项目3:增强版智能知识库
考察内容
知识点:语义分块、MMR去重、上下文压缩、多向量检索(摘要/假设问题)、Self-querying元数据检索
功能
- 支持语义分割,不按字数硬切
- 检索结果 MMR 去重,避免重复内容
- 上下文压缩精简冗余文档
- 多向量:摘要检索、假设问题检索优化匹配
- Self-querying 自动解析时间/分类/评分等元数据过滤
价值
完成此项目,RAG所有高级玩法全部吃透。
项目框架
文档加载
3-enhanced-knowledge-base/utils/loader.py
python
# 文档加载器:读取本地 txt 文档
from langchain_community.document_loaders import TextLoader, PyMuPDFLoader
import os
# 參考
# 文件路径
# DOC_PATH = "./docs/test.txt"
# loader = TextLoader(DOC_PATH, encoding="utf-8")
# # 读取全文
# documents = loader.load()
def load_file(file_path):
"""加载单份文档并挂载基础元数据"""
ext = os.path.splitext(file_path)[-1]
print("ext: ", ext)
if ext == ".txt":
loader = TextLoader(file_path, encoding="utf-8")
elif ext == ".pdf":
loader = PyMuPDFLoader(file_path)
else:
raise ValueError("暂只支持txt、pdf格式")
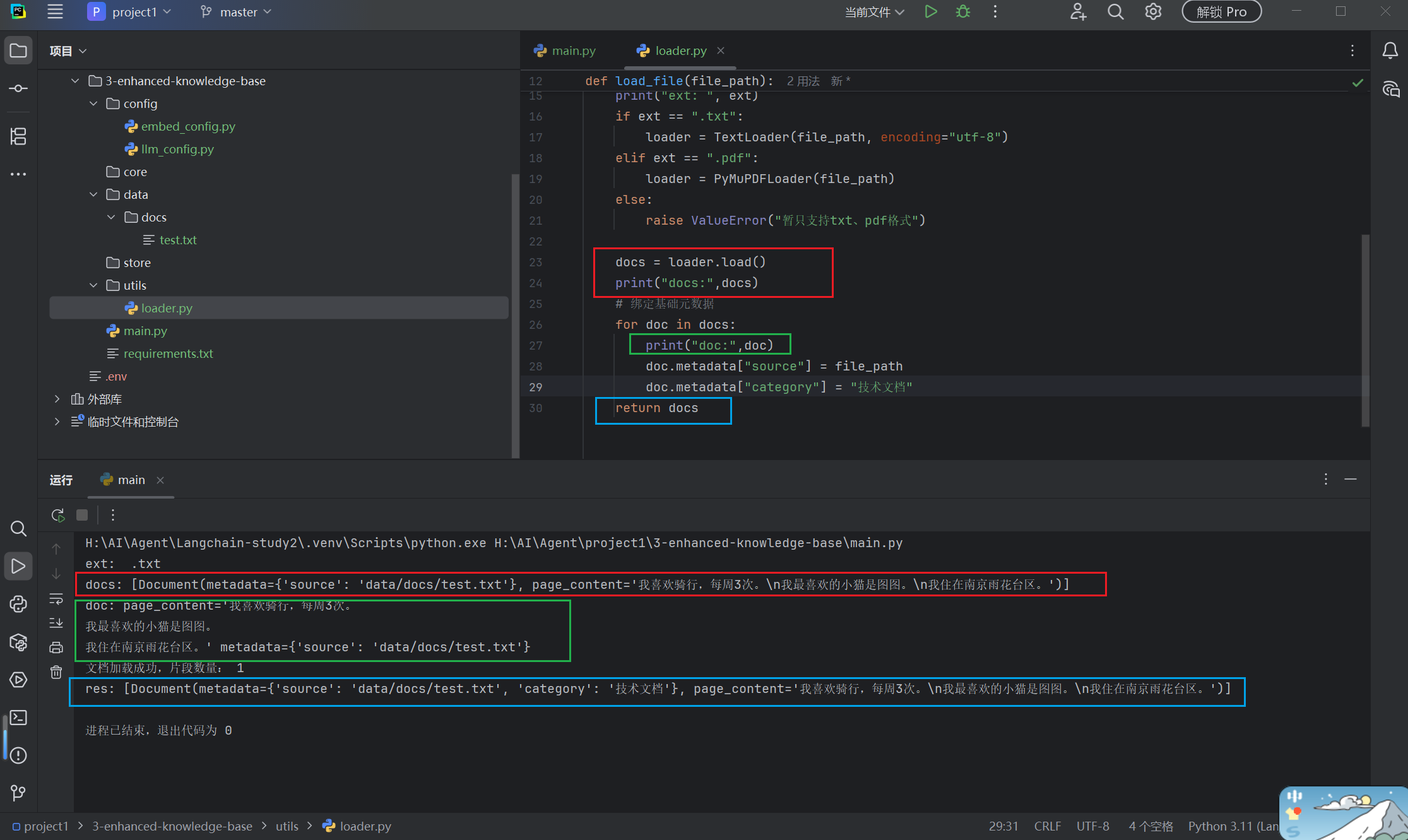
docs = loader.load()
print("docs:",docs)
# 绑定基础元数据
for doc in docs:
print("doc:",doc)
doc.metadata["source"] = file_path
doc.metadata["category"] = "技术文档"
return docs入口3-enhanced-knowledge-base/main.py
python
from utils.loader import load_file
if __name__ == "__main__":
# 后续把文档放进data/raw_docs里,替换路径测试
test_path = "data/docs/test.txt"
try:
res = load_file(test_path)
print("文档加载成功,片段数量:", len(res))
print("res:",res)
except Exception as e:
print("加载异常:", e)运行结果
语义分块 Semantic Chunking
RAG 高级核心功能第一步------语义分块
这一步非常关键,它决定了知识库的 "颗粒度" 是否聪明。不按字数硬切,而是根据语义相似度来断开文档。
使用LangChain自带的SemanticChunker对中文内容进行切块,效果很垃圾,SemanticChunker的相似度计算逻辑 + 分块策略对中文极不友好,调不出好效果。
改用 BCE + 自定义语义分块,这是目前国内最稳、最准、最不抽风的分块方式。
真正可用的分块方法
python
# ======================
# 中文语义分块
# ======================
def split_text_by_semantic(text_list_or_str, max_chunk_len=800, similarity_threshold=0.65):
# 自动把列表转成完整文本
if isinstance(text_list_or_str, list):
text = "\n".join([str(t) for t in text_list_or_str if t])
else:
text = str(text_list_or_str)
# 按句子/段落切分
sentences = []
for line in text.split("\n"):
line = line.strip()
if len(line) > 5:
sentences.append(line)
embedding_model = get_embedding()
if not sentences:
return [text]
chunks = []
current = [sentences[0]]
for s in sentences[1:]:
try:
vec1 = embedding_model.embed_documents([current[-1]])
vec2 = embedding_model.embed_documents([s])
sim = cosine_similarity(vec1, vec2)[0][0]
except:
sim = 0
# 不相似 or 超长 → 切分
if sim < similarity_threshold or len("\n".join(current)) > max_chunk_len:
chunks.append("\n".join(current))
current = [s]
else:
current.append(s)
if current:
chunks.append("\n".join(current))
return chunks运行结果
返回是list,元素是Document对象,包含page_content等属性(找了两篇公众号的内容当做素材,但是平台审核不通过,就不放截图了)
多向量检索(HyDE + 摘要向量)
-
多向量检索:一个文档块 = 3 份向量
- 原文向量
- 摘要向量(LLM 总结这段话)
- HyDE 假设问题向量(LLM 猜用户会怎么问)
-
检索时 3 路同时搜 → 命中率暴涨
-
HyDE:假设文档嵌入,Hypothetical Document Embeddings
- 用户问一个问题 → 先用 LLM 生成一段 "假设的答案文档" → 把这段假答案做 embedding → 用这个向量去库里搜最相似的真实文档。
核心代码
python
# core/multi_vector_builder.py
from langchain_core.prompts import PromptTemplate
from langchain_core.documents import Document
from config.llm_config import get_llm
# 1. 生成摘要
def generate_summary(chunk):
llm = get_llm()
prompt = PromptTemplate(
input_variables=["text"],
template="请给下面的文本生成简洁摘要:\n{text}"
)
chain = prompt | llm
return chain.invoke({"text": chunk.page_content})
# 2. 生成 HyDE 假设问题
def generate_hypothetical_questions(chunk):
llm = get_llm()
prompt = PromptTemplate(
input_variables=["text"],
template="根据文本,生成3个用户可能提出的问题:\n{text}"
)
chain = prompt | llm
return chain.invoke({"text": chunk.page_content})
# 3. 构建多向量文档(原文+摘要+HyDE)
def build_multi_vector_docs(chunks):
multi_docs = []
for i, chunk in enumerate(chunks):
# 基础元数据
meta = chunk.metadata
meta["chunk_id"] = f"chunk_{i}"
# 原文文档
multi_docs.append(Document(page_content=chunk.page_content, metadata=meta))
# 摘要文档
summary = generate_summary(chunk)
multi_docs.append(Document(page_content=f"摘要:{summary}", metadata=meta))
# 假设问题文档
questions = generate_hypothetical_questions(chunk)
multi_docs.append(Document(page_content=f"可能问题:{questions}", metadata=meta))
print(f"构建完成,共生成 {len(multi_docs)} 个多向量条目")
return multi_docs结果结构分析
-
multi_docs = 纯列表 listDocument,里面每个元素都是带 page_content + metadata 的对象。
-
多向量 = 1 个原文块 → 扩展成 3 个 Document
- 第 1 个:原文
- 第 2 个:摘要
- 第 3 个:HyDE 假设问题
-
向量库不知道它们是一组的,FAISS 只认一个个独立向量,不会自动分组。
-
不管是去重、分组、还是合并结果,都要我们手动控制。
-
真正工程上怎么用?
- 存入时:给 metadata 打标记
- 检索后:按 chunk_id 去重、合并、排序
运行失败
- 生成多向量失败,提示加载异常: 'str' object has no attribute 'metadata'。
原因,生成多向量的方法semantic_chunks = split_text_by_semantic(raw_docs)返回的是字符串数组list,不是LangChain的Document对象,字符串没有metadata.
解决:将字符串改回为Document.
运行结果
与分析的结构一致,listDocument,每个元素都是带 page_content + metadata 的对象。
向量库存储与多路检索
将向量存入FAISS.
-
多向量检索 =1 个原文块 → 生成 3 条向量(原文 + 摘要 + HyDE)→ 一起存进 FAISS → 查询时 3 路同时匹配 → 最后按 chunk_id 去重拿回最相关的原文
- 这就是大厂 RAG 系统的标准多路召回。
-
本节要做的内容:
- 给 multi_docs 打上类型标记(底层关键)
- 存入向量库 + 实现多路检索 + 自动去重
核心代码
python
# core/retriever.py
from langchain_community.vectorstores import FAISS
from config.embed_config import get_embedding
# 构建并保存向量库
def create_multi_vector_store(docs, save_path="faiss_multi_db"):
embeddings = get_embedding()
store = FAISS.from_documents(docs, embeddings)
store.save_local(save_path)
print("✅ 多路向量库存储完成")
return store
# 核心:多路检索 + 自动去重
def multi_retrieve(query, vector_store, top_k=3):
# 1. 多路召回(原文、摘要、问题一起匹配)
retriever = vector_store.as_retriever(search_kwargs={"k": top_k * 3})
docs = retriever.get_relevant_documents(query)
# 2. 按 chunk_id 去重(同一组只保留一个)
unique_chunks = []
seen_ids = set()
for doc in docs:
cid = doc.metadata["chunk_id"]
if cid not in seen_ids:
seen_ids.add(cid)
unique_chunks.append(doc)
# 数量达标就终止
if len(unique_chunks) >= top_k:
break
print(f"\n🎯 多路检索完成,去重后结果:{len(unique_chunks)} 条")
return unique_chunks运行结果
返回向量库的3个最相近的向量。
运行越来越慢。
look下各段的耗时情况。
- 加载文档,耗时:0:00:00.000999
- 语义分块,耗时:0:00:39.051776
- 生成多向量,耗时:0:04:56.142265
- 向量库存储,耗时:0:01:41.750813
- 多路检索,耗时:0:00:00.203046
优化思路
直接加载本地已保存的向量库,跳过加载文档、语义分块、生成多向量和存储向量库的操作。
python
# 加载向量库
def load_multi_vector_store(save_path="faiss_multi_db"):
embeddings = get_embedding()
return FAISS.load_local(save_path, embeddings, allow_dangerous_deserialization=True)开始判断本地是否存在向量库,存在则不加载,不存在则创建。
python
if os.path.exists("faiss_multi_db"):
store = load_multi_vector_store()
step0 = datetime.now()
print(f"向量库加载,耗时:{(step0 - start)}")
else:
# 创建向量库优化结果
- 向量库加载,耗时:0:00:00.339462
- 向量库存储/加载,耗时:0:00:00.339462
- 多路检索,耗时:0:00:00.517187
元数据检索 Self‑Querying
- 元数据检索
- 普通检索只能搜内容,Self‑Querying 能让大模型自动把自然语言转换成过滤规则。
- 例如:"2024年之后发布的关于AI的文档",AI自动解析为 内容关键词:AI,元数据过滤:year > 2024
核心代码
python
from config.llm_config import get_llm
from langchain_classic.chains.query_constructor.schema import AttributeInfo
from langchain_classic.retrievers import SelfQueryRetriever
# 定义:元数据字段说明(告诉AI每个字段是干嘛的)
metadata_field_info = [
AttributeInfo(
name="chunk_id",
description="文本块的唯一编号",
type="string"
),
AttributeInfo(
name="vector_type",
description="向量类型:original=原文, summary=摘要, hyde=假设问题",
type="string"
),
AttributeInfo(
name="source",
description="文档来源",
type="string"
)
]
# 文档内容描述(帮助AI理解我们在检索什么)
document_content_description = "知识库文档内容"
def build_self_query_retriever(vector_store):
"""
构建 Self-Query 智能检索器
功能:自动把自然语言 → 过滤条件
"""
llm = get_llm()
# 创建官方自带的智能检索器
self_query_retriever = SelfQueryRetriever.from_llm(
llm,
vector_store,
document_content_description,
metadata_field_info,
verbose=True # 打印解析过程(方便你看原理)
)
return self_query_retriever运行失败
-
输出:加载异常:
Self query retriever with Vector Store type <class 'langchain_community.vectorstores.faiss.FAISS'> not supported. -
原因
- 之前构建的向量库 store 是 FAISS →
sq_retriever = build_self_query_retriever(store)→ 传入的 store 就是 FAISS - SelfQueryRetriever 官方不支持 FAISS
- 之前构建的向量库 store 是 FAISS →
-
总结:LangChain 框架限制
- FAISS = 不支持 Self-Query
- Chroma / Pinecone / Milvus / PGVector = 支持 Self-Query
- 没写错代码,是工具不支持 ✅
-
解决
- 继续用 FAISS ✅️
- 把 MMR、多路检索学完
- 元数据原理已经懂了,环境不支持暂时跳过,完全不影响掌握高级 RAG
- 1 分钟把向量库从 FAISS 换成 Chroma然后立刻就能跑元数据检索
- 继续用 FAISS ✅️
MMR 多样性检索
- 普通检索:只返回复合度最高、但可能很重复、很相似的内容
- MMR 检索
-
最大边际相关性 Maximal Marginal Relevance
-
在相关的基础上,保证结果多样性,不重复、覆盖面更广
-
在 "和问题相关" 与 "结果之间不重复" 之间做平衡,既准确又多样。
-
MMR = λ× 相关性 − (1−λ)× 与已选结果的相似度
- λ=1 → 退化为普通相似度(最相关、易重复)
- λ=0 → 完全去重(最多样、易跑偏)
- 常用 λ=0.5(均衡)
-
搜索参数
- k:最终输出结果条数
- fetch_k:首轮筛选出的候选文档总数
- 逻辑:先筛选足量高相关候选,再从中择优选出指定条数,平衡相关性与内容多样性
-
核心代码
python
from config.embed_config import get_embedding
def mmr_retriever(vector_store, k=3):
retriever = vector_store.as_retriever(search_type="mmr", search_kwargs={"k": k, "fetch_k":k * 3})
return retrievermain.py测试
python
# 7 mmr检索
retriever = mmr_retriever(store)
results = retriever.invoke("你要提问的问题")运行结果
返回向量库的3个最相近的结果
上下文压缩 Contextual Compression
- 上下文压缩
- 检索回来的文档很长、很冗余
- 压缩器会自动把 "和问题无关的废话删掉",只保留关键句子
- → 让给 LLM 的内容更短、更精、更便宜、更快
- 上下文压缩 = 给检索器套了一层壳,不是先检索完再手动压缩
伪代码示意图
python
# 1. 先有基础检索器
retriever = store.as_retriever()
# 2. 套上压缩器 → 变成压缩检索器
compressed_retriever = 压缩器(retriever)
# 3. 用这个新的去检索 → 回来就是裁剪过的
result = compressed_retriever.invoke("问题")核心代码
python
from langchain_classic.retrievers import ContextualCompressionRetriever
from config.llm_config import get_llm
from langchain_classic.retrievers.document_compressors import LLMChainExtractor
def create_compression_retriever(retriever):
# 定义压缩器
extractor = LLMChainExtractor.from_llm(get_llm())
# 把 基础retriever + 压缩器 包装在一起
compressed_retriever = ContextualCompressionRetriever(base_retriever=retriever, base_compressor=extractor)
# 返回 压缩后的检索器
return compressed_retrievermain.py测试
python
# 8 上下文压缩(mmr检索)
retriever = create_compression_retriever(mmr_retriever(store))
results = retriever.invoke("输入你的问题")运行结果
返回向量库最相近的2条向量。
为什么mmr检索 + 上下文压缩只返回了2条内容,而mmr检索返回了3条
检索数量由底层检索器参数控制,压缩层不改变文档条数,只裁剪内容。在生成 MMR 检索器时指定 k 值即可限定返回数量。
压缩仅精简单篇文本内容,不会增减文档条目数。
mmr检索 + 上下文压缩的底层检索器是mmr检索器,而mmr检索器实际返回了3条,因此还是与实际结果对不上。
真实原因:LLMChainExtractor 自己会删文档。
提取器觉得某条文档和问题无关,它会直接整条丢掉,不告诉你,不报错 → 所以数量变少
因此实际现象符合组件特性:MMR 检索固定取回 3 条候选文档,上下文压缩会判定剔除无关文档,最终留存 2 条有效内容。文本做精简裁剪,无效条目直接舍弃。
项目4:结构化输出问答器
项目4:结构化输出问答器(Pydantic + 自定义OutputParser)
知识点:Pydantic结构化输出、自定义解析器、类NER信息抽取、RunnableLambda
功能
- 输入自然语言,自动抽取:天气/时间/地址/商品信息
- 强制固定JSON结构输出,失败自动校验重试
项目分析
模型必须严格按固定 JSON 格式输出。
例如:输入一句自然话,"明天北京会下雨吗?我想买件雨衣。"
输出
python
{
"weather": "下雨",
"time": "明天",
"address": "北京",
"goods": "雨衣"
}核心能力
- 信息抽取(类 NER):抽天气、时间、地址、商品
- 强制结构化输出:用 Pydantic 定义格式
- 自定义解析器:把 LLM 输出转成标准对象
- 失败重试:解析失败自动重新问 LLM
- 链式调用:用 RunnableLambda 组装流程
Pydantic 定义结构化数据模型
- 实体:Pydantic 是第三方 Python 库,属于项目依赖。
- 用法:用它定义数据结构、做数据校验、约束格式的写法,就是一种结构化编程模式。
- 作用:强制输出格式、自动校验、防止乱输出
核心代码
python
from pydantic import BaseModel, Field
class CustomModel(BaseModel):
weather: str = Field(default="", description="抽取的天气信息,如晴天、下雨、多云")
time: str = Field(default="", description="抽取的时间信息,如今天、明天、周一")
address: str = Field(default="", description="抽取的地址信息,如北京、上海、小区")
goods: str = Field(default="", description="抽取的商品信息,如雨衣、手机、奶茶")
# default=""
# 意思是:没抽到信息就默认为空字符串
# description="..."
# 意思是:给大模型看的说明,告诉它该抽什么内容拓展:选型分析
模型选择
是选择llm还是chatmodel?
结论
这个项目必须用 ChatModel(对话模型),普通 LLM(补全模型)不是不能用,但非常不推荐!
原因
- 结构更标准
- ChatModel 用 system + human + ai 三段式对话
- 大模型最吃这套提示词,抽取准确率最高
- 输出 JSON 更稳定
- 普通 LLM 是续写文本,容易乱输出
- 普通 LLM(比如 LLM 类、OpenAI 类)是文本补全模型,输入:今天天气...输出:...很好,适合出去玩
- 不是为 "对话" 设计的,很难强制输出标准 JSON,会经常失败
- ChatModel 专门用来 "回答问题",更听话
- 普通 LLM 是续写文本,容易乱输出
- LangChain 官方最佳实践
- 结构化输出、自定义解析、Agent 开发全部都是基于 ChatModel 设计的
编写提示词模板
写提示词 ChatPromptTemplate,作用:告诉大模型:你必须严格按照定义的 Pydantic 格式输出 JSON,不许说废话。
python
# 提示词模板:构造给大模型的提问格式
from langchain_core.prompts import ChatPromptTemplate
if __name__ == "__main__":
chat_prompt_template = ChatPromptTemplate.from_messages([
("system", """你必须严格遵守以下规则:
1. 从用户输入中抽取4个字段:天气(weather)、时间(time)、地址(address)、商品(goods)
2. 只输出纯净的JSON,不要解释、不要废话
3. 没有信息的字段填空字符串"""),
("user", "{user_input}")
])
chat_prompt = chat_prompt_template.invoke("今天天气不错")
print(chat_prompt)运行结果
python
messages=[SystemMessage(content='你必须严格遵守以下规则:\n 1. 从用户输入中抽取4个字段:天气(weather)、时间(time)、地址(address)、商品(goods)\n 2. 只输出纯净的JSON,不要解释、不要废话\n 3. 没有信息的字段填空字符串', additional_kwargs={}, response_metadata={}), HumanMessage(content='今天天气不错', additional_kwargs={}, response_metadata={})]初始化ChatModel
核心代码
python
from langchain_community.chat_models import ChatTongyi
chat_model = ChatTongyi(
model="qwen-plus", # 模型:qwen-turbo(轻量、快、便宜)/plus(均衡(RAG 首选))/max(最强、慢、贵)
dashscope_api_key=tongyi_api_key, # 阿里云 API Key(或环境变量)
temperature=0.7, # 随机性
max_tokens=2048,
streaming=True, # 流式返回(RAG 生成常用)
verbose=False
)
res = chat_model.invoke(chat_prompt)
print(res)运行结果
python
content='{"weather":"不错","time":"今天","address":"","goods":""}' additional_kwargs={} response_metadata={'finish_reason': 'stop', 'request_id': '3fe9965a-9243-91ef-8062-1cb5a08b22a3', 'token_usage': {'input_tokens': 84, 'output_tokens': 14, 'total_tokens': 98, 'prompt_tokens_details': {'cached_tokens': 0}}} id='lc_run--019e54c4-f4ab-7c50-9138-fde38656ebb2' tool_calls=[] invalid_tool_calls=[]搭建基础调用链路
- 用管道符拼接 提示词模板 + 模型,组成基础可执行链
- 先简单测试调用逻辑,暂不做解析
核心代码
python
chain = chat_prompt_template | chat_model
# chain.invoke("今天天气不错") # ❌ 报错,原因:LangChain 链要求:必须传键值对 dict
res = chain.invoke({"user_input": "今天天气不错"})
print(res)运行结果
python
content='{"weather":"不错","time":"今天","address":"","goods":""}' additional_kwargs={} response_metadata={'finish_reason': 'stop', 'request_id': '072bb037-34c2-9c58-84a9-1da4be03f720', 'token_usage': {'input_tokens': 84, 'output_tokens': 14, 'total_tokens': 98, 'prompt_tokens_details': {'cached_tokens': 0}}} id='lc_run--019e54ce-6ec7-78f0-ab04-33c37d229ab4' tool_calls=[] invalid_tool_calls=[]自定义解析器
目前ChatModel和LangChain链输出的都是
python
AIMessage(content='{"weather":"下雨", ...}')我们希望输出的格式为
python
CustomModel(weather='下雨', time='明天', address='北京', goods='')这就是解析器的作用。
核心代码
python
from langchain_core.output_parsers import BaseOutputParser
import json
class MyParser(BaseOutputParser):
def parse(self, output: str):
# 字符串转字典
obj = json.loads(output)
# 字典拆包给Pydantic
res = InfoExtraction(**obj)
return res
strParse = MyParser()
chain = chat_prompt_template | chat_model | strParse运行结果
python
weather='不错' time='今天' address='' goods=''失败自动重试
-
目标
- 成功:模型输出合法 JSON → 解析成功
- 失败:LLM 输出格式错误 / 解析异常
→ 不崩溃,自动重试调用模型,直到解析成功
-
LangChain重试机制
- LangChain 链路默认不会重试,抛异常 = 直接终止程序
- ✅ 真正重试:必须使用 tenacity 重试库 + 装饰器 @retry
-
实现重试的两个关键
- try/except:捕获解析错误(JSON 错误、Pydantic 校验错误)
- raise 主动抛错:告诉重试库 "本次失败,需要重试"
- @retry 装饰器:控制重试次数、间隔(真正执行重试)
-
完整流程
python调用模型 ↓ 获取输出 ↓ try 尝试解析 成功 → 返回结果 失败 → except 捕获 → 主动抛错 → 触发重试库重新执行整条链 -
两种必捕获的异常
-
json.JSONDecodeError
- 原因:模型返回的不是标准 JSON
- 位置:json.loads() 阶段
-
ValidationError(Pydantic)
- 原因:JSON 格式正确,但字段缺失 / 类型错误
- 位置:InfoExtraction(**data) 阶段
-
可统一捕获:
pythonexcept Exception as e: raise ValueError("解析失败,请重试")
-
-
RunnableLambda 包装
- 管道符 | 只接受 Runnable 类型组件,不认普通函数
- LangChain 里的管道
chain = A | B | C,A、B、C 必须都是 Runnable 类型 - 什么是 Runnable?
- prompt
- llm
- parser
- 工具
- RunnableLambda (普通函数)
- def retry_parser (output): 普通函数 ≠ Runnable → 直接放进管道会报错
- RunnableLambda
chain = prompt | llm | RunnableLambda(retry_parser)- 作用:把普通 Python 函数 → 变成管道能识别的 "可运行节点"
核心代码(含模拟异常代码)
python
from langchain_core.runnables import RunnableLambda
from tenacity import retry, stop_after_attempt, wait_fixed
retry_count = 0
@retry(stop=stop_after_attempt(2), wait=wait_fixed(0.5))
def retry_parser(output):
try:
global retry_count
retry_count += 1
print(f"第 {retry_count} 次解析执行")
# 强制失败,必重试
raise ValueError("手动模拟失败!")
# 自定义 BaseOutputParser LangChain 会自动调用 .content
# RunnableLambda (普通函数) 不会自动取 content,直接把 AIMessage 丢过来
str = output.content
res = InfoExtraction(**json.loads(str))
return res
except Exception as e:
raise ValueError("解析失败,请重试")
chain = chat_prompt_template | chat_model | RunnableLambda(retry_parser)运行结果
第1次解析失败,自动进行第2次。第2次失败不会触发重试。

- 重试次数
- stop_after_attempt(2)
- = 首次执行 + 重试 1 次 = 总共跑 2 次 = 异常后只再试 1 次 ✅