
🔥铅笔小新z:个人主页
🎬博客专栏:Linux学习
💫滴水不绝,可穿石;步履不休,能至渊。

1. 理解"文件"
1-1 狭义理解
从狭义上讲,文件就是存放在磁盘里的数据集合。磁盘是一种永久性存储介质 ,所以文件的数据可以长期保存,不会因为断电而丢失。同时,磁盘也是一种外设 (既可以从它读数据------输入设备,也可以往它写数据------输出设备)。因此,我们对文件的所有操作,本质上都是在对外设进行输入和输出,简称 IO(Input / Output)。
1-2 广义理解------Linux 下一切皆文件
在 Linux 的世界里,有一个非常核心的思想:一切皆文件。
什么叫"一切皆文件"?意思是:键盘、显示器、网卡、磁盘、甚至进程之间的通信管道......这些东西在 Linux 眼里都被抽象成了"文件"。你操作键盘输入,就像读一个文件;你往显示器输出,就像写一个文件。这种抽象化的设计,让开发者只需要学会一套文件操作的 API,就能操作几乎所有类型的硬件资源,大大简化了编程模型。
1-3 文件操作的归类认知
- 空文件也占磁盘空间 :一个 0KB 的文件并不是"什么都不占",它还要存储文件的属性信息(也叫元数据),比如文件名、创建时间、权限、大小等。
- 文件 = 属性(元数据)+ 内容:对文件的操作,无非就是两大类------操作文件的内容(读写数据),或者操作文件的属性(修改权限、重命名等)。
1-4 系统角度
- 操作文件本质是进程在操作文件:你运行一个程序,这个程序就是一个进程,它去打开文件、读写文件,背后都是这个进程在跟操作系统打交道。
- 磁盘的管理者是操作系统:普通程序不能直接操作磁盘,必须通过操作系统来间接完成。
- 库函数只是"马甲" :C 语言的
fopen、fread、fwrite等等,并不是直接操作磁盘的,它们是对底层系统调用接口 的封装。真正干活的是操作系统提供的open、read、write等系统调用。
📌 知识点总结:文件是存储在磁盘上的数据集合,包含属性(元数据)和内容两部分。Linux 的设计哲学是"一切皆文件",键盘、显示器等各种硬件都被抽象成文件,开发者只需要用同一套 IO 接口就能操作各种资源。进程对文件的操作,最终是通过操作系统提供的系统调用接口来完成的,C 语言的库函数只是对这些系统调用的封装,方便我们使用。
2. 回顾 C 语言文件接口
2-1 打开文件
c
#include <stdio.h>
int main()
{
// 以"写入"方式打开名为 myfile 的文件
// 如果文件不存在,会创建它
FILE *fp = fopen("myfile", "w");
if (!fp) { // 如果打开失败,fp 为 NULL
printf("fopen error!\n");
}
// 故意让程序不退出,方便我们查看进程信息
while (1);
fclose(fp); // 关闭文件
return 0;
}思考:打开的文件在哪个路径下?
我们在代码里只写了 "myfile",没写绝对路径,那这个文件会被创建在哪里?答案是程序的当前工作目录。
系统怎么知道进程的当前路径呢?我们可以通过 ls /proc/[进程id] -l 命令来查看正在运行的进程的信息。其中:
cwd:指向当前进程运行目录的符号链接。exe:指向启动当前进程的可执行文件的完整路径的符号链接。
核心理解 :打开文件本质上是进程在打开文件,进程知道自己当前在哪个目录下工作。所以即使我们只给了一个不带路径的文件名,操作系统也知道该把文件创建在哪里。
📌 知识点总结 :fopen 是 C 标准库提供的打开文件的函数,返回一个 FILE* 指针。如果打开失败,返回 NULL。文件不带路径时,默认创建在进程的当前工作目录下。每个正在运行的进程在 /proc/[pid] 目录下都有对应的信息,其中 cwd 记录着进程的当前工作目录。
2-2 写文件
c
#include <stdio.h>
#include <string.h>
int main()
{
// 以写入方式打开文件
FILE *fp = fopen("myfile", "w");
if (!fp) {
printf("fopen error!\n");
return 1;
}
const char *msg = "hello bit!\n";
int count = 5;
// 循环写入 5 次
while (count--) {
// fwrite(数据, 每次写入的字节数, 次数, 文件指针)
fwrite(msg, strlen(msg), 1, fp);
}
fclose(fp); // 关闭文件
return 0;
}📌 知识点总结 :fwrite 用于向文件写入数据。它的参数分别是:要写入的数据、每次写入的字节数、写入的次数、目标文件指针。这里 strlen(msg) 是 "hello bit!\n" 的长度(11 字节),写入 1 次,循环 5 遍,最终文件中会有 5 行 "hello bit!"。
2-3 读文件
c
#include <stdio.h>
#include <string.h>
int main()
{
// 以只读方式打开文件
FILE *fp = fopen("myfile", "r");
if (!fp) {
printf("fopen error!\n");
return 1;
}
char buf[1024]; // 用来存放读取到的数据
while (1) {
// fread(存放位置, 每次读取的字节数, 最多读取的次数, 文件指针)
// 返回值是实际读取到的字节数
ssize_t s = fread(buf, 1, sizeof(buf), fp);
if (s > 0) {
buf[s] = 0; // 手动加上字符串结束符
printf("%s", buf); // 打印到屏幕
}
if (feof(fp)) { // 判断是否到达文件末尾
break;
}
}
fclose(fp);
return 0;
}稍作修改,实现一个简易的 cat 命令:
c
#include <stdio.h>
#include <string.h>
int main(int argc, char *argv[])
{
// 检查命令行参数个数,用法:./程序名 文件名
if (argc != 2) {
printf("argv error!\n");
return 1;
}
// 打开用户指定的文件(只读)
FILE *fp = fopen(argv[1], "r");
if (!fp) {
printf("fopen error!\n");
return 2;
}
char buf[1024];
while (1) {
// 每次最多读 sizeof(buf) 个字节
int s = fread(buf, 1, sizeof(buf), fp);
if (s > 0) {
buf[s] = 0; // 字符串结尾
printf("%s", buf); // 输出到屏幕
}
if (feof(fp)) { // 读到文件末尾就退出
break;
}
}
fclose(fp);
return 0;
}📌 知识点总结 :fread 用于从文件读取数据,返回值是实际读取到的字节数。通过循环 + feof 判断文件是否读完,就可以完整地读取一个文件。我们还可以利用 argv 接收命令行参数,实现一个简易版的 cat 命令------用户指定文件名,程序就把文件内容打印到屏幕上。
2-4 输出信息到显示器的多种方法
c
#include <stdio.h>
#include <string.h>
int main()
{
const char *msg = "hello fwrite\n";
// 方法1:fwrite 向 stdout(标准输出)写
fwrite(msg, strlen(msg), 1, stdout);
// 方法2:printf 直接输出
printf("hello printf\n");
// 方法3:fprintf 指定输出到 stdout
fprintf(stdout, "hello fprintf\n");
return 0;
}📌 知识点总结 :往显示器输出信息至少有三种方式:fwrite(..., stdout)、printf、fprintf(stdout, ...)。它们本质上都是往标准输出(stdout) 这个流里写数据,而标准输出默认关联到显示器。
2-5 标准输入、标准输出、标准错误
C 程序在启动时,操作系统会自动打开三个输入输出流:
| 流 | 名称 | 默认关联设备 | 类型 |
|---|---|---|---|
stdin |
标准输入 | 键盘 | FILE* |
stdout |
标准输出 | 显示器 | FILE* |
stderr |
标准错误 | 显示器 | FILE* |
c
#include <stdio.h>
// 这三个全局变量在 stdio.h 中声明
extern FILE *stdin;
extern FILE *stdout;
extern FILE *stderr;它们都是 FILE* 类型,和 fopen 返回的文件指针一模一样。所以我们能对文件做的事(读写),也能对 stdin、stdout、stderr 做。
📌 知识点总结 :每个 C 程序启动时,操作系统会自动打开三个标准流:stdin(键盘输入)、stdout(屏幕输出)、stderr(屏幕输出错误信息)。它们的类型都是 FILE*,可以用文件操作函数直接操作它们。
2-6 打开文件的方式
fopen 的第二个参数是一个模式字符串,决定了你要怎么操作文件:
| 模式 | 含义 |
|---|---|
"r" |
只读打开,文件必须存在,从文件开头读 |
"r+" |
读写打开,文件必须存在,从文件开头操作 |
"w" |
只写打开,如果文件存在则清空,不存在则创建 |
"w+" |
读写打开,文件存在则清空,不存在则创建 |
"a" |
追加写打开,文件不存在则创建,写的内容追加到末尾 |
"a+" |
读和追加写打开,文件不存在则创建,读取从开头,写入追加到末尾 |
📌 知识点总结 :fopen 的模式决定了你对文件的访问权限和行为:r 系列要求文件必须先存在;w 系列会清空原文件或创建新文件;a 系列是追加模式,写入的内容总是添加到文件末尾,不会覆盖原有数据。选择合适的模式非常重要,选错了可能导致数据丢失或打开失败。
3. 系统文件 I/O
C 语言的文件操作接口(fopen / fread / fwrite 等)虽然好用,但它们只是"马甲",底层真正干活的是操作系统提供的系统调用接口 :open / read / write / close / lseek。学习系统调用接口,能让我们更深刻地理解文件的本质。
3-1 一种传递标志位的方法
在介绍系统调用之前,先来看一个 C 语言的技巧------如何通过位运算来传递多个选项:
c
#include <stdio.h>
// 用不同的二进制位表示不同的选项
#define ONE 0001 // 二进制 0000 0001
#define TWO 0002 // 二进制 0000 0010
#define THREE 0004 // 二进制 0000 0100
void func(int flags)
{
// 通过位与运算检查是否传入了某个选项
if (flags & ONE) printf("flags has ONE! ");
if (flags & TWO) printf("flags has TWO! ");
if (flags & THREE) printf("flags has THREE! ");
printf("\n");
}
int main()
{
func(ONE); // 传入单个选项
func(THREE); // 传入单个选项
func(ONE | TWO); // 传入多个选项(用 | 合并)
func(ONE | THREE | TWO); // 传入所有选项
return 0;
}运行结果:
flags has ONE!
flags has THREE!
flags has ONE! flags has TWO!
flags has ONE! flags has TWO! flags has THREE!原理 :每个选项占用一个独立的二进制位(1、2、4、8......),用 | 运算可以合并多个选项。检查时用 & 运算,就能知道某个位是否被置 1。这种设计在系统调用中非常常见,比如 open 函数的 flags 参数就是这么干的。
📌 知识点总结 :通过位运算传递标志位是一种常用的 C 语言技巧。每个选项用一个独立的二进制位表示,用 | 合并多个选项,用 & 检查某个选项是否存在。这样做的好处是:一个整型参数就能携带多个开关信息,高效且简洁。Linux 的系统调用接口大量使用这种方式。
3-2 系统调用写文件
c
#include <stdio.h>
#include <sys/types.h> // 提供各种数据类型
#include <sys/stat.h> // 提供文件状态相关的结构和宏
#include <fcntl.h> // 提供 open 函数和 O_* 常量
#include <unistd.h> // 提供 write、close 等函数
#include <string.h>
int main()
{
umask(0); // 将文件创建掩码设为 0,确保创建的文件权限不受默认掩码影响
// open: 打开或创建文件
// O_WRONLY: 只写模式
// O_CREAT: 如果文件不存在则创建
// 0644: 如果创建新文件,权限为 rw-r--r--
int fd = open("myfile", O_WRONLY | O_CREAT, 0644);
if (fd < 0) { // open 失败返回 -1
perror("open"); // 打印错误信息
return 1;
}
int count = 5;
const char *msg = "hello bit!\n";
int len = strlen(msg);
while (count--) {
// write(文件描述符, 数据, 写入的字节数)
write(fd, msg, len);
}
close(fd); // 关闭文件
return 0;
}📌 知识点总结 :系统调用 open 用于打开或创建文件,返回一个文件描述符 (一个小整数)。write 通过文件描述符往文件里写数据。close 关闭文件。注意与 C 库函数的区别:库函数用 FILE* 操作文件,系统调用用 int fd(文件描述符)操作文件。umask(0) 是为了避免系统的默认掩码影响我们指定的文件权限。
3-3 系统调用读文件
c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
int main()
{
// O_RDONLY: 只读打开
int fd = open("myfile", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
char buf[1024];
while (1) {
// read(文件描述符, 存放位置, 期望读取的字节数)
// 返回值是实际读取到的字节数,读取到文件末尾返回 0,出错返回 -1
ssize_t s = read(fd, buf, sizeof(buf));
if (s > 0) {
printf("%s", buf);
} else {
break; // 读取完毕或出错就退出
}
}
close(fd);
return 0;
}📌 知识点总结 :系统调用 read 从文件中读取数据,返回实际读到的字节数。返回 0 表示文件读完了,返回 -1 表示出错。跟 C 库的 fread 相比,read 更底层,没有用户态缓冲区,直接向内核请求数据。
3-4 主要系统调用接口介绍
open ------ 打开或创建文件
c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// 打开已有文件
int open(const char *pathname, int flags);
// 创建新文件(需要指定权限)
int open(const char *pathname, int flags, mode_t mode);- pathname:要打开或创建的文件路径。
- flags :打开方式,多个选项用
|连接。常用选项:O_RDONLY:只读打开O_WRONLY:只写打开O_RDWR:读写打开(上述三个必须且只能指定一个)O_CREAT:文件不存在则创建(需要配合 mode 指定权限)O_APPEND:追加写(写入位置自动移到文件末尾)O_TRUNC:如果文件存在,清空内容
- mode :创建新文件时指定的权限,如
0644(八进制,表示rw-r--r--)。 - 返回值:成功返回文件描述符(非负整数),失败返回 -1。
write ------ 向文件写入数据
c
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);- fd:文件描述符。
- buf:要写入的数据。
- count:要写入的字节数。
- 返回值:成功返回实际写入的字节数,失败返回 -1。
read ------ 从文件读取数据
c
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);- fd:文件描述符。
- buf:存放读取数据的缓冲区。
- count:期望读取的字节数。
- 返回值:成功返回实际读到的字节数(可能小于 count),读到文件末尾返回 0,失败返回 -1。
close ------ 关闭文件
c
#include <unistd.h>
int close(int fd);- fd:文件描述符。
- 返回值:成功返回 0,失败返回 -1。
📌 知识点总结 :系统调用是操作系统提供给用户程序的接口,比库函数更底层。open/read/write/close 是最核心的文件操作系统调用。open 的 flags 参数用位运算组合选项,O_RDONLY/O_WRONLY/O_RDWR 三者必须选一,O_CREAT 负责创建文件,O_APPEND 负责追加。read 和 write 返回实际传输的字节数,需要处理返回值小于请求值的情况。
3-5 系统调用 vs 库函数
| 对比项 | 库函数(C 标准库) | 系统调用 |
|---|---|---|
| 函数示例 | fopen, fread, fwrite, fclose |
open, read, write, close |
| 操作对象 | FILE* 文件指针 |
int 文件描述符 |
| 缓冲区 | 有用户态缓冲区 | 无用户态缓冲区(直接进入内核) |
| 性能 | 减少系统调用次数,效率较高 | 每次调用都要切换上下文,开销较大 |
| 层级 | 上层(封装了系统调用) | 底层(直接与内核交互) |
核心关系 :库函数是对系统调用的封装。库函数在内部调用系统调用来完成实际工作,但加上了缓冲区等机制来提高效率。可以这样理解:系统调用是"接口",库函数是"工具",工具用起来更顺手,但底层还是通过接口来干活的。
📌 知识点总结 :库函数(如 fopen / fwrite)和系统调用(如 open / write)的关系是"封装与被封装"的关系。库函数运行在用户态,带有用户级缓冲区,减少了频繁的系统调用,提高了效率;系统调用是操作系统提供的底层接口,每次调用都会涉及用户态到内核态的切换,开销较大。可以理解为:库函数是"高级工具",系统调用是"底层接口",高级工具用起来方便,但底层接口更接近硬件。
3-6 文件描述符 fd
3-6-1 什么是文件描述符
当我们调用 open 打开一个文件时,返回值是一个小整数 (比如 3、4、5......),这个整数就是文件描述符(file descriptor,简称 fd)。
文件描述符到底是什么?
当进程打开一个文件时,操作系统内核会在内存中创建一个 struct file 结构体来描述这个打开的文件。每个进程都有一个 files_struct 结构体,里面最核心的部分是一个指针数组 ,数组的每个元素指向一个打开的文件对象。文件描述符就是这个数组的下标。
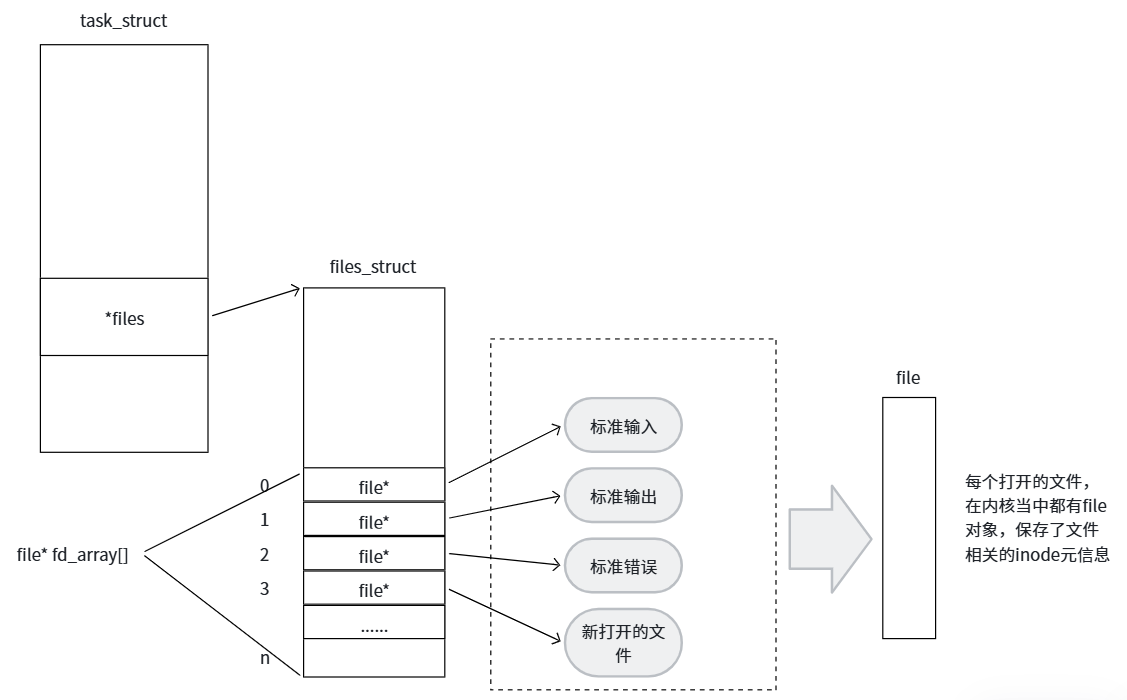
0、1、2 的含义:
Linux 进程启动时,默认打开三个文件描述符:
| 文件描述符 | 名称 | 关联设备 |
|---|---|---|
| 0 | 标准输入(stdin) | 键盘 |
| 1 | 标准输出(stdout) | 显示器 |
| 2 | 标准错误(stderr) | 显示器 |
所以我们可以直接用文件描述符来读写:
c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main()
{
char buf[1024];
// 从标准输入(文件描述符 0,即键盘)读取数据
ssize_t s = read(0, buf, sizeof(buf));
if (s > 0) {
buf[s] = 0; // 字符串结束符
write(1, buf, strlen(buf)); // 写到标准输出(文件描述符 1,即显示器)
write(2, buf, strlen(buf)); // 写到标准错误(文件描述符 2,即显示器)
}
return 0;
}📌 知识点总结 :文件描述符是一个非负小整数,本质上是进程文件描述符表(fd_array[])的下标。通过这个下标,内核就能找到对应的打开文件对象。0、1、2 是系统默认打开的三个文件描述符,分别对应标准输入、标准输出和标准错误。所以操作文件描述符 0、1、2 就相当于操作键盘和显示器。
3-6-2 文件描述符的分配规则
来看一段代码,观察文件描述符的分配规律:
c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
// 只读打开 myfile
int fd = open("myfile", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd); // 猜猜是多少?
close(fd);
return 0;
}运行结果:
fd: 3为什么是 3?因为 0、1、2 已经被标准输入、标准输出、标准错误占用了,所以新打开的文件拿到的就是最小空闲下标------3。
如果我们先关闭 0 呢?
c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
close(0); // 先关闭标准输入
int fd = open("myfile", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}运行结果:
fd: 00 被关闭后,它就成了空闲的最小的下标,所以新打开的文件拿到了 0。
📌 知识点总结 :文件描述符的分配规则是:在进程的文件描述符表中,找到当前没有被使用的最小的下标,作为新打开文件的文件描述符。0、1、2 默认被占用,所以新文件从 3 开始。但如果手动关闭了 0,新文件就会分配到 0。
3-6-3 重定向的本质
先看一段神奇代码:
c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
close(1); // 关闭标准输出(文件描述符 1)
// 以只写方式打开 myfile
int fd = open("myfile", O_WRONLY | O_CREAT, 00644);
if (fd < 0) {
perror("open");
return 1;
}
printf("fd: %d\n", fd); // 猜猜这句输出到哪里?
fflush(stdout); // 刷新 stdout 的缓冲区
close(fd);
exit(0);
}运行这个程序,你会发现屏幕上什么都没有显示 !但是打开 myfile 文件,里面却写着:
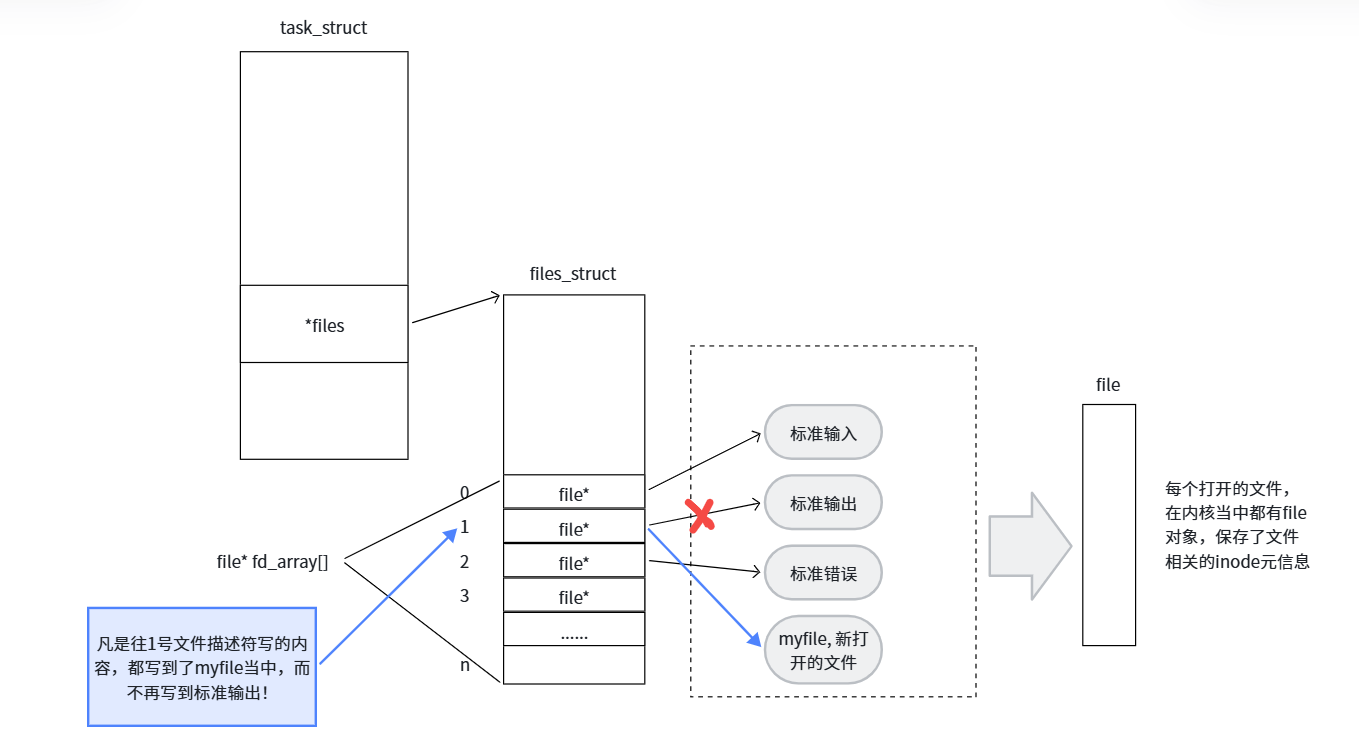
fd: 3发生了什么?
- 我们关闭了文件描述符 1(标准输出原本指向显示器)。
- 然后
open打开myfile,根据分配规则,最小的空闲下标是 1,所以fd = 1。 - 现在文件描述符 1 不再指向显示器,而是指向了
myfile这个磁盘文件。 printf是往stdout输出的,而stdout底层用的是文件描述符 1,所以数据就写进了myfile。
这就是输出重定向的本质!
常见的重定向符号对应的本质:
>:输出重定向(先清空文件,再写入)------对应O_WRONLY | O_CREAT | O_TRUNC>>:追加重定向------对应O_WRONLY | O_CREAT | O_APPEND<:输入重定向(从文件读代替从键盘读)------对应O_RDONLY
重定向的本质:修改文件描述符表中某个下标指向的文件对象,让原本输出到 A 地方的数据,转而输出到 B 地方。
📌 知识点总结 :重定向的本质就是修改文件描述符表中特定下标指向的文件对象 。当我们关闭 1 号文件描述符(原本指向显示器),再打开一个磁盘文件时,根据分配规则,这个磁盘文件会拿到 1 号下标。从此以后,所有往 1 号文件描述符写的数据(包括 printf 等库函数),都会写入磁盘文件,而不是显示器。这就是 >、>>、< 这些重定向操作在操作系统层面的实现原理。
3-6-4 使用 dup2 系统调用
手动 close 再 open 的方式虽然能实现重定向,但比较笨拙。Linux 专门提供了一个系统调用 dup2,可以更便捷地完成重定向:
c
#include <unistd.h>
// 将 newfd 指向 oldfd 所指向的文件对象
// 即:让 newfd 成为 oldfd 的"拷贝"
int dup2(int oldfd, int newfd);- 功能:关闭
newfd(如果它已打开),然后让newfd指向oldfd所指向的同一个文件对象。 - 返回值:成功返回
newfd,失败返回 -1。
示例:实现一个"回显服务器",从键盘读内容,写入日志文件:
c
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
int main()
{
// 打开(或创建)日志文件 log,以读写方式
int fd = open("./log", O_CREAT | O_RDWR, 0644);
if (fd < 0) {
perror("open");
return 1;
}
// 将标准输出(文件描述符 1)重定向到文件
// 注意:这里不需要手动 close(1),dup2 会自动处理
dup2(fd, 1);
// 从现在开始,所有 printf 的内容都会写到 log 文件里
for (;;) {
char buf[1024] = {0};
// 从标准输入(键盘)读取数据
ssize_t read_size = read(0, buf, sizeof(buf) - 1);
if (read_size < 0) {
perror("read");
break;
}
// printf 往 stdout(文件描述符 1)输出
// 但由于 1 已被重定向到 log 文件,数据会写入文件
printf("%s", buf);
fflush(stdout); // 刷新缓冲区,确保数据立即写入文件
}
return 0;
}📌 知识点总结 :dup2(oldfd, newfd) 是一个专门用于重定向的系统调用,它让 newfd 拷贝 oldfd 所指向的文件对象,相当于让 newfd 指向 oldfd 指向的同一个文件。使用 dup2 比手动 close + open 更简洁、更安全,是实际编程中实现重定向的首选方式。
3-6-5 在 minishell 中添加重定向功能
(注:原课件包含一个完整的 minishell 代码,这里我们讲解核心思路和关键代码片段)
要实现 shell 的重定向功能,需要在解析命令时做以下处理:
c
// 伪代码------在 minishell 中添加重定向的核心逻辑
void execute_with_redirect(char *cmd, char **args)
{
int fd;
int old_stdout = -1;
// 遍历参数,查找 ">" 或 ">>" 或 "<"
for (int i = 0; args[i] != NULL; i++)
{
if (strcmp(args[i], ">") == 0)
{
// 输出重定向:创建/清空文件,将 stdout 指向它
fd = open(args[i + 1], O_WRONLY | O_CREAT | O_TRUNC, 0644);
dup2(fd, 1); // 将 1 号(标准输出)重定向到文件
close(fd);
args[i] = NULL; // 从参数列表中移除 ">" 和文件名
break;
}
else if (strcmp(args[i], ">>") == 0)
{
// 追加重定向
fd = open(args[i + 1], O_WRONLY | O_CREAT | O_APPEND, 0644);
dup2(fd, 1);
close(fd);
args[i] = NULL;
break;
}
else if (strcmp(args[i], "<") == 0)
{
// 输入重定向:打开文件,将 stdin 指向它
fd = open(args[i + 1], O_RDONLY);
dup2(fd, 0); // 将 0 号(标准输入)重定向到文件
close(fd);
args[i] = NULL;
break;
}
}
// 执行命令(如 execvp)
// ...
}完整流程:
- 获取用户输入的命令行字符串。
- 解析字符串,拆分成命令和参数。
- 检查参数中是否有重定向符号(
>、>>、<)。 - 如果有,调用
open+dup2完成文件描述符的重定向。 - 去掉重定向部分,只保留真正的命令和参数,然后
exec执行。 - 执行完毕后,如果需要恢复,可以保存原来的文件描述符,执行完再还原。
📌 知识点总结 :在 minishell 中添加重定向功能,核心就是解析命令字符串中的重定向符号,然后调用 open + dup2 修改文件描述符的指向 。> 对应输出重定向(O_TRUNC 清空写入),>> 对应追加重定向(O_APPEND),< 对应输入重定向(O_RDONLY)。实现时要注意从参数列表中移除重定向符号和文件名,只把真正的命令传给 exec 系列函数。
4. 理解"一切皆文件"
4-1 什么是"一切皆文件"
Linux 的设计哲学中有一个核心理念:一切皆文件。
- 在 Windows 中是文件的东西(如普通文件、目录),在 Linux 中也是文件。
- 在 Windows 中不是文件的东西,在 Linux 中也被抽象成了文件:比如磁盘、显示器、键盘等硬件设备,进程之间的管道(pipe),甚至网络编程中的套接字(socket),都可以用文件操作的方式来访问。
4-2 这样做的好处
开发者只需要学习一套 API (open、read、write、close 等),就能操作 Linux 系统中绝大部分的资源。你不用为键盘单独学一套接口,为显示器再学一套,为网络又学一套------统一的文件接口搞定一切。
4-3 内核中的实现原理
当一个文件被打开时,操作系统内核会创建一个 struct file 结构体来管理这个打开的文件:
c
// 这个结构体定义在 Linux 内核源码的 include/linux/fs.h 中
struct file {
// ...
struct inode *f_inode; // 指向文件的 inode(存储元数据)
const struct file_operations *f_op; // 指向文件操作函数表
// ...
atomic_long_t f_count; // 引用计数,表示有多少个文件描述符指向这个文件
unsigned int f_flags; // 打开文件时指定的标志(如 O_RDONLY)
fmode_t f_mode; // 文件的访问模式
loff_t f_pos; // 当前读写位置(文件偏移量)
// ...
};其中最关键的是 f_op 指针,它指向一个 struct file_operations 结构体:
c
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int); // 定位读写位置
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *); // 读
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *); // 写
// ... 还有很多函数指针
int (*open) (struct inode *, struct file *); // 打开
int (*release) (struct inode *, struct file *); // 释放(关闭)
// ...
};重点理解 :file_operations 结构体里全是函数指针 。不同类型的文件(普通磁盘文件、键盘设备、显示器设备、管道......),它们的 file_operations 表里的函数指针指向的是不同的实际函数。
举个例子:
- 当你
read一个磁盘文件 时:通过 fd 找到struct file,再通过f_op找到file_operations表,调用表中的read函数指针,这个指针指向的是磁盘驱动的读取函数。 - 当你
read从键盘 输入时:同样是 fd →struct file→f_op→read函数指针,但这次指针指向的是键盘驱动的读取函数。
同样的接口,不同的实现 ------这就是"一切皆文件"在内核层面的实现机制,也被称为多态的思想(面向对象中的概念,在这里通过函数指针实现)。
📌 知识点总结 :"一切皆文件"是 Linux 最核心的设计理念之一。无论是普通文件、硬件设备、管道还是网络套接字,都被抽象成文件,用同一套 open/read/write/close 接口来操作。内核通过 struct file 结构体管理每个打开的文件,其中的 f_op 指针指向一个 file_operations 函数指针表,不同类型的设备提供不同的函数实现,但对外暴露的接口完全一致。这种设计极大地简化了开发,实现了"一套接口,操作万物"。
5. 缓冲区
5-1 什么是缓冲区
缓冲区(Buffer)是内存中预留的一部分存储空间,用来临时存放输入或输出的数据。简单说,就是数据不直接发给目的地,而是先存到一个"中转站"里,等攒够了再一次性发送。
5-2 为什么要引入缓冲区
直接通过系统调用(如 read / write)操作磁盘时,每次调用都会涉及用户态到内核态的切换(CPU 状态切换,开销很大)。如果频繁地读写磁盘,就会频繁进行系统调用,性能会非常差。
缓冲区的引入就是为了减少系统调用的次数:
没有缓冲区:
程序 → 系统调用 → 磁盘(一次写 1 字节,调用 1000 次)
每次都要切换用户态/内核态,效率极低
有缓冲区:
程序 → 写到缓冲区(内存操作,极快)→ 攒满后 → 一次系统调用 → 磁盘
1000 次写入合并为 1 次系统调用,效率大大提升一句话:缓冲区就是用内存的速度来"中和"磁盘的慢速,用少量的系统调用完成大量的数据传输。
5-3 缓冲类型
C 标准库提供了三种缓冲方式:
| 缓冲类型 | 刷新时机 | 适用场景 |
|---|---|---|
| 全缓冲 | 缓冲区满了才刷新 | 普通文件读写 |
| 行缓冲 | 遇到换行符 \n 就刷新 |
标准输入/输出(终端交互) |
| 无缓冲 | 立即刷新,不做缓存 | 标准错误(stderr) |
除了上述默认规则,以下情况也会触发缓冲区刷新:
- 缓冲区满了。
- 调用
fflush函数强制刷新。 - 进程正常退出(
exit或returnfrommain)。
示例:重定向后的缓冲问题
c
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main()
{
close(1); // 关闭标准输出
// 将 1 号文件描述符重定向到 log.txt
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 1;
}
// printf 往 stdout(即文件描述符 1)写
// 但此时 1 指向的是磁盘文件,缓冲方式从"行缓冲"变成了"全缓冲"
printf("hello world: %d\n", fd);
// 如果不 close 或 fflush,数据可能还在缓冲区里,没有真正写入文件
close(fd);
return 0;
}运行后检查 log.txt,你可能发现它是空的 !因为重定向到磁盘文件后,缓冲方式变成了全缓冲,而写入的内容没有填满缓冲区,所以数据还留在用户态的缓冲区里,没有通过系统调用写入磁盘。
解决方法 :在 close 之前调用 fflush(stdout) 强制刷新缓冲区。
📌 知识点总结 :缓冲区是内存中用来临时存储数据的一块空间,目的是减少系统调用的次数,提高 IO 效率。C 标准库提供三种缓冲策略:全缓冲(文件,满了才刷)、行缓冲(终端,遇到换行符就刷)、无缓冲(stderr,立即刷)。当输出重定向到文件时,缓冲方式会从行缓冲变为全缓冲,可能导致数据没有即时写入磁盘。此时可以用 fflush 强制刷新缓冲区。
5-4 FILE 结构体与缓冲区
C 库函数与系统调用的关系
C 标准库的 FILE 结构体内部封装了文件描述符 fd 。因为所有 IO 操作最终都要通过系统调用完成,而系统调用需要文件描述符。所以 FILE* 本质上就是给 int fd 穿了一件"马甲",顺便加上了一个用户级缓冲区。
经典问题:fork 之后的数据重复
c
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main()
{
const char *msg0 = "hello printf\n";
const char *msg1 = "hello fwrite\n";
const char *msg2 = "hello write\n";
printf("%s", msg0); // C 库函数,带缓冲区
fwrite(msg1, strlen(msg0), 1, stdout); // C 库函数,带缓冲区
write(1, msg2, strlen(msg2)); // 系统调用,无缓冲区
fork(); // 创建子进程
return 0;
}直接运行结果(输出到显示器):
hello printf
hello fwrite
hello write只有一份输出,很正常。
重定向到文件后运行(./a.out > file):
cat file 的内容:
hello write
hello printf
hello fwrite
hello printf
hello fwrite看到了吗?printf 和 fwrite 的内容出现了两份 ,而 write 的内容只有一份!这是为什么?
原因分析
-
缓冲方式变了 :直接输出到显示器时是行缓冲 ,遇到
\n就刷新了。重定向到文件后变成了全缓冲,数据留在缓冲区里,没有立即刷新。 -
fork复制了缓冲区 :fork创建子进程时,子进程会复制父进程的数据段(包括 C 库的缓冲区)。此时缓冲区里还躺着printf和fwrite写入的数据。 -
写时拷贝:父子进程各自维护一份缓冲区数据。进程退出时,各自刷新自己的缓冲区,于是相同的数据被写入了两次。
-
write为什么只有一份 ?因为write是系统调用,没有用户级缓冲区 ,数据直接通过系统调用写入内核,fork时不存在"缓冲区数据待刷新"的问题。时间线:
- printf / fwrite 写入用户级缓冲区(还没刷到内核)
- fork() 创建子进程
- 父子进程各有一份相同的缓冲区数据
- 两个进程退出时,各自刷新缓冲区 → 相同数据写入文件两次
📌 知识点总结 :FILE 结构体内部封装了文件描述符和用户级缓冲区。C 库函数(printf / fwrite)是带缓冲区的,系统调用(write)不带用户级缓冲区。当输出重定向到文件时,缓冲方式从行缓冲变为全缓冲,数据可能留在缓冲区中。此时如果调用 fork(),子进程会复制父进程的缓冲区,导致进程退出时相同数据被刷新两次。这个经典问题清晰地揭示了库函数缓冲区和系统调用无缓冲区的本质区别。
5-5 模拟实现一个简单的 libc
为了更深刻地理解 C 标准库的封装原理,我们来自定义一个简易的 my_stdio,包含自己的 FILE 结构体和基本的文件操作函数。
my_stdio.h ------ 自定义头文件
c
#ifndef __MY_STDIO_H__
#define __MY_STDIO_H__
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
// 缓冲区大小
#define MY_BUFFER_SIZE 4096
// 缓冲区刷新模式
#define MY_NONE_FLUSH 0b000 // 无缓冲
#define MY_LINE_FLUSH 0b001 // 行缓冲
#define MY_FULL_FLUSH 0b010 // 全缓冲
// 自定义 FILE 结构体
// 模拟 C 标准库中的 FILE,封装了文件描述符和用户级缓冲区
typedef struct _MyFILE {
int fd; // 文件描述符
char buffer[MY_BUFFER_SIZE]; // 用户级缓冲区
int pos; // 当前缓冲区中数据的长度(下一个写入位置)
int flush_mode; // 刷新方式:无缓冲 / 行缓冲 / 全缓冲
} MyFILE;
// 函数声明
MyFILE *my_fopen(const char *pathname, const char *mode);
int my_fwrite(const void *ptr, int size, int count, MyFILE *fp);
void my_fflush(MyFILE *fp);
int my_fclose(MyFILE *fp);
#endifmy_stdio.c ------ 函数实现
c
#include "my_stdio.h"
// 根据 mode 字符串解析打开方式,并设置对应的缓冲模式
// 返回 open 系统调用所需的 flags
static int parse_mode(const char *mode, int *flush_mode)
{
if (strcmp(mode, "w") == 0) {
*flush_mode = MY_FULL_FLUSH; // 文件默认全缓冲
return O_WRONLY | O_CREAT | O_TRUNC;
} else if (strcmp(mode, "r") == 0) {
*flush_mode = MY_FULL_FLUSH;
return O_RDONLY;
} else if (strcmp(mode, "a") == 0) {
*flush_mode = MY_FULL_FLUSH;
return O_WRONLY | O_CREAT | O_APPEND;
}
return -1; // 不支持的模式
}
// 打开文件:分配 MyFILE 结构体,调用 open 系统调用
MyFILE *my_fopen(const char *pathname, const char *mode)
{
int flush_mode = 0;
int flags = parse_mode(mode, &flush_mode);
if (flags < 0) return NULL;
// 调用系统调用 open 打开文件
int fd = open(pathname, flags, 0644);
if (fd < 0) return NULL;
// 分配并初始化 MyFILE 结构体
MyFILE *fp = (MyFILE *)malloc(sizeof(MyFILE));
if (!fp) {
close(fd);
return NULL;
}
fp->fd = fd;
fp->pos = 0; // 缓冲区当前为空
fp->flush_mode = flush_mode;
memset(fp->buffer, 0, MY_BUFFER_SIZE);
return fp;
}
// 将缓冲区中的数据真正写入内核(通过系统调用 write)
// 这就是"刷新缓冲区"的本质
void my_fflush(MyFILE *fp)
{
if (fp->pos > 0) {
// 调用 write 系统调用,将缓冲区数据写入文件
write(fp->fd, fp->buffer, fp->pos);
fp->pos = 0; // 重置缓冲区位置
}
}
// 带缓冲的写入函数
int my_fwrite(const void *ptr, int size, int count, MyFILE *fp)
{
int total_bytes = size * count; // 需要写入的总字节数
const char *data = (const char *)ptr;
int written = 0;
while (written < total_bytes) {
int remaining = total_bytes - written;
int space = MY_BUFFER_SIZE - fp->pos; // 缓冲区剩余空间
if (space >= remaining) {
// 缓冲区够用:先把数据拷贝到缓冲区
memcpy(fp->buffer + fp->pos, data + written, remaining);
fp->pos += remaining;
written += remaining;
} else {
// 缓冲区不够:先填满缓冲区
memcpy(fp->buffer + fp->pos, data + written, space);
fp->pos += space;
written += space;
// 缓冲区满了,强制刷新(全缓冲策略)
my_fflush(fp);
}
// 行缓冲模式:如果遇到换行符,立即刷新
if (fp->flush_mode == MY_LINE_FLUSH) {
for (int i = 0; i < fp->pos; i++) {
if (fp->buffer[i] == '\n') {
my_fflush(fp);
break;
}
}
}
}
return count; // 返回写入的"次数"
}
// 关闭文件:先刷新缓冲区,再关闭文件描述符,最后释放结构体
int my_fclose(MyFILE *fp)
{
if (fp) {
my_fflush(fp); // 先刷新,确保所有数据都已写入内核
close(fp->fd); // 关闭文件描述符
free(fp); // 释放 MyFILE 结构体
}
return 0;
}main.c ------ 测试代码
c
#include "my_stdio.h"
#include <stdio.h>
int main()
{
// 使用自定义的 my_fopen 打开文件
MyFILE *fp = my_fopen("test.txt", "w");
if (!fp) {
printf("my_fopen failed!\n");
return 1;
}
// 使用自定义的 my_fwrite 写入数据
const char *msg = "Hello from my_stdio!\n";
my_fwrite(msg, strlen(msg), 1, fp);
// 关闭文件(会自动刷新缓冲区)
my_fclose(fp);
return 0;
}这个模拟实现的核心思想:
MyFILE结构体封装了fd(文件描述符)和一个buffer(用户级缓冲区)。my_fwrite先把数据写入用户缓冲区,缓冲区满了才调用write系统调用刷入内核。my_fflush负责将缓冲区数据通过write系统调用真正写入文件。my_fclose关闭前先刷新缓冲区,避免数据丢失。
这正是 C 标准库 FILE 的工作机制:通过用户级缓冲区减少系统调用次数,提高 IO 效率。
📌 知识点总结 :通过模拟实现一个简易的 my_stdio,我们可以清晰地看到 C 标准库的"封装"本质。FILE 结构体内部包装了文件描述符和一个用户级缓冲区。写入数据时,fwrite 先将数据拷贝到缓冲区,等缓冲区满了(或者遇到换行符、或者手动 fflush)才调用系统调用 write 将数据真正写入内核。这种机制极大地减少了系统调用次数,是 C 标准库 IO 高效的关键所在。模拟实现虽然粗糙,但足以揭示核心原理:库函数 = 系统调用 + 用户级缓冲区。
总结回顾
第 5 讲"基础 IO"涵盖了以下核心知识:
- 文件的概念:文件 = 属性(元数据)+ 内容,Linux 下"一切皆文件"。
- C 标准库文件接口 :
fopen、fread、fwrite、fclose、stdin/stdout/stderr。 - 系统调用接口 :
open、read、write、close、lseek,以及文件描述符的概念。 - 文件描述符与重定向 :fd 的分配规则(最小未使用下标),重定向的本质(修改 fd 指向),
dup2的使用。 - 一切皆文件的实现 :
struct file和file_operations函数指针表实现多态。 - 缓冲区机制:全缓冲、行缓冲、无缓冲,以及 fork 带来的缓冲区拷贝问题。
- 库函数 vs 系统调用:库函数 = 系统调用 + 用户级缓冲区。
