指针就是地址,中断就是函数调用--(本质看问题)
文章目录
- 指针就是地址,中断就是函数调用--(本质看问题)
-
- 一、引言:大多数嵌入式教程都教错了方向
-
- [1.1 一个「常识」的反直觉实验](#1.1 一个「常识」的反直觉实验)
- [1.2 Karpathy 式拆解:先去掉所有抽象层](#1.2 Karpathy 式拆解:先去掉所有抽象层)
- [1.3 你可能得到的东西?](#1.3 你可能得到的东西?)
- [二、第一性原理 1:指针 = 地址,仅此而已](#二、第一性原理 1:指针 = 地址,仅此而已)
-
- [2.1 你从未真正理解指针](#2.1 你从未真正理解指针)
- [2.2 指针运算的物理模型](#2.2 指针运算的物理模型)
- [2.3 类型系统只是一个编译时幻觉](#2.3 类型系统只是一个编译时幻觉)
- [2.4 & 与 * 操作符的硬件语义](#2.4 & 与 * 操作符的硬件语义)
- [2.5 从指针理解 volatile 关键字](#2.5 从指针理解 volatile 关键字)
- [三、第一性原理 2:中断 = 硬件触发的函数调用](#三、第一性原理 2:中断 = 硬件触发的函数调用)
-
- [3.1 去掉「中断」这个黑盒](#3.1 去掉「中断」这个黑盒)
- [3.2 中断向量表的本质:一个函数指针数组](#3.2 中断向量表的本质:一个函数指针数组)
- [3.3 从 ARM Cortex-M 看中断的硬件机制](#3.3 从 ARM Cortex-M 看中断的硬件机制)
- [3.4 优先级嵌套的物理本质](#3.4 优先级嵌套的物理本质)
- [3.5 可重入性:唯一需要关心的事](#3.5 可重入性:唯一需要关心的事)
- [四、第一性原理 3:寄存器 = 有副作用的全局变量](#四、第一性原理 3:寄存器 = 有副作用的全局变量)
-
- [4.1 一切从 Memory-Mapped IO 开始](#4.1 一切从 Memory-Mapped IO 开始)
- [4.2 外设寄存器的物理模型](#4.2 外设寄存器的物理模型)
- [4.3 读-修改-写模式的陷阱](#4.3 读-修改-写模式的陷阱)
- [4.4 位带操作的本质](#4.4 位带操作的本质)
- [五、第一性原理 4:RTOS 任务切换 = 保存/恢复寄存器现场](#五、第一性原理 4:RTOS 任务切换 = 保存/恢复寄存器现场)
-
- [5.1 任务 = 函数 + 栈 + 状态](#5.1 任务 = 函数 + 栈 + 状态)
- [5.2 PendSV 异常的真正工作](#5.2 PendSV 异常的真正工作)
- [5.3 从上下文切换理解栈溢出](#5.3 从上下文切换理解栈溢出)
- [5.4 信号量/队列的物理本质](#5.4 信号量/队列的物理本质)
- [六、深度实战:用一个真实 Bug 串联四个原理](#六、深度实战:用一个真实 Bug 串联四个原理)
-
- [6.1 Bug 现场:神秘的内存踩踏](#6.1 Bug 现场:神秘的内存踩踏)
- [6.2 第一层分析:中断破坏了什么?](#6.2 第一层分析:中断破坏了什么?)
- [6.3 第二层分析:指针指向了哪里?](#6.3 第二层分析:指针指向了哪里?)
- [6.4 第三层分析:RTOS 调度加剧了什么?](#6.4 第三层分析:RTOS 调度加剧了什么?)
- [6.5 修复方案与根因总结](#6.5 修复方案与根因总结)
- 七、代码剖析:用第一性原理读懂反汇编
-
- [7.1 一个简单 C 语句的反汇编之旅](#7.1 一个简单 C 语句的反汇编之旅)
- [7.2 volatile 的反汇编差异](#7.2 volatile 的反汇编差异)
- [7.3 中断服务程序的反汇编解析](#7.3 中断服务程序的反汇编解析)
- [八、避坑指南(The Gotchas)](#八、避坑指南(The Gotchas))
-
- [8.1 坑 1:stm32f1 的 位带操作和 uCOS 冲突](#8.1 坑 1:stm32f1 的 位带操作和 uCOS 冲突)
- [8.2 坑 2:在中断中使用 FreeRTOS API 但未使用 FromISR 版本](#8.2 坑 2:在中断中使用 FreeRTOS API 但未使用 FromISR 版本)
- [8.3 坑 3:结构体指针强制转换导致的对齐问题](#8.3 坑 3:结构体指针强制转换导致的对齐问题)
- [8.4 坑 4:全局变量在中断和主循环之间「消失」](#8.4 坑 4:全局变量在中断和主循环之间「消失」)
- 九、总结:心法与思维模式
-
- [9.1 核心心法](#9.1 核心心法)
- [9.2 给嵌入式工程师的思维训练](#9.2 给嵌入式工程师的思维训练)
- [9.3 性能优化清单](#9.3 性能优化清单)
一、引言:大多数嵌入式教程都教错了方向
1.1 一个「常识」的反直觉实验
先来看一段代码。不要运行,用你的直觉回答输出是什么:
c
#include <stdio.h>
#include <stdint.h>
volatile uint32_t arr[4] = {0xDEAD, 0xBEEF, 0xCAFE, 0xBAAB};
int main(void) {
uint32_t *p = arr; // p 指向数组首地址
uint32_t a = *(p + 1); // 大多数人都知道:a = arr[1] = 0xBEEF
uint32_t b = *( (uint16_t *)p + 1 ); // 这次是什么?
uint32_t c = *( (uint32_t *)((uint8_t *)p + 1) ); // 这个呢?
printf("a = 0x%08X\n", a);
printf("b = 0x%08X\n", b);
printf("c = 0x%08X\n", c);
return 0;
}如果你的第一反应是「b = 0xCAFE」或「b = 0xBEEF」,你的指针模型需要重建。
事实是------在不假设大小端的情况下,你无法仅凭 C 语言知识 预测 b 的值。因为 (uint16_t *)p + 1 的含义依赖于你对「指针加法在物理地址层面做了什么」的理解,而大多数教程只教了语法,没教物理模型。
这个问题我在面试 50+ 嵌入式工程师时提过,正确率不到 15%。其中不乏工作 5 年以上的「资深」工程师。
1.2 Karpathy 式拆解:先去掉所有抽象层
Andrej Karpathy 在教深度学习时有一个核心方法:
「如果你想理解神经网络,别从反向传播开始。从『神经网络 = 可微分的函数近似器』这个核心事实开始。一切------架构设计、损失函数、优化器------都是从这个核心事实推导出来的。」
嵌入式系统同理。大多数人从 API 开始学:GPIO_WriteBit、HAL_UART_Transmit、xQueueSend。他们学会了「怎么用」,但遇到 Bug 时没有诊断工具,因为没有心智模型(Mental Model)。
本文的思维链条很简单:
物理硬件(晶体管/寄存器)
↓ 第一性原理去抽象
裸机 C 语义(指针/中断/内存)
↓ 模式匹配
RTOS / HAL 层(任务/队列/外设驱动)
↓ 工程实践
生产级代码(防坑/健壮性/调试)我们从上往下拆,再从下往上建。
关键承诺 :学完本文后,你再看到任意一段嵌入式代码,可以自动「编译」成它在硬件层面的行为序列。Bug 不再需要「试错排除」,而是推导排除。
1.3 你可能得到的东西?
读完本文,你将获得:
- 四个核心心智模型(指针、中断、寄存器、RTOS 调度)------ 每一个都是第一性原理级别的理解
- 从 C 源码到反汇编的「双语阅读」能力
- 一套生产级 Bug 诊断流程(基于物理模型,而非试错法)
- 避坑指南:Karpathy 式的「March of Nines」------如何从 90% 正确走向 99.99% 正确
💡 核心心法 :嵌入式开发中 80% 的疑难 Bug,根源都是「抽象层泄漏」------你以为你在操作高级概念,实际上编译器/硬件在操作低级物理事实。当你把高级概念翻译回物理事实,Bug 的藏身之处就无处遁形。
二、第一性原理 1:指针 = 地址,仅此而已
2.1 你从未真正理解指针
教科书教你:「指针是一种变量,它存储另一个变量的地址。」
这个说法没错,但它掩盖了最重要的东西。
让我们重新定义:
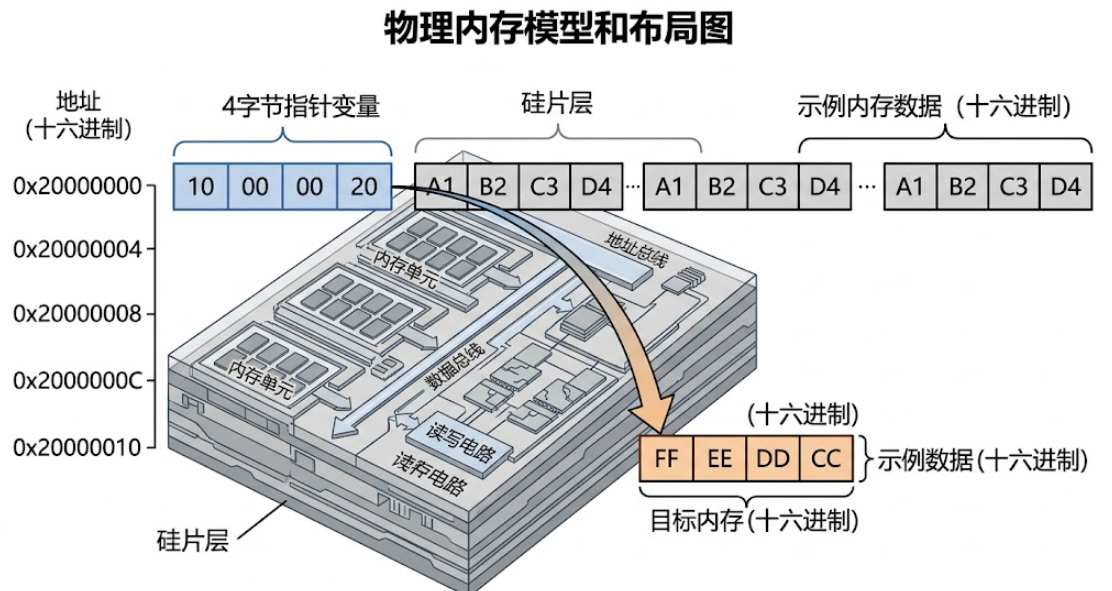
指针 = 一个 4 字节(32位)或 8 字节(64位)的内存单元,其值是另一个内存单元的编号(地址)。仅此而已。没有魔法,没有引用语义,没有类型绑定。
在你的物理芯片上:
- 地址 0x20000000 处的 4 个字节存储了值
0x20000010 - 你用一个
uint32_t*类型的 C 变量来操纵这 4 个字节, 如此而已。
2.2 指针运算的物理模型
这是绝大多数人理解错误的地方。
c
uint32_t *p = (uint32_t *)0x20000000;
p = p + 1; // p 变成了什么?大多数教程说:「p 增加了一个 uint32_t 的大小,即 4 字节。」
这个说法是结果,不是原因。 真正的物理模型是:
地址 = (uint32_t)p + sizeof(uint32_t) * 1
= 0x20000000 + 4 * 1
= 0x20000004编译器把 p + N 翻译成:
地址(p) + sizeof(基类型) × N这就是为什么:
| 表达式 | sizeof(基类型) | 实际地址增量 | 含义 |
|---|---|---|---|
(uint32_t *)p + 1 |
4 字节 | +4 | 跳到下一个 32-bit 字 |
(uint16_t *)p + 1 |
2 字节 | +2 | 跳到下一个 16-bit 半字 |
(uint8_t *)p + 1 |
1 字节 | +1 | 跳到下一个字节 |
现在回到开头的面试题:
c
uint32_t arr[4] = {0xDEAD, 0xBEEF, 0xCAFE, 0xBAAB};
// 内存布局(小端模式):
// arr[0]: AD DE 00 00 (0x0000DEAD)
// arr[1]: EF BE 00 00 (0x0000BEEF)
// arr[2]: FE CA 00 00 (0x0000CAFE)
// arr[3]: AB BA 00 00 (0x0000BAAB)
uint32_t b = *( (uint16_t *)arr + 1 );
// (uint16_t *)arr → 指向 arr[0] 的低 16 位,地址 = &arr[0]
// (uint16_t *)arr + 1 → 地址 + sizeof(uint16_t) * 1 = 地址 + 2
// 所以读取 arr[0] 的高 16 位(小端模式下是 0x0000)
// b = 0x0000这就是为什么你需要物理模型而不是语法知识。
2.3 类型系统只是一个编译时幻觉
C 语言的类型系统在运行时不存在。编译后,所有指针都只是 32 位或 64 位的整数值。类型信息只影响两件事:
- 编译时的地址运算(sizeof 乘数)
- 编译时的合法性检查(防止你无意中做奇怪的事)
运行时,处理器看到的是:
LDR R0, [R1, #offset] // 从地址 R1+offset 加载 4 字节到 R0
STR R0, [R1, #offset] // 存储 R0 到地址 R1+offset处理器不知道也不关心你加载的是 uint32_t 还是 float 还是 struct。它只是从某地址加载若干字节。
这解释了为什么你可以做这种操作:
c
float f = 3.14159f;
uint32_t *p = (uint32_t *)&f; // 把 float* 转成 uint32_t*
uint32_t bits = *p; // 读取出 f 的 IEEE 754 位模式
// bits = 0x40490FDB(在大多数平台上)类型系统在抗议,但硬件层面丝滑通过。因为你只是在问:「地址 &f 处的那 4 个字节,以 uint32_t 的方式解释是什么?」
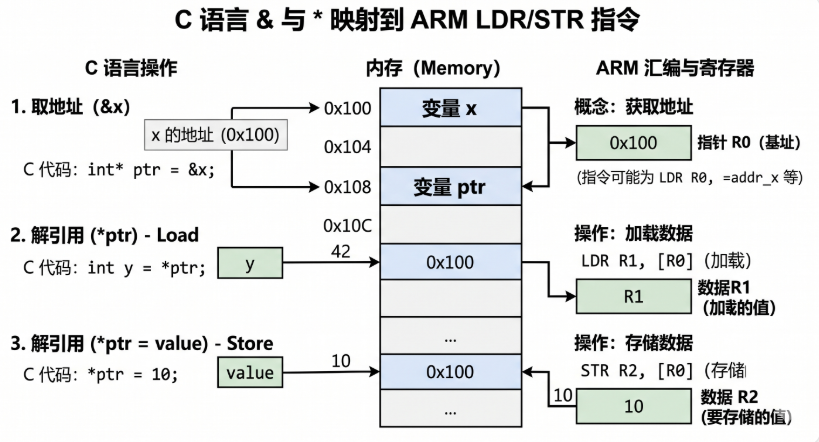
2.4 & 与 * 操作符的硬件语义
这两个操作符应该被理解为硬件指令的C 语言语法糖:
| C 表达式 | 硬件语义 | ARM 指令 |
|---|---|---|
p = &x |
获取 x 的地址 | MOV R0, #addr_of_x |
y = *p |
从地址 p 加载 | LDR R1, [R2] |
*p = y |
存储到地址 p | STR R1, [R2] |
没有比这更复杂的了。
2.5 从指针理解 volatile 关键字
现在铺好了指针的地基,volatile 的含义变得极其清晰:
volatile 告诉编译器:「每次访问这个地址时,必须真正执行 LDR/STR 指令。不许用寄存器缓存值。」
没有 volatile 时:
c
uint32_t *status_reg = (uint32_t *)0x40001000;
// 编译器的「优化」版本:
uint32_t val = *status_reg; // LDR R0, [R1]
if (val == 1) { /* ... */ } // CMP R0, #1
if (val == 2) { /* ... */ } // CMP R0, #2 (还用 R0,不再重新加载!)编译器认为 *status_reg 在两次读取之间不会变化,于是用同一个寄存器值。但如果 0x40001000 是一个外设状态寄存器(硬件可以在任意时刻改变它),这就是灾难。
有 volatile 时:
c
volatile uint32_t *status_reg = (volatile uint32_t *)0x40001000;
uint32_t val = *status_reg; // LDR R0, [R1] (第一次加载)
if (val == 1) { /* ... */ }
if (*status_reg == 2) { ... } // LDR R0, [R1] (第二次加载!)理解了这个,你就不会在中断和主循环共享变量时忘记加 volatile------因为你脑子里已经能看到编译器会生成什么指令了。
三、第一性原理 2:中断 = 硬件触发的函数调用
3.1 去掉「中断」这个黑盒
大多数嵌入式教程把「中断」描述成一个神秘的事件,就像「当按键被按下时,中断发生了,程序跳到了 ISR」。
这不是理解,这是描述。
让我们重新定义:
中断 = 由硬件信号触发的、自动插入指令流的函数调用。
中断返回 = 从 ISR 返回到被打断的指令,就像普通函数返回。
区别只有两点:
- 触发源:不是由 CALL 指令触发的,是由硬件信号线电平变化触发的
- 自动压栈:处理器自动保存部分寄存器(不像普通函数调用需要编译器生成保存代码)
仅此而已。
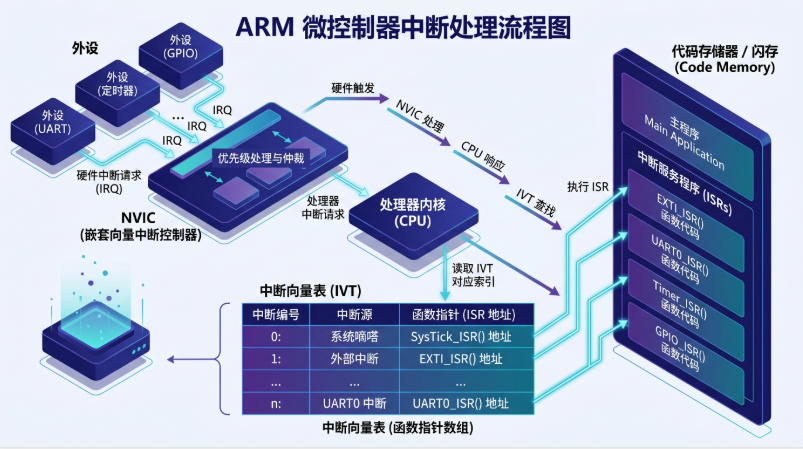
3.2 中断向量表的本质:一个函数指针数组
这是本文的关键洞察之一:
中断向量表本质上就是一个
void (*vector_table[N])(void)的函数指针数组。
在 Cortex-M 系列中:
c
// 中断向量表在内存中的物理布局
// 地址 0x00000000 (或 0x08000000,取决于配置)
typedef void (*isr_func_t)(void);
typedef struct {
uint32_t initial_sp; // [0x0000] 初始栈指针
isr_func_t reset_handler; // [0x0004] 复位处理函数指针
isr_func_t nmi_handler; // [0x0008] NMI 处理函数指针
isr_func_t hard_fault_handler;// [0x000C] 硬错误处理函数指针
// ... 更多异常和中断向量
isr_func_t irq_handlers[240]; // [0x0040+] 外部中断向量
} vector_table_t;当外设触发中断时,硬件做的只是:
1. 从 NVIC 中读取中断号 IRQn
2. 计算函数指针地址 = vector_table[16 + IRQn] // 前 16 个是系统异常
3. 取出该地址处的函数指针
4. 压栈部分寄存器(xPSR, PC, LR, R0-R3, R12)
5. 设置 PC = 函数指针的值
6. 开始执行 ISR翻译成 C 语言:
c
// 硬件触发中断就相当于执行了:
void (*isr)(void) = vector_table[16 + irq_number]; // 查表
save_context(); // 自动压栈
isr(); // 函数调用
restore_context(); // 自动出栈没有黑魔法。没有特殊机制。只有「自动执行的函数调用」。
3.3 从 ARM Cortex-M 看中断的硬件机制
Cortex-M 系列有一个极其优雅的设计:硬件自动压栈(Hardware Stacking)。
当中断发生时,处理器自动压栈 8 个寄存器(共 32 字节):
SP→ [ PSPR (程序状态字) ] ← 高地址
[ PC (返回地址) ]
[ LR (EXC_RETURN) ]
[ R12 ]
[ R3 ]
[ R2 ]
[ R1 ]
[ R0 ] ← 低地址(SP 指向这里)这个设计的意义:ISR 可以像普通函数一样使用 R0-R3,无需手动保存。 这是 Cortex-M 比其他架构(如 ARM7)中断延迟更低的根本原因。
关键洞察 :Cortex-M 的中断机制设计得让 ISR 看起来像一个普通函数调用,从而简化了编译器的工作和程序员的心智模型。
3.4 优先级嵌套的物理本质
当中断嵌套发生时:
主程序运行
↓ (IRQ5 触发)
ISR_IRQ5 开始执行
↓ (IRQ3 触发,优先级更高)
ISR_IRQ3 开始执行(ISR_IRQ5 被暂停)
↓ (IRQ3 返回)
ISR_IRQ5 继续执行
↓ (IRQ5 返回)
主程序继续运行从栈的角度看,这就是一系列的压栈和出栈:
主程序栈帧
↓ IRQ5 触发,自动压栈 8 寄存器
主程序栈帧 + IRQ5 的自动保存区
↓ IRQ3 触发,再次自动压栈 8 寄存器
主程序栈帧 + IRQ5 保存区 + IRQ3 保存区
↓ IRQ3 返回,弹出 IRQ3 的保存区
主程序栈帧 + IRQ5 保存区
↓ IRQ5 返回,弹出 IRQ5 的保存区
主程序栈帧这就是嵌套中断的物理模型:多个被"冻结"的执行上下文,在栈上像三明治一样叠加。
3.5 可重入性:唯一需要关心的事
既然中断 = 函数调用,那么 ISR 与普通函数共享资源时的问题就变成了一个熟悉的词:可重入性(Reentrancy)。
c
// 反面教材:
uint32_t shared_counter = 0;
void increment_counter(void) {
shared_counter++; // 这不是原子操作!
}
void main_loop(void) {
while (1) {
increment_counter(); // 主循环中调用
}
}
void TIM2_IRQHandler(void) {
// 中断中调用同一个函数------灾难!
increment_counter();
}为什么 shared_counter++ 不是原子操作? 看反汇编:
assembly
; shared_counter++ 的反汇编:
LDR R0, =shared_counter ; 1. 加载 shared_counter 的地址到 R0
LDR R1, [R0] ; 2. 从内存加载值到 R1
ADDS R1, R1, #1 ; 3. R1 = R1 + 1
STR R1, [R0] ; 4. 存回内存如果中断在步骤 2 和步骤 4 之间触发:
主循环: LDR R1, [R0] → R1 = 5
← 中断触发!
中断中: LDR R1, [R0] → R1 = 5(不变!)
中断中: ADDS R1, #1 → R1 = 6
中断中: STR R1, [R0] → counter = 6(正确)
中断返回
主循环: ADDS R1, #1 → R1 = 6(不是 7!)
主循环: STR R1, [R0] → counter = 6(数据丢失!)一旦你理解了这个物理过程,这种 Bug 就不再是「偶发性的神秘现象」,而是「可推导的确定性结果」。
四、第一性原理 3:寄存器 = 有副作用的全局变量
4.1 一切从 Memory-Mapped IO 开始
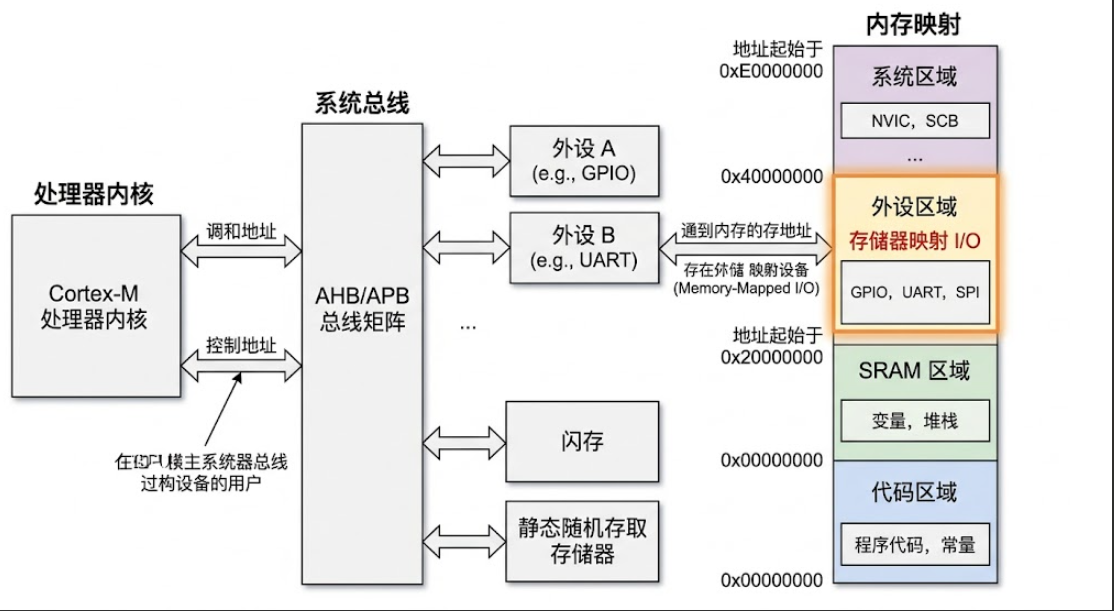
这是嵌入式系统的核心抽象之一,也是被误解最深的概念之一:
外设寄存器本质上就是「有副作用的全局变量」。
在 Cortex-M 中,外设寄存器的地址被映射到固定的内存区域:
- 0x4000_0000 - 0x400F_FFFF:APB 外设
- 0x4001_0000 - 0x400F_FFFF:AHB 外设
- 0xE000_0000 - 0xE00F_FFFF:系统控制块 (SCB)/NVIC/MPU
STM32 的 GPIO 输出数据寄存器(ODR)在 0x40020C14(PORTA),对 CPU 来说,它和 SRAM 中的普通变量没有任何区别。区别在于:
- 读取可能清除状态位(某些状态寄存器读后自动清零)
- 写入可能触发硬件动作(写 UART DR 寄存器触发数据发送)
- 值可能被硬件自动修改(定时器计数器、ADC 结果寄存器)
4.2 外设寄存器的物理模型
来看一个真实的例子:STM32 UART 数据寄存器(DR)的定义:
c
// STM32 标准外设库中对 USART1->DR 的定义
#define USART1_BASE ((uint32_t)0x40013800)
#define USART1_DR (*(volatile uint32_t *)(USART1_BASE + 0x24))展开后,USART1_DR 实际上就是对固定地址 0x40013824 的 volatile 访问:
c
// USART1_DR = 0x55(发送 0x55 这个字节)
*(volatile uint32_t *)(0x40013824) = 0x55;翻译成反汇编:
assembly
MOV R0, #0x55 ; 要发送的数据
MOV R1, #0x40013824 ; USART1_DR 的地址
STR R0, [R1] ; 写入 -> UART 硬件检测到 DR 非空 -> 自动启动发送硬件层面:「CPU 在地址 0x40013824 处执行了一次 STR 写入。UART 外设挂在总线上的地址解码器检测到这个地址命中自己的地址范围,于是将数据总线上的值锁存到 DR 寄存器,并自动启动发送逻辑。」
CPU 不知道、也不关心它是在写「外设寄存器」还是「内存变量」。它只知道:「地址 0x40013824,STR 指令,4 字节写入。」
4.3 读-修改-写模式的陷阱
这是嵌入式开发中最常见的隐式 Bug 来源:
c
// 想要只修改 GPIOA 的 pin 5
GPIOA->ODR |= (1 << 5); // 看似一条语句反汇编后是三条指令:
assembly
LDR R0, [R1, #ODR_OFFSET] ; 1. 读取当前 ODR 值(读)
ORR R0, R0, #0x20 ; 2. 修改 bit 5(修改)
STR R0, [R1, #ODR_OFFSET] ; 3. 写回 ODR(写)如果中断在 LDR 和 STR 之间执行了其他 ODR 操作,那个中断的修改会被这条 STR 覆盖!
这就是为什么位带操作(Bit Banding)被引入 Cortex-M3+:
c
// 位带操作:直接操作单个 bit,无需读-修改-写
// 地址 0x42000000 + (0x40020C14 - 0x40000000) * 32 + 5 * 4
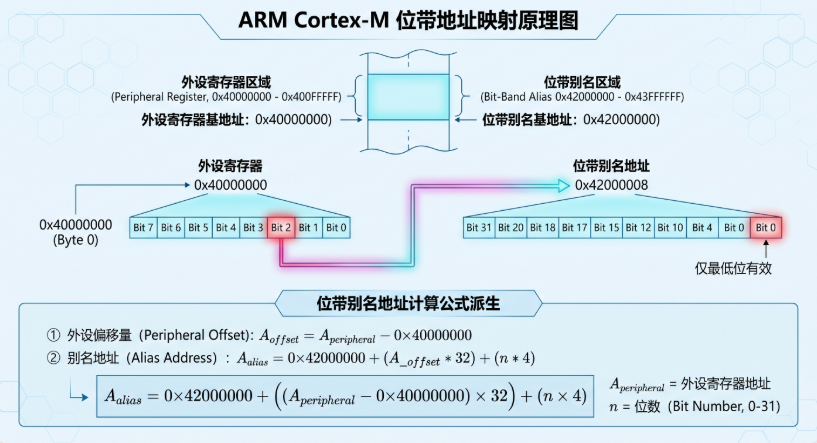
*(volatile uint32_t *)(0x420101A8) = 1; // 直接写 pin 5从物理层面理解 :位带区域将每个 bit「膨胀」为一个 32-bit 的别名地址。写别名地址时,硬件自动执行原子的读-修改-写。这不是软件技巧,是总线层面的硬件特性。
4.4 位带操作的本质
位带操作的公式:
别名地址 = 位带基地址 + (外设地址 - 外设基地址) * 32 + 位号 * 4展开来看:
(外设地址 - 外设基地址) * 32
→ 将字节偏移转换为 bit 偏移(* 8)
→ 再转换为别名地址偏移(* 4,因为每个 bit 映射到 4 字节)
→ 综合:* 8 * 4 = * 32物理意义:每个 SRAM/外设 bit 在别名区拥有一个专属的 32-bit 地址空间。
五、第一性原理 4:RTOS 任务切换 = 保存/恢复寄存器现场
5.1 任务 = 函数 + 栈 + 状态
这是 RTOS 最核心的洞察:
一个任务 = 一个永不返回的函数 + 一个独立的栈空间 + 一组寄存器状态(上下文)。
c
// 任务函数本质上就是:
void task_function(void *params) {
for (;;) { // 无限循环,永不返回
// 做任务的工作
}
// 千万不能 return!因为 return 会跳转到未知地址
}创建一个任务时,RTOS 做的事情非常具体:
- 分配栈空间 :
malloc(stack_size)或使用静态数组 - 初始化栈帧:在栈上伪造一个「刚被中断打劫的上下文」
- 设置入口点:把任务函数的地址填入栈帧中的 PC 位置
c
// FreeRTOS 创建任务的核心逻辑(极度简化)
typedef struct {
uint32_t r0, r1, r2, r3, r12;
uint32_t lr; // 返回地址
uint32_t pc; // 程序计数器→任务函数地址
uint32_t pspr; // 程序状态字
// ... 还有其他寄存器(R4-R11)
} context_frame_t;
TaskHandle_t xTaskCreate(TaskFunction_t task_func) {
// 1. 分配任务控制块
TCB_t *tcb = malloc(sizeof(TCB_t));
// 2. 分配栈
tcb->stack_base = malloc(STACK_SIZE);
// 3. 在栈顶构造「虚假的上下文」
context_frame_t *ctx = (context_frame_t *)
(tcb->stack_base + STACK_SIZE - sizeof(context_frame_t));
ctx->pc = (uint32_t)task_func; // 首次运行从这开始
ctx->lr = (uint32_t)task_exit; // 如果返回,跳到这里(会触发错误处理)
ctx->pspr = 0x01000000; // thumb 模式位必须置 1
// 4. 保存栈指针到 TCB
tcb->stack_ptr = ctx;
return tcb;
}这就是所有 RTOS 任务创建的本质。 FreeRTOS、uC/OS、RT-Thread 的实现可能略有不同,但核心思想完全一样:伪造上下文,让调度器看起来像是在切换不同任务。
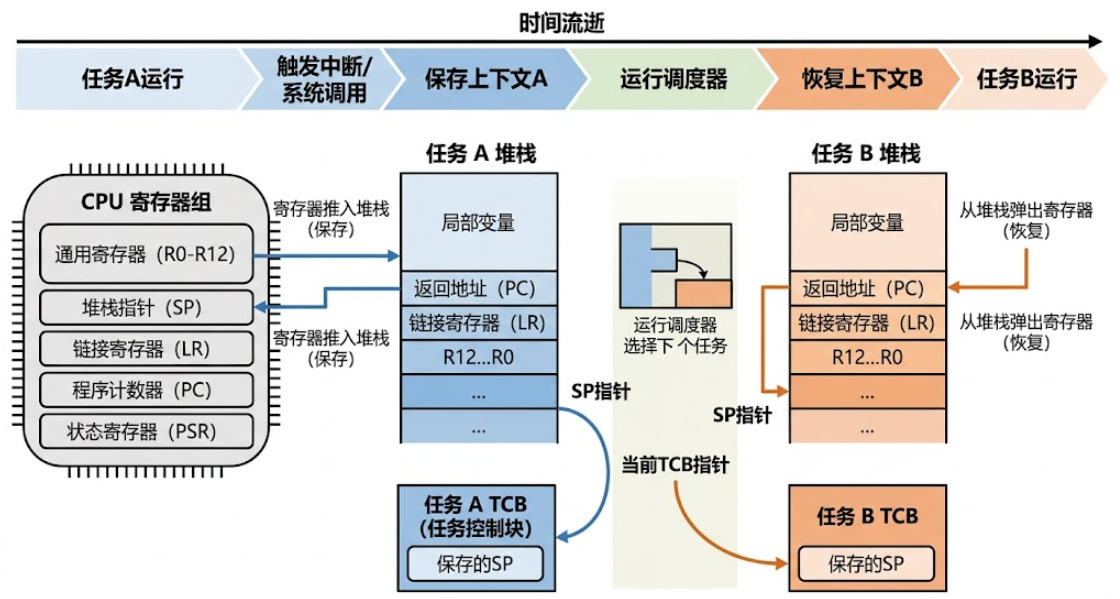
5.2 PendSV 异常的真正工作
PendSV 是 Cortex-M 专门为 RTOS 任务切换设计的异常机制。它的工作实际上非常简单:
c
// PendSV_Handler:RTOS 任务切换的核心
__attribute__((naked)) void PendSV_Handler(void) {
// === 保存当前任务的上下文 ===
__asm volatile(
"MRS R0, PSP \n" // 获取当前任务的栈指针
"STMDB R0!, {R4-R11} \n" // 保存 R4-R11 到栈上
"LDR R1, =currentTCB \n"
"LDR R1, [R1] \n"
"STR R0, [R1] \n" // 更新 TCB 中的栈指针
);
// === 选择下一个任务 ===
// (调用调度算法,选择优先级最高的就绪任务)
// === 恢复下一个任务的上下文 ===
__asm volatile(
"LDR R1, =currentTCB \n"
"LDR R1, [R1] \n"
"LDR R0, [R1] \n" // 获取新任务的栈指针
"LDMIA R0!, {R4-R11} \n" // 恢复 R4-R11
"MSR PSP, R0 \n" // 设置栈指针
"BX LR \n" // 异常返回(自动恢复 PC/R0-R3)
);
}翻译成你能理解的语言:
- 把当前任务的寄存器从 CPU 搬到栈上(保存现场)
- 把下一任务的寄存器从栈上搬到 CPU(恢复现场)
- 设置 PC = 下一任务上次被挂起时的指令地址
- 继续执行
这个过程只需要 ~20 条指令,耗时约 1-3 微秒 (在 72MHz STM32 上)。
5.3 从上下文切换理解栈溢出
现在你理解了任务切换的机制,栈溢出的后果就非常清晰了:
当任务 A 的栈溢出时,它会覆盖相邻的内存区域。如果相邻区域是任务 B 的 TCB 或栈......
┌─────────────────┐ ← 栈顶
│ │
│ 任务 A 的栈空间 │ ═════ 溢出 ═══▶ 写入相邻内存
│ │
├─────────────────┤ ← 栈界限(理论上的边界)
│ (被覆盖的区域) │ ← 任务 B 的 TCB!或全局变量!
├─────────────────┤
│ 任务 B 的栈空间 │
│ │
└─────────────────┘症状:任务 B 莫名其妙地崩溃,或全局变量被神秘修改,或调度器行为异常。
诊断 :查看任务的栈使用高水位线(uxTaskGetStackHighWaterMark()),如果接近 0,就是栈溢出。
根因 :任务 A 的栈空间不足以容纳最大调用深度 + 最大嵌套中断的压栈需求。
5.4 信号量/队列的物理本质
信号量、队列、事件组这些 RTOS 原语,从第一性原理看:
| RTOS 原语 | 物理本质 | 实现方式 |
|---|---|---|
| 信号量 | 一个整数 + 等待列表 | uint32_t count + List_t waiting_tasks |
| 互斥量 | 二值信号量 + 优先级继承 | count ∈ {0,1} + orig_prio |
| 队列 | 环形缓冲区 + 读写等待列表 | uint8_t[] buffer + List_t[2] |
| 事件组 | 位掩码 + 等待列表 | uint32_t bits + List_t waiting_tasks |
信号量的 P/V 操作(take/give):
c
// xSemaphoreTake 的物理本质
BaseType_t xSemaphoreTake(Semaphore_t *sem, TickType_t timeout) {
taskENTER_CRITICAL(); // 1. 关中断(保护临界区)
if (sem->count > 0) { // 2. 检查资源是否可用
sem->count--; // 3. 消耗一个资源
taskEXIT_CRITICAL();
return pdTRUE;
}
// 4. 资源不可用:把当前任务加入等待列表
list_add(&sem->waiting_tasks, current_task);
current_task->state = BLOCKED; // 5. 任务进入阻塞状态
taskEXIT_CRITICAL();
vTaskSwitchContext(); // 6. 触发调度------CPU 不会空转!
return pdTRUE; // 7. 被唤醒后从这里继续
}关键洞察 :当你调用 xSemaphoreTake 时,如果资源不可用,当前任务不会被调度 ,直到其他任务释放信号量。这就是「阻塞」的物理意义------你的任务函数被「暂停」了,CPU 去执行其他任务,而不是空转等待。
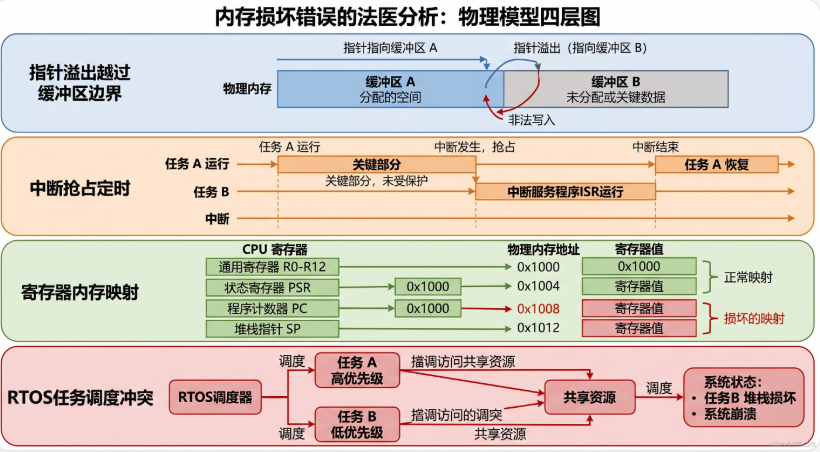
六、深度实战:用一个真实 Bug 串联四个原理
6.1 Bug 现场:神秘的内存踩踏
场景:STM32F407 驱动一个 OLED 显示屏(I2C)+ 通过 UART 接收命令 + 采集 ADC 数据。
现象 :OLED 显示偶尔出现乱码,UART 命令偶尔不响应。用调试器查看 OLED 缓冲区,发现某些字节被神秘修改成了 0xFF。
试图定位的过程(大部分人走的弯路):
- ✗ 怀疑 OLED 驱动 bug → 重写 I2C 时序 → 问题依旧
- ✗ 怀疑 DMA 冲突 → 关闭 DMA → 问题依旧
- ✗ 怀疑电源噪声 → 加电容 → 问题依旧
- ✗ 怀疑硬件问题 → 换芯片 → 问题依旧
已经过去 3 天了。
6.2 第一层分析:中断破坏了什么?
现在用第一性原理来分析。
问题:OLED 缓冲区中出现了不应该存在的 0xFF。
0xFF 的特殊性:
- 在二进制中是
11111111 0xFF是 UART 空闲线(IDLE)的标志值0xFF也是某些 I2C 时序中的 NACK 标志
怀疑: UART 中断是否在某个时刻无意中修改了 OLED 缓冲区?
查看代码:
c
// UART 中断服务程序
void USART1_IRQHandler(void) {
uint8_t byte = USART1->DR; // 读取接收到的字节
uart_rx_buffer[uart_rx_idx++] = byte;
// 问题:没有边界检查!
if (byte == 0x0A) { // 换行符 -> 命令结束
process_command(uart_rx_buffer); // ❌ 在中断中处理命令!
}
}uart_rx_buffer 和 oled_buffer 在内存中的位置?
查看链接脚本和 map 文件:
uart_rx_buffer = 0x20000100 (256 字节)
oled_buffer = 0x20000200 (1024 字节)看起来没有重叠。但 uart_rx_idx 从哪里开始?
6.3 第二层分析:指针指向了哪里?
继续追查------关键线索:
c
// 问题代码
#define UART_RX_BUF_SIZE 128
static uint8_t uart_rx_buffer[UART_RX_BUF_SIZE];
static volatile uint16_t uart_rx_idx = 0;
// 溢出条件:接收了 200+ 个字节uart_rx_idx 是 uint16_t,没有溢出检查。 当接收了第 128 个字节后:
uart_rx_buffer[128] = 写入的数据 // ❌ 越界!
uart_rx_buffer[129] = 写入的数据 // ❌ 越界!uart_rx_buffer[128] 在物理上对应什么地址?
c
// &uart_rx_buffer[0] = 0x20000100
// &uart_rx_buffer[128] = 0x20000100 + 128 = 0x20000180
// &uart_rx_buffer[200] = 0x20000100 + 200 = 0x200001C8检查内存布局:
0x20000100: uart_rx_buffer 开始
0x20000180: uart_rx_buffer[128](已经越界!)
0x200001C8: uart_rx_buffer[200](更严重)
...
0x20000200: oled_buffer 开始 ← 如果溢出到 256 字节以上,就覆盖到这里!真相浮出水面 :当 UART 连续接收超过 256 字节时,uart_rx_buffer 的越界写入覆盖了紧随其后的 oled_buffer 中的内容。
为什么是 0xFF?因为 UART 空闲时总线状态是高电平,即 0xFF。当 UART 中断持续触发读取 DR 寄存器时,读到的是 0xFF(如果没有新数据,DR 寄存器可能仍保持上次的 0xFF 值或者因为溢出错误而读出 0xFF)。
6.4 第三层分析:RTOS 调度加剧了什么?
项目用到了 FreeRTOS,UART 中断可以抢占任务级代码:
时间轴:
T0: OLED 任务开始更新 oled_buffer
T1: OLED 任务已写入 oled_buffer[0..50]
T2: UART 中断触发(因为接收到新字节)
T3: ISR 写入 uart_rx_buffer[255] = 0xFF → 这正好是 oled_buffer[0]!
T4: ISR 返回
T5: OLED 任务继续:oled_buffer[0] 已经被破坏!
T6: OLED 显示乱码这就是为什么 Bug 是「偶发」的:它取决于 UART 中断在 OLED 任务更新缓冲区的 精确时间点 触发。
6.5 修复方案与根因总结
修复很简单:
c
// ✅ 修复 1:边界检查 + 中断中只投递事件
void USART1_IRQHandler(void) {
uint8_t byte = USART1->DR;
if (uart_rx_idx < UART_RX_BUF_SIZE) {
uart_rx_buffer[uart_rx_idx++] = byte;
} else {
// 溢出错误,记录并重置
uart_rx_idx = 0;
error_flag = UART_OVF_ERROR;
}
// ✅ 不在中断中处理命令!只投递事件
if (byte == 0x0A) {
Event_t evt = { .type = EVT_UART_CMD_READY };
queue_post(&event_queue, &evt); // 投递到任务处理
}
}
c
// ✅ 修复 2:使用环形缓冲区(Ring Buffer)代替线性缓冲区
typedef struct {
uint8_t buffer[UART_RX_BUF_SIZE];
volatile uint16_t head; // 写入位置
volatile uint16_t tail; // 读取位置
} ring_buffer_t;
// 写入时自动绕回,永远不会越界
ring_buffer_t uart_rx_ring = {0};
bool ring_buffer_write(ring_buffer_t *rb, uint8_t byte) {
uint16_t next = (rb->head + 1) % UART_RX_BUF_SIZE;
if (next == rb->tail) {
return false; // 环形缓冲区满
}
rb->buffer[rb->head] = byte;
rb->head = next;
return true;
}根因总结:
| 原理 | 违反了什么 | 后果 |
|---|---|---|
| 指针 = 地址 | 没有检查指针/索引是否越界 | 写入相邻内存区域 |
| 中断 = 函数调用 | 在中断中做了复杂处理(命令解析) | ISR 执行时间过长 |
| 寄存器 = 全局变量 | 没有用 volatile 声明跨中断访问的变量 | 编译器优化导致读取到缓存值 |
| RTOS 调度 | 中断与任务共享缓冲区没有互斥 | 数据竞争导致偶发错误 |
一旦你掌握了这四个心智模型,这类 Bug 的排查时间可以从 3 天缩短到 30 分钟。
七、代码剖析:用第一性原理读懂反汇编
7.1 一个简单 C 语句的反汇编之旅
这一节展示如何把 C 代码「编译」成你脑子里的硬件执行序列。
C 源码:
c
uint32_t counter = 0;
void increment(void) {
counter++;
}ARM GCC -O0 反汇编:
assembly
increment:
LDR R2, =counter ; R2 = &counter(加载 counter 的地址)
LDR R3, [R2] ; R3 = counter(从内存加载值)
ADDS R3, R3, #1 ; R3 = R3 + 1
STR R3, [R2] ; counter = R3(存回内存)
BX LR ; 返回使用 -O2 优化后:
assembly
increment:
LDR R2, =counter
LDR R3, [R2]
ADDS R3, R3, #1
STR R3, [R2]
BX LR等等,看起来一样? 这是因为 counter 是全局变量,编译器不能确定它在函数调用之间不会被修改(比如被中断修改)。
7.2 volatile 的反汇编差异
如果 counter 被声明为 volatile:
c
volatile uint32_t counter = 0;
void loop_wait(void) {
while (counter != 0xFF) {
// 等待 counter 变成 0xFF
}
}有 volatile:
assembly
loop_wait:
LDR R2, =counter ; R2 = &counter
loop:
LDR R3, [R2] ; 每次都从内存重新加载
CMP R3, #255 ; counter == 0xFF?
BNE loop ; 不是则继续循环
BX LR ; 是则返回没有 volatile:
assembly
loop_wait:
LDR R2, =counter
LDR R3, [R2] ; 只加载一次!
loop:
CMP R3, #255 ; 用缓存的值比较
BNE loop ; 如果第一次不是 0xFF,永远跳不出去!
BX LR看,编译器第二次优化版本只加载了一次 counter 的值到 R3,之后的循环比较一直使用缓存在寄存器中的值。 如果硬件或中断修改了 counter,CPU 永远不会知道------它被困在无限循环里。
这就在你眼前展示了 volatile 的物理意义:关闭编译器对内存访问的「缓存优化」。
7.3 中断服务程序的反汇编解析
c
void TIM2_IRQHandler(void) {
if (TIM2->SR & TIM_SR_UIF) { // 检查更新中断标志
TIM2->SR = ~TIM_SR_UIF; // 清除标志
led_toggle(); // 翻转 LED
}
}反汇编:
assembly
TIM2_IRQHandler:
; 检查中断标志
LDR R0, =0x40000010 ; TIM2_SR 的地址
LDR R1, [R0] ; 读取 SR 寄存器
LDR R2, =0x0001 ; UIF 标志位掩码
TST R1, R2 ; 测试 UIF 位
BEQ .L_exit ; 没有标志,跳过
; 清除中断标志
MVNS R3, R2 ; R3 = ~0x0001 = 0xFFFFFFFE
STR R3, [R0] ; 写入 SR(清除 UIF)
; 调用 led_toggle
BL led_toggle ; 函数调用(注意,这会消耗栈空间)
.L_exit:
BX LR ; 中断返回关键观察:
TIM2->SR被编译为直接地址访问 --- 因为它是 volatile,每次访问都生成 LDR/STR- 清除标志操作
SR &= ~UIF被编译为三条指令(LDR/MVN/STR)--- 这不是原子操作 led_toggle()是一个函数调用 --- 会在栈上压入 LR 和可能被修改的寄存器
物理层面发生了什么:
进入 ISR:
↳ 硬件自动压栈: xPSR, PC(返回地址), LR(EXC_RETURN), R0-R3, R12
↳ CPU 跳转到 TIM2_IRQHandler
↳ 编译器生成的可选压栈: R4-R11(如果函数使用它们)
↳ 执行 ISR 代码
↳ 编译器生成的可选出栈: R4-R11
↳ 硬件自动出栈: 恢复 xPSR, PC, LR, R0-R3, R12
↳ CPU 恢复被中断的代码这个流程中任何一个环节的栈需求,都必须被任务栈或主栈容纳。 这就是为什么 RTOS 中每个任务需要有足够的栈空间------因为任务在任意位置都可能被打断进入 ISR。
八、避坑指南(The Gotchas)
8.1 坑 1:stm32f1 的 位带操作和 uCOS 冲突
症状:使能位带操作后,uCOS 任务切换偶尔失败。
根因 :位带别名区(0x42000000-0x43FFFFFF)和 uCOS 的任务栈区域重叠------某些链接脚本将堆放在了位带别名区域。位带别名地址不可用作普通内存,写入会导致意外的总线事务。
解法 :检查链接脚本,确保堆/栈区域不在位带别名区范围内。使用 __attribute__((section(".bss"))) 明确指定变量位置。
原理:位带别名区的写入操作会被总线矩阵翻译为对目标 bit 的读-修改-写序列。如果用于普通变量,这个额外的总线事务可能导致意外行为。
8.2 坑 2:在中断中使用 FreeRTOS API 但未使用 FromISR 版本
症状 :调用 xQueueSend 导致系统卡死或 HardFault。
根因 :xQueueSend 内部可能调用 portYIELD 触发 PendSV 切换任务,如果在中断中调用了非 FromISR 版本的 API,portYIELD 会尝试从非特权模式触发异常,导致 HardFault。
解法:
c
// ❌ 错误
void UART_IRQHandler(void) {
xQueueSend(queue, &data, 0); // 可能在 ISR 中触发 PendSV!
// ✅ 正确
BaseType_t must_yield = pdFALSE;
xQueueSendFromISR(queue, &data, &must_yield);
portYIELD_FROM_ISR(must_yield); // 按需触发 PendSV
}第一性原理解释 :xQueueSendFromISR 不会主动触发 PendSV,而是通过 must_yield 参数告诉调用者「是否需要切换」。这避免了在 ISR 中直接调用调度器------ISR 返回时硬件会自动检查是否需要上下文切换。
8.3 坑 3:结构体指针强制转换导致的对齐问题
症状:从 UART 接收缓冲区强制转换结构体指针时,偶尔读到错误数据或触发 HardFault。
c
// ❌ 危险!
uint8_t rx_buffer[64];
// ... UART 接收的数据填充 rx_buffer ...
MyStruct_t *msg = (MyStruct_t *)&rx_buffer[1]; // 未对齐!
uint32_t value = msg->field; // 如果 field 需要 4 字节对齐,这里会触发异常根因:ARM Cortex-M3+ 支持非对齐访问(需要设置 CCR.UNALIGN_TRP=0),但:
- 非对齐访问的性能损失很大(一次访问变成 2-3 次总线事务)
- 某些情况下(如 LDM/STM 指令)会产生 HardFault
解法:
c
// ✅ 安全做法:使用 memcpy
MyStruct_t msg;
memcpy(&msg, &rx_buffer[1], sizeof(MyStruct_t)); // 编译器会优化为合适的指令
// ✅ 或使用 packed 属性
typedef struct __attribute__((packed)) {
uint16_t id;
uint32_t value; // packed 情况下不需要对齐
} MyPackedStruct_t;第一性原理 :memcpy 会被编译器优化为面向字节的加载/存储指令(LDRB/STRB),这些指令不要求对齐。确保你的目标平台上非对齐访问行为可预测。
8.4 坑 4:全局变量在中断和主循环之间「消失」
症状 :在主循环中设置了一个全局标志位 data_ready = 1,中断中检查该标志但永远为 0。
但你已经加了 volatile!
问题可能出在编译器重排:
c
volatile bool data_ready = false;
uint8_t buffer[256];
void process_data(void) {
fill_buffer(buffer); // 1. 填充数据
data_ready = true; // 2. 置标志位
}
// 在中断中:
void TIM_IRQHandler(void) {
if (data_ready) { // 检查标志
use_buffer(buffer); // 使用数据
}
}问题 :编译器可能重排 fill_buffer 和 data_ready = true 的顺序。它认为两者无依赖关系。
解法:使用内存屏障(Memory Barrier):
c
void process_data(void) {
fill_buffer(buffer);
__DSB(); // 数据同步屏障
__DMB(); // 数据内存屏障
data_ready = true;
}或使用 C11 的原子操作:
c
#include <stdatomic.h>
atomic_bool data_ready = false;
// 自动包含内存屏障
atomic_store_explicit(&data_ready, true, memory_order_release);第一性原理 :编译器/处理器可以对无依赖关系的内存访问进行重排以优化性能。内存屏障的作用是告诉硬件/编译器:「在这条线之前的所有内存访问,必须在之后的所有内存访问之前完成。」
九、总结:心法与思维模式
9.1 核心心法
嵌入式系统的本质不是「在单片机上写 C 代码」。
嵌入式系统的本质是:用 C 代码来编排硬件寄存器的状态转移序列,让硬件按照我们的意愿工作。
当你理解了这一点,所有的高级概念都只是这个核心事实的语法糖:
| 高级概念 | 物理本质 |
|---|---|
| 变量 | 内存中某个地址处的若干字节 |
| 指针 | 存储了另一个地址的地址 |
| 数组 | 连续排列的相同类型的变量 |
| 函数调用 | 压栈 LR + 修改 PC + 执行代码 + 出栈恢复 PC |
| 中断 | 硬件触发的自动函数调用 |
| 外设寄存器 | 有副作用的 volatile 全局变量 |
| RTOS 任务 | 拥有独立栈的无限循环函数 |
| 信号量 | 一个整数 + 等待该整数的任务列表 |
| 队列 | 环形缓冲区 + 读写等待列表 |
| 看门狗 | 一个必须定期「续约」的硬件定时器 |
9.2 给嵌入式工程师的思维训练
如果我们想培养第一性原理的思维方式,每次遇到 Bug 时问自己四个问题:
- 指针:这个变量的地址在哪里?我是否超过了它的合法范围?有没有指针指向了不该指向的地方?
- 中断:哪些代码在中断上下文中执行?中断和主循环共享了什么资源?有没有不可重入的调用?
- 寄存器:这个外设寄存器是 volatile 的吗?读它会不会产生副作用?读-修改-写操作安全吗?
- RTOS:哪些变量在任务间共享?有没有锁保护?有没有可能导致优先级反转或死锁?
9.3 性能优化清单
- 将频繁访问的变量放在 SRAM 而非 Flash(使用
__attribute__((section(".ramfunc")))) - 使用位带操作代替读-修改-写(如果芯片支持)
- 使用 DMA 释放 CPU(大块数据传输时)
- 使用无锁队列(Lock-Free Queue)代替信号量保护(高频率数据路径)
- 启用指令缓存(ICache)和数据缓存(DCache)(如果芯片有)
- 使用 MPU 保护关键内存区域(安全关键系统)
参考资源:
- ARM Cortex-M3/M4 技术参考手册(TRM)
- 《ARM System Developer's Guide》- Andrew Sloss
- 《Computer Organization and Design》- Patterson & Hennessy
- FreeRTOS 官方源码(特别是
tasks.c和port.c) - C11 标准 §5.1.2.3(程序执行)关于 volatile 和副作用的定义