《构建 Claude Code 的经验:Prompt Caching 就是一切》深度解析
原文作者:Thariq (@trq212),Claude Code 核心工程师 @ Anthropic
发布时间:2026 年 2 月 20 日
一、核心论点
文章的核心论点只有一句话:
"Cache Rules Everything Around Me"------缓存统治一切。
对于 Claude Code 这类长周期 Agentic 产品,Prompt Caching(提示词缓存)是使其在成本和延迟上可行的根本基础设施。整篇文章围绕"如何从系统设计层面将提示词缓存优化到极致"展开。
二、Prompt Caching 基础原理
2.1 是什么
Prompt Caching 允许 API 复用之前请求中已完成的计算,避免对相同内容重复计算,从而显著降低延迟和成本。
2.2 为什么需要缓存:LLM 推理的计算特性
要理解缓存,先理解 LLM 处理文本时做了什么。
大语言模型在生成每个输出 token 时,需要"关注"(Attention)输入序列中的所有历史 token。这个过程会产生大量中间计算结果,称为 KV Cache(Key-Value 矩阵)------即每个输入 token 经过 Transformer 各层计算后留下的中间状态。
没有 Prompt Caching 时:
第 1 次请求:[System(2000 tokens) + 工具(5000 tokens) + 对话(500 tokens)]
→ 全部 7500 tokens 从零计算,生成 KV Cache
→ 响应完成,KV Cache 丢弃
第 2 次请求:[System(2000 tokens) + 工具(5000 tokens) + 对话(1000 tokens)]
→ 全部 8000 tokens 再次从零计算
→ 前 7000 tokens 内容完全没变,却全部重算了一遍这相当于每次打开同一本书,都要重新把它打印一遍。
有 Prompt Caching 后:
第 1 次请求:[System + 工具 + 对话(500)] → 全量计算,KV Cache 保存在服务器端
第 2 次请求:[System + 工具 + 对话(1000)] → 前 7000 tokens 直接读缓存,只计算新增的 500 tokens2.3 工作机制:前缀匹配
核心机制:精确前缀匹配(Exact Prefix Matching)
API 通过比对请求开头的内容是否与已缓存的前缀完全一致,来决定是否复用 KV Cache:
缓存中存储的前缀:[A][B][C][D] ──── cache_control 断点
新请求的前缀: [A][B][C][D][E][F](新增了 E、F)
↑
完全匹配!命中缓存,只需计算 E、F关键推论:前缀中任何一处变化,该位置及之后的所有缓存全部失效。
缓存中存储的前缀:[A][B][C][D]
新请求的前缀: [A][B][X][D] ← 第三个位置由 C 变成了 X
↑
从这里开始全部缓存失效,[D] 也没用了,必须全部重算这就是为什么提示词的内容顺序如此重要------哪怕只是把两个工具的定义对调一下位置,整个工具列表之后的所有缓存都会作废。
2.4 cache_control 断点
在 API 请求中,通过在消息内容上标记 cache_control 来指定缓存断点:
json
{
"role": "user",
"content": [
{
"type": "text",
"text": "你是一个编程助手,以下是项目规范...",
"cache_control": {"type": "ephemeral"}
}
]
}断点的含义:"请把从请求开头到这个断点为止的所有内容缓存起来。"
可以设置多个断点,形成多级缓存层次。API 从最长的匹配前缀开始尝试命中:
断点布局示意:
[静态 System Prompt ──────────────────────────────── ✂ 断点 1] 全局缓存
[工具定义 ─────────────────────────────────────────── ✂ 断点 2] 全局缓存
[CLAUDE.md & Memory ─────────────────────────────── ✂ 断点 3] 项目级缓存
[Session 上下文 (env/MCP/style) ──────────────────── ✂ 断点 4] 会话级缓存
[对话消息 ── 每轮增长,不缓存]
命中断点 4:只需计算新增的对话消息(最佳情况)
命中断点 2:需重算 CLAUDE.md + Session 上下文 + 对话消息
全部未命中:从头全量计算(最差情况,成本最高)
2.5 缓存的成本结构
Prompt Caching 的计费分两部分:
| 操作 | 触发时机 | 相对成本 |
|---|---|---|
| Cache Write(写缓存) | 首次建立该前缀的缓存 | 略高于普通 Input(需要存储开销) |
| Cache Read(读缓存) | 后续请求命中已有缓存 | 约为普通 Input 的 10% |
普通 Input Token: ████████████████ 100%
Cache Write(首次): █████████████████░ ~125%
Cache Read(命中): ██ ~10%盈亏平衡点: 一个前缀只要被复用 2 次以上,总成本就低于每次全量计算。复用次数越多,节省越显著。
这也解释了为什么 Claude Code 把工具定义(占据大量 token)放在最稳定的位置:这些内容每次会话都会复用,缓存收益极高。
2.6 缓存的生命周期(TTL)
缓存不是永久有效的。API 提供两个 TTL 选项:
| TTL 值 | 持续时间 | 说明 |
|---|---|---|
"5m" |
5 分钟(默认) | 不指定 ttl 时的默认值 |
"1h" |
1 小时 | 需要显式设置 |
每次命中会刷新 TTL 计时;超过 TTL 未被访问则缓存自动过期,下次请求需重新全量计算并写缓存。
如何将 TTL 设置为 1 小时(API 层面):
在每个 cache_control 断点对象中添加 "ttl": "1h":
json
{
"type": "text",
"text": "你是一个编程助手...",
"cache_control": {
"type": "ephemeral",
"ttl": "1h"
}
}在 Claude Code CLI 中开启 1 小时缓存:
通过环境变量控制:
bash
export ENABLE_PROMPT_CACHING_1H=1设置后,Claude Code 内部构建所有 cache_control 断点时会自动使用 "ttl": "1h" 代替默认的 5 分钟。
永久生效可写入 shell 配置文件(~/.zshrc 或 ~/.bashrc):
bash
echo 'export ENABLE_PROMPT_CACHING_1H=1' >> ~/.zshrc
source ~/.zshrc自行调用 Claude API 构建 Agent(如 kiro2cc-proxy) 则需要在代码里对每个 cache_control
断点显式传入 "ttl": "1h",无法依赖上述环境变量。
这也是 Claude Code 团队像监控系统可用性一样监控缓存命中率 的原因------命中率骤降往往意味着
某处变更破坏了前缀稳定性,或会话中断超过 TTL 导致缓存批量过期,成本会显著上升。
2.7 最小缓存阈值
并非任何长度的前缀都会被缓存。API 要求前缀达到一定的最小 token 数量,才会触发缓存存储(避免缓存管理开销大于收益)。这意味着:
- 非常短的 System Prompt 可能不会被缓存
- Claude Code 将大量静态内容(工具定义、CLAUDE.md)堆叠在请求前端,有一部分原因正是为了确保前缀足够长,稳定触发缓存阈值
三、提示词布局策略:静态在前,动态在后
3.1 Claude Code 的四层布局
| 层级 | 内容 | 缓存作用域 |
|---|---|---|
| 1 | 静态 System Prompt + 工具定义 | 全局缓存(所有会话共享) |
| 2 | CLAUDE.md 项目配置 | 项目级缓存(同项目内共享) |
| 3 | Session 上下文 | 会话级缓存(同会话内共享) |
| 4 | 对话消息(Messages) | 不缓存前缀 |
越靠前的层越稳定,越多请求能共享该前缀的缓存命中。

3.2 容易破坏缓存顺序的常见陷阱
实践中,以下看似无害的操作都会破坏缓存:
-
在静态 System Prompt 中嵌入详细时间戳
每次请求时间不同 → 前缀不同 → 全部缓存失效
-
工具定义顺序非确定性
如工具列表通过 Map/Set 生成,每次顺序可能不同 → 缓存失效
-
动态更新工具参数
如
AgentTool的可调用子 Agent 列表发生变化 → 缓存失效
四、用 Messages 代替修改 System Prompt
4.1 问题场景
某些信息会随时间变化,例如:
- 当前时间
- 用户刚刚修改的文件内容
- 配置变更
4.2 错误做法
直接更新 System Prompt → 导致整个前缀缓存失效 → 每次都付全价
4.3 正确做法:<system-reminder> 标签
Claude Code 的实际方案:在下一轮用户消息或工具结果中,附加一个 <system-reminder> 标签来传递更新信息,而不是修改 System Prompt。
用户消息(下一轮):
"请继续..."
<system-reminder>当前时间是 Wednesday,2026-02-20 03:57 UTC</system-reminder>效果: System Prompt 保持不变 → 缓存前缀不变 → 命中缓存 → 节省成本
这正是本项目 kiro2cc-proxy 中
<system-reminder>注入逻辑的设计依据。
五、不要在会话中途切换模型
5.1 反直觉的成本计算
提示词缓存是模型独立的。 每个模型有自己独立的缓存空间,跨模型不共享。
反直觉示例:
假设当前 Opus 会话已积累 100k tokens 的缓存前缀,此时有一个"简单问题"需要回答:
- 直觉判断:切换到 Haiku 更便宜(单价低)
- 实际结果:切换到 Haiku 更贵,因为需要从零重建 Haiku 的缓存前缀,100k tokens 全部按全价计算
结论: 在长会话中,切换模型的代价不只是单次请求的价格差,而是丢失全部已积累缓存的代价。
5.2 正确的跨模型方案:Subagent + Handoff Message
当确实需要切换模型时,正确做法是:
- 主模型(Opus)准备一条精简的 Handoff Message,总结当前任务状态
- 将该消息作为新上下文传给 Subagent(Haiku)
- Subagent 从新的短上下文开始,不需要继承完整历史
Claude Code 的实践: Explore 子 Agent 使用 Haiku,由 Opus 准备 handoff,而非直接在主会话中切换模型。
六、不要在会话中途增删工具
6.1 为什么不能动态增删工具
工具定义是缓存前缀的一部分。在会话过程中增加或移除任何工具 → 整个缓存前缀失效。
常见的错误直觉: "我应该只给模型当前需要的工具,以节省 Token 和避免干扰。"
实际代价: 每次调整工具集都会导致缓存完全失效,远超"多几个工具定义"的 Token 成本。
6.2 Plan Mode 的反直觉设计
Plan Mode(计划模式) 是一个极佳的"围绕缓存约束进行功能设计"的案例。
直觉实现方案(错误):
用户进入 Plan Mode → 替换工具集 → 只保留只读工具此方案每次切换 Plan Mode 都会破坏缓存。
Claude Code 的实际方案:
始终保持完整工具集不变
增加两个专用工具:EnterPlanMode、ExitPlanMode
用户启用 Plan Mode →
向模型发送 system message:"你现在处于 Plan Mode,
只能探索代码库,不能编辑文件,完成计划后调用 ExitPlanMode"额外收益: 因为 EnterPlanMode 本身是一个模型可以主动调用的工具,模型在遇到复杂问题时可以自主进入 Plan Mode,无需用户触发,且不会产生任何缓存失效。
七、工具搜索:延迟加载代替移除
7.1 问题背景
Claude Code 可以加载数十个 MCP 工具。将所有工具的完整 Schema 都放入每次请求中成本高昂,但移除工具又会破坏缓存。
7.2 解决方案:defer_loading
核心思路:用轻量级 Stub 占位,按需加载完整 Schema
json
// 延迟加载的工具 stub(极低 Token 成本)
{
"name": "some_mcp_tool",
"defer_loading": true
}流程:
- 所有工具以 stub 形式存在于请求中(保持前缀稳定)
- 模型需要某工具时,调用
ToolSearch工具搜索它 - API 动态加载该工具的完整 Schema
- 此后该工具可正常调用
效果:
- 缓存前缀稳定(stub 始终相同、顺序固定)
- 按需支付完整 Schema 的 Token 成本
- 通过官方 API 的
tool_search工具可直接使用此能力
八、Context 压缩(Compaction)与 Cache-Safe Forking
8.1 什么是 Compaction
当对话消耗完整个 Context Window 时,系统需要对历史对话进行摘要压缩,然后以压缩后的摘要开启新会话继续工作。
8.2 简单实现的缓存陷阱
错误的简单实现:
独立 API 调用:
- System Prompt:不同(简化的摘要指令)
- 工具:无(简化处理)
- 历史:完整历史
- 动作:生成摘要实际代价: 压缩时的请求前缀与主对话完全不同 → 整个历史(可能数十万 Token)全部按全价计算 → 用户为一次压缩付出巨额成本。
8.3 Cache-Safe Forking 方案
Claude Code 的正确实现:
压缩请求使用与父会话完全相同的:
- System Prompt
- 用户上下文
- 系统上下文
- 工具定义
然后:
-
前置父会话的完整对话历史
-
在末尾追加压缩指令作为新的用户消息
[相同 System Prompt + 相同工具] ← API 视角:与父会话前缀完全一致 → 命中缓存
[父会话历史 messages] ← 全部命中缓存,只计算缓存价格
[新增:压缩指令 message] ← 只有这一条是新 Token,按全价计算
效果: 压缩成本从"全部历史按全价"降至"只有压缩指令按全价"。
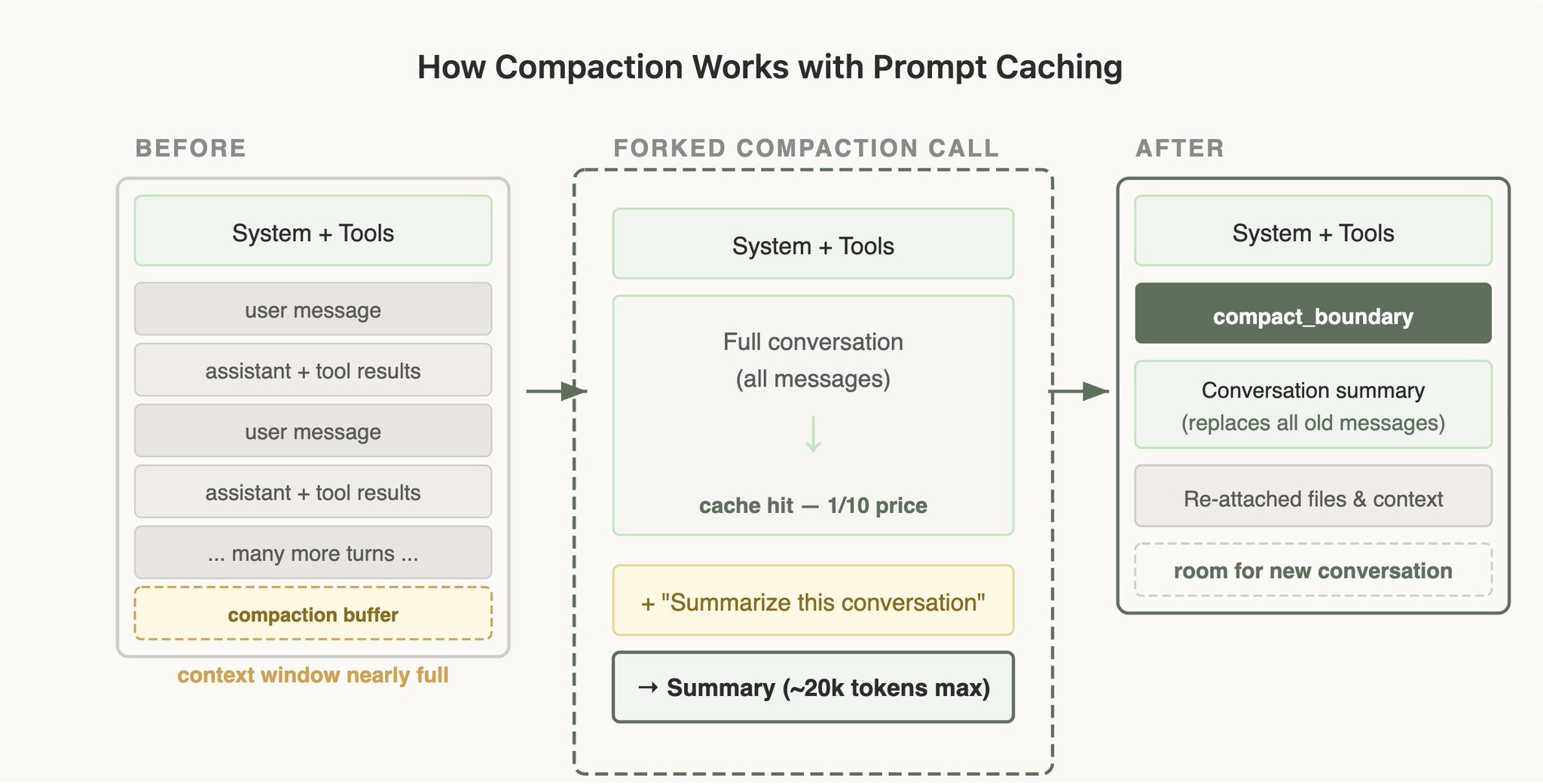
8.4 Compaction Buffer
Cache-Safe Forking 方案要求在压缩时能够重发完整历史,因此需要预留一个 Compaction Buffer------在 Context Window 即将耗尽前提前触发压缩,确保有足够空间容纳完整历史 + 压缩指令 + 摘要输出。
8.5 API 内置 Compaction
基于 Claude Code 的这些实践经验,Anthropic 已将 Compaction 能力直接内置到 API 中,开发者无需自行实现这些复杂细节。
九、缓存命中率监控
9.1 监控级别
"像监控系统可用性(Uptime)一样监控你的缓存命中率。"
Claude Code 团队的实践:
- 对缓存命中率设置告警(Alert)
- 缓存命中率过低时宣布 SEV(严重事件,Severity Event)
- 将缓存命中率视为核心业务指标
9.2 为什么这么重要
高缓存命中率直接影响:
- 成本:缓存命中的 Token 价格是全价的 10%(Input)
- 延迟:复用计算结果,响应更快
- 速率限制:更低成本使 Anthropic 能为订阅用户提供更慷慨的速率限制
十、经验总结(原文 Lessons Learned)
| # | 原则 | 关键点 |
|---|---|---|
| 1 | 前缀匹配决定一切 | 正确排列提示词顺序,缓存自然生效 |
| 2 | 用 Messages 代替修改 System Prompt | <system-reminder> 传递动态信息 |
| 3 | 不要中途切换模型或增删工具 | 用工具建模状态转换,用 defer_loading 延迟加载 |
| 4 | 像监控可用性一样监控缓存命中率 | SEV 告警机制 |
| 5 | Fork 操作必须共享父会话前缀 | Cache-Safe Forking 方案 |
基于 Claude Code 工程师 Thariq @trq212 原文整理分析