Claude Code 上下文工程架构:源码级深度解析
基于
@anthropic-ai/claude-code@2.1.88还原源码,结合四层上下文压缩机制与项目实际架构,从源码视角拆解 AI 如何连续聊几百轮也不混乱。
一、为什么 AI 聊久了会"失忆"?
现象与真相
- 现象:聊着聊着,AI 突然忘了刚才改的哪行代码。
- 误区:这不是模型太笨。
- 真相:是它的上下文窗口被撑爆了。所有发给模型的 messages、system prompt、tool results 都占用 token,当总量接近模型上下文窗口上限(如 200k),模型就无法正常工作。
Claude Code 的应对策略
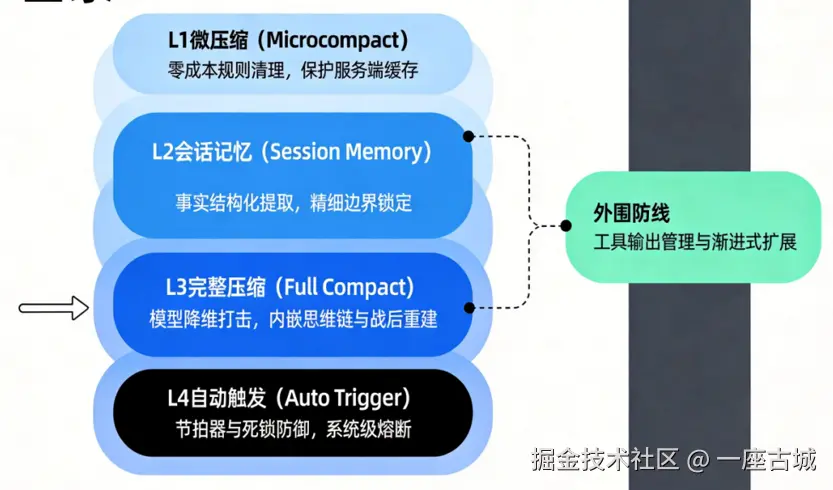
这不是单点功能,而是一个 分 4 层的防御系统,层层往下兜底:
| 层级 | 名称 | 成本 | 核心机制 |
|---|---|---|---|
| L1 | 微压缩 (Microcompact) | 零成本(纯规则) | 删除过时工具输出 |
| L2 | 会话记忆 (Session Memory) | 低成本(fork agent) | 提炼结构化事实到 MEMORY.md |
| L3 | 完整压缩 (Full Compact) | 高成本(调用模型) | 模型降维打击 + 思维链剥离 |
| L4 | 自动触发 (Auto Trigger) | 调度系统 | 节拍器 + 熔断器 |
二、上下文三层架构:构建发给 AI 的 Prompt
在讨论"压缩"之前,先看上下文是怎么构建的。系统通过三个核心函数构建上下文,在 QueryEngine.ts 中通过 Promise.all() 并行获取:
2.1 SystemPrompt(系统提示词)
- 文件 :
prompts.ts---getSystemPrompt() - 内容:30+ 工具的 schema 定义、MCP 服务器指令、输出风格配置、技能工具命令、语气和风格指令
2.2 UserContext(用户上下文)
- 文件 :
context.ts---getUserContext() - 内容:CLAUDE.md 文件内容(项目级 AI 指令)、当前日期
- 优化 :通过
memoize()缓存,对话期间不变
2.3 SystemContext(系统上下文)
- 文件 :
context.ts---getSystemContext() - 内容:Git 状态(分支、提交、工作区状态)、缓存破坏器
注入机制
在 api.ts 中:
typescript
// SystemContext 追加到系统提示词末尾
appendSystemPrompt(systemPrompt, systemContext)
// UserContext 作为第一条用户消息前置(标记为 isMeta)
prependUserContext(messages, userContext)三、Token 是核心资源:5 种计算方式
在 tokens.ts 中,系统提供了 5 种不同的 token 计算方式,服务于不同场景:
| 函数 | 用途 | 包含缓存 token |
|---|---|---|
getTokenCountFromUsage() |
单次 API 调用完整上下文 | 是 |
finalContextTokensFromLastResponse() |
跨压缩边界的 task_budget 计算 | 否 |
messageTokenCountFromLastAPIResponse() |
Claude 单次响应生成量 | 否(仅 output) |
tokenCountWithEstimation() |
测量上下文大小的权威函数 | 视情况 |
roughTokenCountEstimationForMessages() |
无 API 数据时的 fallback | 估算 |
权威函数:tokenCountWithEstimation()
这是自动压缩阈值检查的权威函数。关键设计:
- 使用最后一次 API 响应的 实际 token 计数(来自 API usage)
- 对之后的消息使用 估算(避免重复计算)
- 正确处理并行工具调用的 interleaved 消息
css
消息流: [..., assistant(id=A), user(result), assistant(id=A), user(result)]
↑ 这里只估算1个 ↑ 但实际有2个
解决方案:回退到第一个相同 message.id 的节点上下文窗口配置
在 utils/context.ts 中:
typescript
const MODEL_CONTEXT_WINDOW_DEFAULT = 200_000 // 所有模型统一 200k
const COMPACT_MAX_OUTPUT_TOKENS = 20_000 // 压缩摘要最大输出
const MAX_OUTPUT_TOKENS_DEFAULT = 32_000 // 默认最大输出
const CAPPED_DEFAULT_MAX_TOKENS = 8_000 // capped 默认值四、L1 微压缩:零成本的规则清理
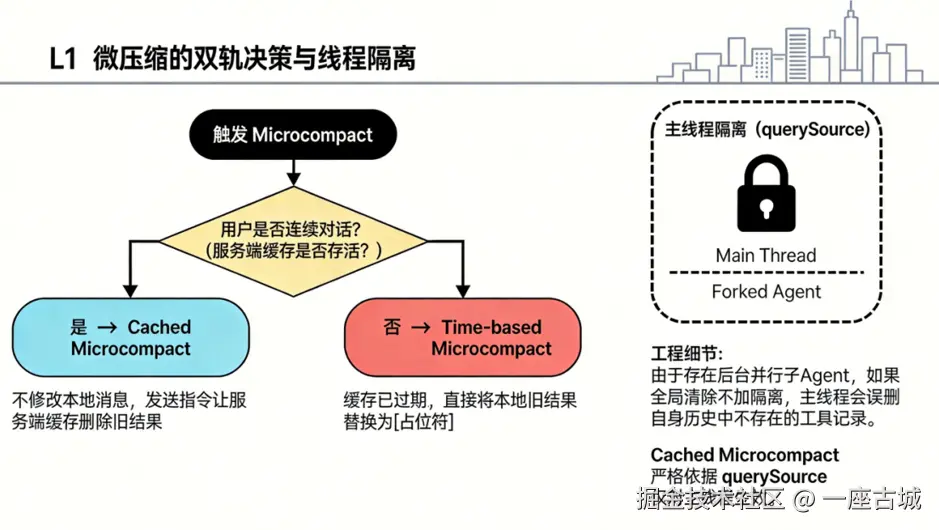
核心逻辑
纯规则驱动,不调用大模型(零花费)。保留最近 N 个白名单工具结果,删除过时的大体积时效性输出(如 Read、Bash、Grep 等工具的历史结果)。
终极挑战:缓存保护
切token,在哪切,怎么切,绝对不能破坏服务端已缓存的 Prompt 前缀。如果缓存活着,必须通过 API 精细编辑,只删旧结果,不动 Prompt 前缀。
双轨决策机制
| 模式 | 触发条件 | 操作方式 |
|---|---|---|
| Cached Microcompact | 用户连续对话,缓存存活 | API 精细编辑,只删旧结果 |
| Time-based Microcompact | 缓存过期或超时 | 本地替换,长输出 → 简短占位符 |
线程隔离 (QuerySource)
主线程 (Main Thread) 与 Forked Agent (子Agent) 隔离。防止子 Agent 误删主线程不存在的工具记录,导致上下文逻辑乱套。
五、L2 会话记忆:提炼事实,而非简单摘要
核心思路
绝对不要给历史记录做简单的摘要 (会丢失细节)。而是将杂乱的聊天记录提炼成 结构化的事实。
机制:The Memory Elevator
后台悄悄派一个 Forked Agent,将对话提炼为结构化文件:
markdown
# MEMORY.md (自动生成的位置: .claude/memory.md)
如:
- project
- TypeScript、Vue、React框架
- progress
- DB Migration 80%
- preference
- camelCase 命名规范等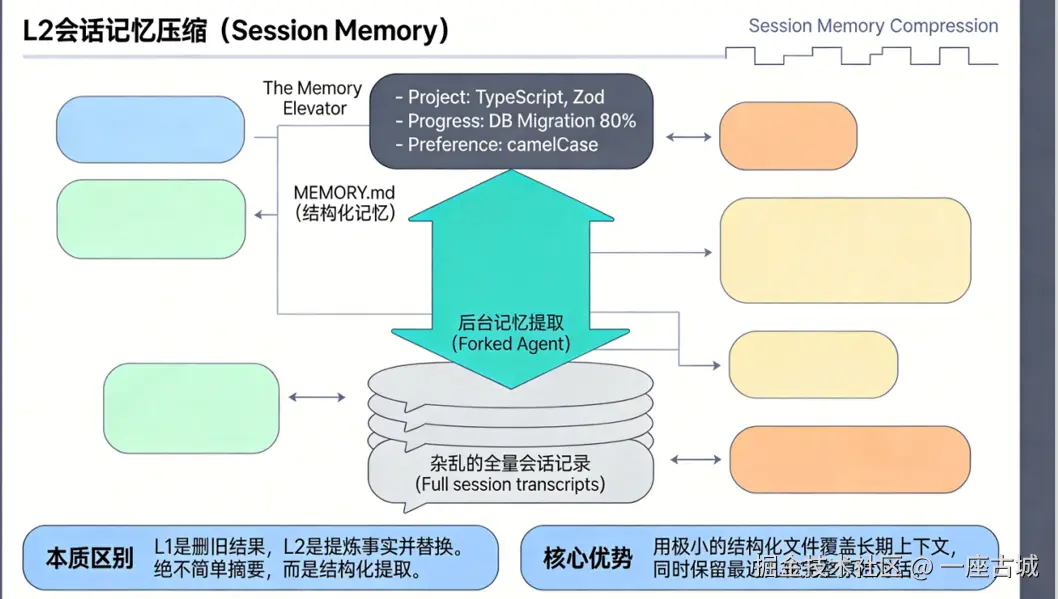
源码位置
- 文件 :
sessionMemory.ts(495 行) - 触发方式 :
- 阈值触发(上下文达到一定大小时自动触发)
- 手动触发(
/summary命令)
- 执行方式:隔离的 forked agent 执行提取,不影响主对话
优势
用极小的结构化文件覆盖长期上下文,同时保留最近几轮完整原始对话。
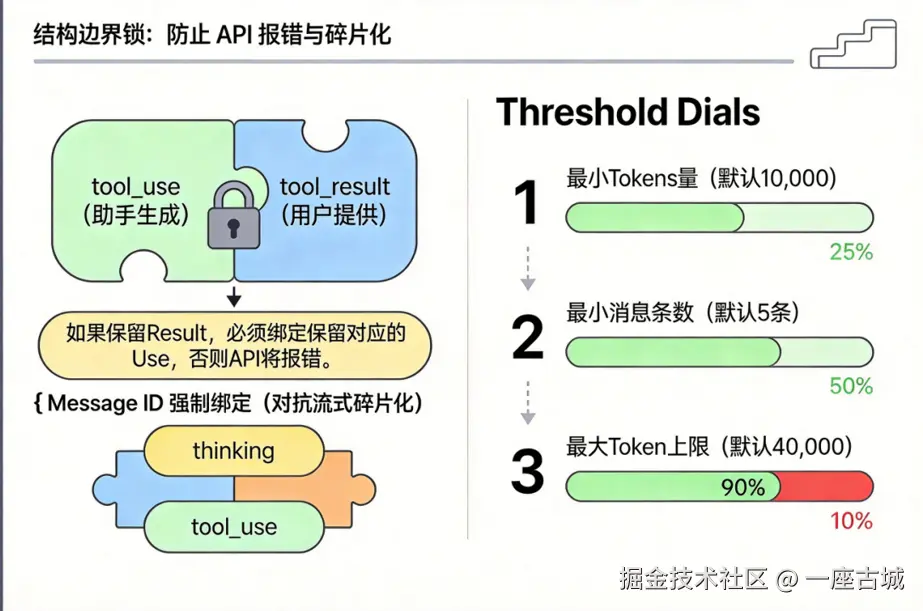
六、结构边界锁:防止 API 报错与碎片化
在压缩过程中,系统设置了多重"结构边界锁"来防止 API 层面的错误:
阈值拨盘 (Threshold Dials)
| 参数 | 默认值 | 作用 |
|---|---|---|
| 最小 Tokens 量 | 10,000 | 太小的对话不压缩 |
| 最小消息条数 | 5 条 | 至少需要足够的对话轮次 |
| 最大 Token 上限 | 40,000 | 超过此值强制压缩 |
Tool 绑定锁
如果保留 Tool Result,必须绑定保留对应的 Tool Use,否则 API 会报错。消息结构必须完整配对。
Message ID 绑定
强制绑定 <thinking> 和 tool_use,防止流式输出碎片化导致思考过程被切断。
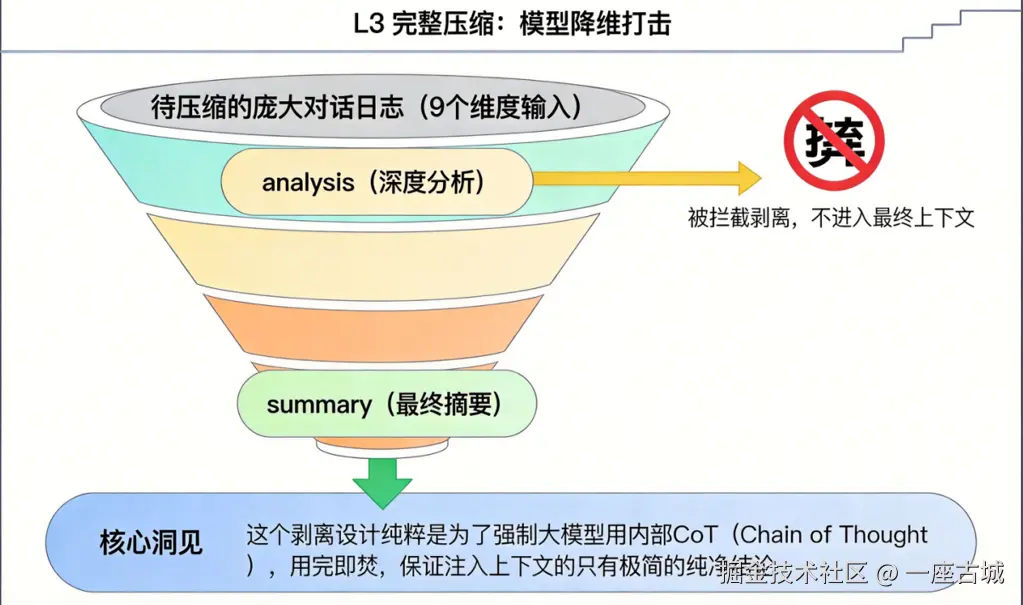
七、L3 完整压缩:模型降维打击
核心流程
在 compact.ts(1705 行)中实现完整的压缩流程:
markdown
1. 记录压缩前 token 数: tokenCountWithEstimation(messages)
2. 执行 PreCompact hooks
3. 调用 AI 生成摘要: streamCompactSummary()
├── 输入: 庞大对话日志(9个维度)
│ 源码位置: prompt.ts --- BASE_COMPACT_PROMPT (第61-143行)
│ | # | 维度 | 内容 |
│ |---|------|------|
│ | 1 | Primary Request and Intent | 用户的所有显式请求和意图 |
│ | 2 | Key Technical Concepts | 讨论的技术概念、技术栈、框架 |
│ | 3 | Files and Code Sections | 查看/修改/创建的文件及代码片段,含变更说明 |
│ | 4 | Errors and fixes | 遇到的错误及修复方式,特别是用户反馈的修正 |
│ | 5 | Problem Solving | 已解决的问题和正在进行的排查 |
│ | 6 | All user messages | 所有非工具结果的用户消息(用于理解意图变化) |
│ | 7 | Pending Tasks | 被明确要求处理的待办任务 |
│ | 8 | Current Work | 摘要请求前正在进行的工作的精确描述(含文件名和代码) |
│ | 9 | Optional Next Step | 下一步行动,需与用户最近的明确请求直接对齐,含原文引用 |
├── 强制模型进行 <analysis>(深度分析)
└── 输出: <summary>(最终摘要)
4. 创建压缩边界标记: createCompactBoundaryMessage()
5. 构建压缩后消息: buildPostCompactMessages()
6. 执行 PostCompact hooks神来之笔:思维链剥离
系统会直接把 <analysis> 剥离掉,不进入最终上下文 。只保留 <summary>。
就像考试,草稿纸(分析过程)不交卷,只交答题卡(摘要)。既保证质量,又省下 Token。
缓存友好设计
typescript
cacheSafeParams: CacheSafeParams // 保持 prompt cache 命中使用 cacheSafeParams 确保压缩操作不会破坏服务端已缓存的 prompt 前缀。
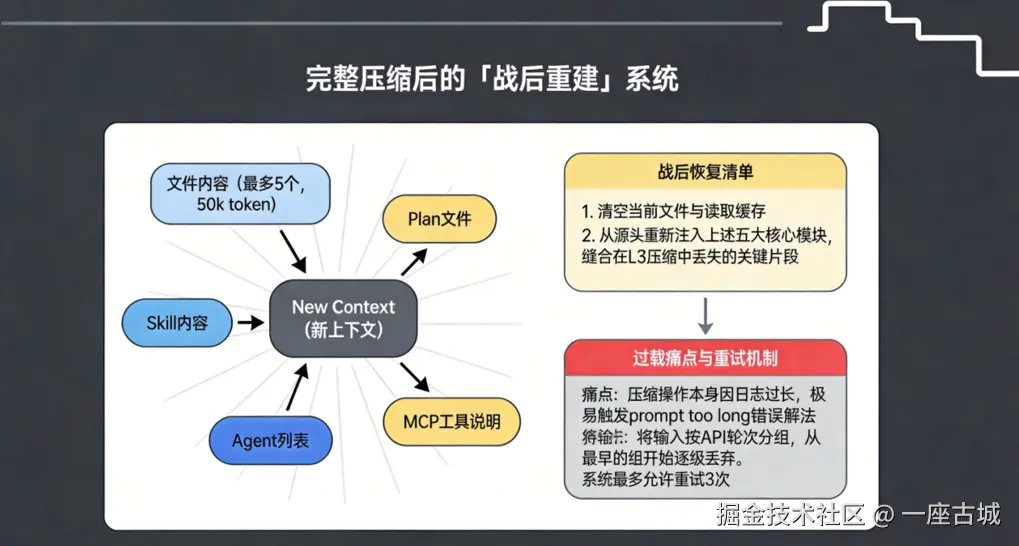
八、战后重建系统:压缩后重新注入核心模块
问题
大压缩相当于无差别降维打击,可能误伤关键业务上下文。
解决
压缩后第一件事:清空当前缓存,重新注入核心模块。
注入清单包括:
- 文件内容(最多 5 个,50k token)
- Plan 文件
- Skill 内容
- MCP 工具说明
- Agent 列表
过载重试机制
如果压缩请求本身太长触发 prompt too long,系统会按 API 轮次分组丢弃旧记录,最多重试 3 次:
typescript
if (summary.startsWith(PROMPT_TOO_LONG_ERROR_MESSAGE)) {
messagesToSummarize = truncateOldestMessages(messagesToSummarize)
retryCacheSafeParams = rebuildCacheSafeParams(messagesToSummarize)
continue // 重试
}
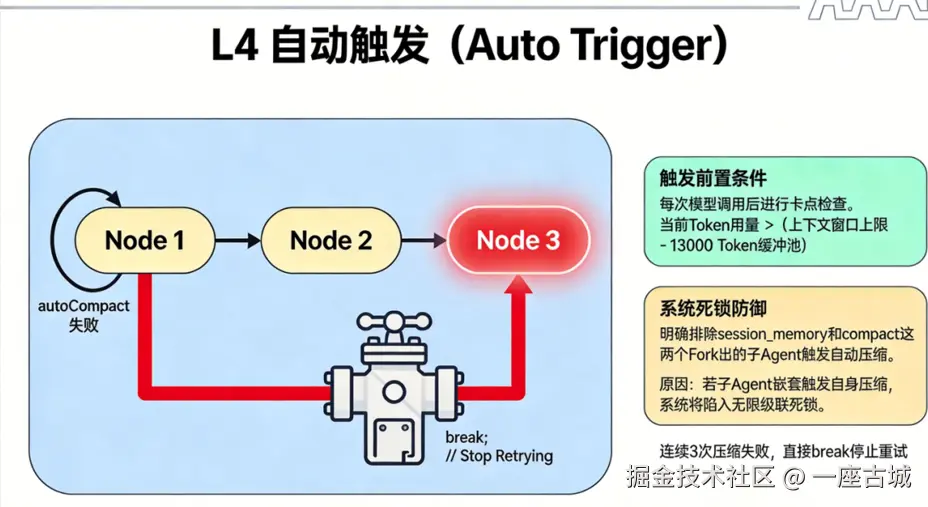
九、L4 自动触发:系统的节拍器与熔断器
触发公式
每次模型调用后检查:
scss
当前 Token 用量 > (上下文窗口上限 - 13000 Token 缓冲池)在 autoCompact.ts(351 行)中:
typescript
export function getEffectiveContextWindowSize(model: string): number {
const reservedTokensForSummary = Math.min(
getMaxOutputTokensForModel(model),
MAX_OUTPUT_TOKENS_FOR_SUMMARY // 20,000
)
let contextWindow = getContextWindowForModel(model, getSdkBetas())
// 支持环境变量覆盖
const autoCompactWindow = process.env.CLAUDE_CODE_AUTO_COMPACT_WINDOW
if (autoCompactWindow) {
contextWindow = Math.min(contextWindow, parseInt(autoCompactWindow, 10))
}
return contextWindow - reservedTokensForSummary
}
四级阈值系统
| 阈值 | 位置 | 作用 |
|---|---|---|
| 警告阈值 | ~90% 上下文窗口 | 提示用户上下文即将满了 |
| 错误阈值 | ~95% 上下文窗口 | 接近危险线 |
| 自动压缩阈值 | 剩余 < 13k token | 触发自动压缩 |
| 阻止限制 | 极限值 | 达到后阻止新操作 |
系统死锁防御
明确排除 session_memory 和 compact 这两个 Fork 出的子 Agent 触发自动压缩:
防止子 Agent 嵌套触发自身压缩,陷入无限级联死锁。
熔断机制 (Breaker)
如果连续 3 次压缩失败,直接 break 停止重试。
真实事故:曾发生过一天浪费 25 万次 API 调用的事故,全靠这个熔断器止损。
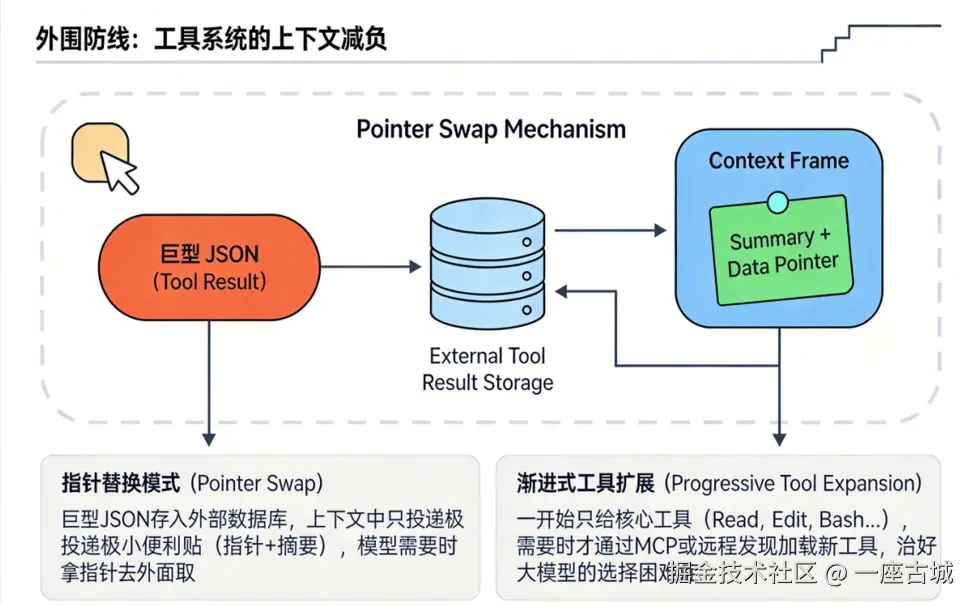
十、外围防线:工具系统的上下文减负
指针替换模式 (Pointer Swap)
javascript
巨型 JSON (Tool Result) → 存入外部数据库
上下文中只投递 → 极小的"便利贴"(指针 + 摘要)
模型想查细节 → 拿着指针去外部取渐进式工具扩展 (Progressive Tool Expansion)
- 一开始只给核心工具(Read, Edit, Bash...)
- 需要时才通过 MCP 或远程发现加载新工具
- 目的:治好大模型的"选择困难症",减少错误重试带来的上下文污染
MCP 相关文件:services/mcp/
- 连接外部 MCP 服务器
- 动态加载工具定义
- OAuth 认证支持
- 工具搜索(ToolSearch)
十一、核心循环:Query Loop 的 Token 管理
整个系统的核心循环在 query.ts(1729 行)中:
typescript
async function* queryLoop(params, consumedCommandUuids): AsyncGenerator<...> {
let state: State = {
messages: params.messages,
maxOutputTokensOverride: params.maxOutputTokensOverride,
autoCompactTracking: undefined,
maxOutputTokensRecoveryCount: 0,
hasAttemptedReactiveCompact: false,
turnCount: 1,
...
}
const budgetTracker = feature('TOKEN_BUDGET') ? createBudgetTracker() : null
let taskBudgetRemaining: number | undefined = undefined
while (true) {
// 1. 检查上下文窗口
const tokenUsage = tokenCountWithEstimation(state.messages)
// 2. 检查是否需要压缩
const warningState = calculateTokenWarningState(tokenUsage, model)
if (warningState.isAboveAutoCompactThreshold) {
const compactionResult = await compactConversation(...)
// 更新任务预算(跨压缩边界)
if (params.taskBudget) {
taskBudgetRemaining = Math.max(0,
(taskBudgetRemaining ?? params.taskBudget.total) - preCompactContext
)
}
state.messages = buildPostCompactMessages(compactionResult)
}
// 3. 执行 API 调用
yield* executeAPIQuery(...)
// 4. 处理工具调用
// 5. 检查预算
if (feature('TOKEN_BUDGET') && budgetTracker) {
const decision = checkTokenBudget(budgetTracker, agentId, budget, globalTurnTokens)
if (decision.action === 'stop') {
return { reason: 'budget_exhausted', ... }
}
}
}
}十二、Token 预算系统
支持用户精确控制 token 消耗。在 utils/tokenBudget.ts 中:
三种语法格式
typescript
// 1. 简写(开头): "+500k"
// 2. 简写(结尾): " +500k."
// 3. 详细: "use 2M tokens" / "spend 500k tokens"运行时检查
在 query/tokenBudget.ts 中:
- 完成阈值:90% --- 达到后停止
- 收益递减阈值:500 token --- 连续 3 次增量都 < 500 token 时停止
十三、特性开关系统
大量使用 feature() 和 getFeatureValue_CACHED_MAY_BE_STALE() 进行特性控制:
typescript
feature('TOKEN_BUDGET') // Token 预算功能
feature('REACTIVE_COMPACT') // 响应式压缩
feature('CONTEXT_COLLAPSE') // 上下文折叠
feature('HISTORY_SNIP') // 历史裁剪
feature('COORDINATOR_MODE') // 协调器模式
feature('KAIROS') // 助手模式
feature('EXPERIMENTAL_SKILL_SEARCH') // 实验性技能搜索
feature('PROMPT_CACHE_BREAK_DETECTION') // Prompt 缓存破坏检测设计目的:特性灰度发布、A/B 测试、内部调试、实验性功能保护。
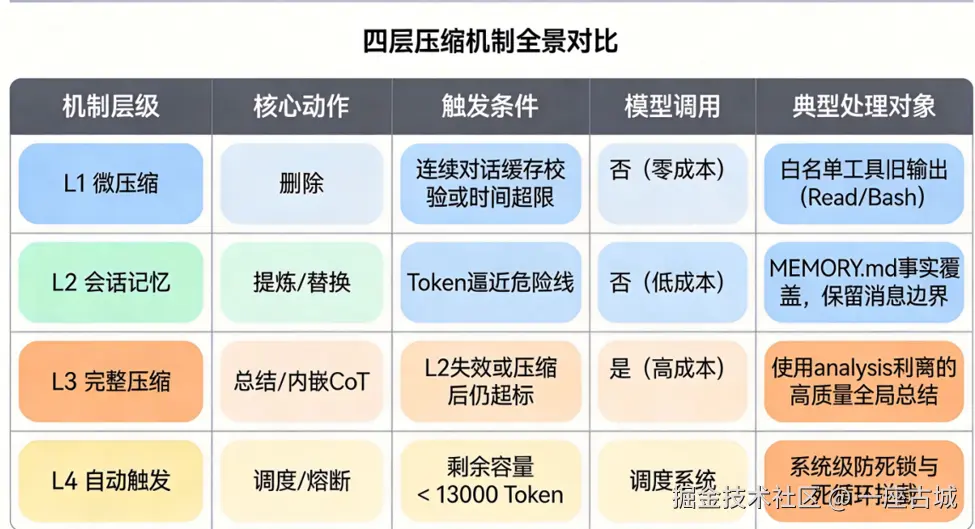
十四、四层压缩机制全景对比
| 层级 | 操作 | 触发条件 | 调用模型 | 产出 |
|---|---|---|---|---|
| L1 微压缩 | 删除旧输出 | 连续对话缓存校验 / 时间超限 | 否(零成本) | 白名单工具旧输出被清理 |
| L2 会话记忆 | 提炼/替换 | Token 逼近危险线 | 否(低成本 fork) | MEMORY.md 事实覆盖 |
| L3 完整压缩 | 总结 + 内嵌 CoT | L2 失效或压缩后仍超标 | 是(高成本) | <analysis> 剥离的高质量全局总结 |
| L4 自动触发 | 调度/熔断 | 剩余容量 < 13000 Token | 调度系统 | 系统级防死锁与死循环拦截 |
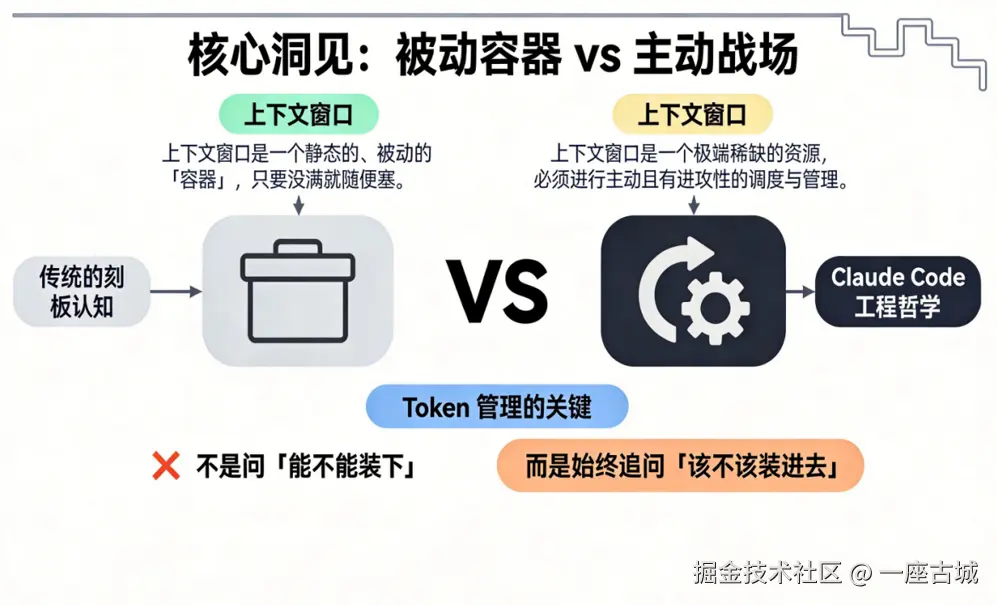
十五、核心洞见:被动容器 vs 主动战场
传统的刻板认知
上下文窗口是一个静态的、被动的"容器",只要没满就随便塞。
Claude Code 工程哲学
上下文窗口是一个极端稀缺的资源,必须进行主动且有进攻性的调度与管理。
Token 管理的关键
- 不是问"能不能装下"
- 而是始终追问"该不该装进去"
总结
从规则清理到模型降维,再到系统级熔断,这是一套教科书级别的上下文管理方案。
十六、数据流全景
yaml
用户输入
↓
QueryEngine.submitMessage()
↓
构建上下文: SystemPrompt + UserContext + SystemContext(并行 Promise.all)
↓
query() 循环
├── L1: 微压缩(规则清理,零成本)
├── L2: 会话记忆(结构化事实提取)
├── L3: 完整压缩(模型降维 + 思维链剥离)
├── L4: 自动触发(节拍器 + 熔断器)
├── Token 计数(5 种方式精确测量)
├── 预算检查(用户指定 + 收益递减)
├── API 流式调用(看门狗 + 非流式降级)
└── 工具执行(MCP 扩展 + 渐进式加载)
↓
SDK / REPL 输出十七、代码源索引
| 模块 | 核心文件 | 行数 | 职责 |
|---|---|---|---|
| 入口 | main.tsx |
4684 | CLI 主入口、命令路由 |
| 初始化 | init.ts |
340 | 系统初始化、配置 |
| QueryEngine | QueryEngine.ts |
1295 | 对话生命周期管理 |
| Query 循环 | query.ts |
1729 | 核心查询循环、token 管理 |
| Token 计数 | tokens.ts |
261 | 5 种 token 计算 |
| Token 预算 | tokenBudget.ts |
73 | 用户预算解析 |
| 预算跟踪 | query/tokenBudget.ts |
93 | 运行时预算检查 |
| 上下文构建 | context.ts |
189 | UserContext/SystemContext |
| 上下文配置 | utils/context.ts |
221 | 窗口大小、输出限制 |
| 系统提示 | prompts.ts |
914 | SystemPrompt 构建 |
| 自动压缩 | autoCompact.ts |
351 | 压缩阈值计算 |
| 压缩实现 | compact.ts |
1705 | 压缩完整流程 |
| API 调用 | claude.ts |
3419 | 流式 API 调用 |
| 会话内存 | sessionMemory.ts |
495 | 跨会话记忆 |
| 上下文分析 | analyzeContext.ts |
1382 | 上下文可视化 |
| Token 估算 | tokenEstimation.ts |
495 | Token 估算服务 |
总计还原文件数 :4756 个(含 1884 个 .ts/.tsx 源文件)
十八、关键设计模式
18.1 缓存策略
| 策略 | 用途 |
|---|---|
lodash-es/memoize() |
缓存上下文函数(UserContext/SystemContext) |
| Anthropic Prompt Cache | 服务端缓存,通过 cacheSafeParams 保护 |
| File State Cache | 文件状态缓存避免重复读取 |
| Claude.md Cache | 项目指令缓存 |
18.2 异步并行
typescript
// 并行获取三个上下文
const [defaultSystemPrompt, userContext, systemContext] = await Promise.all([
getSystemPrompt(...),
getUserContext(),
getSystemContext(),
])18.3 Generator 流式处理
整个系统重度使用 async function* 和 yield*:
typescript
async function* query(params): AsyncGenerator<..., Terminal> {
yield* queryLoop(params, consumedCommandUuids)
}18.4 状态管理
typescript
// 不可变参数(从不重新赋值)
const { systemPrompt, userContext, ... } = params
// 可变跨迭代状态
let state: State = { messages: params.messages, ... }
// 循环中整体替换状态
state = { ...state, messages: newMessages, transition: 'auto_compact' }十九、错误处理与恢复
max_output_tokens 错误恢复
typescript
const MAX_OUTPUT_TOKENS_RECOVERY_LIMIT = 3
if (error.apiError === 'max_output_tokens') {
if (state.maxOutputTokensRecoveryCount < MAX_OUTPUT_TOKENS_RECOVERY_LIMIT) {
state.maxOutputTokensOverride = ESCALATED_MAX_TOKENS // 64,000
state.maxOutputTokensRecoveryCount++
continue
}
}流式降级
流失败时自动降级到非流式请求。
Prompt Too Long 重试
压缩请求本身也可能 prompt too long,系统会截断最旧的消息并重试。
二十、性能优化总结
| 优化方向 | 具体措施 |
|---|---|
| 启动性能 | 延迟加载、早期配置、API 预连接、Profiler Checkpoint |
| 运行时性能 | Token 估算、Prompt Cache、并行工具调用、流式处理 |
| 内存管理 | 消息压缩、文件缓存、优雅关闭、Stream 资源释放 |
| 上下文管理 | L1-L4 四层压缩、指针替换、渐进式工具扩展 |
分析基于 @anthropic-ai/claude-code@2.1.88 还原源码,仅供技术研究学习