上一章模型下载并在本地跑通。本章在此基础上做微调:用 Hugging Face 的 BERT,在 ChnSentiCorp 上训练中文评价情感分析。
流程:加载数据 → 做 Dataset → Tokenizer 编码 → 设计下游模型 → 训练保存权重;效果评估与测试下期。
1.Hugging Face模型微调训练
模型微调的基本概念
微调是指在预训练模型的基础上,通过进一步的训练来适应特定的需求。
BERT模型通过预训练来学习语言的通用模式,然后通过微调来适应特定的任务,如情感分析、命名实体识别等。
微调过程中,通常冻结BERT的预训练层,只训练与下游任务相关的层。
微调三个关键阶段
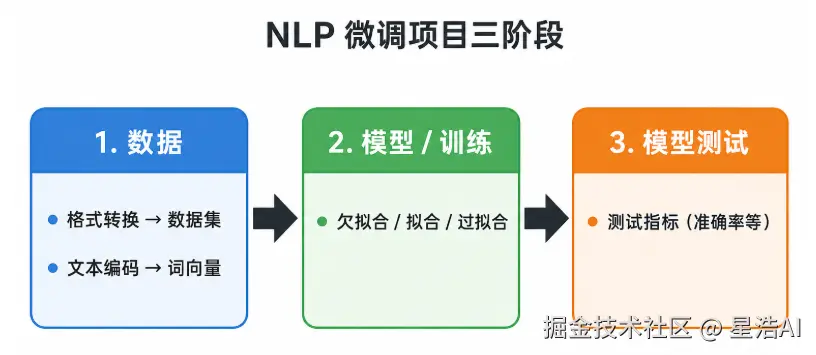
一个典型的 NLP 项目,可以按下面三个阶段来推进:
1. 数据
- 对数据做格式转换,整理成模型可使用的数据集
- 将文本转换为数字,叫做文本编码 (最终要变成词向量:用一个向量代表一个词)
2. 模型 / 训练
- 判断模型的训练状态:欠拟合、拟合、过拟合
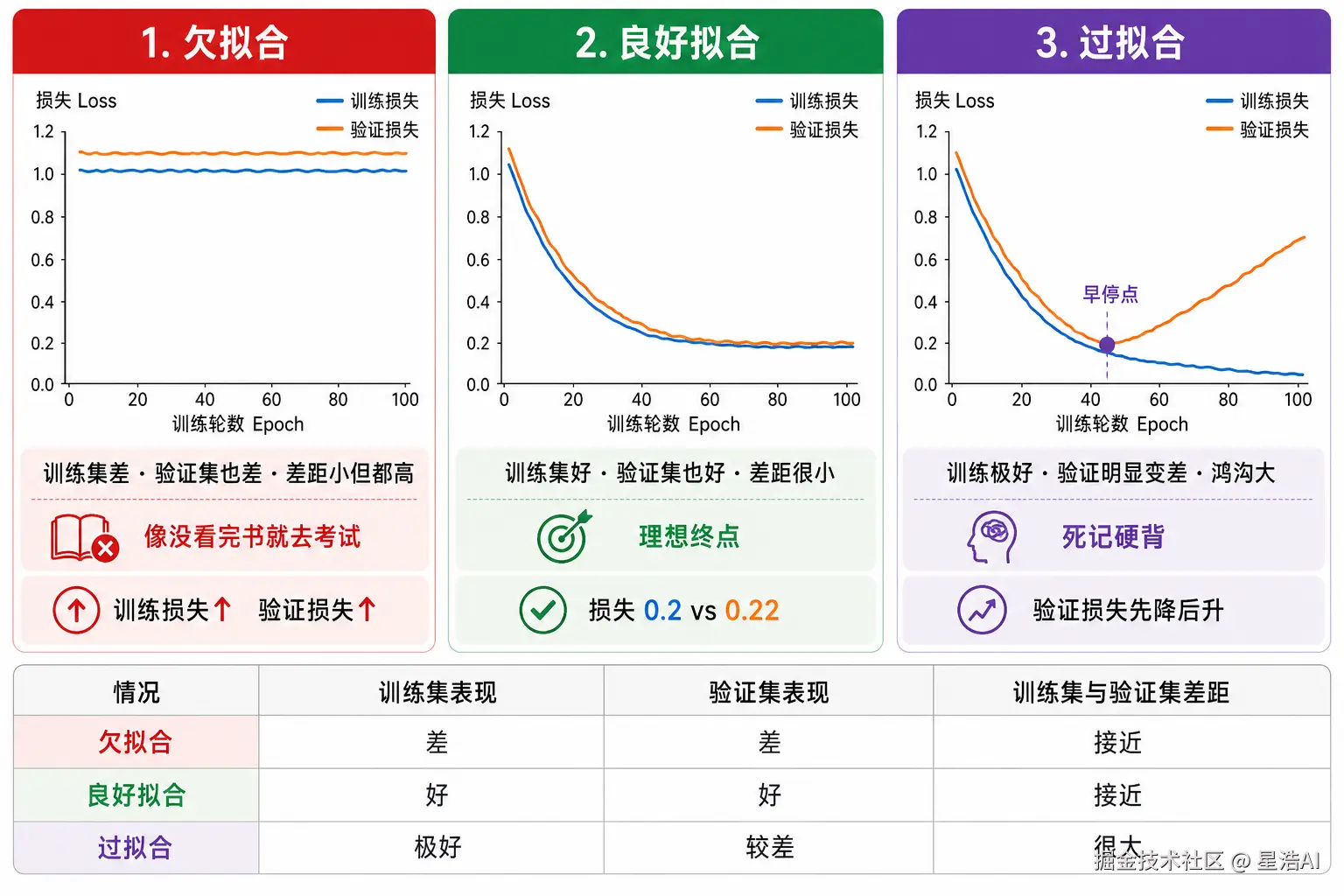
3. 模型测试
- 看测试指标
2.加载数据集
情感分析任务的数据通常包括文本 及其对应的情感标签。
使用Hugging Face的datasets库可以轻松地加载和处理数据集。
- 在线加载数据
python
from datasets import load_dataset
# 加载数据集
dataset = load_dataset(path="lansinuote/ChnSentiCorp",cache_dir="D:/model/data/")
# 查看数据集
print(dataset)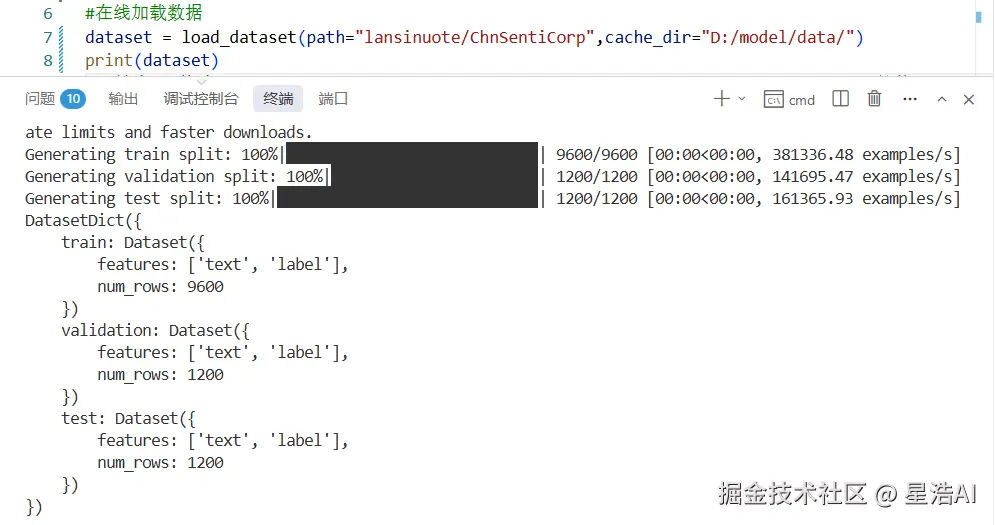
- 从缓存加载数据
python
# 第一个示例
from datasets import load_from_disk
# 从缓存加载数据
datasets = load_from_disk(r"D:\model\data\ChnSentiCorp")
# 查看数据集
print(dataset)- 查看测试集的数据信息
python
# # 查看测试集的数据信息 【train-训练数据,validation-验证数据,test-测试数据】
train_data = datasets["test"]
for data in train_data:
print(data)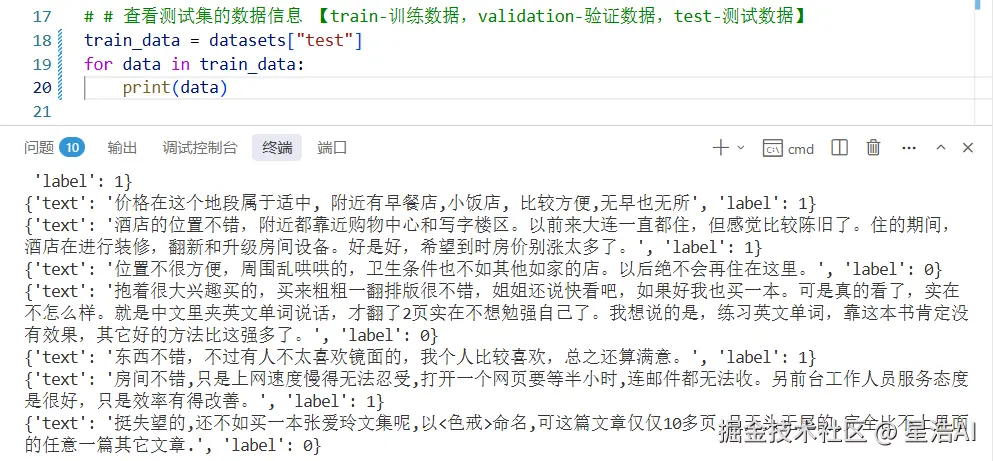
json
[
{'text': '东西不错,不过有人不太喜欢镜面的,我个人比较喜欢,总之还算满意。', 'label': 1},
{'text': '非常一般的一本书,充满了假想的理想主义色彩,建议刚毕业的职场新人千万不要看。', 'label': 0}
]- dataset 转 csv
python
#转为csv格式
dataset.to_csv(path_or_buf=r"D:\\model\\data\\ChnSentiCorp.csv")- 加载 csv 文件
python
from datasets import load_dataset
# 扩展:加载CSV格式数据
dataset = load_dataset(path="csv",data_files=r"D:\\model\\data\\ChnSentiCorp.csv")
print(dataset)2.1数据集格式
Hugging Face的datasets库支持多种数据集格式,如CSV、JSON、TFRecord等。至少包含两列:一列是文本数据 ,另一列是情感标签。
2.2数据集信息
加载数据集后,可以查看数据集的基本信息,如数据集大小、字段名称等。这有助于我们了解数据的分布情况,并在后续步骤中进行适当的处理。
css
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 9600
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
test: Dataset({
features: ['text', 'label'],
num_rows: 1200
})
})训练集-train:9600条数据;
验证集-validation:1200条数据;
测试集-test:1200条数据;
包含text和label两个字段。
3.制作DataSet
加载数据集后,需要对其进行处理以适应模型的输入格式。这包括数据清洗、格式转换等操作。
python
# 自定义数据集
from torch.utils.data import Dataset
from datasets import load_from_disk
class MyDataset(Dataset):
#初始化数据集
def __init__(self,split):
#从磁盘加载数据
self.dataset = load_from_disk(r"D:\\model\\data\\ChnSentiCorp")
if split == "train": # 训练集
self.dataset = self.dataset["train"]
elif split == "test": # 测试集
self.dataset = self.dataset["test"]
elif split == "validation": # 验证集
self.dataset = self.dataset["validation"]
else:
print("数据名错误!")
#返回数据集长度
def __len__(self):
return len(self.dataset)
#对每条数据单独做处理
def __getitem__(self, item):
text = self.dataset[item]["text"]
label = self.dataset[item]["label"]
return text,label
if __name__ == '__main__':
dataset = MyDataset("train")
for data in dataset:
print(data)输出结果:
text
('虽是观景房,不过我住的楼层太低(19楼)看不到江景,但地点很好,离轻轨临江门站和较场口站(起点)很近,解放碑就在
附近(大约100多公尺吧)!', 1)
('性价比不错,交通方便。行政楼层感觉很好,只是早上8点楼上装修,好吵。 中餐厅档次太低,虽然便宜,但是和酒
店档次不相配。', 1)
('跟心灵鸡汤没什么本质区别嘛,至少我不喜欢这样读经典,把经典都解读成这样有点去中国化的味道了', 0) 3.1 数据集字段
在制作 Dataset时,需定义数据集的字段。本案例中,text(文本)和 label(情感标签)。每个字段都需要与模型的输入和输出匹配。
3.2 数据集信息
制作 Dataset 后,通过 dataset.info 等方法查看其大小、字段名称等信息,以确保数据集的正确性和完整性。
4.vocab字典制作
在微调 BERT 模型之前,需要将模型的词汇表(vocab)与数据集中的文本匹配。这一步骤确保输入的文本能够被正确转换为模型的输入格式。
python
from transformers import BertTokenizer
#加载字典和分词器
token = BertTokenizer.from_pretrained(r"D:\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f")
# print(token)
python
"""
本节小结核心介绍AI模型是如何处理字符数据的
"""
#准备要编码的文本数据
sents = ["床前明月光",
"跟心灵鸡汤没什么本质区别嘛,至少我不喜欢这样读经典"]
#批量编码句子(如何将编码成数字)
out = token(
[sents[0], sents[1]], # 编码的文本段
add_special_tokens=True, # 是否增加 special tokens ,必须要添加
#当句子长度大于max_length(上限是model_max_length)时,截断
truncation=True,
max_length=15, # 设置最大编码长度
#一律补0到max_length (凑一个矩阵出来,长了需要载掉,短了要补0 )
padding="max_length",
#数据返回样式,可取值为tf,pt,np,默认为list
# pt PyTorch Tensor 使用 PyTorch 框架时
return_tensors=None,
return_attention_mask=True,
return_token_type_ids=True,
return_special_tokens_mask=True,
#返回序列长度
return_length=True
)
for k,v in out.items():
print(k,":",v)
#解码文本数据
print(token.decode(out["input_ids"][0]),token.decode(out["input_ids"][1]))
上面 token(...) 函数,常见字段含义如下:
input_ids:编码后的词 ID 序列,即模型真正读入的数字。token_type_ids:区分两个句子------第一句与特殊符号为 0 ,第二句为 1 ;仅用于句对任务(如问答、下一句预测 NSP)。special_tokens_mask:特殊符号位置为 1 ,普通词为 0。length:本条样本编码后的实际长度(可不含右侧 padding)。attention_mask:有效 token 为 1 ,padding 为 0;模型会忽略 mask 为 0 的位置。
本案例是单句情感分析,一般只需
input_ids和attention_mask;token_type_ids在句对任务里才用得上。
4.1词汇表(vocab)
BERT 模型使用词汇表(vocab)将文本转换为模型可以理解的输入格式。 词汇表包含所有模型已知的单词及其对应的索引。 确保数据集中的所有文本都能找到对应的词汇索引是至关重要的。
4.2文本转换
使用 tokenizer 将文本分割成词汇表中的单词,并转换为相应的索引。此步骤需要确保文本长度、特殊字符处理等都与 BERT 模型的预训练设置相一致。
5.下游任务模型设计
在微调 BERT 模型之前,需要设计一个适应情感分析任务的下游模型结构。通常包括一个或多个全连接层,用于将 BERT 输出的特征向量转换为分类结果。
python
# 模型
import torch
from transformers import BertModel
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(DEVICE)
#加载预训练模型
pretrained = BertModel.from_pretrained(r"D:\model\bert-base-chinese\models--bert-base-chinese\snapshots\c30a6ed22ab4564dc1e3b2ecbf6e766b0611a33f").to(DEVICE)
print(pretrained)
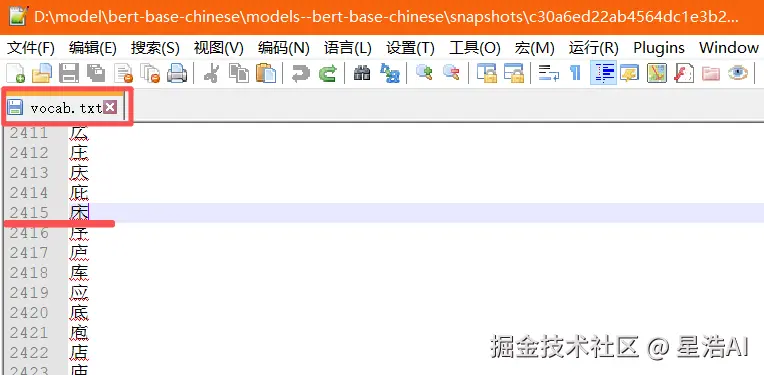
# word_embedding 词向量编码。例:"床"在vocab.txt中的索引为2415,再将2415转化为向量,即为词向量
#定义下游任务(增量模型)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
#设计全连接网络,实现二分类任务,十分类就设置成10
self.fc = torch.nn.Linear(768,2)
#使用模型处理数据(执行前向计算)
def forward(self,input_ids,attention_mask,token_type_ids):
#冻结Bert模型的参数,让其不参与训练(Bert模型不参与训练的原因:没有必要,没有数据,没有设备)
with torch.no_grad():
out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
#增量模型参与训练
out = self.fc(out.last_hidden_state[:,0])
return out5.1 模型结构
下游任务模型通常包括以下几个部分:
- BERT模型 用于生成文本的上下文特征向量。
- Dropout层 用于防止过拟合,通过随机丢弃一部分神经元来提高模型的泛化能力。
- 全连接层 用于将BERT的输出特征向量映射到具体的分类任务上。
5.2 模型初始化
使用 BertModel.from_pretrained() 方法加载预训练的 BERT 模型,同时也可以初始化自定义的全连接层。初始化时,需要根据下游任务的需求,定义合适的输出维度。
6.自定义模型训练
模型设计完成后,进入训练阶段。通过数据加载器(DataLoader)高效地批处理数据,并使用优化器更新模型参数。
python
from torch.utils.data import DataLoader
from torch.optim import AdamW
from net import Model # 自定义类
#定义设备信息
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#实例化 dataLoader
train_loader = DataLoader(
dataset=train_dataset,
#训练批次
batch_size=50,
#打乱数据集
shuffle=True,
#舍弃最后一个批次的数据,防止形状出错
drop_last=True,
#对加载的数据进行编码 (下面是内部方法调用,不要写括号)
collate_fn=collate_fn
)
model = Model().to(DEVICE)
#定义优化器
optimizer = AdamW(model.parameters())
#定义损失函数
loss_func = torch.nn.CrossEntropyLoss()
for epoch in range(EPOCH): # 整体训练的轮次
for i,(input_ids,attention_mask,token_type_ids,label) in enumerate(train_loader):
#将数据放到DEVICE上面
input_ids, attention_mask, token_type_ids, label = input_ids.to(DEVICE),attention_mask.to(DEVICE),token_type_ids.to(DEVICE),label.to(DEVICE)
#前向计算(将数据输入模型得到输出)
out = model(input_ids,attention_mask,token_type_ids)
#根据输出计算损失
loss = loss_func(out,label)
#根据误差优化参数
optimizer.zero_grad() #优化器的梯度归0
loss.backward()
optimizer.step() 6.1 数据加载
使用 DataLoader 实现批量数据加载。DataLoader 自动处理数据的批处理和随机打乱,确保训练的高效性和数据的多样性。
6.2 优化器
Adamw 是一种适用于 BERT 模型的优化器,结合 Adam 和权重衰减的特点,能够有效地防止过拟合。
6.3 训练循环
训练循环包含前向传播(forward pass)、损失计算(loss calculation)、反向传播(backward pass)、参数更新(parameter update)等步骤。每个epoch 都会对整个数据集进行一次遍历,更新模型参数。通常训练过程中会跟踪损失值的变化,以判断模型的收敛情况。
python
#验证模型(判断模型是否过拟合)
#设置为评估模型
model.eval()
#不需要模型参与训练
with torch.no_grad():
val_acc = 0.0 #定义验证的精度
val_loss = 0.0 #定义验证的loss
for i, (input_ids, attention_mask, token_type_ids, label) in enumerate(val_loader):
# 将数据放到DVEVICE上面
input_ids, attention_mask, token_type_ids, label = input_ids.to(DEVICE), attention_mask.to(
DEVICE), token_type_ids.to(DEVICE), label.to(DEVICE)
# 前向计算(将数据输入模型得到输出)
out = model(input_ids, attention_mask, token_type_ids)
# 根据输出计算损失
val_loss += loss_func(out, label)
#根据数据,计算验证精度
out = out.argmax(dim=1)
val_acc+=(out==label).sum().item()
val_loss/=len(val_loader)
val_acc/=len(val_loader)
print(f"验证集:loss:{val_loss},acc:{val_acc}")
#根据验证准确率保存最优参数
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(),"params/best_bert.pth") # 目录必须手动创建 或 python 代码创建
print(f"EPOCH:{epoch}:保存最优参数:acc{best_val_acc}")
#保存最后一轮参数
torch.save(model.state_dict(), "params/last_bert.pth")
print(f"EPOCH:{epoch}:最后一轮参数保存成功!")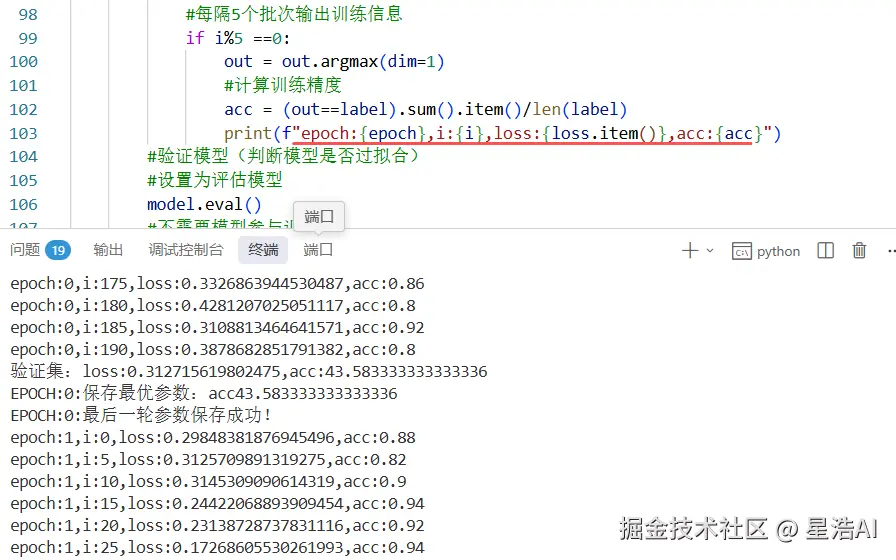
7.下期预告:最终效果评估与测试
在模型训练完成后,需要评估其在测试集上的性能。通常使用准确率、精确率、召回率和F1分数等指标来衡量模型的效果。
8.小结
介绍了如何使用Hugging Face的 BERT模型进行中文评价情感分析的微调训练。
我们从加载数据集、制作Datasets、词汇表操作、模型设计、自定义训练,下期介绍效果评估与测试,逐步讲解了整个微调过程。