSO全局路径规划
状态设置计算粒子与 g b e s t gbest gbest 的欧氏距离并归一化散为4种状态:
s i ( k ) = ∥ p a t h i ( k ) − g b e s t ( k ) ∥ s_i(k) = \|path_i(k) - gbest(k)\| si(k)=∥pathi(k)−gbest(k)∥
s ˉ i ( k ) = { L 1 , s 1 ≤ s i ( k ) L 2 , s 2 ≤ s i ( k ) < s 1 G 1 , s 3 ≤ s i ( k ) < s 2 G 2 , 0 ≤ s i ( k ) < s 3 \bar{s}_i(k) = \begin{cases} L_1, & s_1 \leq s_i(k) \\ L_2, & s_2 \leq s_i(k) < s_1 \\ G_1, & s_3 \leq s_i(k) < s_2 \\ G_2, & 0 \leq s_i(k) < s_3 \end{cases} sˉi(k)=⎩ ⎨ ⎧L1,L2,G1,G2,s1≤si(k)s2≤si(k)<s1s3≤si(k)<s20≤si(k)<s3
奖励设置以动作前后归一化目标函数差值之和作为奖励:
r i ( k , k + 1 ) = O b j L ( p a t h i ( k ) ) − O b j L ( p a t h i ( k + 1 ) ) + O b j R ( p a t h i ( k ) ) − O b j R ( p a t h i ( k + 1 ) ) r_i(k, k + 1) = ObjL(path_i(k)) - ObjL(path_i(k + 1)) + ObjR(path_i(k))-ObjR(path_i(k+1)) ri(k,k+1)=ObjL(pathi(k))−ObjL(pathi(k+1))+ObjR(pathi(k))−ObjR(pathi(k+1))
4.ADWA动态路径规划
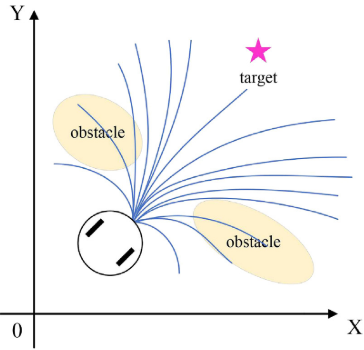
动态障碍物避障策略
针对DWA算法在特定动态避障时因角速度调整不足导致失败的缺陷,本文提出一种改进自适应动态窗口法 (ADWA)。设 t t t时刻机器人与障碍物位置分别为 p t r = ( x t r , y t r ) p_t^r=(x_t^r,y_t^r) ptr=(xtr,ytr) 和 p t o = ( x t o , y t o ) p_t^o=(x_t^o,y_t^o) pto=(xto,yto)。当两者满足速度相似度阈值 ε \varepsilon ε且距离小于碰撞半径 d i s t ( v , ϖ ) c o l l i s i o n dist(v,\varpi)_{collision} dist(v,ϖ)collision时:
∥ v t r − v t o ∥ < ε ∧ d i s t ( v t , ϖ t ) = ∥ p t r − p t o ∥ < d i s t ( v , ϖ ) c o l l i s i o n \|v_t^r - v_t^o\| < \varepsilon \;\wedge\; dist(v_t, \varpi_t) = \|p_t^r - p_t^o\| < dist(v, \varpi)_{collision} ∥vtr−vto∥<ε∧dist(vt,ϖt)=∥ptr−pto∥<dist(v,ϖ)collision
动态调整权重系数策略
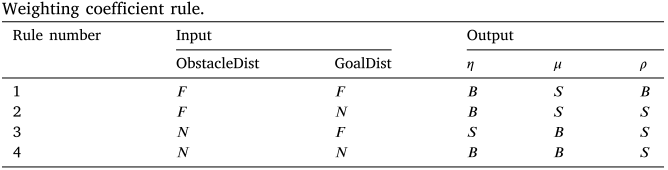
动态权重调整策略以机器人与障碍物的最近距离及与目标的距离为输入变量,其状态集记为 { N , F } \left\{N,F\right\} {N,F}(近、远);以三个权重系数为输出变量,其状态集记为 { S , B } \{S,B\} {S,B} (小、大)。动态调节规则矩阵设计逻辑如下:
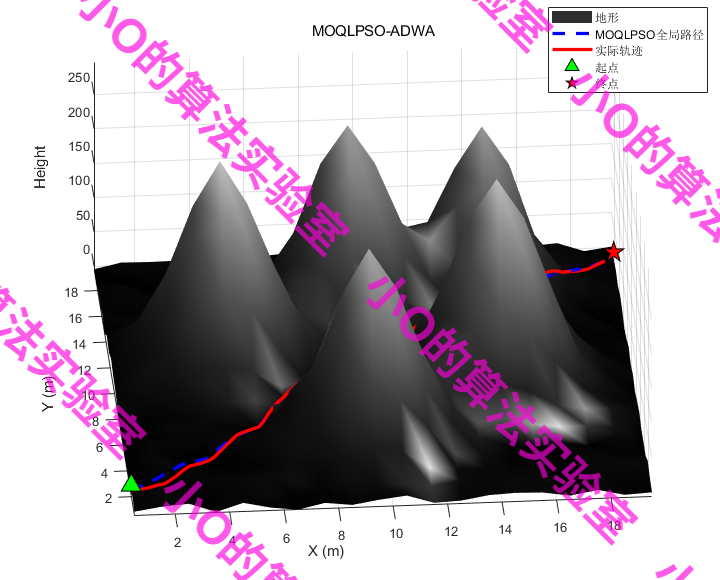
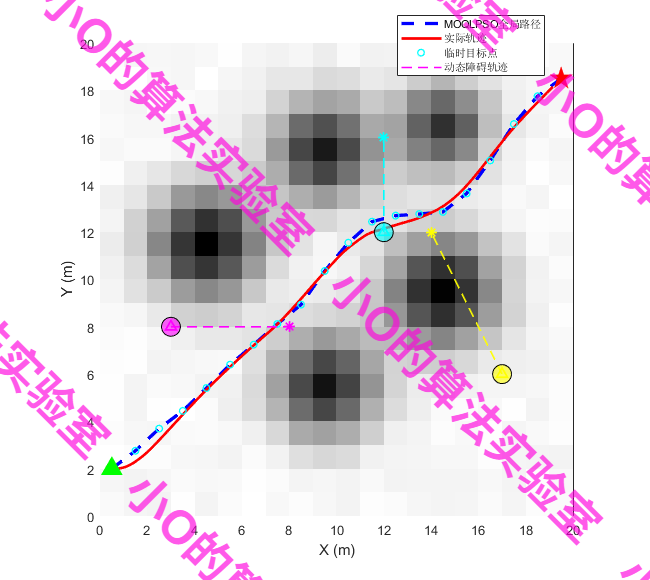
5.结果展示
6.参考文献
Duan Z, Zhang Y, Zhao Q, et al. Dynamic path planning for certain mobile robots in the 3D rough terrain: Fusion of the Q-learning enhanced MOPSO and improved DWAJ. Mathematics and Computers in Simulation, 2026.
7.代码获取
xx
8.算法辅导·应用定制·读者交流
xx