第二讲,我们主要进行参数实验,就是固定一个参数来看最终有什么变化。
也就是说我们遵守一个原则:一次只改一个参数
我们先使用一个基准版本,就是我们的模型使用dreamshaper_8.safetensors这个模型,也就是上一讲中在最后让自己下载的模型
我们的正向提示词就是用这个:
a cute orange cat sitting by a window, warm sunset light, highly detailed fur, soft shadows, realistic, cozy atmosphere
负向提示词使用这个:
low quality, blurry, deformed, extra limbs, watermark, text, ugly
然后就是分辨率:
宽度:512
高度:512
批量大小:1
K采样器基准参数
先统一成这样:
步数(steps):20
cfg:7
采样器名称:euler
调度器:normal
降噪:1.00
先做一个非常重要的设置:固定种子,现在 K采样器里有一个:
生成后控制:randomize
这个意思是:每次生成后,种子会自动随机变化。
如果一直是 randomize,我们就没法做严谨对比。
点击生成后控制会出现四个选项:
其中fixed表示的就是固定
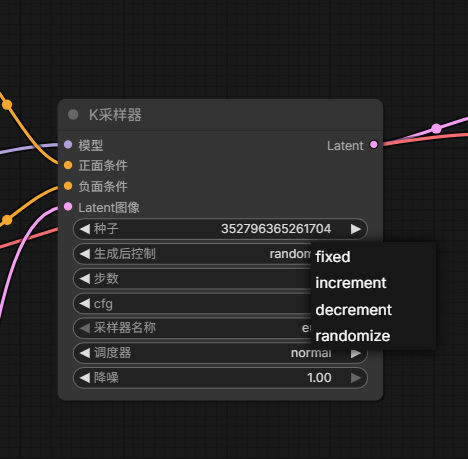
然后就是将生成后控制变为固定之后,我们开始生成我们的第一张图:

实验一 seed(种子)
之后开始我们的第一个参数,种子(seed):种子主要影响构图、姿态、细节随机性。
其余的都保持不变,我们设置种子为111111,222222,333333来看一看最终的生图有什么区别:
下面三张图片分别为种子为111111,222222,333333得到的图片,其实我们可以发现
都还是"橘猫、窗边、暖光"
但猫的:姿势,视角,表情,构图,背景细节会发生变化



总结:Seed 决定什么?
Seed 不改变大方向,但会改变"这一张具体长什么样"。
所以以后如果你出了一张特别满意的图:一定要记住 seed。
实验二 steps(步数)
这个实验二主要是为了理解Steps 主要影响细节丰富度和画面完成度。
我们先把随机种子固定为11111111,其余的都保持不变,我们只改变steps
下面分别为步数为10,20,30,40所生成的图片:
steps = 10:生成快,画面有了,但细节通常比较少,毛发、边缘、光影可能偏粗

steps = 20:一般已经比较稳定,是很常用的一个步数设置

steps = 30
细节可能更完整一些
但速度更慢
提升有,但不会翻天覆地

steps = 40
有时会再细一点
但很多时候提升已经不明显
时间明显更长

要注意的是Steps 并不是越高越好,对我们低显存的电脑来说,20~30 往往最实用。再往上,不一定值那个时间。
实验三:cfg
CFG 主要决定模型"听不听你的提示词"。
我们就其余都保持固定:seed为111111,steps为20,其余都保持不变,只改变cfg
我们将cfg分别设置为3,7,10,14
当cfg = 3
模型比较"自由发挥"
画面可能自然,但不一定很听你的提示词
有时主体不够明确

cfg = 7
通常比较平衡
既听提示词,又不至于过度僵硬
很多人常用这个区间

cfg = 10
模型会更强地执行提示词
细节可能更"明显"
但有时会开始变得不自然

cfg = 14
很可能出现"太用力"
画面容易僵硬
光影、纹理、轮廓可能怪
有时反而更差
(吐槽:这他妈啥啊,跟鬼一样,绷不住了)

CFG 的常用区间
对我们现在这种使用场景,通常建议:5~8 最常用,7 左右最稳
实验四:Sampler(采样器)
不同采样器会让图的气质、细节方式、稳定性略有不同。
我们接下来的实验就,只改变采样器,其余的都保持不变:
看以看到采样器有非常多种,它们本质上是在用不同的方法,让模型一步一步把噪声变成图片。我们可以做一个简单的理解:
模型 = 画家
提示词 = 你的要求
种子 = 起稿方式
采样器 = 画家"怎么画"的方法
步数 = 画多少步
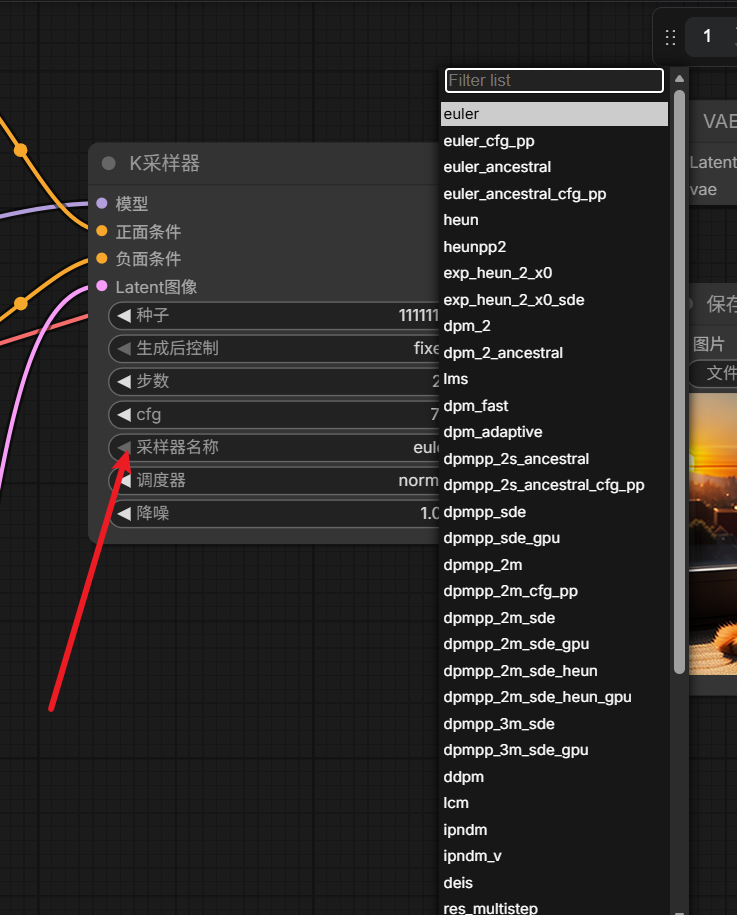
我们可以先理解几个关键的:
1)ancestral
比如:
euler_ancestral
dpm_2_ancestral
dpmpp_2s_ancestral
它的特点:这类一般随机性更强,更"活",变化更大。
直观感受:更有创意感,同样提示词下变化更明显,有时更容易出惊喜,但也可能更不稳定。
适合:想要变化,想多尝试构图,不追求严格复现
这张图片的采样器是euler_ancestral

这个图片的采样器是dpm_2_ancestral:

这张图片的采样器是dpmpp_2s_ancestral:

2)sde
比如:
dpmpp_sde
dpmpp_2m_sde
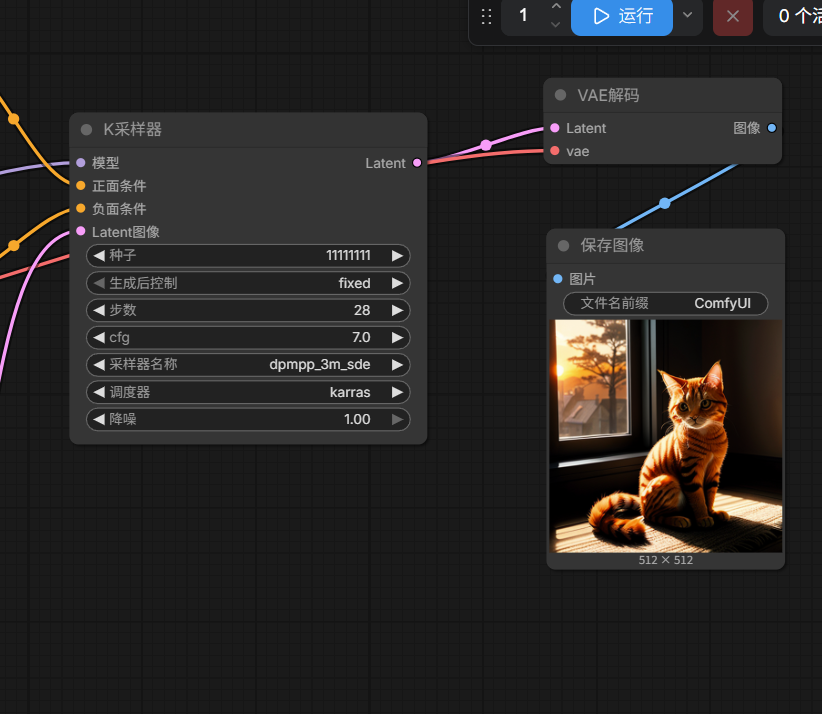
dpmpp_3m_sde
它的特点:一般会更平滑、更稳一些,经常在质量上表现不错。
直观感受:细节往往比较好,画面比较稳定,适合中高质量出图,有时稍微慢一点


(不是这是猫么?我问你,这是猫吗?)
我讲一讲出现这种的原因把:主要就是Stable Diffusion 生成图像时,不是一下子"蹦"出一张图。它其实是:先从一团随机噪声开始,然后一步一步去噪,最后变成一张图。
采样器就像"去噪路线"。3M 这类采样器会参考前面几步的信息,试图更聪明地预测下一步。
但如果参数不合适,它也可能:方向判断错,细节过度放大,噪声没去干净,色彩被推得很怪,画面变成彩色块、油污感、碎片感
我们这张就是这种情况。

(下面的这些都可以自己试一试,挺好玩的)
3)2m / 3m / 2s
比如:
dpmpp_2m
dpmpp_3m_sde
dpmpp_2s_ancestral
这是它们内部算法结构的差异。
我们现阶段不用深究数学原理,只要粗略记住:
2M:通常比较稳,常用
3M:有时更细,但也更复杂
2S:也常见,部分场景效果好
4)cfg_pp
比如:
euler_cfg_pp
dpmpp_2m_cfg_pp
这是和 CFG 引导方式有关的变种。
我们现在可以先把它理解为:某些采样器的"增强版/特殊版",但对入门来说,不用优先碰。
5)_gpu
比如:
dpmpp_sde_gpu
dpmpp_2m_sde_gpu
这个一般表示更偏向 GPU 优化版本。
如果有些节点或版本支持得好,可能更快一些。
对我们刚入门的新手来说:
使用这个euler就够了:
其特点就是:稳,快,好理解,入门最友好
实验五 调度器
采样器决定"怎么去噪",调度器决定"每一步去噪怎么分配"。
生图不是一步完成的,比如我们设置:steps = 20,AI 就会从噪声到图像走 20 步。
调度器就是在安排:
第 1 步去多少噪
第 2 步去多少噪
......
第 20 步去多少噪
| 调度器 | 简单理解 | 适合情况 |
|---|---|---|
normal |
默认、稳定、普通路线 | Euler、入门测试 |
karras |
很常用,质量通常更稳 | DPM++ 系列常用 |
exponential |
去噪分布更激进一些 | 可以测试,但不是新手默认 |
sgm_uniform |
新模型/部分工作流常用 | 后面再学也行 |
simple |
简化路线 | 特殊场景,先不用管 |
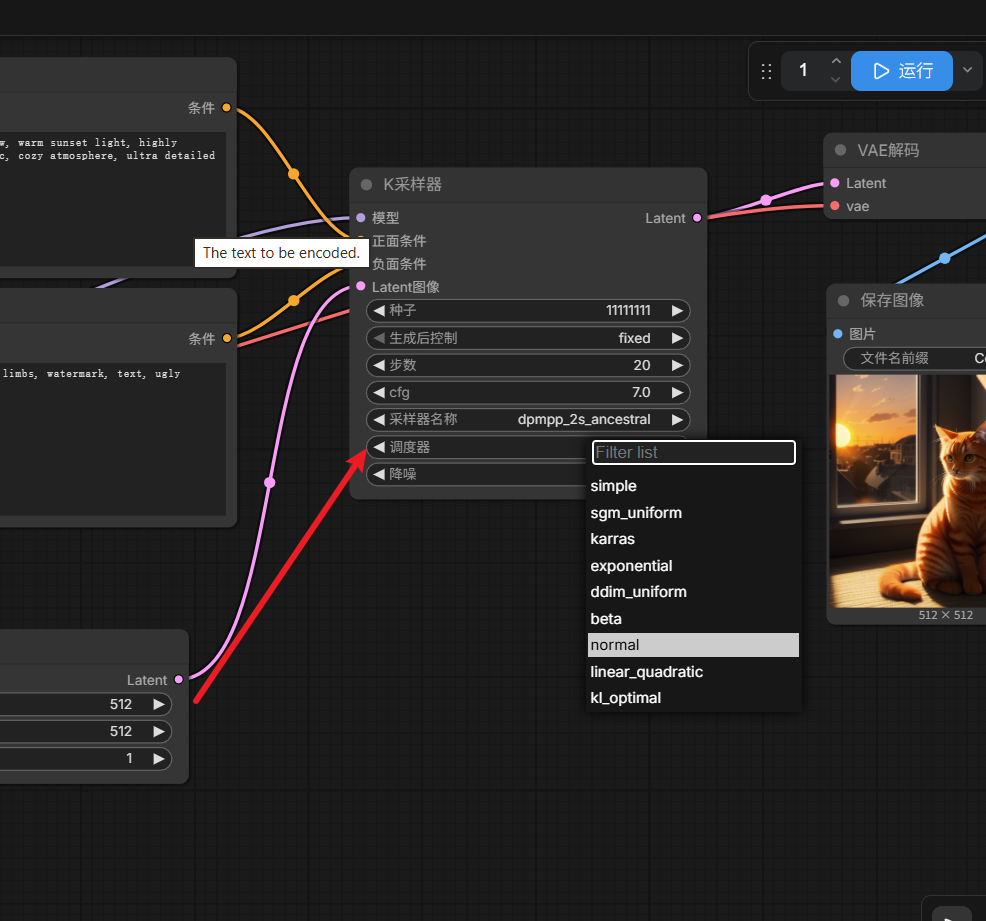
我们现在最为实用的搭配:
快速稳定:
采样器:euler
调度器:normal
steps:20
cfg:7

更认真出图:
采样器:dpmpp_2m
调度器:karras
steps:24
cfg:6.5 或 7

细腻一点:
采样器:dpmpp_2m_sde
调度器:karras
steps:24~28
cfg:6~7

我们刚才尝试 3m 出问题,很可能就和 采样器 + 调度器 + 步数搭配不合适有关,于是我做了一些尝试,下面是设置以及一些生出来的图发现能够正常生图(哎呀,这个地方自己多试一试把)
实验六:其余的小点
其一:文生图时,通常必须保持:降噪 = 1.00,因为我们要让 AI 从噪声完整生成一张图。
降噪真正重要的地方:图生图
图生图是:
给 AI 一张原图,让它根据提示词重新画。
这时候降噪决定:
保留原图多少
改变原图多少
| 降噪值 | 效果 |
|---|---|
0.2 |
改得很少,基本保留原图 |
0.4 |
轻微重绘,适合修图 |
0.6 |
明显改变,但还能看出原图 |
0.8 |
大幅重绘,原图只剩大概结构 |
1.0 |
几乎重新生成 |
所以:
文生图:denoise = 1.00
图生图:denoise = 0.3~0.7 常用
我们现在还没开始图生图,所以先不用重点折腾降噪。
其二:宽度和高度是什么?
这个比较直观:
宽度 = 图片横向大小
高度 = 图片纵向大小
比如:
512 × 512
就是方图。
768 × 512
就是横图。
512 × 768
就是竖图。
其三:批量大小是什么?
批量大小意思是:一次生成几张图。
比如:批量大小 = 1,一次生成 1 张。批量大小 = 4,一次生成 4 张。
因为我们的显存比较的小,所以最好每一次生成一张图就可以了。
今日学习comfyui结束,等明天接着学习吧!