一、什么是事件相关电位(ERP)?
1.1 通俗理解
python
你给朋友拍了 100 张照片,每张都有一点噪点:
单张照片: 看不清细节(噪声太大)
叠加 100 张:噪点互相抵消,脸越来越清晰!
ERP 就是这个道理:
100 次刺激 → 100 个脑电分段
叠加平均 → 随机噪声抵消 → 大脑的真实反应浮现出来1.2 为什么叠加平均有效?
python
假设:
大脑信号:每次刺激后都相同(比如 +2 μV 的峰值)
随机噪声:每次不同,有时正有时负
分段1:信号(+2) + 噪声(+3) = +5
分段2:信号(+2) + 噪声(-1) = +1
分段3:信号(+2) + 噪声(-2) = 0
分段4:信号(+2) + 噪声(+2) = +4
...
平均:(+5 + 1 + 0 + 4 + ...) / 100 ≈ +2
随机噪声平均后趋近于 0,信号浮现出来!1.3 经典 ERP 成分
python
┌──────────────────────────────────┐
│ 刺激出现后的脑电变化时间线 │
├──────────────────────────────────┤
│ │
│ P1/N1: 0-150ms(感觉加工) │
│ P200: 150-250ms(注意) │
│ N200: 200-350ms(冲突检测) │
│ P300: 300-500ms(认知加工) │
│ │
│ P = Positive(正波,向上) │
│ N = Negative(负波,向下) │
│ 数字 = 大约出现的时间(毫秒) │
└──────────────────────────────────┘二、环境准备与数据加载
2.1 导入库
python
# ========== 环境设置 ==========
# matplotlib.use('TkAgg'):
# 设置 matplotlib 的渲染后端为 TkAgg
# TkAgg 基于 Tkinter,Windows 系统自带,无需额外安装
# 必须在 import pyplot 之前设置
import matplotlib
matplotlib.use('TkAgg')
# pyplot:matplotlib 的主要绘图接口
# 提供类似 MATLAB 的绘图风格
import matplotlib.pyplot as plt
# mne:脑电/MEG 分析核心库
import mne
# numpy:科学计算库,提供高效的数组操作
import numpy as np
# os:处理文件和目录路径
import os
# warnings:控制警告信息的输出
import warnings
warnings.filterwarnings('ignore') # 隐藏所有警告
# ========== 中文字体设置 ==========
# rcParams:matplotlib 的全局配置字典
# 'font.sans-serif':无衬线字体列表,按顺序尝试
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei']
# 'axes.unicode_minus':是否使用 Unicode 减号
# False = 使用 ASCII 连字符 "-",避免中文字体下显示为方块
plt.rcParams['axes.unicode_minus'] = False
print("="*60)
print("MNE-Python 第7天:事件相关电位(ERP)分析")
print("="*60)2.2 加载数据并预处理
python
# ---------- 1. 加载数据 ----------
sample_data_folder = mne.datasets.sample.data_path()
raw_fname = os.path.join(sample_data_folder, 'MEG', 'sample', 'sample_audvis_raw.fif')
raw = mne.io.read_raw_fif(raw_fname, preload=False)
print("✅ 原始数据加载完成")
# ---------- 2. 快速预处理 ----------
print("\n快速预处理...")
# 提取 EEG + EOG + STIM 通道
# pick_types():根据类型筛选通道
# eeg=True:保留脑电通道(分析目标)
# eog=True:保留眼电通道(ICA 需要)
# stim=True:保留刺激通道(提取事件需要)
raw_eeg = raw.copy().pick_types(eeg=True, eog=True, stim=True)
# 重命名 EEG 通道
# 列表推导式:遍历通道名,只保留以 'EEG' 开头的
eeg_names = [ch for ch in raw_eeg.ch_names if ch.startswith('EEG')]
montage = mne.channels.make_standard_montage('standard_1020')
standard_names = montage.ch_names[:len(eeg_names)]
# dict(zip(A, B)):将两个列表配对为字典
# {'EEG 001':'Fz', 'EEG 002':'Cz', ...}
raw_eeg.rename_channels(dict(zip(eeg_names, standard_names)))
raw_eeg.set_montage(montage)
# 🔑 关键:先加载到内存,再做滤波
raw_eeg.load_data()
# 陷波滤波:去除 60Hz 工频干扰
raw_eeg.notch_filter(freqs=60, picks='eeg', verbose=False)
# 带通滤波:保留 1-40 Hz
# l_freq=1:高通 1Hz,去除缓慢漂移
# h_freq=40:低通 40Hz,去除高频肌肉噪声
raw_eeg.filter(l_freq=1, h_freq=40, picks='eeg', verbose=False)
# 重参考:平均参考(每个通道减去所有通道的均值)
raw_eeg.set_eeg_reference('average', verbose=False)
print("✅ 快速预处理完成")2.3 提取事件并创建 Epochs
python
# ---------- 3. 提取事件 ----------
print("\n提取事件...")
# find_events():从刺激通道自动检测事件
events = mne.find_events(raw_eeg, stim_channel='STI 014')
print(f" 提取到 {len(events)} 个事件")
# 事件 ID 字典
event_id = {
'听觉/左耳': 1,
'听觉/右耳': 2,
'视觉/左眼': 3,
'视觉/右眼': 4
}
# ---------- 4. 创建 Epochs ----------
print("\n创建 Epochs...")
# reject:拒绝幅度 > 150μV 的坏段
reject_criteria = dict(eeg=150e-6)
epochs = mne.Epochs(
raw_eeg, # 连续数据
events, # 事件数组
event_id=event_id, # 事件 ID 字典
tmin=-0.2, # 刺激前 0.2 秒
tmax=0.5, # 刺激后 0.5 秒
baseline=(-0.2, 0), # 基线校正:刺激前 0.2 秒
reject=reject_criteria, # 拒绝坏段
preload=True, # 加载到内存
verbose=False
)
print(f"✅ Epochs 创建完成")
print(f" 总事件: {len(events)}, 保留: {len(epochs)}, 丢弃: {len(events)-len(epochs)}")三、🔑 重要步骤:检查可用的通道
3.1 为什么需要检查?
python
不同数据集的通道可能不同:
- 有些有 Pz,有些没有
- 有些 64 通道,有些 32 通道
- 通道名可能不同(Pz vs PZ vs pz)
经验:永远不要假设数据中有什么通道!
先用代码查看,再决定用什么通道。3.2 代码实现
python
# ---------- 2.5 查看实际有哪些通道 ----------
print("\n数据中的 EEG 通道(前20个):")
# 筛选出所有 EEG 类型的通道
# 列表推导式 + get_channel_types()
eeg_chs = [ch for ch in raw_eeg.ch_names
if raw_eeg.get_channel_types(picks=[ch])[0] == 'eeg']
# 打印前 20 个通道名
for i, ch in enumerate(eeg_chs[:20]):
print(f" {i:2d}: {ch}", end=" ") # end=" " 表示不换行
if (i + 1) % 5 == 0: # 每 5 个换一行
print()
print(f"\n总 EEG 通道数: {len(eeg_chs)}")
# 🔑 从实际存在的通道中选择要绘图的通道
if 'Cz' in eeg_chs:
# Cz 存在 → 首选 Cz(头顶中央,ERP 分析最常用)
plot_channels = ['Cz']
# 如果 Fz 也存在,加上
if 'Fz' in eeg_chs:
plot_channels.append('Fz')
# 如果 Pz 也存在,加上
if 'Pz' in eeg_chs:
plot_channels.append('Pz')
# 如果只找到了 Cz 一个,就用前 3 个 EEG 通道
if len(plot_channels) == 1:
plot_channels = eeg_chs[:3]
else:
# Cz 不存在 → 直接用前 3 个 EEG 通道
plot_channels = eeg_chs[:3]
print(f"\n将使用这些通道绘图: {plot_channels}")代码逻辑解析:
python
检查通道的逻辑流程:
┌─────────────────────────────────┐
│ 数据中有哪些 EEG 通道? │
│ eeg_chs = [Fp1, Fpz, Fp2, ...] │
└────────────┬────────────────────┘
↓
┌──────────────┐
│ Cz 存在吗? │
└──┬───────┬───┘
YES NO
↓ ↓
以 Cz 为首 直接用前3个通道
↓
┌──────────────┐
│ Fz 存在吗? │
└──┬───────┬───┘
YES NO
↓ ↓
添加 Fz 跳过
↓
┌──────────────┐
│ Pz 存在吗? │
└──┬───────┬───┘
YES NO
↓ ↓
添加 Pz 跳过
↓
plot_channels = ['Cz', 'Fz']
或 ['Cz'] 或 ['Cz', 'Fz', 'Pz']⚠️ 核心经验:永远在使用通道名前确认它是否存在!
四、提取事件并创建 Epochs
python
# ---------- 3. 提取事件和创建 Epochs ----------
# find_events():从刺激通道(STI 014)自动检测事件
# 返回值:events 数组,形状为 (事件数, 3)
# 第0列:事件发生的采样点编号
# 第1列:事件持续的采样点数(通常为 0)
# 第2列:事件编号
events = mne.find_events(raw_eeg, stim_channel='STI 014')
# 事件 ID 字典:将数字编号映射为可读的条件名
event_id = {
'听觉/左耳': 1, # 编号1:左耳听到纯音
'听觉/右耳': 2, # 编号2:右耳听到纯音
'视觉/左眼': 3, # 编号3:左眼看到棋盘格
'视觉/右眼': 4 # 编号4:右眼看到棋盘格
}
# 创建 Epochs(第6天学的内容)
epochs = mne.Epochs(
raw_eeg, # 连续 EEG 数据
events, # 事件数组
event_id=event_id, # 条件名→编号映射
tmin=-0.2, # 刺激前 0.2 秒
tmax=0.5, # 刺激后 0.5 秒
baseline=(-0.2, 0), # 基线校正:用刺激前 0.2 秒
reject=dict(eeg=150e-6), # 拒绝幅度 >150μV 的坏段
preload=True, # 加载到内存
verbose=False # 不打印详细信息
)
print(f"✅ Epochs: {len(epochs)} 个分段")五、叠加平均计算 ERP
5.1 什么是叠加平均?
python
# average() 的数学原理:
# 对于每个时间点 t:
# evoked[t] = (epoch_1[t] + epoch_2[t] + ... + epoch_N[t]) / N
#
# N = 该条件的分段数量
# 效果:
# 随机噪声 → 每次不同 → 平均后趋近于 0
# 大脑信号 → 每次相同 → 平均后保持不变
# → 信噪比提升 √N 倍!5.2 代码实现
python
# ---------- 4. 计算各条件 ERP ----------
print("\n计算 ERP...")
# 创建一个空字典,存储各条件的 Evoked 对象
evoked_dict = {}
# 遍历每种实验条件
for cond_name in event_id.keys():
# epochs[cond_name]:通过条件名筛选分段
# .average():对所有筛选出的分段做叠加平均
evoked_dict[cond_name] = epochs[cond_name].average()
# 打印该条件的分段数量
n_epochs = len(epochs[cond_name])
print(f" {cond_name}: {n_epochs} 个分段 → ERP")
print("✅ 各条件 ERP 计算完成")Evoked 对象的结构:
python
Evoked 对象
├── .data → 二维数组 (通道数 × 时间点数)
├── .times → 一维时间数组,单位:秒
├── .ch_names → 通道名称列表
├── .info → 通道信息(类型、位置、采样率等)
├── .comment → 描述文字(如 "听觉/左耳")
├── .nave → 叠加的分段数量
│
├── .plot() → 画波形图
├── .plot_topomap() → 画地形图
└── .save() → 保存为文件六、ERP 波形可视化
6.1 绘制各条件的 ERP 波形
python
# ---------- 5. 绘制 ERP 波形 ----------
print("\n绘制 ERP 波形...")
# plt.subplots(2, 2):创建 2行×2列 的子图布局
# fig:整个画布对象
# axes:2×2 的子图数组
# axes[0,0] = 第1行第1列
# axes[0,1] = 第1行第2列
# axes[1,0] = 第2行第1列
# axes[1,1] = 第2行第2列
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
# zip():将两个序列配对
# zip(['A','B','C','D'], [ax1,ax2,ax3,ax4])
# → [('A', ax1), ('B', ax2), ('C', ax3), ('D', ax4)]
for idx, (cond_name, ax) in enumerate(zip(event_id.keys(), axes.flatten())):
# axes.flatten():将 2×2 数组展平为 1×4
# 这样可以用一个循环遍历所有子图
# evoked.plot():绘制 Evoked 波形
evoked_dict[cond_name].plot(
picks=plot_channels, # 🔑 使用实际存在的通道
axes=ax, # 画在哪个子图上
show=False, # 不单独弹出新窗口
spatial_colors=True, # 每个通道不同颜色
time_unit='ms' # 横轴单位:毫秒(更直观)
)
# 设置子图属性
ax.set_title(cond_name, fontsize=12, fontweight='bold')
# axvline():画竖线标注刺激点
# x=0:刺激发生的时刻
# color='red':红色
# linestyle='--':虚线
# alpha=0.5:半透明
ax.axvline(x=0, color='red', linestyle='--', alpha=0.5, label='刺激点')
# 添加网格线
ax.grid(True, alpha=0.3)
# 显示图例
ax.legend(fontsize=7)
# suptitle():整个画布的标题(sup = superior)
plt.suptitle(f'各条件 ERP(通道: {", ".join(plot_channels)})',
fontsize=16, fontweight='bold')
# tight_layout():自动调整子图之间的间距
plt.tight_layout()
# savefig():保存图片
plt.savefig('day7_erp_waveforms.png', dpi=150, bbox_inches='tight')
# show():显示图片
# block=True:阻塞模式,保持窗口打开直到手动关闭
plt.show(block=True)ERP 波形解读指南:
python
振幅 (μV)
↑
+5 │ ╱╲
│ ╱ ╲ ← P200(正向波,~200ms)
+2 │ ╱ ╲___
│ ╱ ╲___
0 ┼─────────────────→ 时间 (ms)
│╱ ↑ ╲
-2 │ 刺激点(0ms) ╲
│ ╲___ ← N400(负向波,~400ms)
-5 │
└────────────────────────
-200 0 200 400 600
关键观察点:
1. 基线期(-200~0ms)→ 应该接近 0(基线校正的效果)
2. 刺激后的早期反应(0~150ms)→ 感觉加工
3. 刺激后的中期反应(150~300ms)→ 注意和认知加工
4. 不同条件之间波形的差异 → 大脑对不同刺激的反应不同七、脑地形图
7.1 什么是脑地形图?
python
脑地形图 = 某个时刻,头皮上各位置的电压"地图"
前面(鼻子方向)
┌─────────────────┐
│ Fp1 ● ● Fp2│ ← ● 红色 = 正电压
│ F3 ● Fz● F4 │ ← ● 蓝色 = 负电压
│ C3 ● Cz● C4 │
│ P3 ● Pz● P4 │
│ O1 ● Oz● O2 │
└─────────────────┘
后面(后脑勺方向)
就像天气预报的温度分布图
但显示的是头皮上的电位分布(单位:微伏)7.2 代码实现
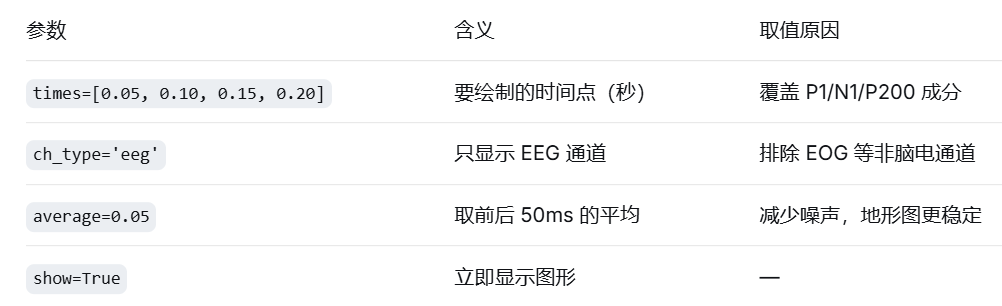
python
# ---------- 6. 脑地形图 ----------
print("\n绘制脑地形图...")
# plot_topomap():绘制脑地形图时间序列
fig = evoked_dict['听觉/左耳'].plot_topomap(
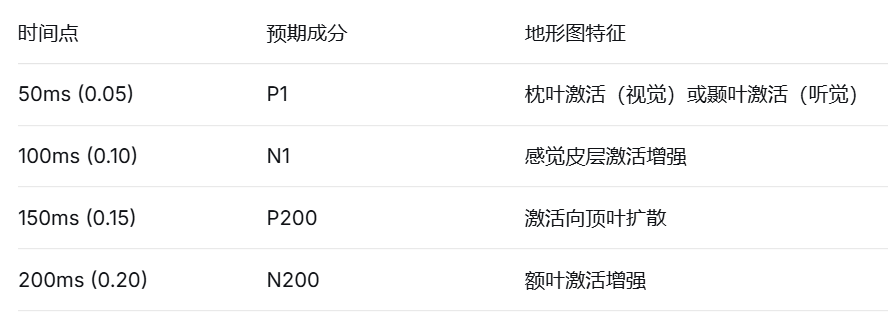
times=[0.05, 0.10, 0.15, 0.20], # 50, 100, 150, 200 毫秒
ch_type='eeg', # 通道类型:EEG
show=True, # 显示图形
average=0.05 # 每个时间点前后 ±50ms 取平均
)
plt.suptitle('听觉/左耳 - 脑地形图时间序列', fontsize=14, fontweight='bold')
plt.show(block=True)参数详解:
时间点选择参考:
八、差异波分析
8.1 什么是差异波?
python
差异波 = 条件A的ERP - 条件B的ERP
为什么要做差异波?
直接看两个 ERP:差异可能很小,不明显
差异波:差异被放大,共同部分消失
就像找不同游戏:
两张几乎一样的照片
差异波 = 照片A - 照片B
相同的地方 → 灰色(0)
不同的地方 → 凸显出来8.2 代码实现
python
# ---------- 7. 差异波 ----------
print("\n计算差异波...")
# mne.combine_evoked():对 Evoked 对象做数学运算
#
# 参数:
# 第1个参数:[Evoked对象列表]
# 第2个参数:weights=[权重列表]
#
# 计算方式:
# 结果 = 权重[0]×Evoked[0] + 权重[1]×Evoked[1] + ...
# 合并听觉条件(左耳和右耳取平均)
auditory_all = mne.combine_evoked(
[evoked_dict['听觉/左耳'], evoked_dict['听觉/右耳']],
weights=[0.5, 0.5] # 0.5×左耳 + 0.5×右耳 = 听觉平均
)
# 合并视觉条件(左眼和右眼取平均)
visual_all = mne.combine_evoked(
[evoked_dict['视觉/左眼'], evoked_dict['视觉/右眼']],
weights=[0.5, 0.5] # 0.5×左眼 + 0.5×右眼 = 视觉平均
)
# 计算跨模态差异波:听觉 - 视觉
diff_modality = mne.combine_evoked(
[auditory_all, visual_all],
weights=[1, -1] # 1×听觉 + (-1)×视觉 = 听觉 - 视觉
)
diff_modality.comment = '听觉 - 视觉'
print("✅ 差异波计算完成")weights 参数详解:

8.3 差异波可视化
python
# 绘制差异波
fig = diff_modality.plot(
picks=plot_channels[0], # 用第一个可用通道
show=True
)
plt.suptitle(f'差异波:听觉 - 视觉({plot_channels[0]})',
fontsize=14, fontweight='bold')
plt.show(block=True)差异波解读指南:
python
差异波(听觉 - 视觉):
振幅
↑
│ ╱╲ ← 正值:听觉反应 > 视觉反应
│ ╱ ╲
0 ─┼────────────→ 时间
│ ╱ ╲
│ ╱ ╲___ ← 负值:听觉反应 < 视觉反应
│╱
└──────────────────
看什么?
1. 偏离 0 的时间段 → 两种条件有差异
2. 偏离的幅度 → 差异的大小
3. 偏离的方向 →
正值 = 听觉反应更强
负值 = 视觉反应更强九、保存结果
python
# ---------- 8. 保存 ----------
print("\n保存结果...")
# 遍历各条件的 ERP,逐个保存
for cond_name, evoked in evoked_dict.items():
# 将文件名中的特殊字符替换掉
# 例如:'听觉/左耳' → '听觉_左耳'
safe_name = cond_name.replace('/', '_')
filename = f'day7_erp_{safe_name}.fif'
# save():将 Evoked 对象保存为 .fif 文件
evoked.save(filename, overwrite=True)
print(f" ✅ {filename}")
# 保存差异波
diff_modality.save('day7_diff_modality.fif', overwrite=True)
print(" ✅ day7_diff_modality.fif")
print("\n✅ 所有结果已保存")十、第7天完整代码
python
# ========== 环境设置 ==========
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import mne
import numpy as np
import os
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei']
plt.rcParams['axes.unicode_minus'] = False
print("="*60)
print("MNE-Python 第7天:事件相关电位(ERP)分析")
print("="*60)
# ---------- 1. 加载数据并预处理 ----------
sample_data_folder = mne.datasets.sample.data_path()
raw_fname = os.path.join(sample_data_folder, 'MEG', 'sample', 'sample_audvis_raw.fif')
raw = mne.io.read_raw_fif(raw_fname, preload=False)
raw_eeg = raw.copy().pick_types(eeg=True, eog=True, stim=True)
eeg_names = [ch for ch in raw_eeg.ch_names if ch.startswith('EEG')]
montage = mne.channels.make_standard_montage('standard_1020')
standard_names = montage.ch_names[:len(eeg_names)]
raw_eeg.rename_channels(dict(zip(eeg_names, standard_names)))
raw_eeg.set_montage(montage)
raw_eeg.load_data()
raw_eeg.notch_filter(freqs=60, picks='eeg', verbose=False)
raw_eeg.filter(l_freq=1, h_freq=40, picks='eeg', verbose=False)
raw_eeg.set_eeg_reference('average', verbose=False)
# ---------- 2. 查看可用通道(防御性编程) ----------
print("\n可用 EEG 通道:")
eeg_chs = [ch for ch in raw_eeg.ch_names
if raw_eeg.get_channel_types(picks=[ch])[0] == 'eeg']
print(f" 共 {len(eeg_chs)} 个,前10个: {eeg_chs[:10]}")
# 选择实际存在的通道
if 'Cz' in eeg_chs:
plot_channels = ['Cz']
if 'Fz' in eeg_chs: plot_channels.append('Fz')
if 'Pz' in eeg_chs: plot_channels.append('Pz')
if len(plot_channels) == 1: plot_channels = eeg_chs[:3]
else:
plot_channels = eeg_chs[:3]
print(f" 绘图通道: {plot_channels}")
# ---------- 3. 提取事件和创建 Epochs ----------
events = mne.find_events(raw_eeg, stim_channel='STI 014')
event_id = {'听觉/左耳': 1, '听觉/右耳': 2, '视觉/左眼': 3, '视觉/右眼': 4}
epochs = mne.Epochs(raw_eeg, events, event_id=event_id,
tmin=-0.2, tmax=0.5, baseline=(-0.2, 0),
reject=dict(eeg=150e-6), preload=True, verbose=False)
print(f"✅ Epochs: {len(epochs)} 个分段")
# ---------- 4. 计算 ERP ----------
print("\n计算 ERP...")
evoked_dict = {}
for cond_name in event_id.keys():
evoked_dict[cond_name] = epochs[cond_name].average()
print(f" {cond_name}: {len(epochs[cond_name])} 个分段")
# ---------- 5. 绘制 ERP 波形 ----------
print("\n绘制 ERP 波形...")
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
for idx, (cond_name, ax) in enumerate(zip(event_id.keys(), axes.flatten())):
evoked_dict[cond_name].plot(picks=plot_channels, axes=ax,
show=False, spatial_colors=True, time_unit='ms')
ax.set_title(cond_name, fontsize=12, fontweight='bold')
ax.axvline(x=0, color='red', linestyle='--', alpha=0.5, label='刺激点')
ax.grid(True, alpha=0.3)
ax.legend(fontsize=7)
plt.suptitle(f'各条件 ERP(通道: {", ".join(plot_channels)})', fontsize=16)
plt.tight_layout()
plt.savefig('day7_erp_waveforms.png', dpi=150)
plt.show(block=True)
# ---------- 6. 脑地形图 ----------
print("\n绘制脑地形图...")
fig = evoked_dict['听觉/左耳'].plot_topomap(
times=[0.05, 0.10, 0.15, 0.20], ch_type='eeg',
show=True, average=0.05)
plt.suptitle('听觉/左耳 - 脑地形图', fontsize=14)
plt.show(block=True)
# ---------- 7. 差异波 ----------
print("\n计算差异波...")
auditory_all = mne.combine_evoked(
[evoked_dict['听觉/左耳'], evoked_dict['听觉/右耳']], weights=[0.5, 0.5])
visual_all = mne.combine_evoked(
[evoked_dict['视觉/左眼'], evoked_dict['视觉/右眼']], weights=[0.5, 0.5])
diff_modality = mne.combine_evoked([auditory_all, visual_all], weights=[1, -1])
fig = diff_modality.plot(picks=plot_channels[0], show=True)
plt.suptitle(f'差异波:听觉 - 视觉({plot_channels[0]})', fontsize=14)
plt.show(block=True)
# ---------- 8. 保存 ----------
print("\n保存结果...")
for cond_name, evoked in evoked_dict.items():
safe_name = cond_name.replace('/', '_')
evoked.save(f'day7_erp_{safe_name}.fif', overwrite=True)
diff_modality.save('day7_diff_modality.fif', overwrite=True)
print("✅ 所有结果已保存")
print("\n" + "="*60)
print("第7天学习完成!")
print("="*60)
print("\n🎯 明日预告:第8天 - 时频分析(ERD/ERS)")