1.案例描述
用 Q-learning 算法训练智能体在网格世界中自主 学习 避障、找到从起点到终点的最优路径,并展示训练结果。
2.代码实现
python
# -*- coding: utf-8 -*-
import numpy as np
import random
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"当前运行设备: {device}")
class GridWorld:
def __init__(self, size=7):
self.size = size
self.start = (0, 0)
self.goals = {(size - 1, size - 1): 1.0, (0, size - 1): 0.5}
self.walls = {(2, 2), (2, 3), (3, 2), (4, 4)}
self.traps = {(3, 5), (5, 3)}
self.state = self.start
def reset(self):
self.state = self.start
return self._state_to_obs(self.state)
def step(self, action):
x, y = self.state
nx, ny = x, y
if action == 0: nx -= 1 # up
elif action == 1: nx += 1 # down
elif action == 2: ny -= 1 # left
elif action == 3: ny += 1 # right
nx = np.clip(nx, 0, self.size - 1)
ny = np.clip(ny, 0, self.size - 1)
if (nx, ny) in self.walls:
nx, ny = x, y
self.state = (nx, ny)
reward = -0.05
done = False
if self.state in self.traps:
reward = -1.0
done = True
if self.state in self.goals:
reward = self.goals[self.state]
done = True
return self._state_to_obs(self.state), reward, done
def _state_to_obs(self, state):
obs = np.zeros((4, self.size, self.size), dtype=np.float32)
obs[0, state[0], state[1]] = 1.0
for w in self.walls: obs[1, w[0], w[1]] = 1.0
for t in self.traps: obs[2, t[0], t[1]] = 1.0
for g in self.goals: obs[3, g[0], g[1]] = 1.0
return obs.flatten()
class DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super(DQN, self).__init__()
self.net = nn.Sequential(
nn.Linear(state_dim, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, action_dim)
)
def forward(self, x):
return self.net(x)
class ReplayBuffer:
def __init__(self, capacity=8000):
self.buffer = []
self.capacity = capacity
def push(self, s, a, r, s_, d):
if len(self.buffer) >= self.capacity:
self.buffer.pop(0)
self.buffer.append((s, a, r, s_, d))
def sample(self, batch_size):
batch = random.sample(self.buffer, batch_size)
s, a, r, s_, d = zip(*batch)
return (torch.FloatTensor(np.array(s)).to(device),
torch.LongTensor(np.array(a)).to(device),
torch.FloatTensor(np.array(r)).to(device),
torch.FloatTensor(np.array(s_)).to(device),
torch.FloatTensor(np.array(d)).to(device))
def __len__(self):
return len(self.buffer)
def train():
env = GridWorld(size=7)
state_dim = 4 * env.size * env.size
action_dim = 4
q_net = DQN(state_dim, action_dim).to(device)
target_net = DQN(state_dim, action_dim).to(device)
target_net.load_state_dict(q_net.state_dict())
optimizer = optim.Adam(q_net.parameters(), lr=1e-3)
criterion = nn.MSELoss()
buffer = ReplayBuffer()
gamma = 0.95
epsilon = 1.0
epsilon_min = 0.05
epsilon_decay = 0.995
episodes = 200
batch_size = 64
rewards_history = []
for ep in range(episodes):
s = env.reset()
total_reward = 0
while True:
# 动作选择
if random.random() < epsilon:
a = random.randint(0, action_dim - 1)
else:
with torch.no_grad():
s_tensor = torch.FloatTensor(s).unsqueeze(0).to(device)
q_values = q_net(s_tensor)
a = q_values.argmax().item()
s_, r, done = env.step(a)
buffer.push(s, a, r, s_, done)
s = s_
total_reward += r
# 经验回放
if len(buffer) >= batch_size:
bs, ba, br, bs_, bd = buffer.sample(batch_size)
# 计算当前 Q 值
q_eval = q_net(bs).gather(1, ba.unsqueeze(1)).squeeze(1)
# 计算目标 Q 值
with torch.no_grad():
q_next = target_net(bs_).max(1)[0]
q_target = br + gamma * q_next * (1 - bd)
loss = criterion(q_eval, q_target)
# 更新网络
optimizer.zero_grad()
loss.backward()
optimizer.step()
if done:
break
epsilon = max(epsilon * epsilon_decay, epsilon_min)
rewards_history.append(total_reward)
if ep % 30 == 0:
target_net.load_state_dict(q_net.state_dict())
print(f"Episode {ep}, Reward {total_reward:.2f}, Epsilon {epsilon:.2f}")
return env, q_net, rewards_history
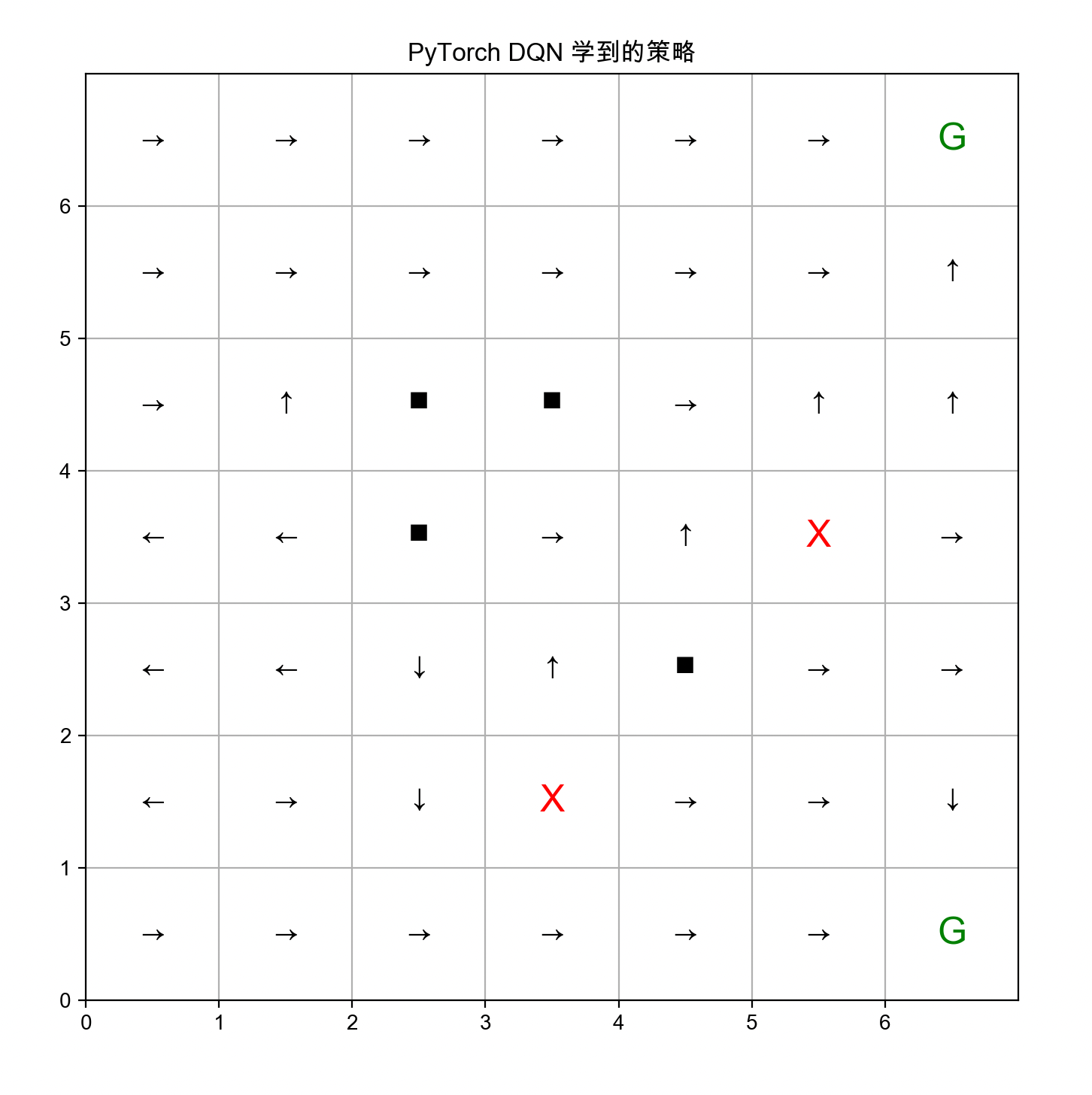
def visualize_policy(env, q_net):
q_net.eval()
arrows = {0: '↑', 1: '↓', 2: '←', 3: '→'}
fig, ax = plt.subplots(figsize=(8, 8))
ax.set_xlim(0, env.size)
ax.set_ylim(0, env.size)
ax.set_xticks(np.arange(env.size))
ax.set_yticks(np.arange(env.size))
ax.grid(True)
for i in range(env.size):
for j in range(env.size):
if (i, j) in env.walls:
ax.text(j + 0.5, env.size - i - 0.5, '■', fontsize=18, ha='center', va='center')
continue
if (i, j) in env.traps:
ax.text(j + 0.5, env.size - i - 0.5, 'X', color='red', fontsize=18, ha='center', va='center')
continue
if (i, j) in env.goals:
ax.text(j + 0.5, env.size - i - 0.5, 'G', color='green', fontsize=18, ha='center', va='center')
continue
obs = env._state_to_obs((i, j))
with torch.no_grad():
obs_tensor = torch.FloatTensor(obs).unsqueeze(0).to(device)
q = q_net(obs_tensor)
a = q.argmax().item()
ax.text(j + 0.5, env.size - i - 0.5, arrows[a],
ha='center', va='center', fontsize=16)
plt.title("PyTorch DQN 学到的策略")
plt.show()
if __name__ == "__main__":
env, q_net, rewards = train()
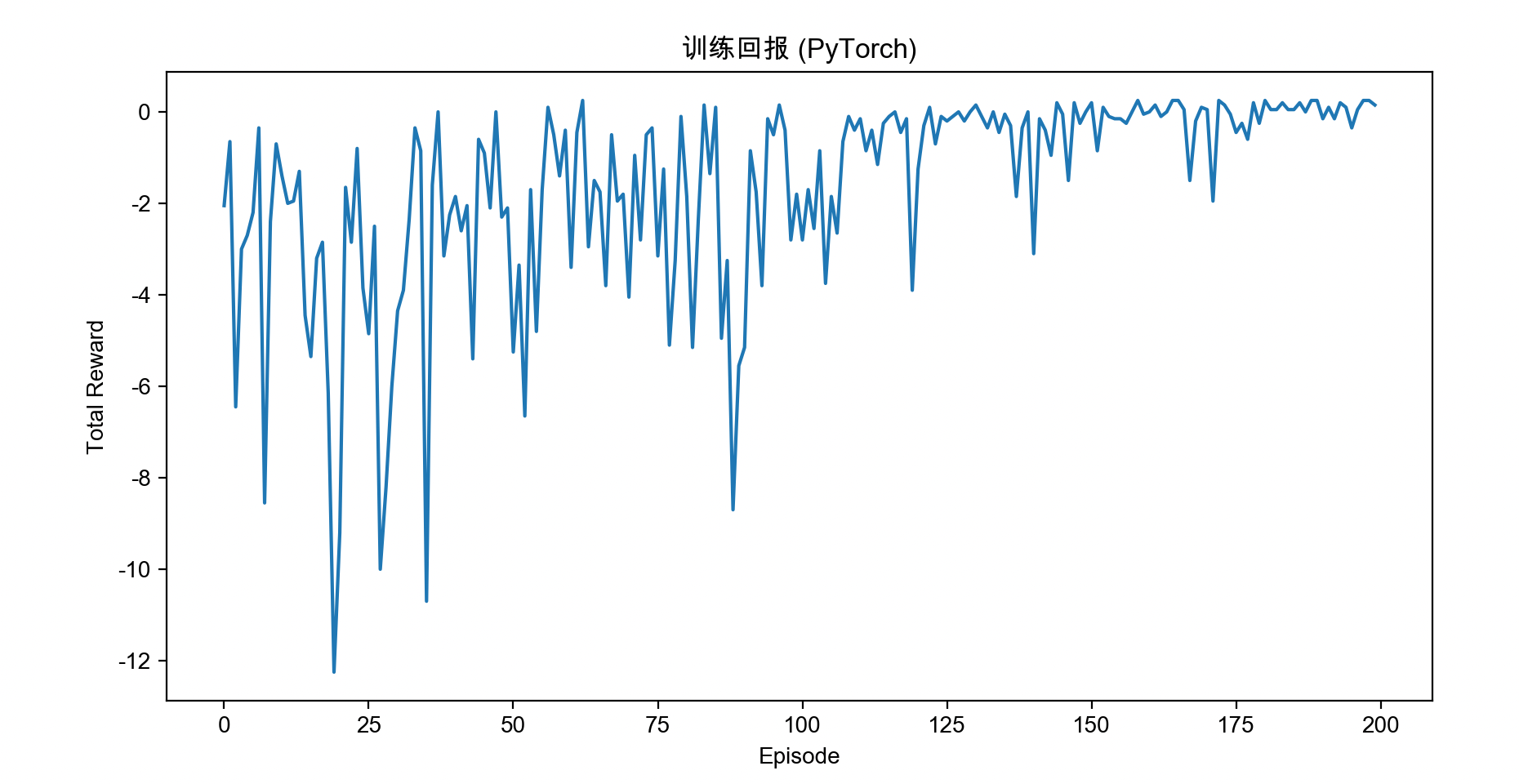
plt.figure(figsize=(10, 5))
plt.plot(rewards)
plt.title("训练回报 (PyTorch)")
plt.xlabel("Episode")
plt.ylabel("Total Reward")
plt.show()
visualize_policy(env, q_net)3.效果展示
bash
当前运行设备: cpu
Episode 0, Reward -3.20, Epsilon 0.99
Episode 30, Reward -2.90, Epsilon 0.86
Episode 60, Reward -2.30, Epsilon 0.74
Episode 90, Reward -0.55, Epsilon 0.63
Episode 120, Reward -1.40, Epsilon 0.55
Episode 150, Reward 0.00, Epsilon 0.47
Episode 180, Reward 0.25, Epsilon 0.40