前言
说个真实经历。
刚学 ZooKeeper 的时候,我就用单机版跑实验。./zkServer.sh start 敲下去,客户端连上 localhost:2181,看起来一切正常,心里还挺有成就感。直到有一次测试环境断电重启,ZooKeeper 服务跟着恢复了,结果发现之前创建的节点数据全丢了------临时节点(ephemeral)没了,顺序节点(sequential)的计数器也重置了。那一刻才反应过来:单机 ZooKeeper 根本不是真正的 ZooKeeper,它只是一个玩具。
后来接手一个 Kafka 集群维护的工作,才真正体会到 ZooKeeper 集群的价值。Kafka 依赖 ZooKeeper 做 Controller 选举、分区分配、配置管理------这些操作要求 ZooKeeper 必须是强一致的,单机版根本撑不住。一旦某个节点挂了,集群能在几秒内自动选主恢复,服务不中断,数据不丢失。这才是 ZooKeeper 该有的样子。
搭集群的过程不算复杂,但有几个地方确实容易踩坑:
一是 myid 文件。三台机器分别对应 myid 为 1、2、3,这个文件必须放在 dataDir 指定的目录下,内容就是纯数字,少了它集群永远选不出 Leader。二是 zoo.cfg 里的 server 列表。格式是 server.N=IP:2888:3888,前面是 IP,后面两个端口分别是通信端口和选举端口,三台机器都要写全,不能只写自己。三是 防火墙。2181、2888、3888 这几个端口必须放开,不然节点之间互相找不到,集群起不来。
搭好之后用 ./zkServer.sh status 看一下,能看到当前节点是 Leader 还是 Follower,这才算真正跑起来了。

1.前提条件
准备三台虚拟机,并列出对应的IP地址和主机名,如下图所示
| IP | Hostname |
|---|---|
| 192.168.42.140 | zookeeper1 |
| 192.168.42.145 | zookeeper2 |
| 192.168.42.146 | zookeeper3 |
在虚拟机分别对hostname进行命名:
shell
hostnamectl set-hostname zookeeper1 //修改hostname
hostname //查看hostname


2.环境准备(3虚拟机都要做)
关闭防火墙:
shell
systemctl stop firewalld //停止firewalld防火墙
systemctl disable firewalld //disable防火墙,使其开机不自启
systemctl status firewalld //查看firewalld是否已经关闭 配置操作系统(SELINUX修改成disabled):
配置操作系统(SELINUX修改成disabled):
shell
vi /etc/sysconfig/selinux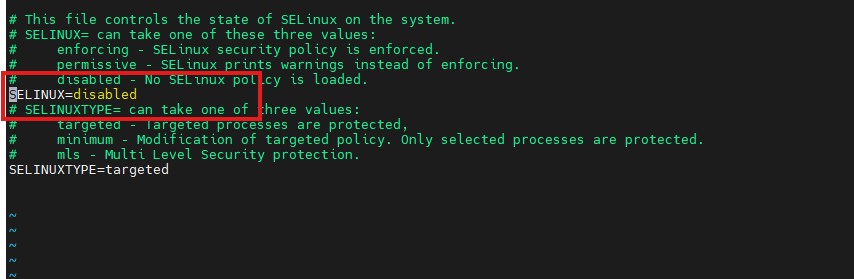
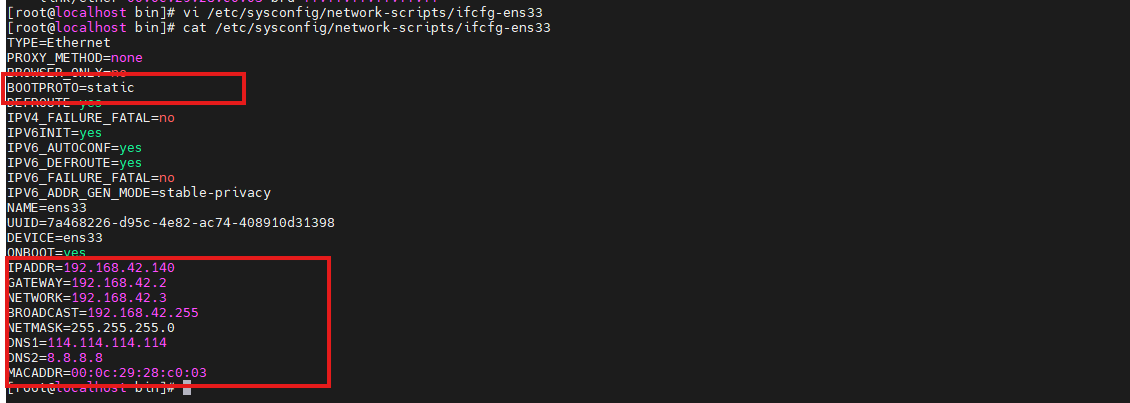
设置本机IP地址与MAC地址:
shell
vi /etc/sysconfig/network-scripts/ifcfg-ens33- BOOTPROTO的值修改成static
- 文末加上对应的IP地址与MAC地址等数据
- MAC 地址查看方法:ip link show ens33
添加主机名与映射关系:
shell
192.168.42.140 zookeeper1
192.168.42.145 zookeeper2
192.168.42.146 zookeeper3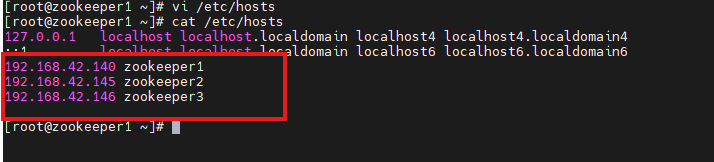
3.安装zookeeper(三台虚拟机都要操作)
3.1环境准备
- jvm环境
- JDK 必须是7或以上版本
shell
java -version
3.2.下载安装
去zookeeper 官网下载完后,将压缩包上传到linux环境中,我这边上传到/shan路径:

对压缩包进行解压:
shell
tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz
重命名:
shell
mv apache-zookeeper-3.7.1-bin/ zookeeper
3.3 配置
进入zookeeper目录下的conf目录,将目录中的zoo_sample.cfg改成zoo.cfg:
shell
mv zoo_sample.cfg zoo.cfg
在zookeeper目录下新建一个zkData文件夹
shell
mkdir zkData
回到zoo.cfg中,对其进行修改,将dataDir的路径换成我们刚刚新建的zkData的路径
shell
vim zoo.cfg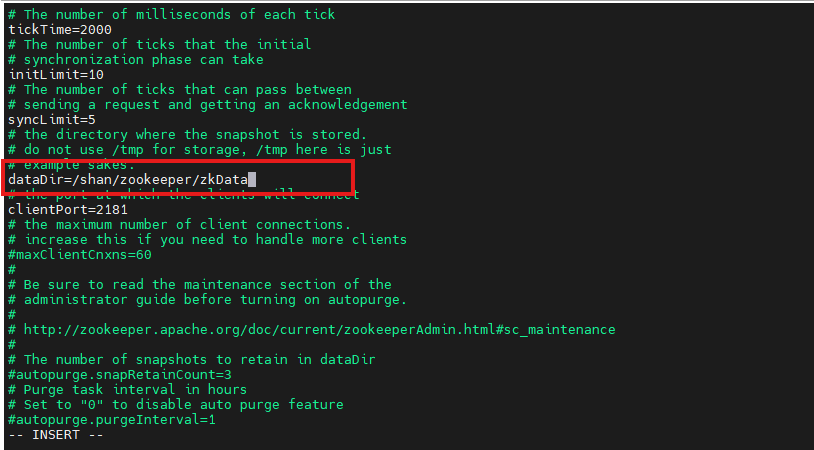
3.3.启动测试
进入bin目录下,启动服务端:
shell
./zkServer.sh start
jps查看进程:
shell
jps
回到zookeeper目录下,启动客户端:
shell
bin/zkCli.sh
3.4.退出
shell
quit
3.5关闭客户端
shell
./zkServer.sh stop4.配置zookeeper集群
添加环境变量:
shell
export ZK_HOME=/shan/zookeeper
export PATH=$PATH:$ZK_HOME/bin对zookeeper/conf 中的zoo.cfg修改 :
shell
server.1=192.168.42.140:2888:3888
server.2=192.168.42.145:2888:3888
server.3=192.168.42.146:2888:3888

进入zkData中,修改myid文件:
shell
vi myid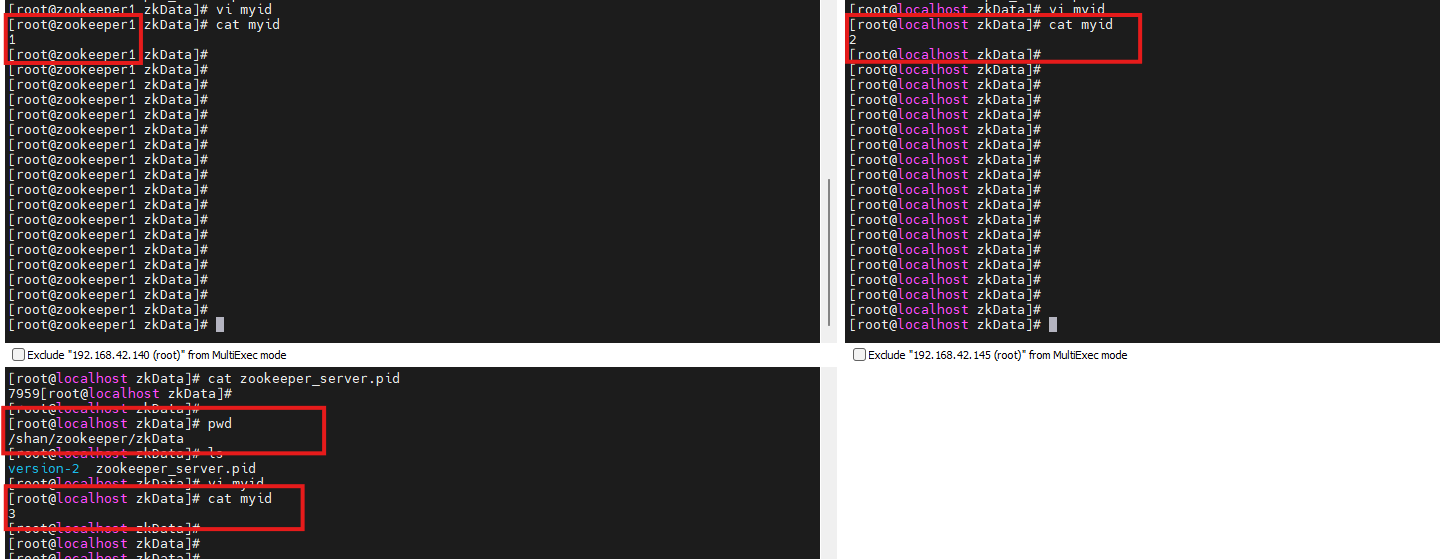
5.zookeeper集群测试
启动各个服务器的zookeeper:
shell
./zkServer.sh start 启动成功的被选举为zookeeper3被选举为leader而zookeeper2和zookeeper1成为了follower:
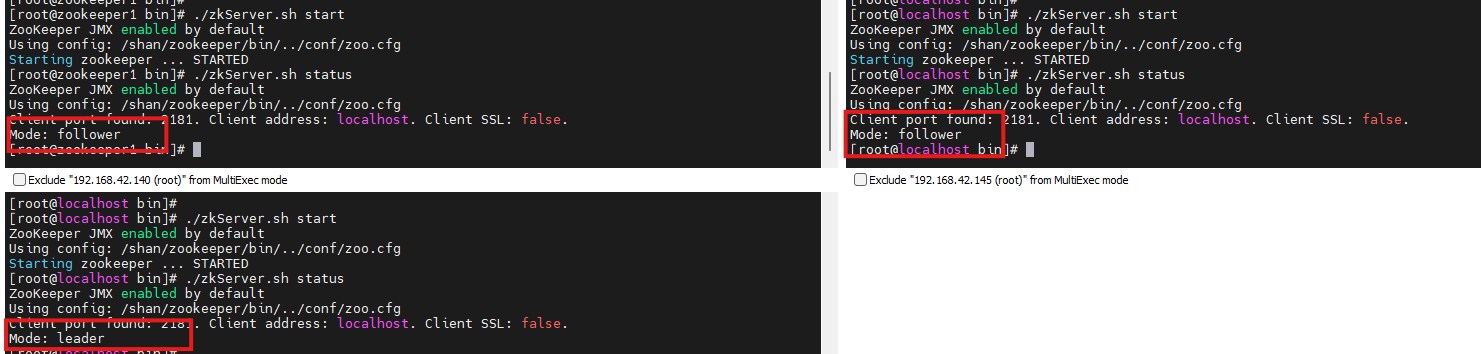
至此,zookeeper集群搭建成功啦~
6.zookeeper简单使用
登录到节点:
shell
./zkCli.sh -server 127.0.0.1:2181使用help来查看zookeeper客户端命令:
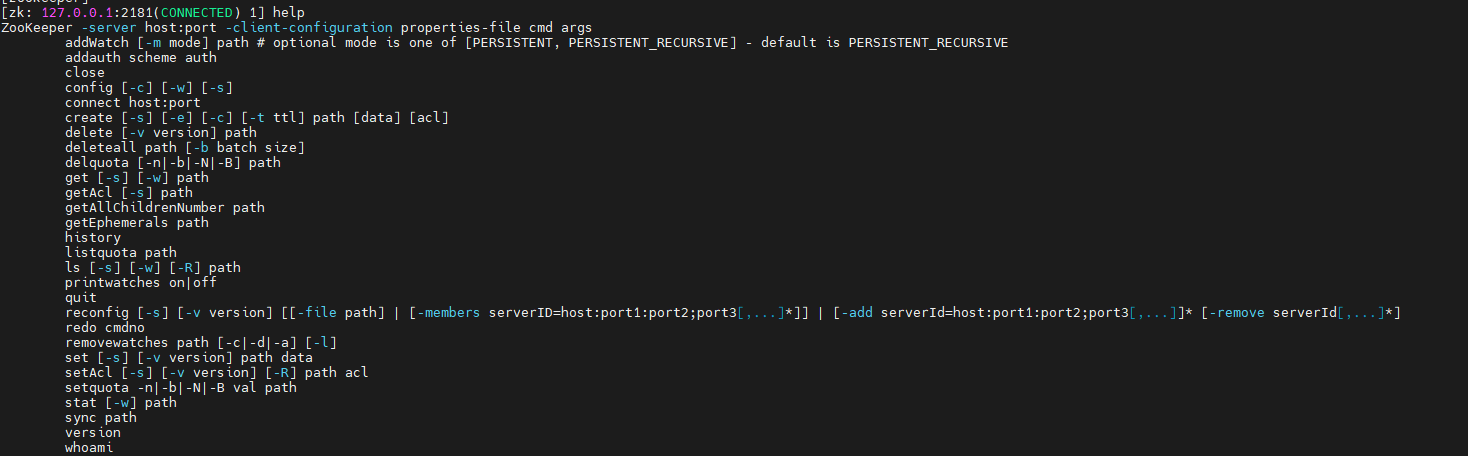
ls watch : 查看zookeeper节点,默认情况下只存在一个zookeeper节点:

- -s:顺序节点,顺序是累加的,由 zookeeper 提供
- -e:临时节点,服务器断开,然后重新连接服务器之后该节点会消失
shell
ls /
ls /zookeeper
create -e /znode01 001
create -e -s /znode02 002
create /znode03 003
create -s /znode04 004
ls /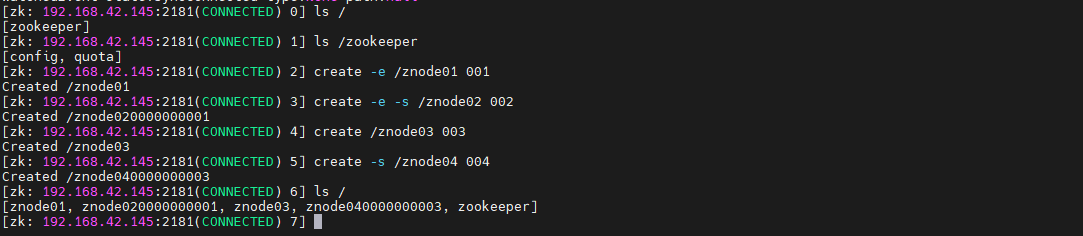
断开 zookeeper 后台服务之后,再次连接,可以看到根节点下的临时节点 znode01、znode02 已经消失了,但是由于 znode03、znode04 是持久节点,所以还继续存在:

查看节点值:
shell
get /znode03
获取节点的状态体:
shell
stat /znode03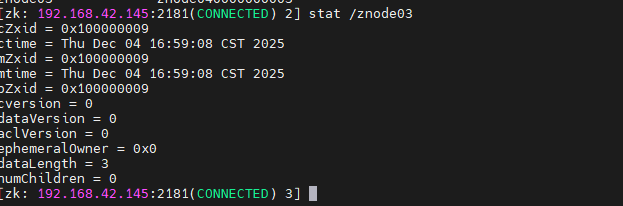
修改节点值:
shell
set /znode03 10086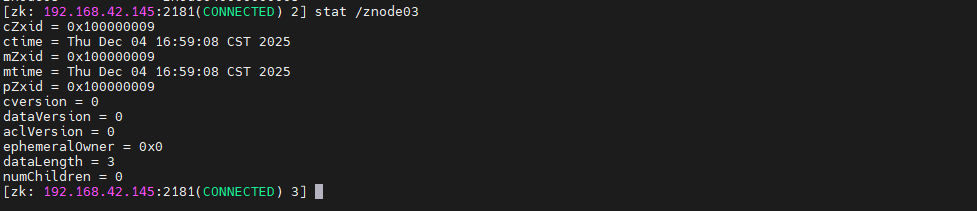
删除节点,zookeeper中有两种删除的方式:
- delete version:类似于 Linux 中删除某一个文件
- rmr path:类似于递归删除文件夹

leader创建了一个文件,follower也会创建:
leader:

follower:


在现实开发或测试场景中,你本地虚拟机里运行的ZooKeeper服务地址是 192.168.42.145:2181,但该 IP 仅限内网访问,外部设备(比如你的手机、公司电脑,或云服务器)无法直接连接。这时,你可以借助 Cpolar 实现内网穿透:只需在 ZooKeeper所在机器上执行 cpolar,Cpolar 就会为你分配一个公网地址。之后,无论你在世界哪个角落,都可以像这样连接:
shell
./zkCli.sh -server 3.tcp.cpolar.io:12345跟我一起来安装cpolar吧!
7.安装cpolar内网穿透工具
cpolar 可以将你本地电脑中的服务(如 SSH、Web、数据库)映射到公网。即使你在家里或外出时,也可以通过公网地址连接回本地运行的开发环境。
❤️以下是安装cpolar步骤:
使用一键脚本安装命令:
shell
sudo curl https://get.cpolar.sh | sh
安装完成后,执行下方命令查看cpolar服务状态:(如图所示即为正常启动)
shell
sudo systemctl status cpolar
Cpolar安装和成功启动服务后,在浏览器上输入虚拟机主机IP加9200端口即:【ip:9200】访问Cpolar管理界面,使用Cpolar官网注册的账号登录,登录后即可看到cpolar web 配置界面,接下来在web 界面配置即可:
打开浏览器访问本地9200端口,使用cpolar账户密码登录即可,登录后即可对隧道进行管理。
8.配置公网地址
通过配置,你可以在本地 WSL 或 Linux 系统上运行 SSH 服务,并通过 Cpolar 将其映射到公网,从而实现从任意设备远程连接开发环境的目的。
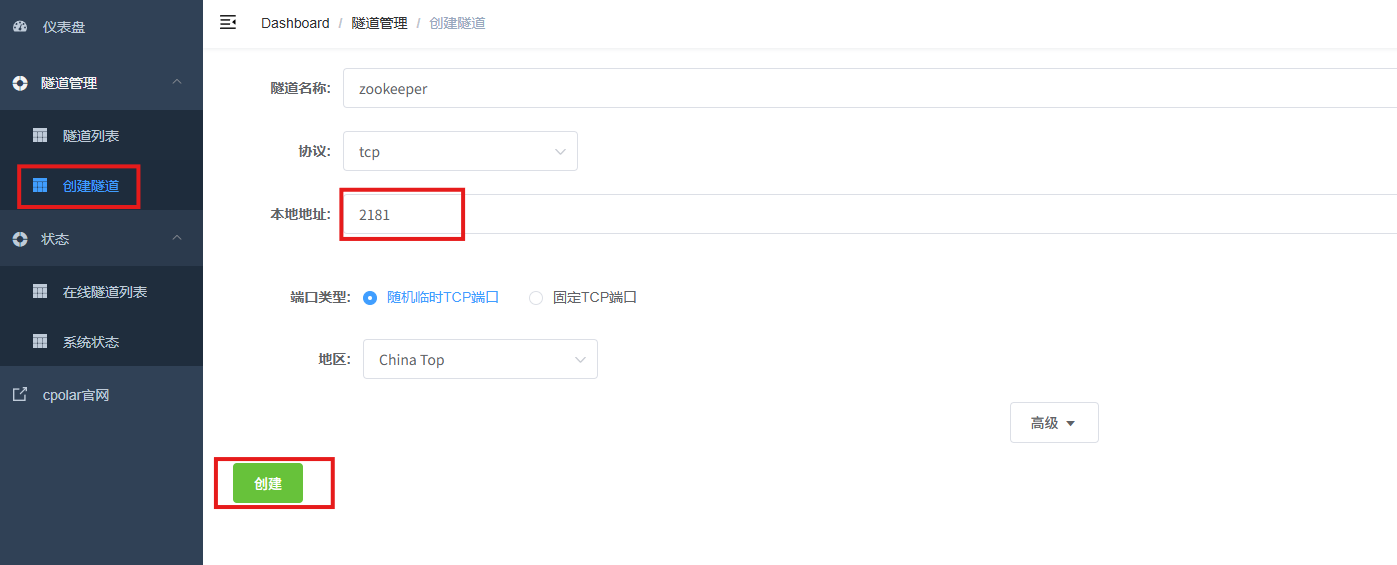
- 隧道名称:可自定义,本例使用了:zookeeper,注意不要与已有的隧道名称重复
- 协议:tcp
- 本地地址:
- 端口类型:随机临时TCP端口
- 地区:China Top
创建成功后,打开左侧在线隧道列表,可以看到刚刚通过创建隧道生成了公网地址,接下来就可以在其他电脑或者移动端设备(异地)上,使用任意一个地址在终端中访问即可。
-
tcp 表示使用的协议类型
-
2.tcp.cpolar.top是 Cpolar 提供的域名
-
10518是随机分配的公网端口号
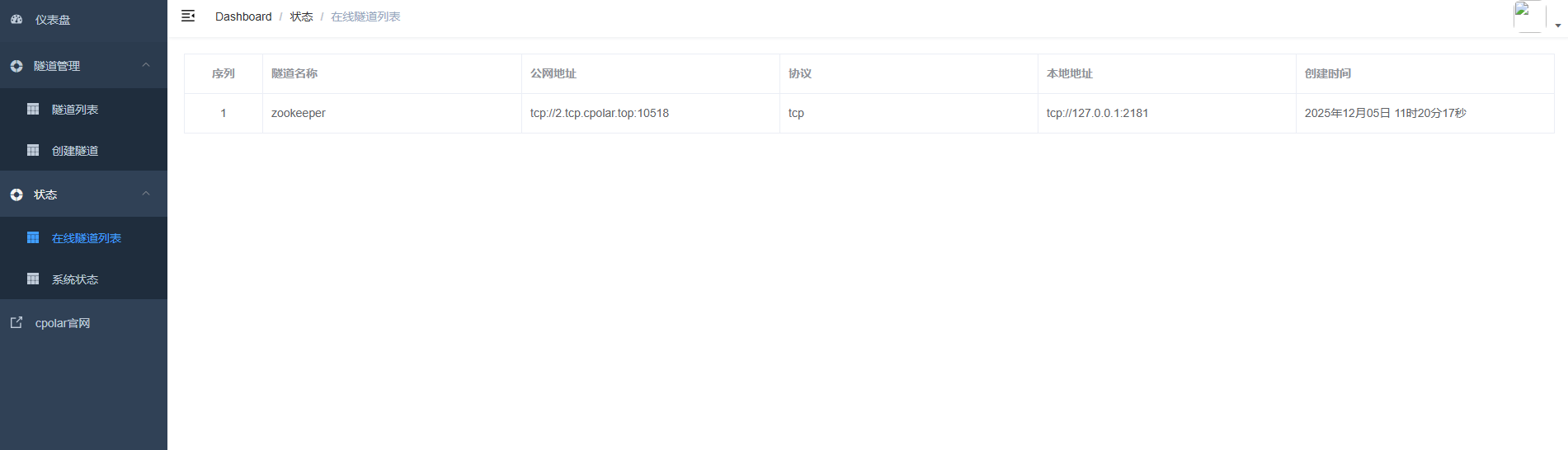
通过Cpolar提供的公网地址和端口,ZooKeeper就可以在公网访问啦
shell
./zkCli.sh -server 2.tcp.cpolar.top:10518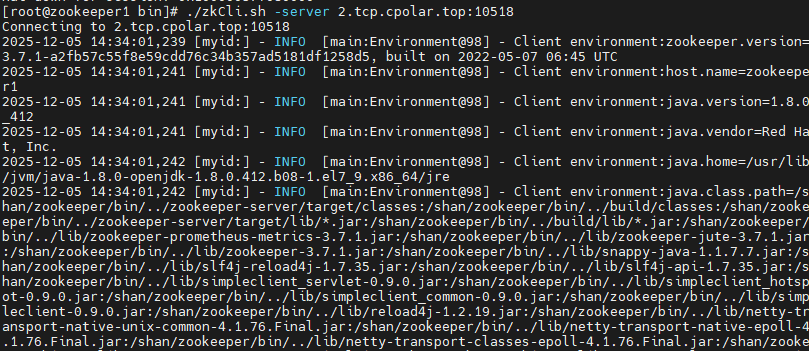

9.保留固定TCP公网地址
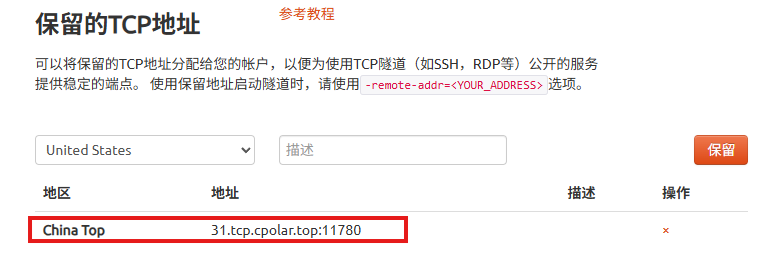
使用cpolar为其配置TCP地址,该地址为固定地址,不会随机变化。

选择区域和描述:有一个下拉菜单,当前选择的是"China Top"。
右侧输入框,用于填写描述信息。
保留按钮:在右侧有一个橙色的"保留"按钮,点击该按钮可以保留所选的TCP地址。
列表中显示了一条已保留的TCP地址记录。
-
地区:显示为"China Top"。
-
地址:显示为"31.tcp.cpolar.top:11780"。
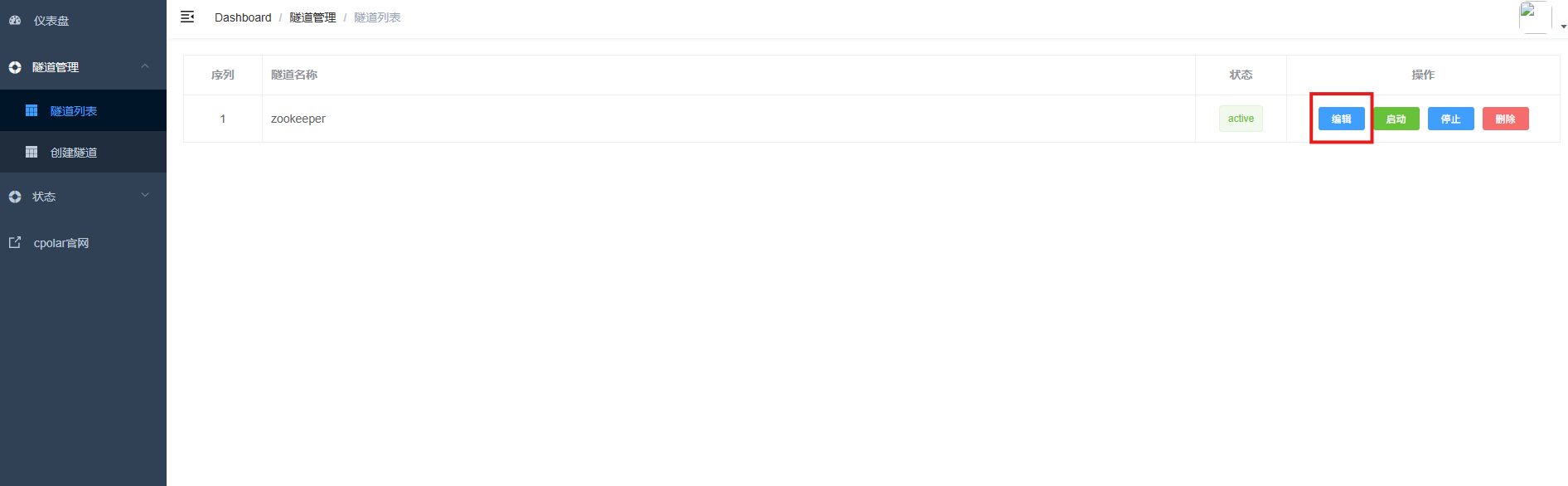
登录cpolar web UI管理界面,点击左侧仪表盘的隧道管理------隧道列表,找到所要配置的隧道zookeeper,点击右侧的编辑。
修改隧道信息,将保留成功的TCP端口配置到隧道中。
- 端口类型:选择固定TCP端口
- 预留的TCP地址:填写保留成功的TCP地址
点击更新。
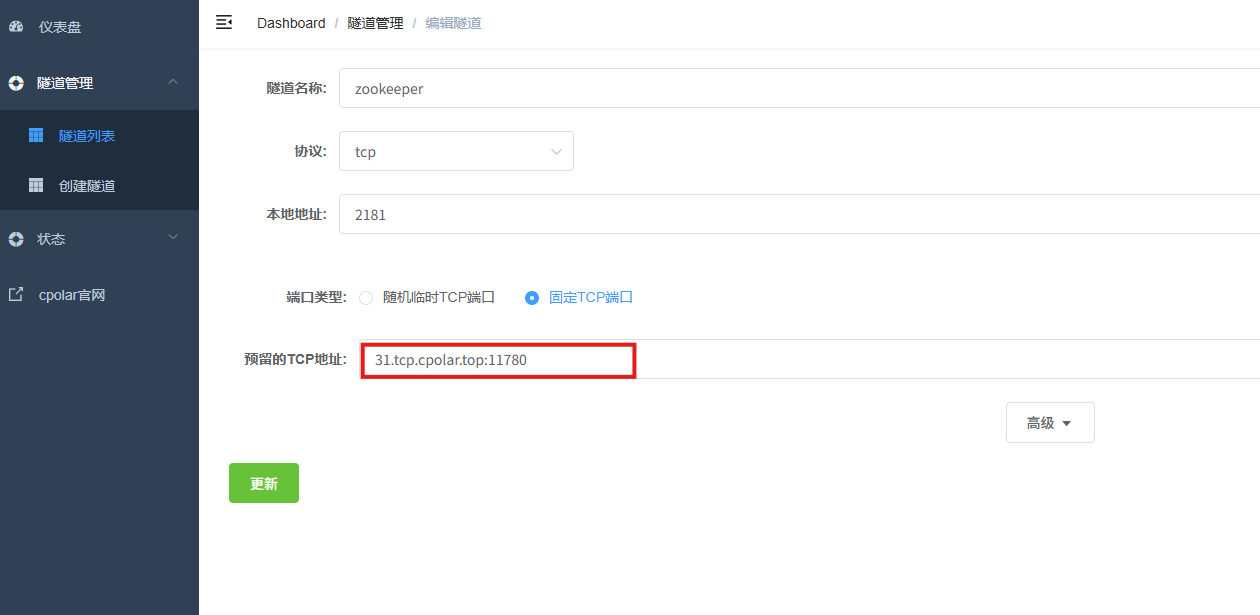
创建完成后,打开在线隧道列表,此时可以看到随机的公网地址已经发生变化,地址名称也变成了保留和固定的TCP地址。
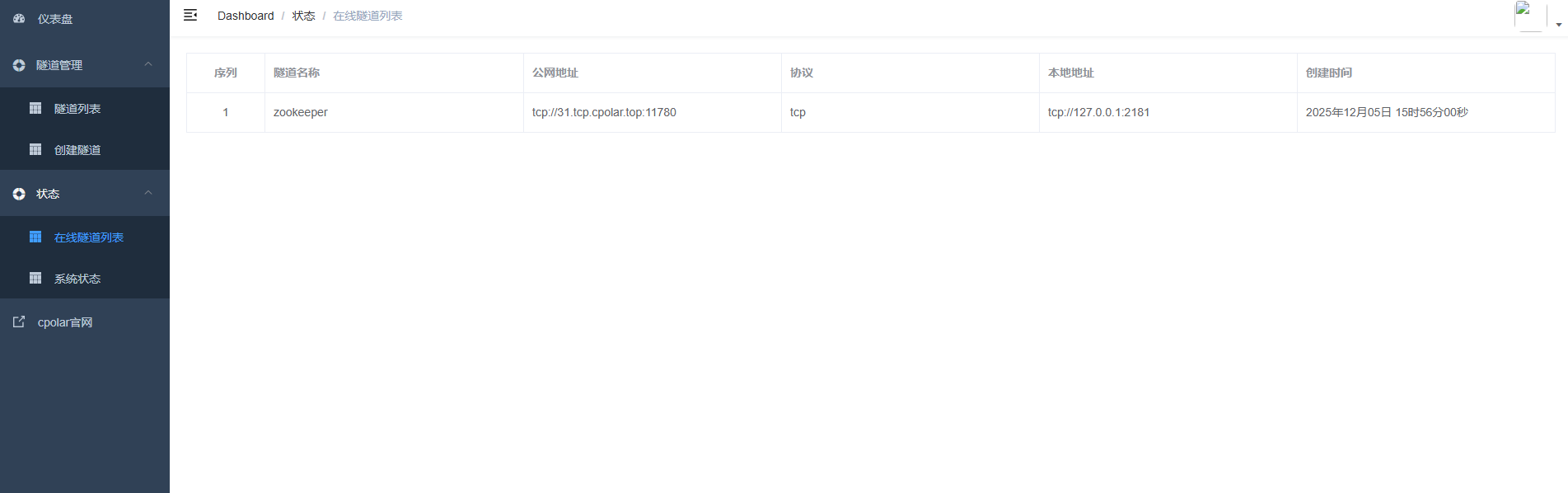
最后测试一下固定的地址是否好用,测试命令:
shell
./zkCli.sh -server 31.tcp.cpolar.top:11780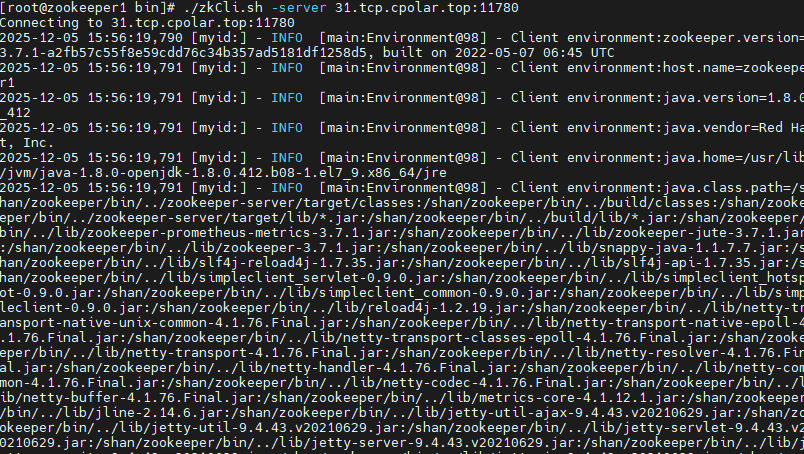

总结
回头看,单机 ZooKeeper 的最大问题不是不能用,而是它掩盖了你对 ZooKeeper 的理解------你会以为它就是这么运作的,但实际上它的容错、自动选主、数据同步能力全靠集群模式。如果你的生产环境要跑 Kafka、HBase、Dubbo 这些依赖 ZooKeeper 的组件,老老实实搭三节点集群是基本功,没得商量。
踩过的坑才是自己的经验。