什么叫进程?
程序和可执行程序是一回事,包括指令的本质也是程序,只要是文件,就一定是存在磁盘上,根据计算机体系结构,磁盘属于外设,一切程序要运行第一步肯定是要加载到内存里,在我们的操作系统里可以同时运行多个程序,每一个都要加载到内存,这时候就会产生很多的进程,操作系统要管理这些进程,就需要先描述再组织,获取这些进程的数据是第一步,再用结构体去描述每一个进程的属性,最后用数据结构将这些结构体组织起来,值得一提的是,我们还没有去启动进程时候的第一个软件就是操作系统,它也在内存里。那到底什么是进程?程序的代码和数据从磁盘加载到内存准备要运行,操作系统为了管理这些进程就需要先有描述每一个进程的结构体,结构体+程序本身就称为进程,所以进程 = 内核数据结构对象(内核里的一个结构体变量) + 自己程序的代码和数据。
知道了进程的概念,那什么不是进程呢?程序不是进程,程序由代码和数据构成,说白了就是01数据,它的本质就是文件。我们知道程序运行要先从磁盘加载到内存,那程序加载到内存之后的数据和代码是不是进程呢?也不是。由上边得出的结论,对于进程来讲,对重要的其实是描述它的结构体,里边包含了进程的属性和信息,只有结构体+加载到内存的程序才叫进程。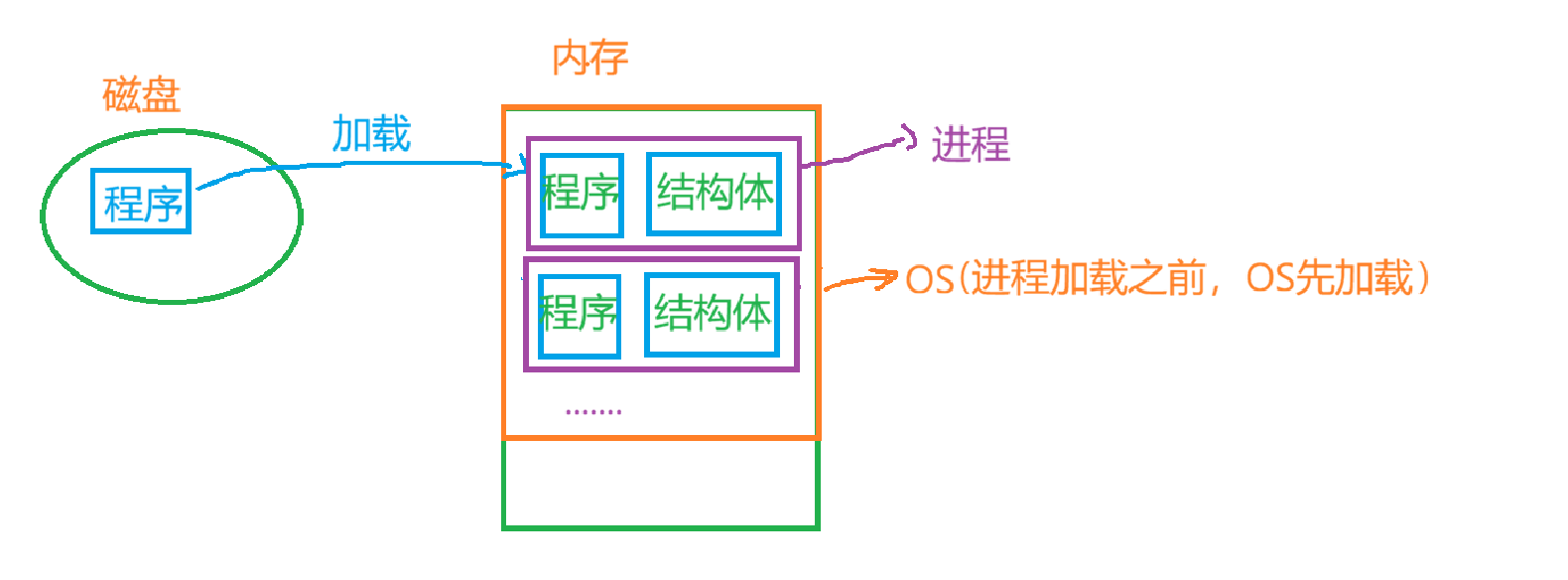
PCB
PCB就是描述进程的那个结构体的名称,它是操作系统这个学科里描述进程结构体的统称,具体到Linux里,描述进程的结构体的名字叫struct task_struct,里边一定包含了进程的所有属性,直接或者间接通过这个结构体找到。OS管理进程,就是在管理PCB,平时在Linux里./运行程序,使用指令(本质上就是一个可执行文件),windows里双击,手机里打开APP,这些都是在启动进程,就这样理解,只要是从外设加载到内存并且有相应的结构体去描述的过程都叫启动进程。
进程属性
下边列出的就是tast_struct里包含的各种进程的属性,tast_struct是个结构体,我不管它这里边的每个属性具体有多复杂,我能确定一点,这些属性本质上就是变量(不管是int,float,自定义类型)。
标⽰符(pid): 描述本进程的唯⼀标⽰符,⽤来区别其他进程。(就像学校里的学号)
状态: 任务状态,退出代码,退出信号等。(就像播放音乐时候的开关状态)
优先级: 相对于其他进程的优先级。(决定了获得CPU资源的先后,就像食堂排队吃饭一样,有优先级的本质就是资源少人多,僧多粥少,放到电脑里就是CPU资源少,进程多)
程序计数器: 程序中即将被执⾏的下⼀条指令的地址。(CPU内有很多的寄存器用来保存执行过程中的各种临时数据,CPU执行代码是从上往下一行行执行的,程序的代码很多,CPU怎么知道代码执行到了哪一行呢?CPU里还有一个寄存器叫EIP(PC指针),就是程序计数器)
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。(简单一说,当CPU选中某个进程的时候,这个进程有其对应的PCB,那光有PCB无法找到这个进程对应程序的代码和数据呀,因此内存指针的作用就是帮助CPU去找到它们)
上下⽂数据: 进程执⾏时处理器的寄存器中的数据休学例⼦,要加图CPU,寄存器。
..........
接下来重点说一下上下文数据,首先来看一个问题,一个进程执行代码会占有CPU,那它会把自己的代码执行完才放弃CPU给下一个进程吗?不会,试想一下你现在在执行一个代码,假如说是while(1)死循环,要是真得等一个进程执行完才行,那OS不就死机了吗?当代计算机会给每一个进程分配一个时间片,时间片执行完毕就自动出让CPU,让另一个进程执行,这叫基于时间片的轮转调度,时间片你就可以理解为是CPU给它旗下的每一个进程分配的执行时间,该进程的执行时间结束就会立马出让它所占据的CPU资源,因此一个进程没有执行完就有可能会把CPU让出去。由于时间片的到达,就会存在进程切换和调度的动作,说白了就是进程现在退出了到时候又回到之前的位置继续执行,那我当前这个进程再要回到原来的位置上继续执行,它是怎么找到的呢?答案就是保留上下文数据,这个上下文数据就是进程对应的CPU内的寄存器的临时数据,当进程随着时间片的结束退出CPU的时候,CPU会保存它的上下文数据,这个数据会随进程退出的时候一起带走,等它再回来的时候就恢复上下文数据到相应的寄存器里就可以继续接着上一次退出的地方运行了,至于上次执行到了哪条指令,不是有程序计数器嘛,上下文数据也包括了EIP里的数据。
注意,上下文数据是指的寄存器里的临时数据,是数据,不是寄存器本身。CPU硬件只有一套,CPU内的寄存器硬件可以在不同的时间段保存不同进程的数据。再通俗一点就是,寄存器是唯一的,但数据可以是多份的,对应不同的进程,因此上下文数据是进程私有的数据,随着时间片的结束,上下文数据就保存在进程对应的PCB里(这对于老式内核来说是这样的,所以才有上下文数据这个属性)。
标示符
一个进程如何获取自己的标示符?获取自己的标识符就是在获取自己的task_struct结构体内部的属性值,在我上一篇文章里说过,人无法直接去操控操作系统里的数据结构,这样不安全,因此我现在想获取这个进程的标识符就必须通过相应的系统调用去帮我们完成,这个系统调用就是getpid,哪个进程在调用就是获取该进程自己的pid。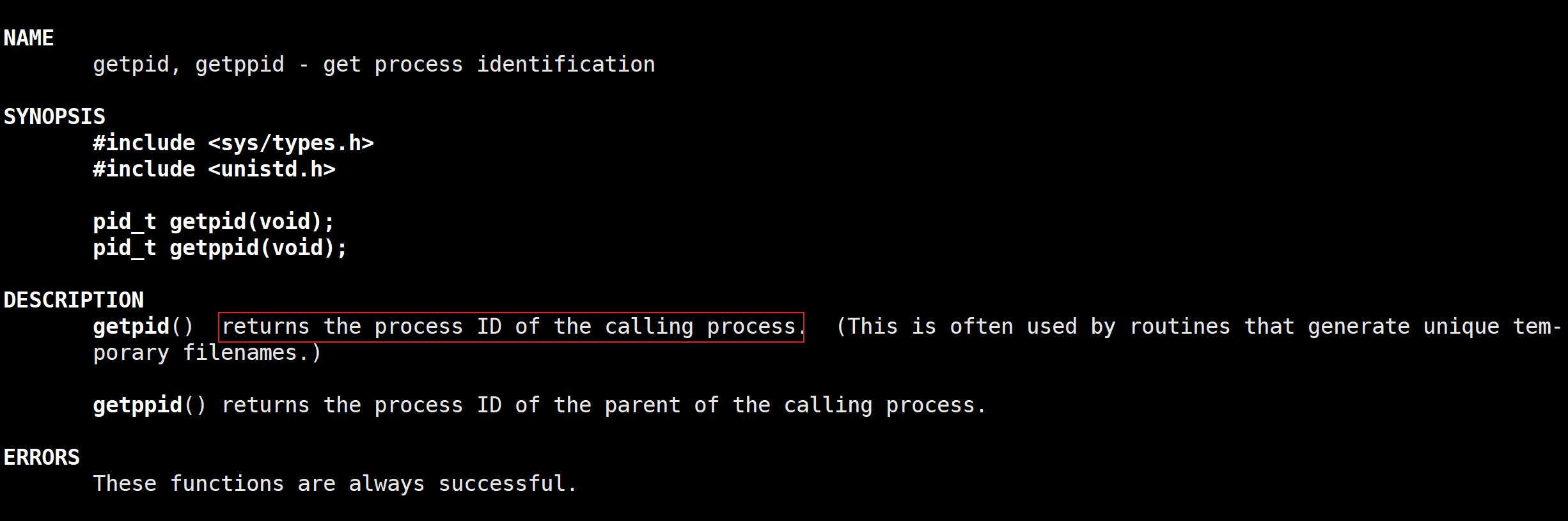
只要有while(1)死循环,进程就可以一直运行不退出,但不代表没有死循环的就不是进程,只要是运行可执行程序,都是进程,只不过运行完就退出了,不好观察。(注意下边打错了,应该是标示符)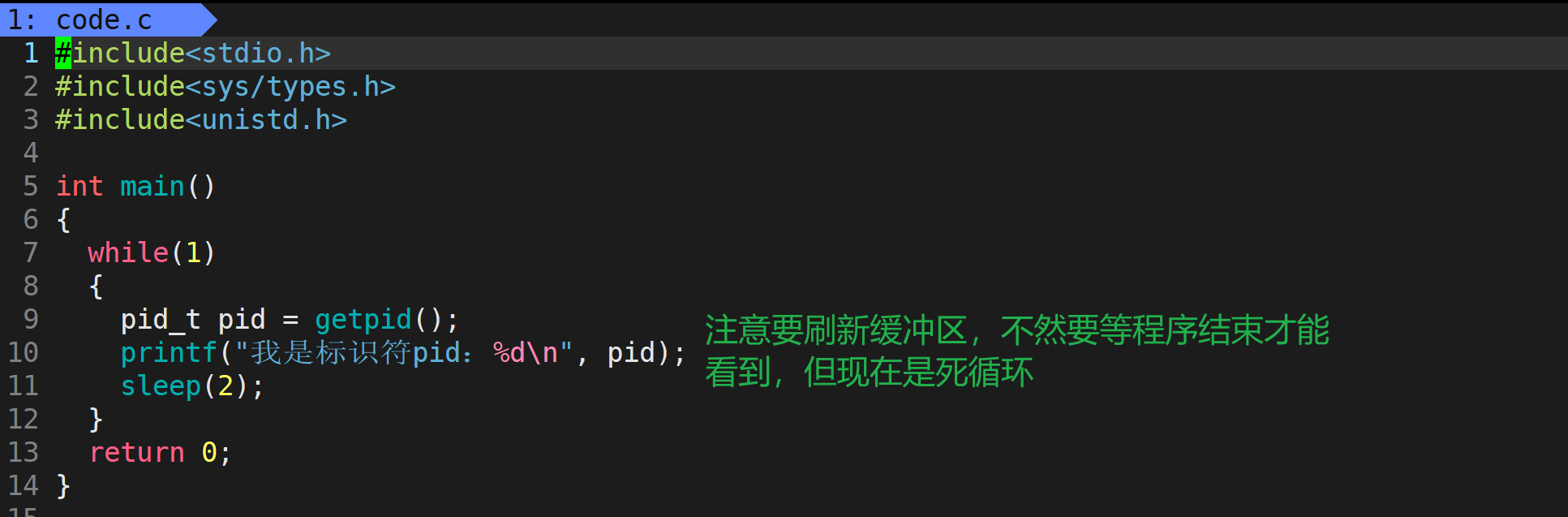

现在我们知道了上边的程序是一个进程,标示符为15156,怎么证明呢?首先你必须得让程序一直在运行,一直运行就代表这个进程一直存在,然后有个ps axj指令,可以查看系统中所有的进程。而且上文也说了,指令本质就是可执行文件,因此执行指令也是在启动进程,所以由下图就可以知道code.exe确实是一个进程且PID为18630,不知道大家有没有发现怎么同一个code.exe的进程PID不一样,原因就是之前关掉过这个进程,当重新启动这个进程的时候,此进程非彼进程,又会有新的PID,然后这个PID的大小其实是递增的,系统内部有个计数器(全局变量),每启动一个进程,计数器就++,当进程分配完了,计数器的值又会从0开始,那为什么我看到的code.exe的进程的PID不是连续增大的,是因为在我终止进程和启动进程的中间,系统可能又启动了好几个其他的进程。(注意可以用 ; 把两条命令集然起来,或者还可以用&&)
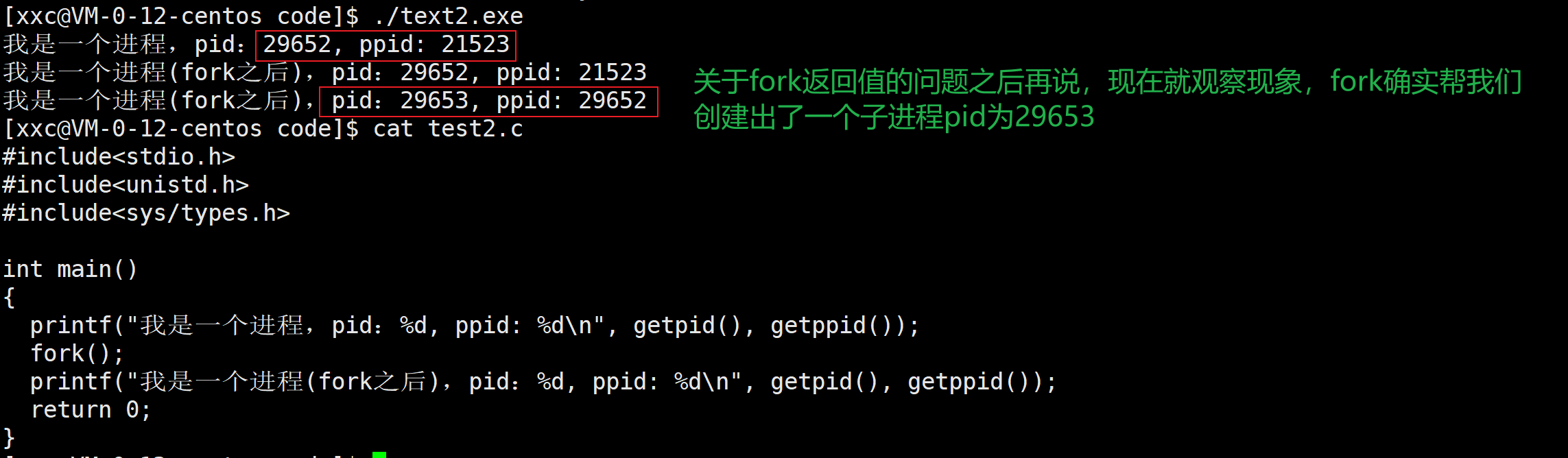
除了进程自己的pid,它还有一个ppid叫做父进程标示符,在Linux系统中,新的进程,往往是通过父进程的方式创建出来的。如下图我们获取了所有进程并且通过ppid筛选出了当前进程的父进程,发现就是bash,命令行解释器,也就是说我们执行的所有的指令都是bash的子进程,并且shell外壳自己就是一个进程。通过ppid我们也可以知道,进程结构是树形结构的,每一个进程有对应的父进程,也可以有子进程。
如何创建进程(子进程)(通过代码的方式)?
创建子进程的本质就是OS内部多了一个子进程,我们不可能直接在操作系统里创建一个task_struct吧,用户不能直接和操作系统进行交互,因此创建子进程一定是通过系统调用的方式,fork,就是来创建子进程的,包括bash也是调用fork来创建子进程的。
/proc:
在我们的根目录下有一个叫proc的目录,里边包含了很多用数字命令的目录,这些数字就是当前正在运行的进程的PID,因此在/proc里就能实时看到当前正在运行的所有进程。每创建一个进程,/proc目录下就会多一个以这个进程的PID命名的目录,当然,如果终止了一个进程,那/proc里就会自动把以该进程PID命名的目录关闭。(Linux下一切皆文件)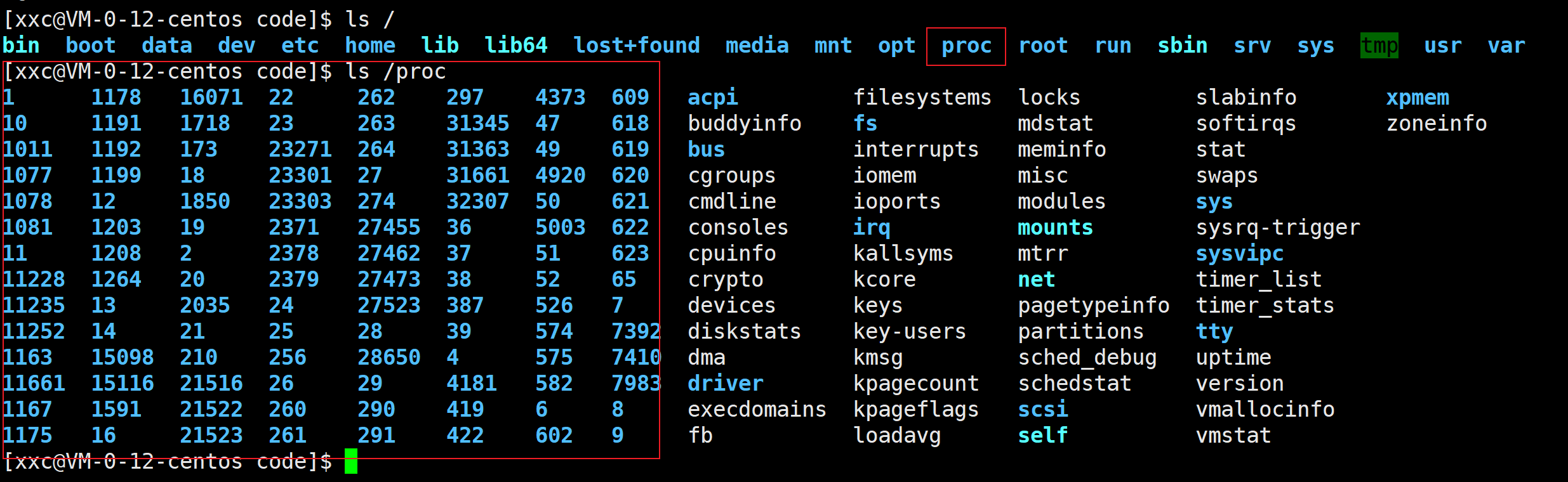
随便打开一个进程的文件夹,就能在里边看到进程的所有属性,ps ajx显示的进程属性内容也是从它的/proc/PID里筛选出来的,一个进程有非常多的属性,其中有exe,表示的是进程在启动之前的那个可执行文件,还有一个属性是cwd,cwd就是当前进程的工作路径,就是我们所谓的当前路径,每一个进程在启动的时候,都默认有自己的cwd,那我们怎么修改它呢?肯定还是无法直接修改PCB里的属性值,那肯定是用系统调用,chdir可以修改进程的工作路径,它的参数就是你想修改的路径字符串。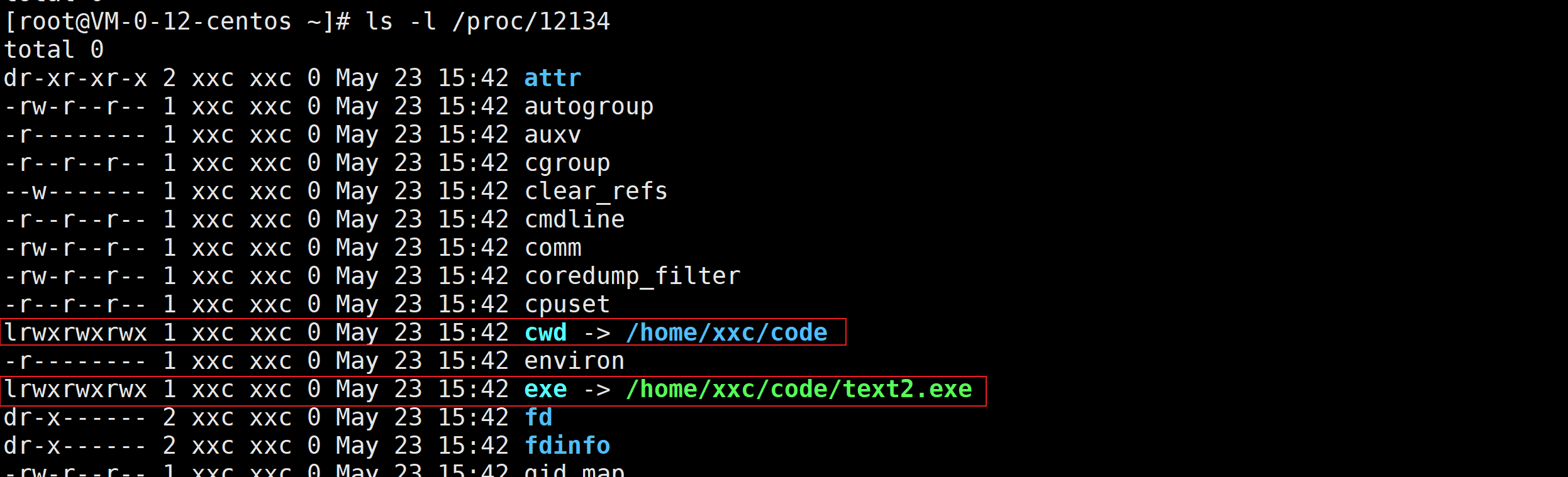

重谈fork
上文已经知道了fork是创建子进程的,由下边的现象可知,fork之后,代码是共享执行的,就是如下所示嘛,fork之后是一个死循环,父进程打印一句之后,子进程也打印一句。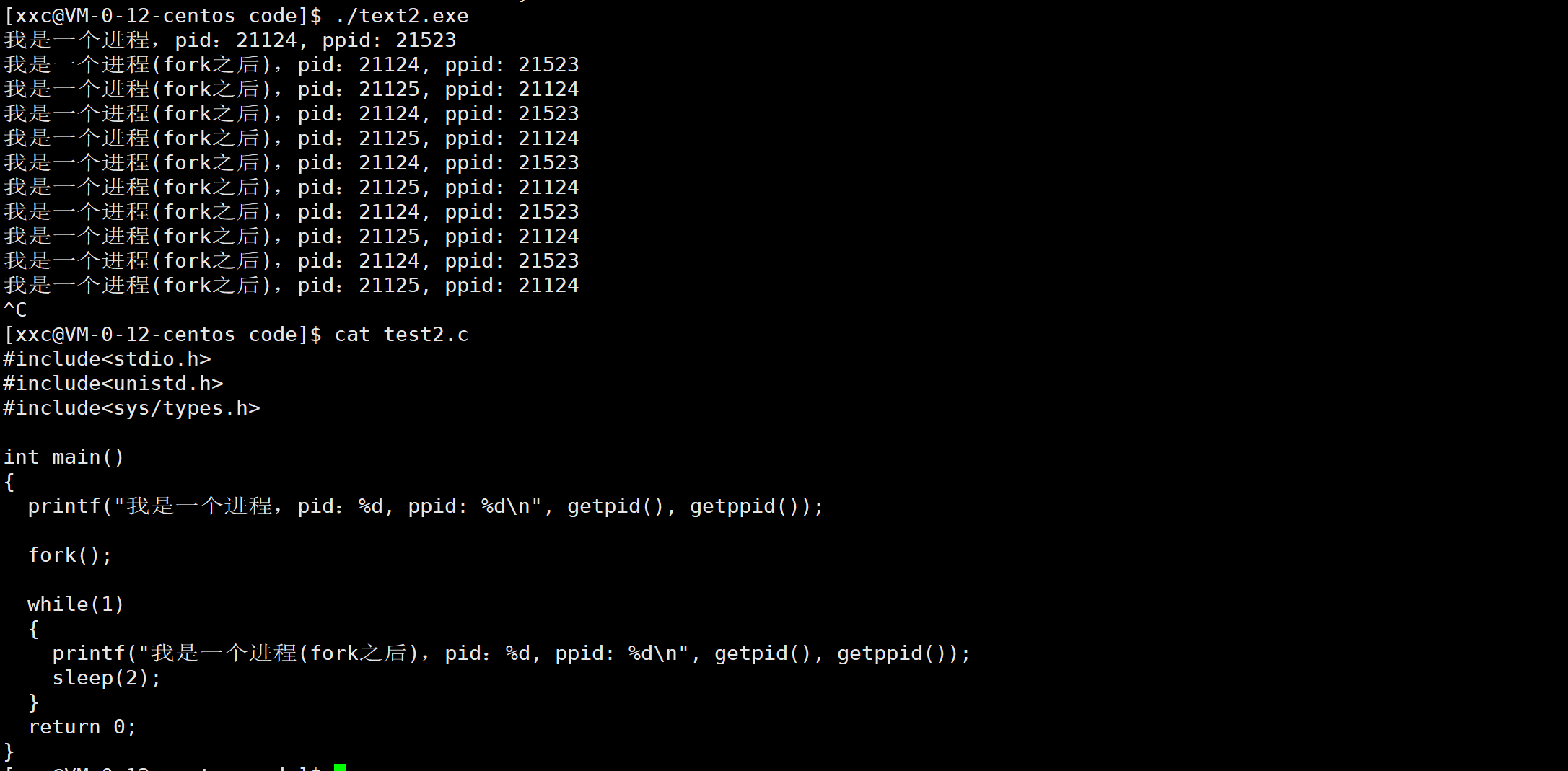
为什么父进程要创建子进程?本质上是为了让子进程完成任务。fork是为了实现分流,利用它的返回值,查看man手册可以知道fork是有两个返回值的,如果创建子进程成功就返回子进程的PID给父进程,返回0给子进程。如果失败就返回-1给父进程,并且设置一个错误值。所以我们利用fork的返回值就可以用来进行父子进程分流,一份代码,两个进程。
小实践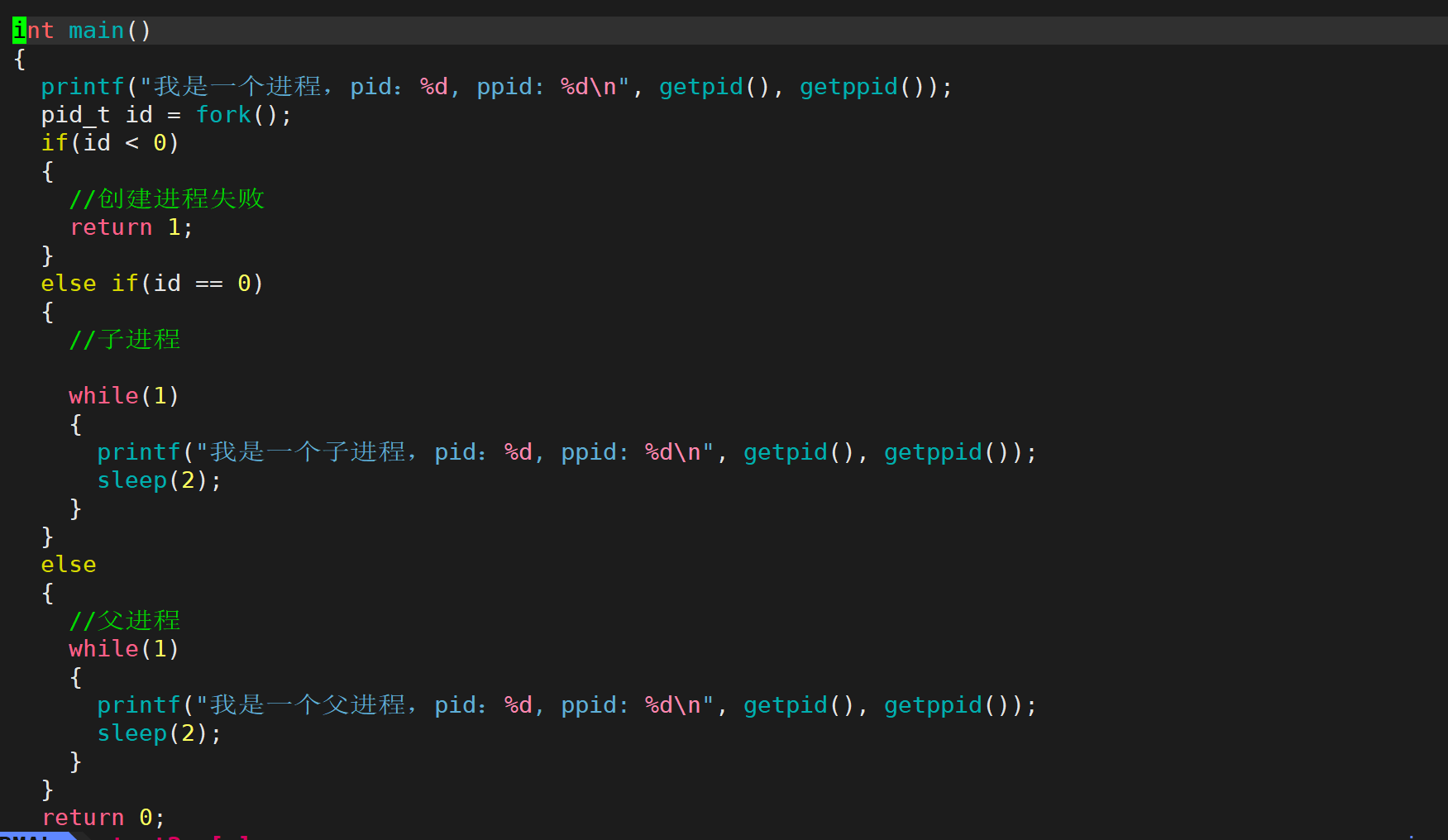

三个问题
认知:
对于一个父进程来说,有它自己的task_struct,task_struct内部有指针指向可执行程序的代码和数据,方便将来CPU调度的时候执行,而我现在在代码里边用fork创建了一个子进程,只要是进程,我先不管怎么来的,肯定是有它的PCB,而实际上子进程的PCB是以父进程的为模板来创建的,把父进程里的属性拷贝给子进程,当然也有子进程自己的属性需要改改。父进程的代码和数据是从磁盘上加载到内存里加上PCB才形成一个进程的,它是一个完整的进程,而子进程的代码和数据哪儿来呢?默认是没有的,没有就没法运行,但是子进程内部有各种指针,默认是指向的就是父进程的代码和数据,说白了就是在默认情况下,fork之后的代码和数据,一般都是父子共享的。这也就说明了为什么fork之后的代码怎么父进程执行完,子进程也执行。
问题1:为什么给子进程返回的是0,给父进程返回的是子进程的PID?
父进程和子进程的比例是 1 : n 的。给子进程返回0是因为不存在父进程找不到的问题,getppid就能找到了,但是一个父进程有很多个子进程,给父进程返回子进程的PID是为了标识特定的一个子进程,未来控制特定的子进程。
问题2:fork(),一个函数怎么返回了两次?
如果一个函数已经准备return了,那么它的核心功能已经做完了,同理,fork函数准备返回之前,它的核心功能(创建一个子进程,并且创建完毕就要能被OS调度执行了)也已经做完了,又由上文说的,fork之后,父子进程共享代码,这句话说的就是子进程被创建之后的事,return语句本身也是一句代码,也就是说,fork函数内部将子进程创建完毕之后,return语句也是属于子进程被创建之后的代码,自然也要父子共享,被执行两次,所以一个fork函数,返回了两次。
问题3:为什么一个id可以同时接受两个fork的返回值?(代码见上文小实践那里的id)
这里涉及到后边的知识,先说结论,后边会重谈的。源文件被编译链接之后,变量名就变成一个地址了,这个地址叫做虚拟内存地址,在虚拟地址空间里,最终会被转移到物理内存里,而父子进程都有自己的虚拟地址空间,fork返回的时候,返回值id在它们的虚拟地址空间里都会存一份,两个空间里id的地址是一样的,如果发现父子进程之中有一个的id被修改了,在物理内存里就会新开辟一块空间把修改的id的内容写进去(父子进程的虚拟地址空间不一样,但是它们都关联同一个物理内存),这叫写时拷贝,而return语句的本质就是在写入,return了两次就写了两次,物理内存里就有两块互不相关的空间存着两次返回的id值。(大概了解一下就行了)