概念讲解
已经学习到前面的各种各样的顺序表有:单链表、栈、队等的单链表的了,其实对于树的概念我们还是一无所知,可能有些人会在想树的知识肯定与前面的内容还是有些联系但还是很难想象这么去这么去实现树这么庞大又复杂的这个东西,但其实如果已经深入了解过树的概念还是可以知道树其实并不困难。

图 1 现实世界的树
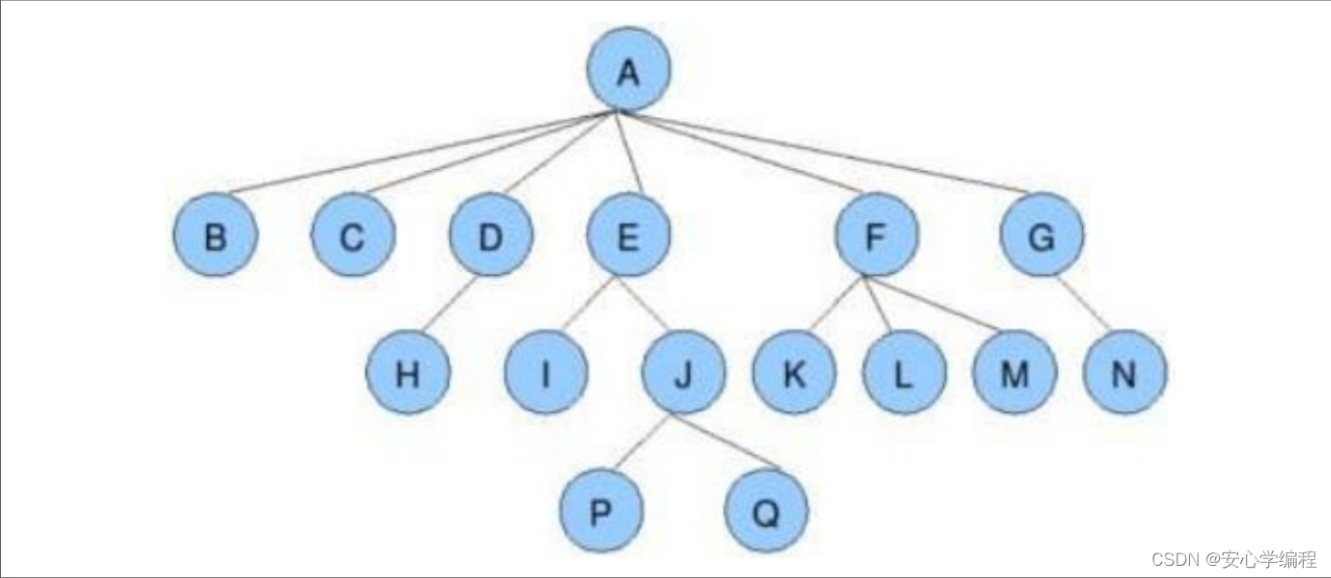
图 2 计算机理解的树
树的定义
树是一种非线性的数据结构,由节点(Node)和边(Edge)组成。每个节点包含数据,并通过边与其他节点相连。树具有层次结构,最顶层的节点称为根节点(Root),没有子节点的节点称为叶节点(Leaf)。
树的基本术语
- 根节点(Root):树的顶层节点,没有父节点。
- 父节点(Parent):一个节点的直接上层节点。
- 子节点(Child):一个节点的直接下层节点。
- 叶节点(Leaf):没有子节点的节点。
- 子树(Subtree):树中任意节点及其后代构成的树。
- 深度(Depth):从根节点到当前节点的路径长度。
- 高度(Height):从当前节点到最远叶节点的路径长度。
(比较抽象不要介意)
非二叉树的计算机内的宏观图片
可以看到树的的基本原理还是以顺序表的结构存储数据的,通过两个指针和一个整形存取的内容。但是这种数据的存取还是太复杂了,所有又提出看二叉树的概念。
二叉树的定义
所谓的二叉树就是每一个节点只分出两个节点,这就是二叉树。
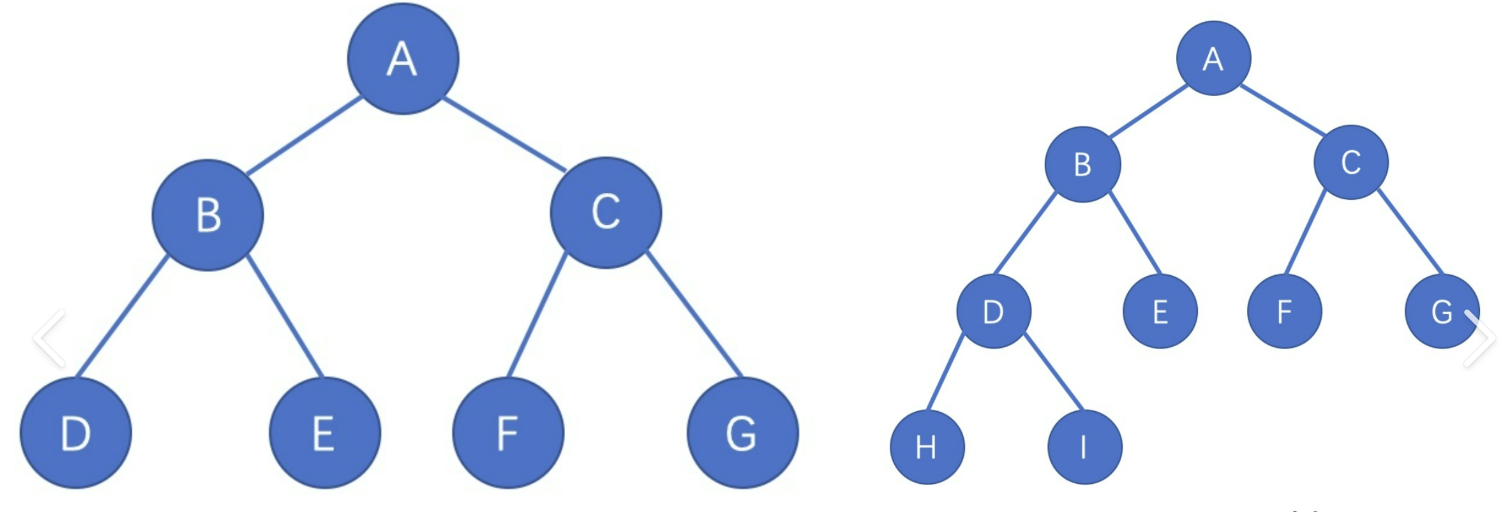
而二叉树又分出满叉树和完全二叉树。
满叉树,就是上图左边这种,底层没有一个衍生出其他的节点,就是满叉树;
完全二叉树,就是像上图左边的这种,底层没有完全占满,但是依次从左顺过去没有出现断断续续的就是满叉树。可能比较抽象画个图就知道了。
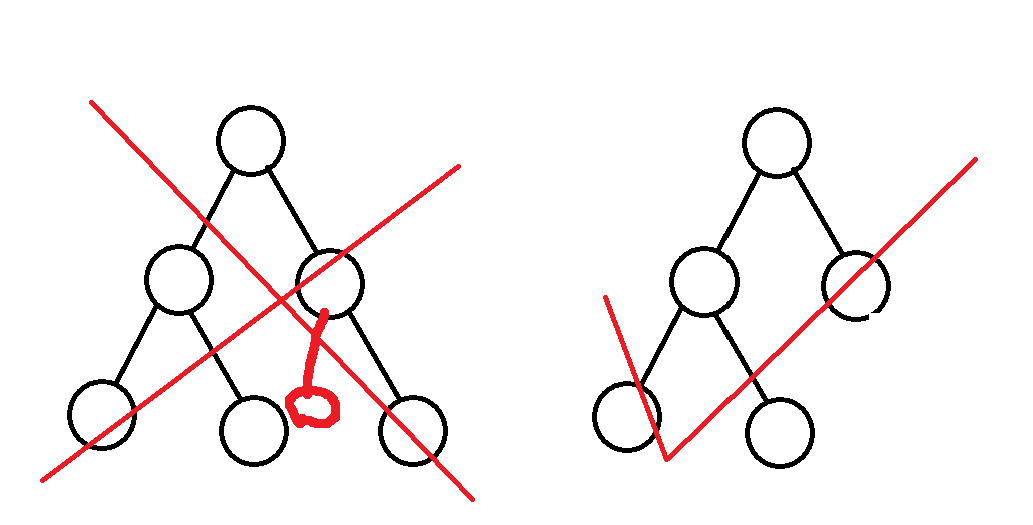
完全二叉树与普通二叉树比较
而在二叉树的定义内人们又引出堆的概念。
堆的定义
堆的基于二叉树的定义,顶层逻辑是一个数组累成的二叉树的数组。
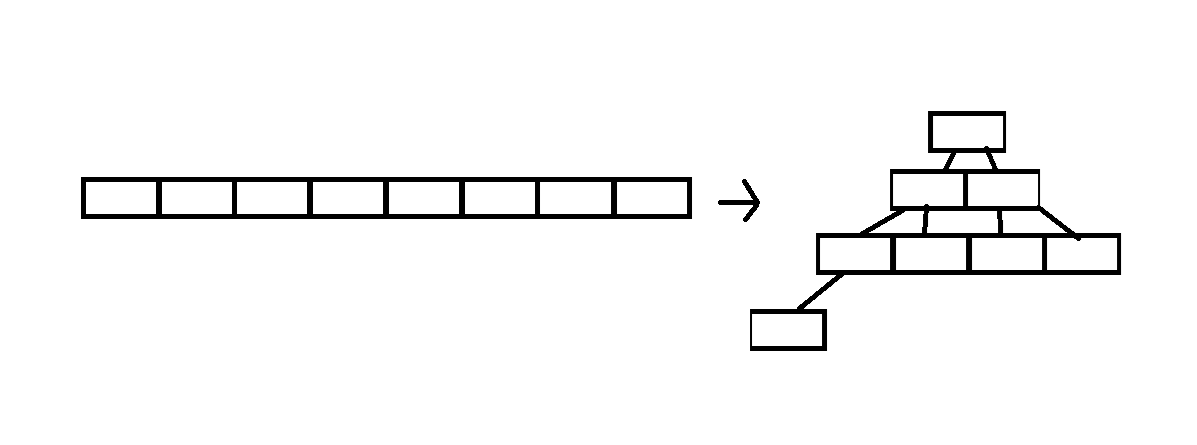
堆里不是随便存取数值就可以,不然与普通的数组没有区别
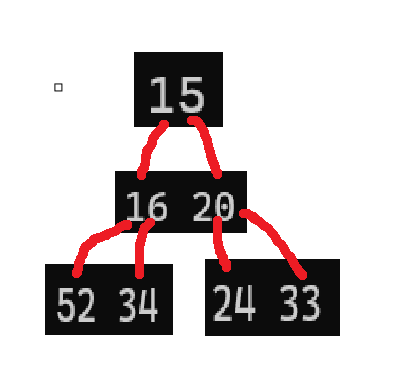
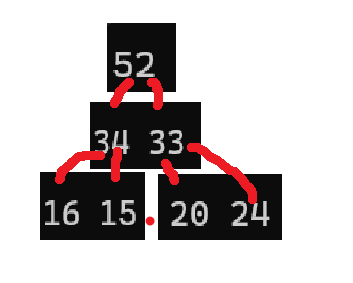
堆顶一定要比两个分支出来的小或者大,而堆顶最是所有的最小就是小堆而相反最大就是大堆。
堆的模拟实现
基本代码
堆的结构:
cpp
typedef int DateType;
typedef struct heap
{
DateType* arr;
int size;
int capacity;
}HP;初始化和销毁函数:
cpp
void HPInit(HP* heap)//初始化
{
heap->arr = NULL;
heap->capacity = heap->size = 0;
return;
}
void HPdeatory(HP* heap)//销毁
{
free(heap->arr);
heap->arr = NULL;
heap->capacity = heap->size = 0;
return;
}输出打印函数:
cpp
void print(HP* hph)
{
assert(hph);
for (int i = 0; i < hph->size; i++)
{
printf("%d ", hph->arr[i]);
}
printf("\n");
return;
}实现代码
修整函数(swap (交换)函数 、向下调整和向上调整):
cpp
//修正堆函数 要利用到递归的
//修整类型函数
void swap(DateType* arr1, DateType* arr2)
{
DateType tmp = *arr1;
*arr1 = *arr2;
*arr2 = tmp;
return;
}
void AdjustDown(DateType* arr, int n, int i)//上下调整
{
int largest = i;//i==parent
int left = 2 * i + 1;
if (left < n && arr[left] > arr[largest])
largest = left;
if (left + 1 < n && arr[left + 1] > arr[largest])
largest++;
if (largest != i) {
int tmp = arr[i];
arr[i] = arr[largest];
arr[largest] = tmp;
AdjustDown(arr, n, largest);//递归
}
}
void AdjustTop(DateType* arr, int head, int i)//又下到上调整
{
//head 头是越往上走,节点越小
int child = i;
int parent = (i - 1) / 2;
//这里只管父子关系无需管兄弟关系
if (head < child && arr[parent] < arr[child])// < 大堆 > 小堆
{
swap(&arr[parent], &arr[child]);
AdjustTop(arr, head, parent);
}
}因为要符合堆的概念需要每一个写入的内容符合堆的概念就需要向上调整和向下调整的函数。函数原理当调用数组通过比较的时候就通过swap 就行交换操作,因为进行交换上面或者下面的内容以及不符和内容要求就需要进行再一次调整所有就用函数递归的进行循环,如果已经符合条件或者已经走到头或者尾就停止函数递归的操作。
尾插函数:
cpp
void HPpush(HP* heap, DateType a)//入堆尾入
{
assert(heap);
//扩容
if (heap->size == heap->capacity)
{
heap->capacity = heap->capacity == 0 ? 4 : heap->capacity * 2;
DateType* news = realloc(heap->arr, sizeof(DateType) * heap->capacity);
if (news == NULL)
{
perror("realloc");
return;
}
heap->arr = news;
}
//入堆
heap->arr[heap->size] = a;
heap->size++;
AdjustTop(heap->arr, 0, heap->size - 1);
}原理: 判断要不要扩容 -> 写尾部内容,size++ -> 调整(从下往上调整)
cpp
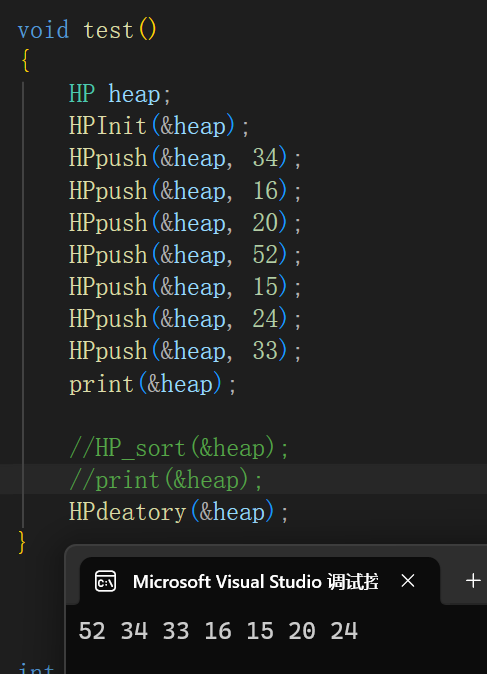
void test()
{
HP heap;
HPInit(&heap);
HPpush(&heap, 34);
HPpush(&heap, 16);
HPpush(&heap, 20);
HPpush(&heap, 52);
HPpush(&heap, 15);
HPpush(&heap, 24);
HPpush(&heap, 33);
print(&heap);
HPdeatory(&heap);
}
头删函数:
cpp
void HPPop(HP* heap)//头删除
{
assert(heap);
swap(&heap->arr[0], &heap->arr[heap->size - 1]);
heap->size--;
AdjustDown(heap->arr, heap->size, 0);
return;
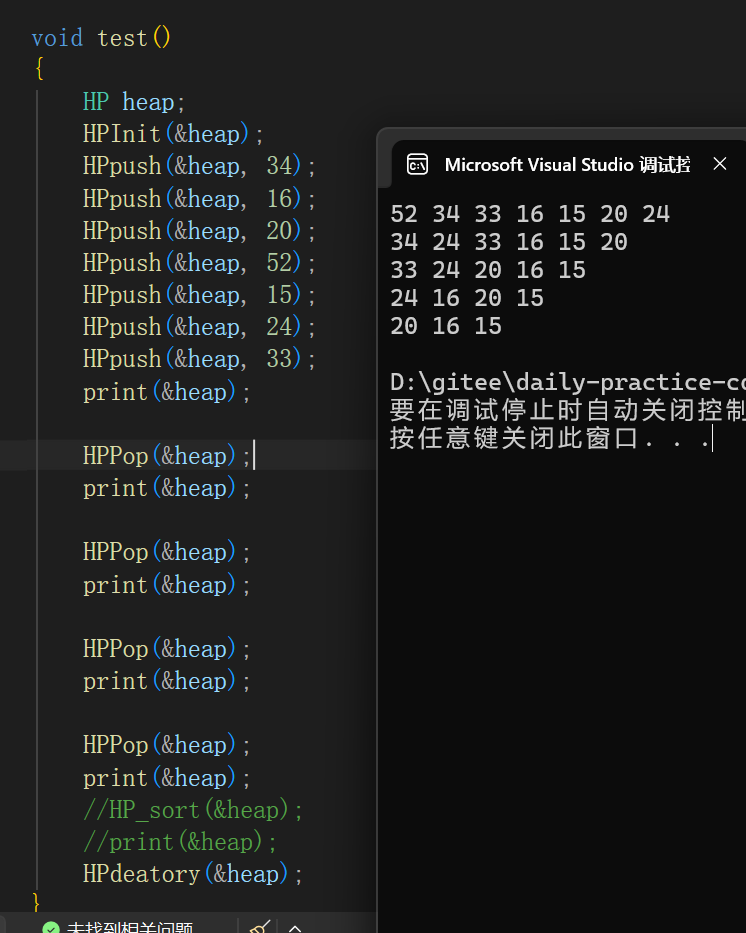
}原理:尾堆和顶堆进行交换,size-- -> 调整(从上往下调整)
cpp
void test()
{
HP heap;
HPInit(&heap);
HPpush(&heap, 34);
HPpush(&heap, 16);
HPpush(&heap, 20);
HPpush(&heap, 52);
HPpush(&heap, 15);
HPpush(&heap, 24);
HPpush(&heap, 33);
print(&heap);
HPPop(&heap);
print(&heap);
HPPop(&heap);
print(&heap);
HPPop(&heap);
print(&heap);
HPPop(&heap);
print(&heap);
//HP_sort(&heap);
//print(&heap);
HPdeatory(&heap);
}
拓展代码
排序函数
cpp
void HP_sort(HP* heap)//大堆就是升序,小堆就是降序
{
for (int i = heap->size - 1; i > 0; i--)
{
swap(&heap->arr[0], &heap->arr[i]);
AdjustDown(heap->arr, i, 0);
}
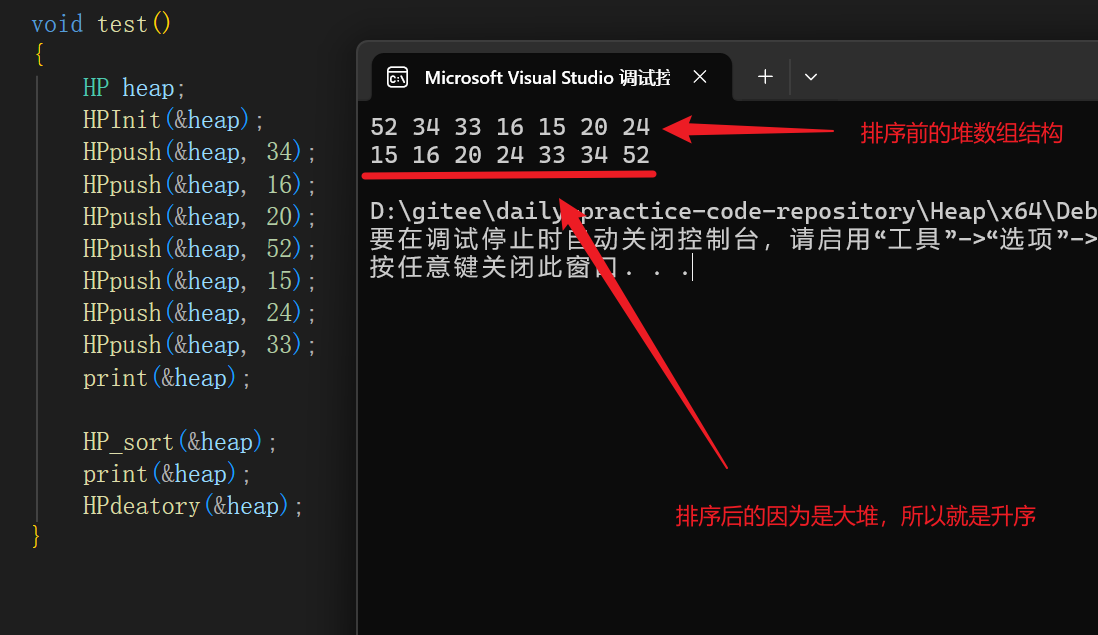
}函数原理:通过提取顶堆与调整到尾堆位置,尾堆进行调整(从上往下调整),循环,最后呈现的数组成一个有序排序,大堆就是就是升序,小堆就是降序。
cpp
void test()
{
HP heap;
HPInit(&heap);
HPpush(&heap, 34);
HPpush(&heap, 16);
HPpush(&heap, 20);
HPpush(&heap, 52);
HPpush(&heap, 15);
HPpush(&heap, 24);
HPpush(&heap, 33);
print(&heap);
HP_sort(&heap);
print(&heap);
HPdeatory(&heap);
}