
最近刷到姚顺宇的一句话:"AI 不需要脑子!本科生就能干!做 AI 最重要的特质就是靠谱。"
当时我还纳闷,这么顶尖的 AI 研究员,怎么会说 AI 这么"简单"?
直到我扒完大模型推理背后的这些优化技巧才发现:原来那些听起来高大上的 RMSNorm、FlashAttention、Gumbel-Max,本质上全是我们高中就学过的数学小技巧,甚至和你生活里的买菜、排队、抽奖,逻辑一模一样!
今天就用最生活化的例子,带你把大模型里的这些"黑科技"拆得明明白白,看完你就会说:哦?原来我早就懂AI了?
- 为什么要给数据 "调平"?从两个城市的气温说起
先问你个问题: 有两个城市,A 城市一年四季都是 20℃,不冷不热;B 城市夏天 60℃热死人,冬天 -20℃冻死人。 如果只看平均温度,两个城市都是 20℃,你会觉得它们一样宜居吗?
肯定不会啊!B 城市的温度波动也太大了,根本没法住。
这就是大模型里最基础的问题:数据的"波动"。
大模型有上百层网络,数据在层之间传递的时候,数值会越变越大,就像 B 城市的温度,忽高忽低。 这会导致什么?
-
要么数值太大,直接把 GPU 的计算搞溢出,输出一堆乱码;
-
要么梯度消失,模型学不到东西,训练直接崩了。
所以工程师们想了个办法:给数据 "调平",也就是归一化。
最早的 LayerNorm,就像你整理一堆衣服: 先把所有衣服的平均位置对齐(减均值),再把它们的大小拉到统一的尺度(除以标准差),这样不管原来的衣服多大,整理完之后都整整齐齐,不会乱。
但是后来大家发现:其实对齐平均这一步,好像没那么重要? 模型真正关心的,不是数据的绝对位置,而是它们之间的相对大小啊!
于是就有了 RMSNorm:直接把对齐平均这一步砍了!只做尺度的缩放。 就像你叠衣服,不用先把所有衣服都铺平对齐,直接叠就行,叠完之后一样整齐,还省了一半的时间!
这一下就把计算量砍了好多:原来要两次遍历数据,现在一次就够了;原来要做一堆减法,现在都省了。GPU 跑起来快了好多,而且模型的效果几乎没差!
你看,这就是最基础的 Infra 优化:用一个数学上的小假设,砍掉没用的计算,把速度提上去,就这么简单。
- 打分变概率:选餐厅的"爱憎分明"法则
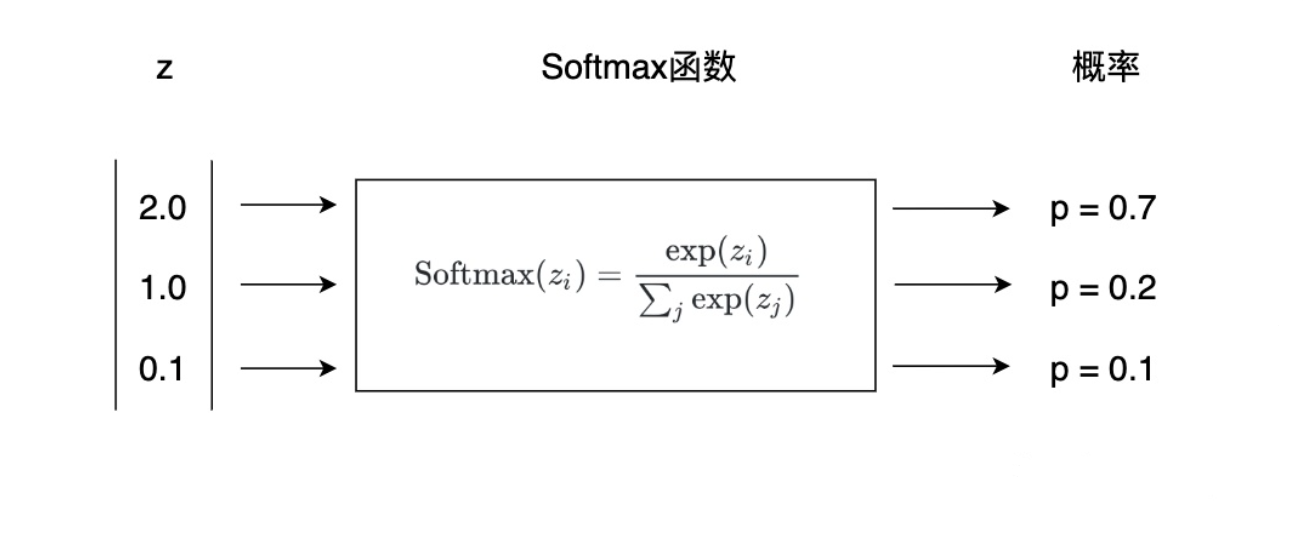
周末你想出去吃饭,给三个餐厅打了分: 猫咖:3.2 分,日料:1.5 分,川菜:-0.8 分。
现在你想把这些分数,变成你去每个餐厅的概率,怎么算?
直接加起来算百分比?不行啊,有负数,而且 3.2 比 1.5 高了一点,但是直接算的话,差距不够大,你本来更想去猫咖,结果算出来的概率差距没那么明显。
这时候 Softmax 就来了:它用了个指数函数,把这些分数都变成正数,然后再算比例。
就像上面的图里,3.2、1.5、-0.8,经过 Softmax 一算,直接变成了 0.7、0.2、0.1! 也就是 70% 的概率去猫咖,20% 去日料店,10% 去川菜馆。
而且它还放大了差距:本来猫咖只比日料高 1.7 分,算完之后概率直接差了 5 倍,完美体现了你"更想去猫咖"的偏好,爱憎分明。
但是这里还有个小问题:如果分数太大了怎么办?比如有人给猫咖打了 1000 分,那 e 的 1000 次方,直接就把 GPU 的计算搞溢出了,算出来一堆 NaN。
工程师又想了个小技巧:所有分数都先减去最高分! 比如最高分是 1000,那所有分数都减 1000,这样最大的分数就变成 0 了,其他的都是负数,e 的负数次方都是小于 1 的小数,再也不会溢出了! 而且数学上,这个操作结果完全不变,因为分子分母都乘了同一个 e 的 -1000 次方,约掉了。
就像你打分的时候,大家都先减去最高分,这样所有分数都不会太大,算起来就不会出错了,是不是很聪明?
- 排队的规矩:AI 也不能 "插队看未来"

你有没有过这种经历:排队买奶茶,你前面的人还没点单,你就偷偷看后面的人点了什么? 那肯定不行啊!作弊了啊!你排队的时候,只能看你前面的人点了啥,后面的你不能看,不然就乱套了。
大模型生成文字也是一样的道理!
比如你让 AI 写 "床前明月光",它生成第一个字 "床" 的时候,不能看后面的 "前""明" 这些字;生成第二个字 "前" 的时候,只能看 "床",不能看后面的;生成 "光" 的时候,才能看前面所有的字。
如果它提前看了后面的字,那就是作弊了,相当于考试提前看了答案,那还叫什么生成啊?
所以就有了 Causal Mask:它就像排队的规矩,给后面的字的分数直接加个负无穷,这样 Softmax 一算,这些后面的字的概率直接变成 0,模型根本就不会看它们。
就像上面的图里,黄色的是能看的,灰色的是不能看的,每个字只能看自己和前面的,后面的全屏蔽了,完美保证了因果关系。
而且现在的 FlashAttention,连那个大的掩码矩阵都不用存了! 直接在计算的时候,跳过后面的块就行,后面的数我根本就不读,也不算,直接省了一半的计算量和内存! 就像排队的时候,后面的人你直接不用管,不用看他们的单,直接处理前面的,省了好多功夫。
- 把 "慢计算" 变 "快并行":FlashAttention 的快速分拣术
你有没有见过快递站分拣快递? 原来的老办法,是把所有的快递都搬到大厅里,然后一个个分,但是大厅就那么大,快递太多了放不下,还要搬来搬去,慢死了。
后来的新办法,是把快递分成小包裹,一个个拿到分拣台,处理完一个,再拿下一个,不用都搬到大厅,这样就省了好多空间,速度也快多了。
FlashAttention 干的就是这个事!
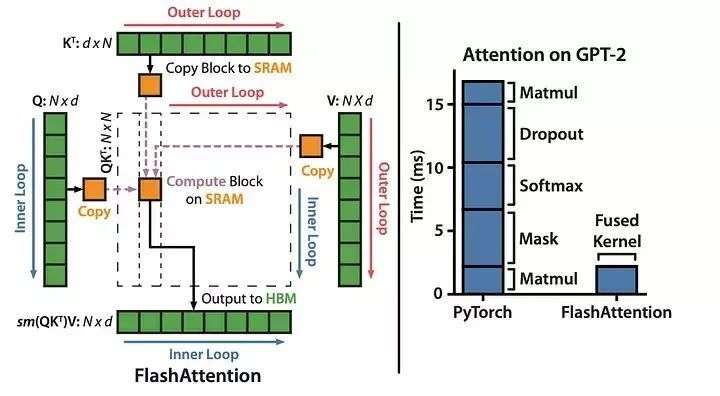
原来的 Attention 计算,要把所有的 Q、K、V 都搬到显存里,还要存一个巨大的中间矩阵,这个矩阵是 N×N 的,序列越长,这个矩阵越大,显存直接就爆了,还要频繁读写显存,慢得要命。
FlashAttention 就把这些矩阵切成小的块,就像把快递分成小包裹,一个个拿到 GPU 的小缓存(SRAM)里,处理完一个,再拿下一个。 而且它还搞了个 "边算边走" 的 Online Softmax,不用等所有数据都到了再算,来一块算一块,中间的结果都存在寄存器里,根本不用写回显存!
就像左边的图里,原来的老办法,要把所有数据都搬来搬去,现在的 FlashAttention,分块处理,把内存的读写减了好多,速度直接提了 7 倍多!
这就是所谓的 "内存墙" 的解法:原来 GPU 的算力很强,但是内存读写太慢了,所以我们就少读写内存,多用寄存器和小缓存,把计算和读写流水线化,这样速度就上去了。
- 抽奖的新玩法:原来抽奖也能并行?
算完概率之后,就要采样了,也就是抽奖:比如猫咖70%,日料20%,川菜10%,你要按照这个概率,抽一个出来,决定你去哪个餐厅。
原来的老办法,就是轮盘赌: 你转个轮盘,指针停在哪就是哪,但是这个操作要一个个算前缀和,比如先算猫咖的 70%,再加日料的 20%,再加川菜的 10%,然后看指针落在哪。
但是这个操作是串行的啊!GPU 是并行的,一个个算太慢了,尤其是大模型的词表有十几万个词,一个个加,要等到猴年马月?
这时候 Gumbel-Max 的技巧就来了! 数学家发现:只要给每个奖券的对数概率加一个随机的噪声,然后直接选最大的那个,结果和轮盘赌完全一样!
就像你给每个奖券都摇个随机数,然后大家比大小,谁大谁中,不用一个个转轮盘了!
这个操作太爽了:所有的奖券可以一起算,完全并行,GPU 一下子就能跑完,不用等一个个加。 而且跨卡的话,也不用把所有的结果都传过来,每个卡算自己的最大的,然后比一下就行,通信量直接从十几万降到了几个!
原来要串行的抽奖,一下子变成了并行的比大小,速度直接翻了好几倍! 你看,这又是一个数学的等价变换,把不适合硬件的操作,变成了适合的,就这么简单。
写在最后:大模型的优化,本质上都是 "偷懒" 的艺术
null
-
能少算一步就少算一步(RMSNorm 砍掉均值);
-
能不读写内存就不读写(FlashAttention 分块计算);
-
能并行就绝不串行(Gumbel-Max 把采样变成比大小);
-
能用数学变换等价简化,就绝不硬算。
这些操作,没有一个需要什么高深的数学,全是高中的数学知识,但是就是这些小小的技巧,把大模型的推理速度,从原来的几秒一个字,提升到了现在的几十字一秒,把百万 Token 的长文本推理,变成了可能。
原来姚顺宇说的 "AI 不需要脑子,靠谱就行",是这个意思啊! 大模型本身就是个实验科学,我们不用搞什么花里胡哨的新算法,只要把这些基础的数学技巧,用到位,把硬件的效率榨干,就能把 AI 的速度提上去,让更多人用得起大模型。
聊聊你的看法?
你平时用 AI 聊天、写东西的时候,有没有调过 Temperature 这个参数?你觉得调完之后,AI 的回答变化大吗? 或者你有没有发现,原来 AI 背后的这些技术,其实和我们生活里的小事这么像?来评论区聊聊你的看法吧!