1. NVLS(nvlink sharp)机内算法
H100开始一代用于机内allreduce操作。
主要流程:
Scatter->reduce-> broadcast -> gather。其中reduce和broadcast由Nvswitch做,但由GPU发起控制指令驱动。
其中GPU有一个UC(unicast)内存地址和MC(multicast) 内存地址, 都映射到同一块物理地址,可以由GPU和nvswitch共同访问。
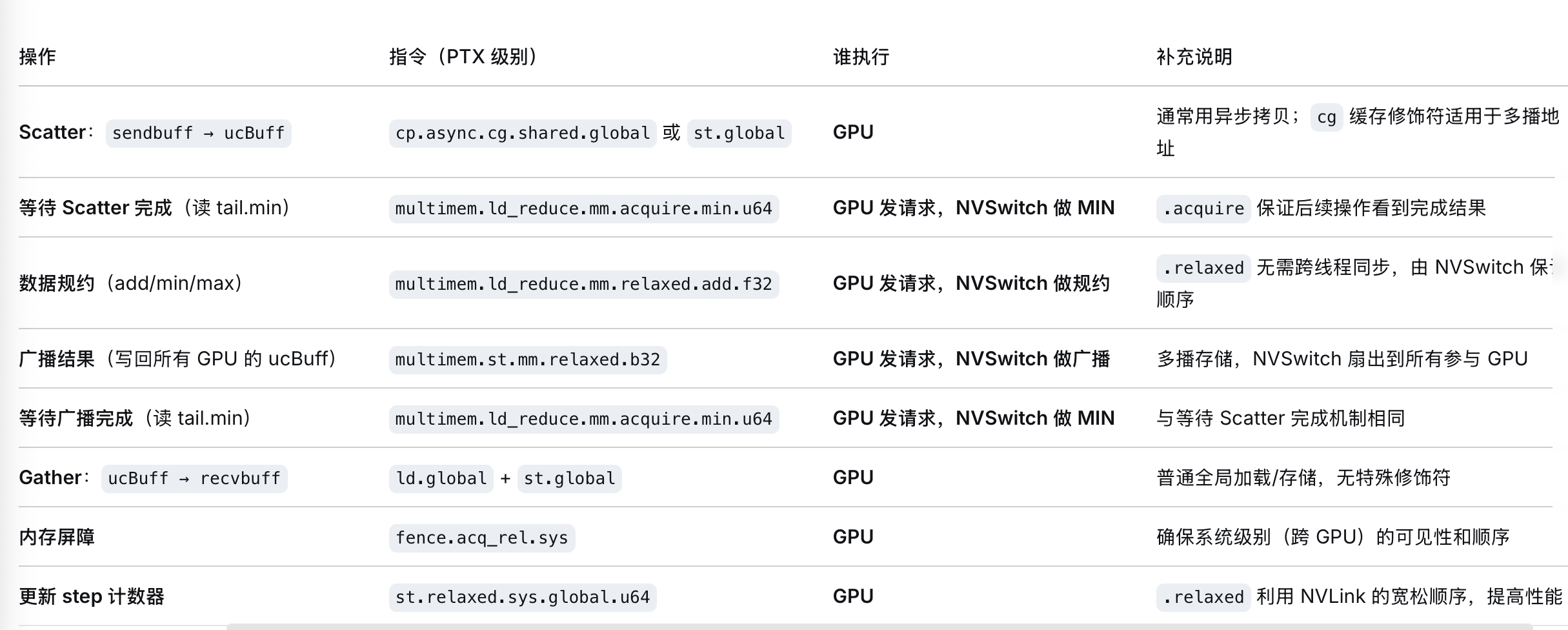
详细流程:
初始状态:每个 GPU 有 sendbuff(本 GPU 的输入数据)
═══════════════════════ 阶段一:Scatter ═══════════════════════
【全部 GPU 并行,纯 GPU 本地操作】
GPU-k: sendbuff[0..N] ──GPU拷贝──→ ucBuff[0..N] (UC 地址,本地内存)
更新 send.tail,通知"我已写入 ucBuff"
═══════════════════════ 阶段二:Reduce + Broadcast ═══════════
【GPU 发指令 + NVSwitch 硬件执行计算】
Step 2a: 等待所有人 Scatter 完成
┌─────────────────────────────────────────────────────────┐
│ GPU-k 发: multimem.ld_reduce.min([MC_tail]) │ ← GPU 发请求
│ NVSwitch: min(tail_GPU0, tail_GPU1, ..., tail_GPU7) │ ← NVSwitch 计算
│ 返回: 全局最小 step,确认所有人写完 │ ← NVSwitch 返回
└─────────────────────────────────────────────────────────┘
Step 2b: 从 MC 地址读数据(触发硬件规约)
┌─────────────────────────────────────────────────────────┐
│ GPU-k 发: multimem.ld_reduce.add.f32 %reg, [MC_addr] │ ← GPU 发请求
│ NVSwitch: 读所有 GPU ucBuff[i],执行 add 规约 │ ← NVSwitch 计算
│ 返回: sum(GPU0[i], GPU1[i], ..., GPU7[i]) → %reg │ ← NVSwitch 返回
└─────────────────────────────────────────────────────────┘
← GPU SM 寄存器里得到全局 sum,GPU 自身没做加法计算!
Step 2c: 将规约结果写回 MC 地址(触发硬件广播)
┌─────────────────────────────────────────────────────────┐
│ GPU-k 发: multimem.st.b32 [MC_addr], %reg │ ← GPU 发请求
│ NVSwitch: 将 sum 广播写入所有 GPU 的 ucBuff[i] │ ← NVSwitch 执行
└─────────────────────────────────────────────────────────┘
更新 send.tail,通知"规约结果已写入 ucBuff"
═══════════════════════ 阶段三:Gather ═══════════════════════
【全部 GPU 并行,纯 GPU 本地操作】
等待 MC_tail min 确认广播完成(GPU 发请求,NVSwitch 做 min)
GPU-k: ucBuff[0..N] ──GPU拷贝──→ recvbuff[0..N] (本地内存,UC 地址)
最终状态:每个 GPU 的 recvbuff = sum(所有 GPU 的 sendbuff)二. 机间CollNet Sharp算法
目前只有NV的ib交换机支持交换机Sharp协议,CollNet有两种实现模式。
1.CollNet Direct (机内过Nvswitch场景,如全局AllReduce) , 这种是假设只有一个head网卡接交换机。
时间 →
Node0: GPU0(leaf) GPU1(leaf) GPU2(Head) IB/SHARP GPU4(Node1-Head)
| | | | |
├──Scatter─→| | | |
├──────────Scatter──────→| | |
| ├──Scatter─→| | |
| | | | |
| | Reduce locally | |
| | ├──iallreduce──→|←──iallreduce─|
| | | SHARP硬件内Reduce |
| | |←─ result ────┤ |
| | | | |
|←─────Bcast/Gather─────| | |
| |←──Gather─ | | |
↓ ↓ ↓ ↓ ↓
[done] [done] [done] [done] [done]节点内的数据通过 Head GPU做local Reduce, 然后发给 IB switch。
2.CollNet Chain (机内不过Nvswitch场景,原理和direct类似)
但是我们经常的硬件架构是一个GPU接一个网卡出,CollNet Direct变为以下情况
Node0: rank0(head0) rank1(head1) rank2(head2) rank3(head3)
│ │ │ │
│ │ │ │
└───────────────┴───────────────┴───────────────┘
│
IB/SHARP Switch
(4路并行 iallreduce)
│
┌───────────────┬───────────────┬───────────────┐
│ │ │ │
rank0(head0) rank1(head1) rank2(head2) rank3(head3)
cpp
const int hasUp = (direct->up[0] >= 0) ? 1 : 0; // = 0,无叶节点需要汇聚
const int hasDn = (direct->down[0] >= 0) ? 1 : 0; // = 0,无叶节点需要广播
// 线程分配:
// nThreadsScatter = WARP_SIZE (hasUp=0, hasDn=0,只分配最少线程)
// nThreadsGather = 0
// nThreadsBcast = WARP_SIZE
// nThreadsReduce = 剩余所有线程
// Reduce 路径 (hasUp=0, hasDn=0):直接发网络,无本地 reduce 操作
} else {
// Directly send to network
prims.send(offset, nelem); // 直接 send 到 out=nRanks(IB 网络出口)
}
// Bcast 路径:直接从网络接收
} else {
prims.recv(offset, nelem, /*postOp=*/true); // 直接从 nRanks 接收结果
}没有任何 Scatter/Gather/LocalReduce 步骤,GPU 直接将数据送给 SHARP,再直接从 SHARP 接收。
三. Tree算法
比较简单,机内机间都可以用,如图单树
Level 0: GPU0 (根)
/ \
Level 1: GPU4 (GPU? 未画出)
/ \
Level 2: GPU2 GPU6
/ \ / \
Level 3: GPU1 GPU3 GPU5 GPU7实际 NCCL 特点 :不一定是完全二叉树(取决于 GPU 拓扑),通常会使用 Kary 树(每个父节点有 4-8 个子节点)来减少层数,根节点选择:通常是离 NVSwitch 最近的 GPU
两步过程:Reduce 阶段(向上规约)、 Broadcast 阶段(向下广播)
多channel时,会生成2个树,Double Tree, 多channel共用这两颗树,这样为了更好地利用带宽。
Tree 0 (Btree): Tree 1 (镜像):
0---------------8 3----------------11
______/ \ / \______
4 \ / 7
/ \ \ / / \
2 6 10 1 5 9
/ \ / \ / \ / \ / \ / \
1 3 5 7 9 11 0 2 4 6 8 10