文章目录
1.源码
cpp
/**
* Copyright 1993-2015 NVIDIA Corporation. All rights reserved.
*
* Please refer to the NVIDIA end user license agreement (EULA) associated
* with this source code for terms and conditions that govern your use of
* this software. Any use, reproduction, disclosure, or distribution of
* this software and related documentation outside the terms of the EULA
* is strictly prohibited.
*
*/
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <helper_cuda.h>
#include <helper_string.h>
////////////////////////////////////////////////////////////////////////////////
// Variable on the GPU used to generate unique identifiers of blocks.
////////////////////////////////////////////////////////////////////////////////
__device__ int g_uids = 0;
////////////////////////////////////////////////////////////////////////////////
// Print a simple message to signal the block which is currently executing.
////////////////////////////////////////////////////////////////////////////////
__device__ void print_info(int depth, int thread, int uid, int parent_uid)
{
if (threadIdx.x == 0)
{
if (depth == 0)
printf("BLOCK %d launched by the host\n", uid);
else
{
char buffer[32];
for (int i = 0 ; i < depth ; ++i)
{
buffer[3*i+0] = '|';
buffer[3*i+1] = ' ';
buffer[3*i+2] = ' ';
}
buffer[3*depth] = '\0';
printf("%sBLOCK %d launched by thread %d of block %d\n", buffer, uid, thread, parent_uid);
}
}
__syncthreads();
}
////////////////////////////////////////////////////////////////////////////////
// The kernel using CUDA dynamic parallelism.
//
// It generates a unique identifier for each block. Prints the information
// about that block. Finally, if the 'max_depth' has not been reached, the
// block launches new blocks directly from the GPU.
////////////////////////////////////////////////////////////////////////////////
__global__ void cdp_kernel(int max_depth, int depth, int thread, int parent_uid)
{
// We create a unique ID per block. Thread 0 does that and shares the value with the other threads.
__shared__ int s_uid;
if (threadIdx.x == 0)
{
s_uid = atomicAdd(&g_uids, 1);
}
__syncthreads();
// We print the ID of the block and information about its parent.
print_info(depth, thread, s_uid, parent_uid);
// We launch new blocks if we haven't reached the max_depth yet.
if (++depth >= max_depth)
{
return;
}
cdp_kernel<<<gridDim.x, blockDim.x>>>(max_depth, depth, threadIdx.x, s_uid);
}
////////////////////////////////////////////////////////////////////////////////
// Main entry point.
////////////////////////////////////////////////////////////////////////////////
int main(int argc, char **argv)
{
printf("starting Simple Print (CUDA Dynamic Parallelism)\n");
// Parse a few command-line arguments.
int max_depth = 2;
if (checkCmdLineFlag(argc, (const char **)argv, "help") ||
checkCmdLineFlag(argc, (const char **)argv, "h"))
{
printf("Usage: %s depth=<max_depth>\t(where max_depth is a value between 1 and 8).\n", argv[0]);
exit(EXIT_SUCCESS);
}
if (checkCmdLineFlag(argc, (const char **)argv, "depth"))
{
max_depth = getCmdLineArgumentInt(argc, (const char **)argv, "depth");
if (max_depth < 1 || max_depth > 8)
{
printf("depth parameter has to be between 1 and 8\n");
exit(EXIT_FAILURE);
}
}
// Find/set the device.
int device = -1;
cudaDeviceProp deviceProp;
device = findCudaDevice(argc, (const char **)argv);
checkCudaErrors(cudaGetDeviceProperties(&deviceProp, device));
if (!(deviceProp.major > 3 || (deviceProp.major == 3 && deviceProp.minor >= 5)))
{
printf("GPU %d - %s does not support CUDA Dynamic Parallelism\n Exiting.", device, deviceProp.name);
exit(EXIT_WAIVED);
}
// Print a message describing what the sample does.
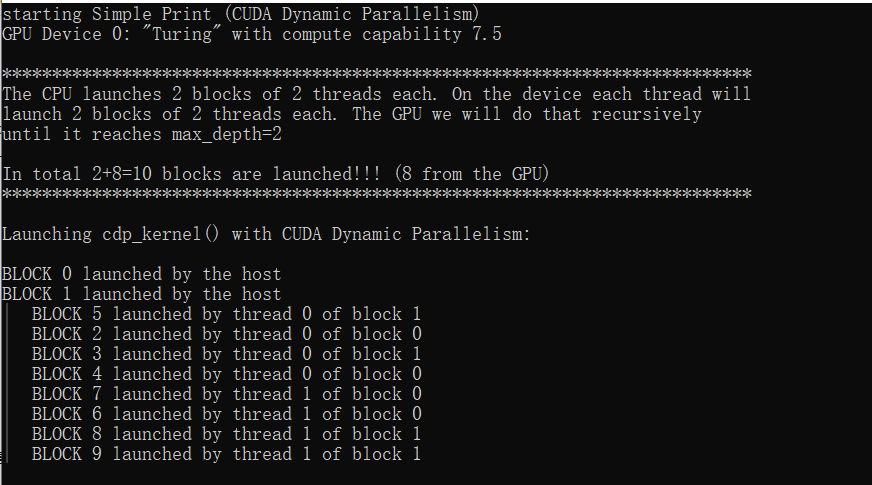
printf("***************************************************************************\n");
printf("The CPU launches 2 blocks of 2 threads each. On the device each thread will\n");
printf("launch 2 blocks of 2 threads each. The GPU we will do that recursively\n");
printf("until it reaches max_depth=%d\n\n", max_depth);
printf("In total 2");
int num_blocks = 2, sum = 2;
for (int i = 1 ; i < max_depth ; ++i)
{
num_blocks *= 4;
printf("+%d", num_blocks);
sum += num_blocks;
}
printf("=%d blocks are launched!!! (%d from the GPU)\n", sum, sum-2);
printf("***************************************************************************\n\n");
// We set the recursion limit for CDP to max_depth.
cudaDeviceSetLimit(cudaLimitDevRuntimeSyncDepth, max_depth);
// Launch the kernel from the CPU.
printf("Launching cdp_kernel() with CUDA Dynamic Parallelism:\n\n");
cdp_kernel<<<2, 2>>>(max_depth, 0, 0, -1);
checkCudaErrors(cudaGetLastError());
// Finalize.
checkCudaErrors(cudaDeviceSynchronize());
exit(EXIT_SUCCESS);
}
接下来对每一行代码进行详细解释:
2.文件头部注释
cpp
/**
* Copyright 1993-2015 NVIDIA Corporation. All rights reserved.
*
* Please refer to the NVIDIA end user license agreement (EULA) associated
* with this source code for terms and conditions that govern your use of
* this software. Any use, reproduction, disclosure, or distribution of
* this software and related documentation outside the terms of the EULA
* is strictly prohibited.
*
*/解释:NVIDIA 版权声明和许可协议说明,表明代码所有权和使用限制。
3.头文件包含
cpp
#include <iostream>
#include <cstdio>
#include <cstdlib>解释:标准 C++ 头文件
iostream:输入输出流cstdio:C 风格标准输入输出(printf等)cstdlib:C 风格标准库(exit等)
cpp
#include <helper_cuda.h>
#include <helper_string.h>解释:NVIDIA CUDA 辅助库头文件
helper_cuda.h:提供 CUDA 错误检查、设备选择等辅助函数helper_string.h:提供命令行参数解析辅助函数
4.设备端全局变量
cpp
__device__ int g_uids = 0;解释:
__device__:表示这个变量存储在 GPU 全局内存中g_uids:全局唯一标识符计数器,所有 block 共享= 0:初始化为 0,用于原子分配唯一 ID
5.打印信息函数
cpp
__device__ void print_info(int depth, int thread, int uid, int parent_uid)解释:
__device__:这个函数在 GPU 上执行,只能被 GPU kernel 调用depth:当前递归深度(0表示CPU启动)thread:父 block 中负责启动当前 block 的线程 IDuid:当前 block 的唯一标识符parent_uid:父 block 的唯一标识符
cpp
{
if (threadIdx.x == 0)解释:只让每个 block 中的线程 0 执行打印,避免多个线程重复输出
cpp
{
if (depth == 0)
printf("BLOCK %d launched by the host\n", uid);解释:如果深度为 0,说明是 CPU 直接启动的根 block,打印主机启动信息
cpp
else
{
char buffer[32];解释:深度>0,说明是 GPU 动态启动的,创建字符缓冲区用于构建缩进
cpp
for (int i = 0 ; i < depth ; ++i)
{
buffer[3*i+0] = '|';
buffer[3*i+1] = ' ';
buffer[3*i+2] = ' ';
}解释:构建树形缩进
- 每层深度用 3 个字符表示:"| "
- 例如 depth=2:buffer = "| | | "(实际是 "| | ",因为最后一个不完整)
- depth=1:"| | "
- depth=2:"| | | "
cpp
buffer[3*depth] = '\0';解释:在缩进字符串末尾添加字符串结束符
cpp
printf("%sBLOCK %d launched by thread %d of block %d\n", buffer, uid, thread, parent_uid);解释:打印层级关系和启动信息
%s:树形缩进uid:当前 block IDthread:父 block 中的哪个线程启动了当前 blockparent_uid:父 block ID
cpp
}
}
__syncthreads();解释 :__syncthreads() 是 block 内线程同步点
- 确保打印完成后再继续执行
- 防止输出交错混乱
cpp
}6.核心 CDP Kernel
cpp
__global__ void cdp_kernel(int max_depth, int depth, int thread, int parent_uid)解释:
__global__:表示这是一个 kernel 函数,可以被 CPU 或 GPU 调用- 参数说明:
max_depth:最大递归深度(不变)depth:当前深度(每递归一次+1)thread:启动此 block 的线程 IDparent_uid:父 block 的 UID
cpp
{
// We create a unique ID per block. Thread 0 does that and shares the value with the other threads.
__shared__ int s_uid;解释:
__shared__:声明共享内存变量s_uid:同一个 block 内所有线程共享的 UID 存储位置- 共享内存访问速度比全局内存快,且能实现线程间通信
cpp
if (threadIdx.x == 0)
{
s_uid = atomicAdd(&g_uids, 1);
}解释:
- 只有线程 0 执行此代码
atomicAdd(&g_uids, 1):原子操作- 读取
g_uids当前值 - 将其加 1
- 返回旧值
- 整个过程不可分割,保证多 block 并发时的数据一致性
- 读取
- 返回值赋给
s_uid,作为当前 block 的唯一 ID
cpp
__syncthreads();解释:
- 强制所有线程等待,直到线程 0 完成 UID 分配
- 确保所有线程都能访问到正确的
s_uid值
cpp
// We print the ID of the block and information about its parent.
print_info(depth, thread, s_uid, parent_uid);解释:调用之前定义的打印函数,输出当前 block 的信息
cpp
// We launch new blocks if we haven't reached the max_depth yet.
if (++depth >= max_depth)
{
return;
}解释:
++depth:先自增,再比较(先增加深度再判断)- 如果达到或超过最大深度,直接返回,不再启动新 block
- 注意:这是深度优先的逻辑判断
cpp
cdp_kernel<<<gridDim.x, blockDim.x>>>(max_depth, depth, threadIdx.x, s_uid);解释:
- 这是 CDP 的核心:在 GPU kernel 内部启动新的 kernel
<<<gridDim.x, blockDim.x>>>:配置参数gridDim.x:使用父 kernel 相同的 grid 维度(2个block)blockDim.x:使用父 kernel 相同的 block 维度(2个线程)
- 参数传递:
max_depth:最大深度不变depth:已自增的新深度threadIdx.x:当前线程 ID 作为父线程标识s_uid:当前 block 的 UID 作为父 block ID
cpp
}7.主函数
cpp
int main(int argc, char **argv)解释:CPU 端主函数入口
cpp
{
printf("starting Simple Print (CUDA Dynamic Parallelism)\n");解释:输出程序启动信息
命令行参数解析
cpp
// Parse a few command-line arguments.
int max_depth = 2;解释:初始化最大深度为 2(默认值)
cpp
if (checkCmdLineFlag(argc, (const char **)argv, "help") ||
checkCmdLineFlag(argc, (const char **)argv, "h"))
{
printf("Usage: %s depth=<max_depth>\t(where max_depth is a value between 1 and 8).\n", argv[0]);
exit(EXIT_SUCCESS);
}解释:
- 检查命令行是否有 "help" 或 "h" 标志
- 如果有,打印使用方法并退出
argv[0]是程序名称
cpp
if (checkCmdLineFlag(argc, (const char **)argv, "depth"))
{
max_depth = getCmdLineArgumentInt(argc, (const char **)argv, "depth");解释:检查是否有 "depth" 参数,如果有则获取其整数值
cpp
if (max_depth < 1 || max_depth > 8)
{
printf("depth parameter has to be between 1 and 8\n");
exit(EXIT_FAILURE);
}
}解释:验证深度范围(1-8),超出则报错退出
GPU 设备选择和检查
cpp
// Find/set the device.
int device = -1;
cudaDeviceProp deviceProp;解释:
device:存储设备 IDdeviceProp:存储设备属性结构体
cpp
device = findCudaDevice(argc, (const char **)argv);解释:辅助函数,自动选择合适的 CUDA 设备
cpp
checkCudaErrors(cudaGetDeviceProperties(&deviceProp, device));解释:
- 获取指定设备的属性信息
checkCudaErrors:宏,检查 CUDA 调用是否出错
cpp
if (!(deviceProp.major > 3 || (deviceProp.major == 3 && deviceProp.minor >= 5)))解释:检查 GPU 计算能力
- CDP 需要 Compute Capability ≥ 3.5
- major=3, minor=5 表示 3.5 版本
- 如果不支持,打印错误并退出
cpp
{
printf("GPU %d - %s does not support CUDA Dynamic Parallelism\n Exiting.", device, deviceProp.name);
exit(EXIT_WAIVED);
}打印统计信息
cpp
// Print a message describing what the sample does.
printf("***************************************************************************\n");
printf("The CPU launches 2 blocks of 2 threads each. On the device each thread will\n");
printf("launch 2 blocks of 2 threads each. The GPU we will do that recursively\n");
printf("until it reaches max_depth=%d\n\n", max_depth);解释:描述程序行为:CPU 启动 2x2,GPU 每个线程启动 2x2
cpp
printf("In total 2");
int num_blocks = 2, sum = 2;
for (int i = 1 ; i < max_depth ; ++i)
{
num_blocks *= 4;
printf("+%d", num_blocks);
sum += num_blocks;
}解释:计算并打印总 block 数量
- 每层深度:每个 block 启动 4 个新 block(2块 × 2线程)
- 所以总数:2 + 2×4 + 2×4×4 + ...
cpp
printf("=%d blocks are launched!!! (%d from the GPU)\n", sum, sum-2);
printf("***************************************************************************\n\n");解释:打印总数和 GPU 启动的数量
设置和启动 Kernel
cpp
// We set the recursion limit for CDP to max_depth.
cudaDeviceSetLimit(cudaLimitDevRuntimeSyncDepth, max_depth);解释:
- 设置 CDP 运行时同步深度限制
- 防止无限递归导致资源耗尽
cudaLimitDevRuntimeSyncDepth:动态并行递归深度限制
cpp
// Launch the kernel from the CPU.
printf("Launching cdp_kernel() with CUDA Dynamic Parallelism:\n\n");
cdp_kernel<<<2, 2>>>(max_depth, 0, 0, -1);解释:
- 从 CPU 启动初始 kernel
<<<2, 2>>>:2 个 block,每个 2 个线程- 参数:
max_depth, 0, 0, -1depth=0:根层次thread=0:无意义的占位符parent_uid=-1:表示没有父 block
cpp
checkCudaErrors(cudaGetLastError());解释:检查 kernel 启动是否有错误(异步错误)
清理和退出
cpp
// Finalize.
checkCudaErrors(cudaDeviceSynchronize());解释:
- 等待所有 GPU 操作完成
- 包括所有递归启动的 kernel
- 检查执行过程中的错误
cpp
exit(EXIT_SUCCESS);
}解释:程序正常退出
8.关键概念总结
- CUDA 动态并行:GPU kernel 可以启动新的 GPU kernel
- 原子操作:保证多 block 并发时数据一致性
- 共享内存:block 内线程间快速共享数据
- 递归控制:通过深度限制防止无限递归
- 层级可视化:树形结构显示调用关系