导读:很多人理解 AI Agent 时,只盯着模型能力、工具调用和 Prompt,其实真正让 Agent 变成"长期同事"的,是 Sessions。没有 Sessions,Agent 每次换平台、换窗口、换时间,都像失忆;有了 Sessions,任务才有连续性,历史才可检索,平台之间才可以无缝接力。
本文用通俗语言拆解 Hermes Agent 的 Sessions 设计:它如何保存完整任务轨迹,如何在 CLI、Telegram、Discord、Slack、Email 等入口之间维持同一条工作线,如何通过 SQLite + FTS5 找回过去的上下文,又如何避免把所有历史都塞进模型窗口导致 token 爆炸。
一、为什么 Sessions 是长期 Agent 的底座
普通聊天机器人最容易出现的问题是:当前窗口里有什么,它就知道什么;窗口一换、平台一换、时间一长,它就很难继续上一次的任务。对于真正的 Agent 来说,这远远不够。Agent 不只是"回答一句话",而是要接任务、查资料、改文件、跑命令、调用工具、等待结果、再继续下一步。
Hermes Agent 官方文档明确强调:它不是绑在 IDE 里的 coding copilot,也不是单个 API 外面包一层聊天界面,而是可以运行在 VPS、GPU 集群或 serverless 环境里的 autonomous agent;它可以在 Telegram 上接收消息,同时在云主机上继续工作。
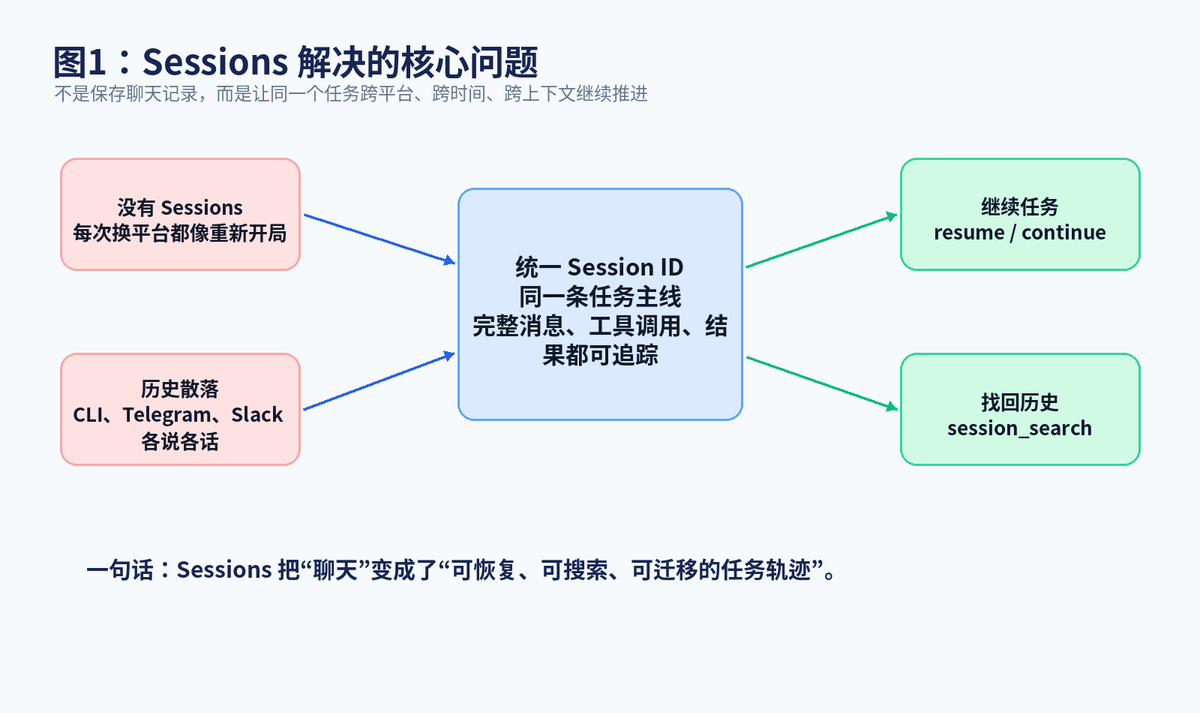
这类 Agent 最核心的工程问题就是:任务状态到底放在哪里?如果所有状态只放在模型上下文里,窗口很快就会爆;如果只放在聊天平台里,跨平台就断;如果只写日志,Agent 下次也不一定能找回。Sessions 的作用就是把这些分散的交互统一成一条可恢复、可搜索、可迁移的任务轨迹。
二、Sessions 的整体架构:入口不同,任务主线相同

Hermes 的入口很多:CLI、TUI、Telegram、Discord、Slack、WhatsApp、Signal、Email、SMS、Teams 等都可以成为用户和 Agent 交互的入口。但入口再多,不能意味着每个平台各自维护一份孤立历史。官方 Messaging Gateway 文档说明,Gateway 是一个连接所有配置平台的后台进程,会处理 sessions、cron jobs 和语音消息;每个平台 adapter 接收消息后,会通过 per-chat session store 路由到 AIAgent。
这套设计的重点是:平台只是入口,Session 才是任务身份。用户可以从 CLI 开始一个任务,中途把任务转到 Telegram,晚上再回到 CLI 继续。只要背后的 session_id 没断,Agent 就能沿着同一条历史继续推进。
从架构角度看,Sessions 是 Gateway、AIAgent、Memory、Tools、Context Compression 之间的连接层。它既服务用户体验,也服务工程可观测性:哪次任务用了多少 token、调用了哪些工具、在哪个平台发生、是否由压缩产生父子链路,都可以回到 Session 存储里查。
三、一次 Session 怎么产生:从消息进入到历史写入
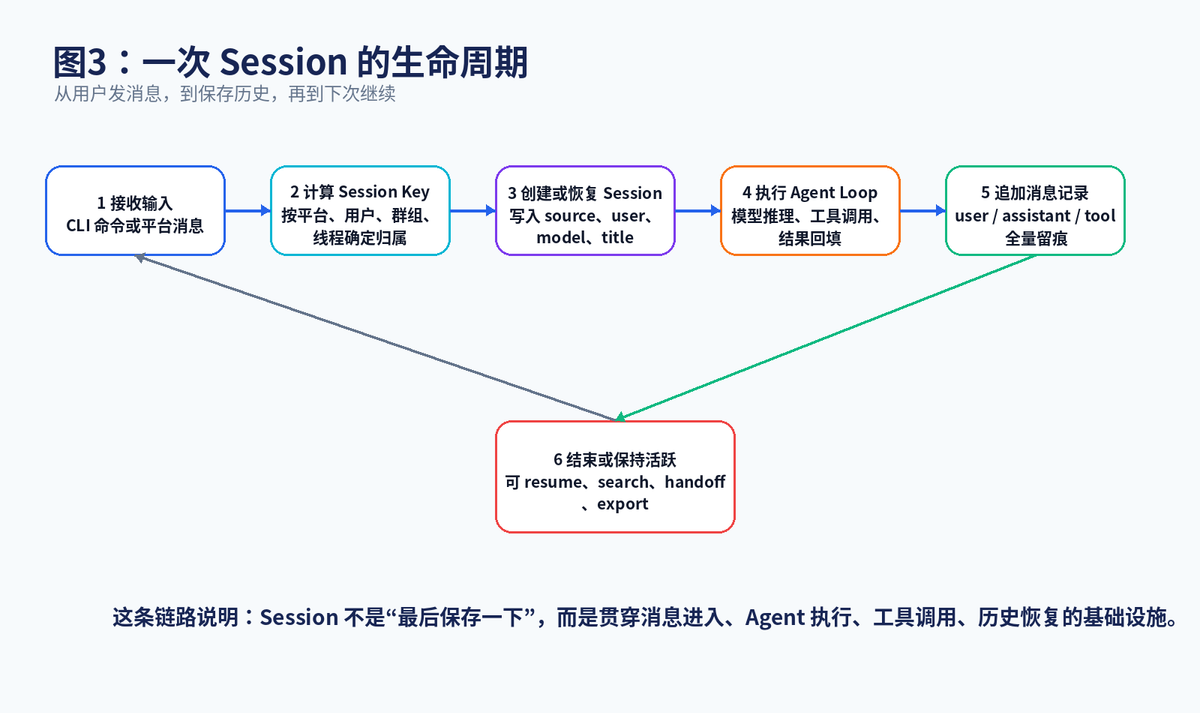
一次 Session 的产生可以理解成 6 步:第一步,用户在某个平台发来消息;第二步,Hermes 根据消息来源构造 session key;第三步,系统检查这个 key 是否已经对应一个活跃 session;第四步,没有就创建,有就恢复;第五步,把用户消息交给 AIAgent 执行;第六步,把用户消息、助手回复、工具调用、工具结果都追加到会话历史中。
这说明 Session 不是"结束时保存一下聊天记录",而是贯穿一次任务执行的全过程。模型调用之前,它决定要恢复哪些历史;工具调用之后,它记录工具名、参数、结果和 token 信息;任务结束之后,它又支持 resume、search、export、prune 等后续操作。
从 AI 应用工程角度看,这个设计很关键。很多简单 Agent 项目失败,不是因为模型不会回答,而是因为没有稳定的任务状态层:用户一刷新页面就丢上下文,工具执行失败无法复盘,历史决策找不到,平台切换后任务线断掉。Hermes 的 Sessions 正是在解决这些问题。
四、state.db 数据模型:把聊天历史变成可检索资产
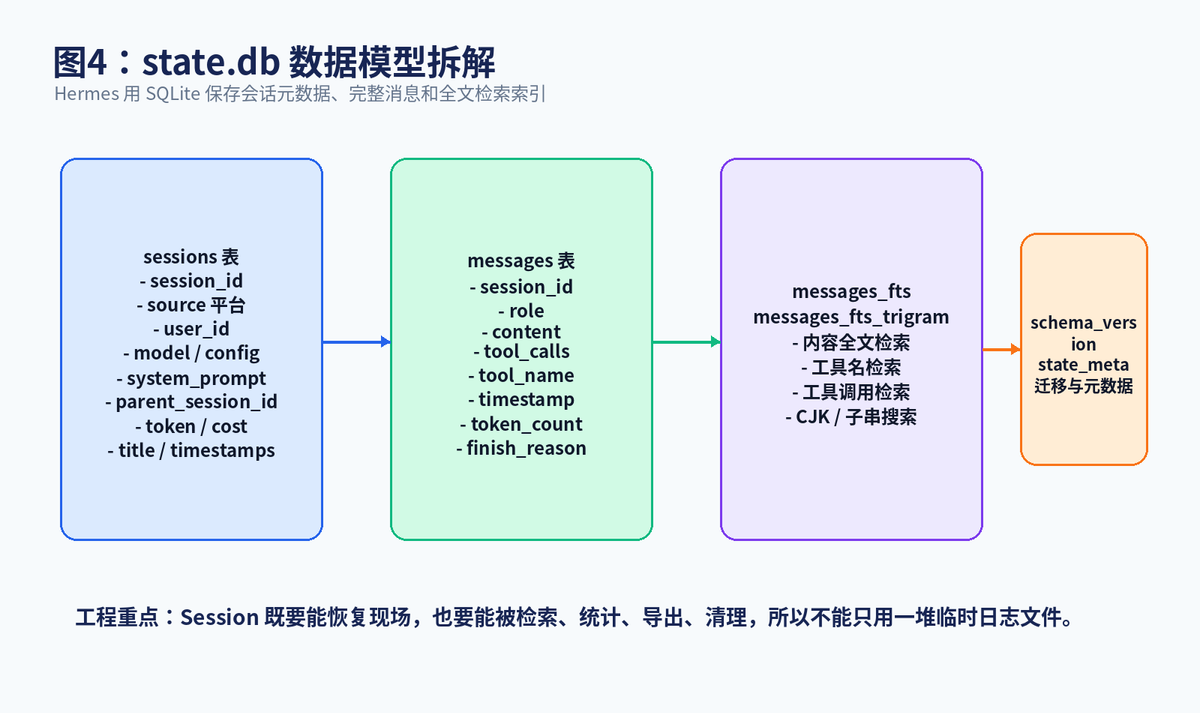
官方 Session Storage 文档指出,Hermes 使用 SQLite 数据库 ~/.hermes/state.db 持久化 session metadata、full message history 和 model configuration。这个文件不是随便存几行日志,而是一套有 schema、有索引、有全文检索能力的状态仓库。
最重要的表可以分成三类:第一类是 sessions 表,用来记录 session_id、source 平台、user_id、model、model_config、system_prompt、parent_session_id、token 统计、费用估算、title、started_at、ended_at 等;第二类是 messages 表,用来记录每条消息的 role、content、tool_calls、tool_name、timestamp、token_count、finish_reason 等;第三类是 messages_fts 和 messages_fts_trigram,用来做全文检索和 CJK / 子串搜索。
为什么不用简单 JSON 文件?因为长期运行 Agent 的历史会越来越多,必须要支持快速查询、按平台过滤、按角色过滤、统计 token、处理并发读写和 schema 迁移。官方文档里也提到,state.db 使用 WAL mode,适合多平台 Gateway 下的并发读取和单写入模式。
五、Resume:让任务从"历史记录"恢复为"工作现场"

Resume 的价值不只是"打开旧聊天"。用户可以使用 hermes --continue 继续最近一次 CLI 会话,也可以用 hermes --resume <session_id> 或标题恢复指定会话。官方 Sessions 文档还说明,恢复时会显示一个 compact recap 面板,把最近的用户和助手交换用较短形式展示,并把工具调用折叠成数量和工具名。
这个设计很适合长期任务。比如你昨天让 Agent 排查一个部署问题,它跑了命令、查了日志、改了配置、记录了失败原因。今天你回来,不需要重新解释全部背景,只要 resume 这个 session,Agent 就能沿着已有任务轨迹继续。
对于企业 AI 应用来说,Resume 对应的能力就是"工单续办"。用户再次进入系统时,系统不能只显示一句"欢迎回来",而应该能恢复这个工单的目标、当前状态、做过哪些动作、下一步该做什么。
六、Handoff:CLI、Telegram、Discord 之间如何接力
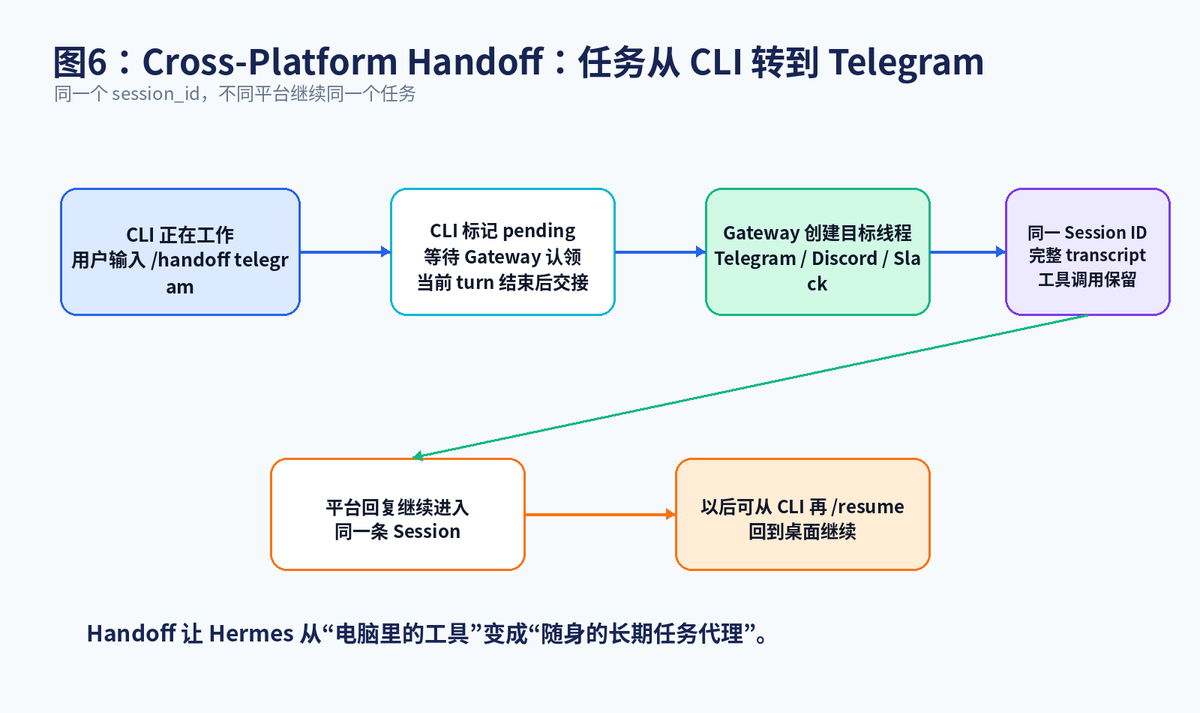
官方 Sessions 文档专门介绍了 Cross-Platform Handoff:用户可以在 CLI 中输入 /handoff <platform>,把正在进行的会话转移到消息平台的 home channel。关键点是,目标平台接手的是同一个 session_id,完整的 role-aware transcript 和 tool calls 都保留。
这就让 Hermes 不再只是"电脑终端里的工具"。你可以上午在 CLI 中让它处理代码,出门后把会话交接到 Telegram;它在云主机上继续执行,你在手机上接收结果;晚上回到电脑,再通过 /resume 把会话拉回 CLI。
这对产品设计很有启发:未来的 Agent 不一定绑定在某个 App 里,而应该像一个"任务进程"。用户在哪里,任务入口就在哪里;但任务本身的状态,需要在一个统一的 Session 层里保持连续。
七、Session Search:过去做过的事如何被找回
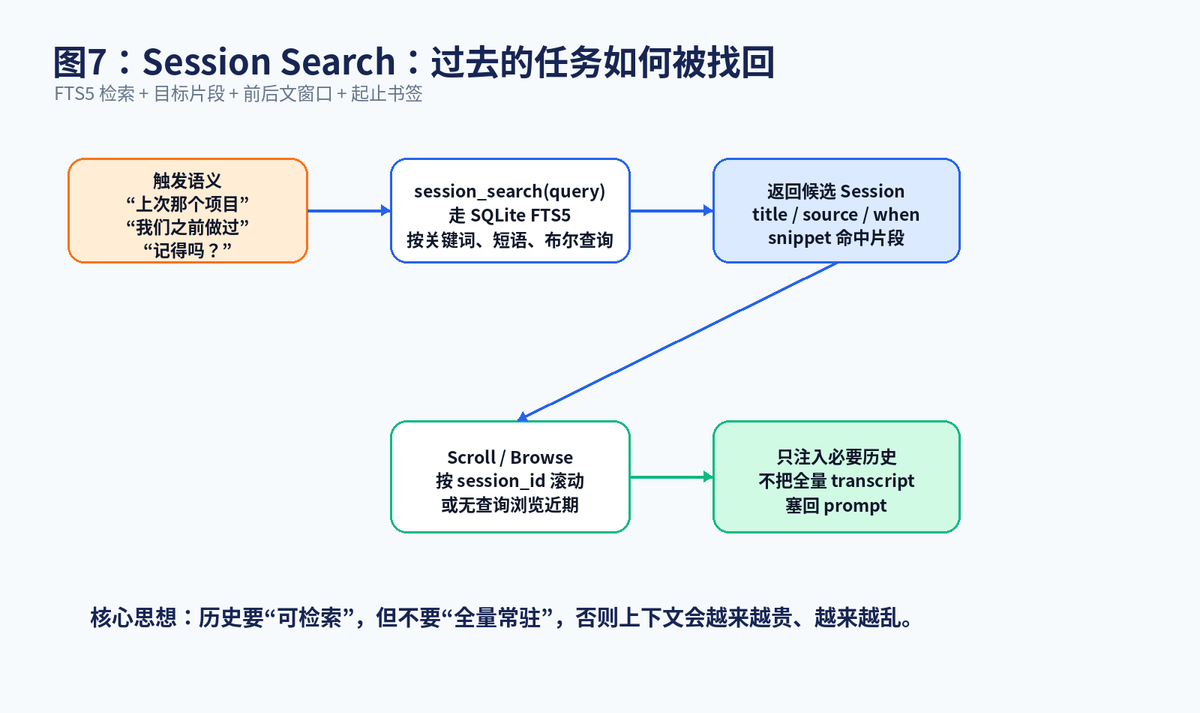
Session Search 是 Hermes "跨会话记忆"的重要支撑。官方文档说明,Agent 内置 session_search 工具,基于 SQLite FTS5 在所有过去对话中做全文搜索,并能返回数据库里的真实消息,而不是只给一个模糊总结。
它有三种典型用法:第一种是 Discovery,传入 query,比如 auth refactor,返回相关 Session、命中片段、开头几条消息和结尾几条消息;第二种是 Scroll,传入 session_id 和 around_message_id,在某个命中位置前后滚动查看;第三种是 Browse,不传参数,浏览最近会话。
这个设计的精髓在于:历史不是每次都塞进模型,而是在需要时检索。比如用户说"上次那个 Docker 部署问题继续一下",Agent 可以先用 session_search 找到相关历史,再把关键片段注入当前上下文。这样既避免用户重复解释,也避免把所有历史长期放进 prompt。
八、Context 与 History 的区别:保存完整,不等于全部发送
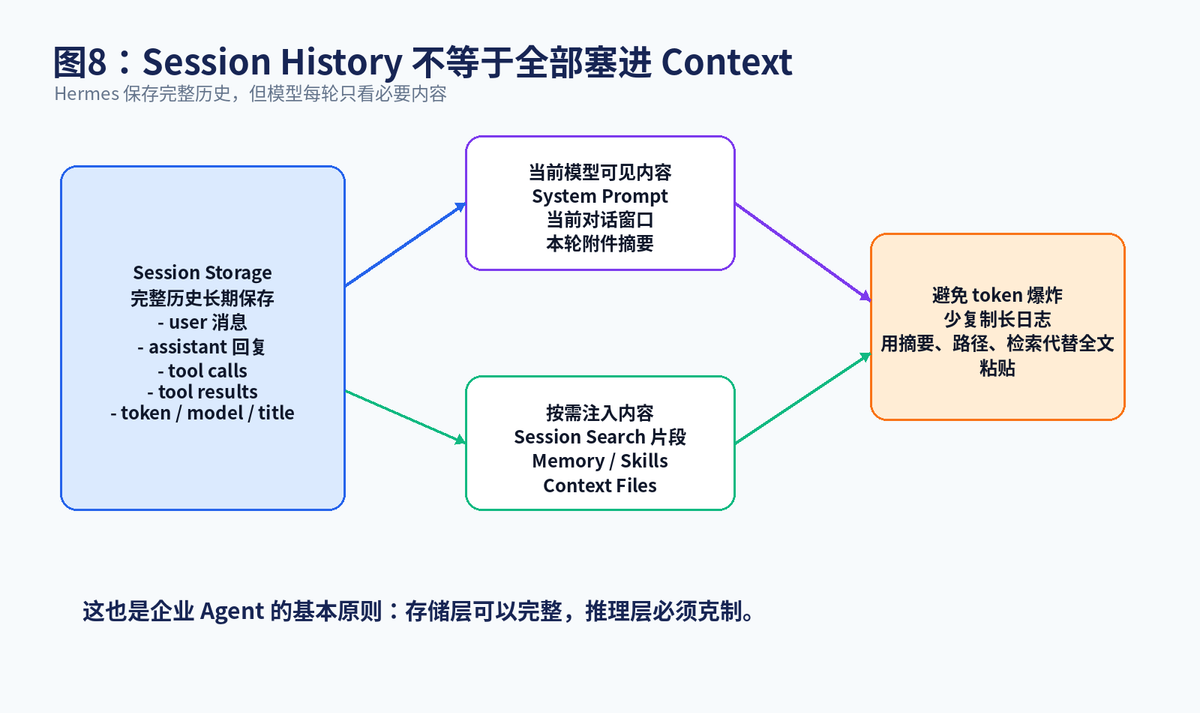
官方 Sessions 文档特别说明:Hermes 会保存 session history 以便恢复会话,但不会把它曾经处理过的每一个字节都反复发送给模型。每一轮模型真正看到的是选定的 system prompt、当前对话窗口,以及本轮显式注入的内容。
这个区别非常重要。Session History 是存储层,目标是完整、可追踪、可检索;Context 是推理层,目标是短、准、够用。把这两个概念混在一起,就会导致很多 Agent 项目上下文失控:历史越堆越多,模型越跑越贵,回答越来越偏。
Hermes 对附件也做了类似处理:图片可能在下一次模型调用中作为视觉输入,也可能被预分析成文本描述;音频会在配置了 STT 时转成文本;文档可以提取文本;但原始二进制文件不会在未来每一轮都重复复制进 prompt。这就是"存储完整,推理克制"的设计原则。
九、压缩、父子链路与长任务延续
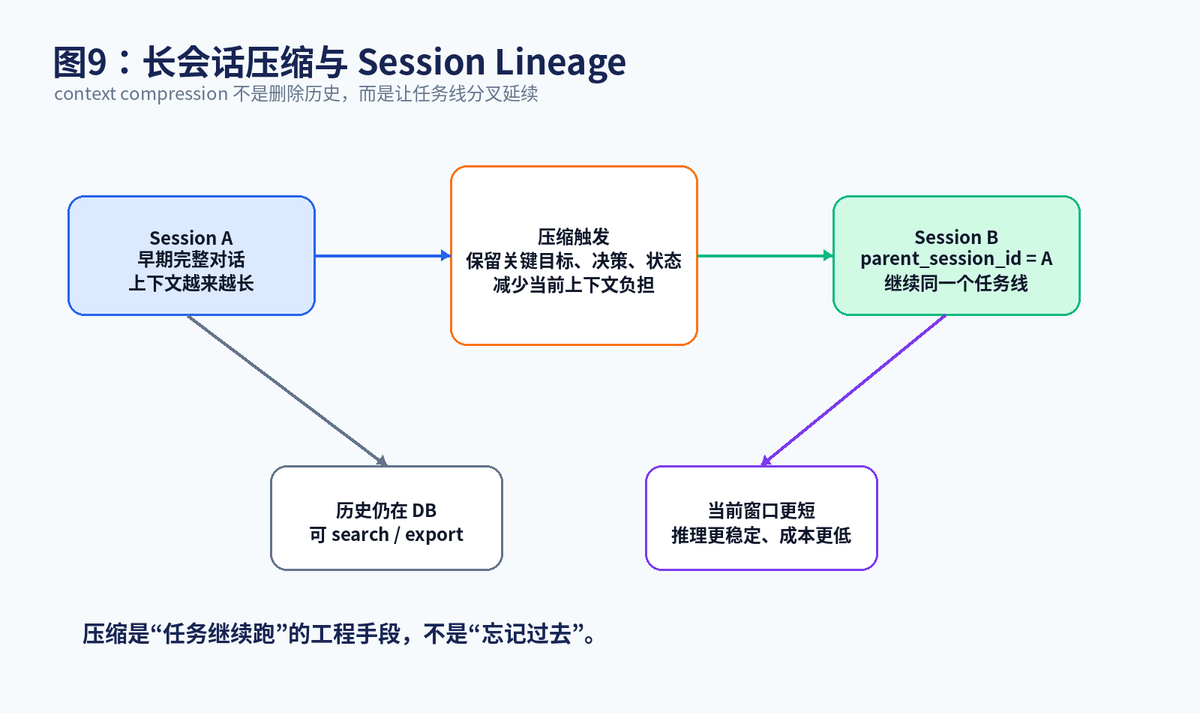
长任务一定会遇到上下文增长问题。Hermes 的解决思路不是无限扩展 prompt,而是在需要时做 context compression,并通过 parent_session_id 保持 Session lineage。官方 Session Storage 文档指出,sessions 表中有 parent_session_id 字段,压缩触发的 session split 会形成父子链路。
可以把它理解成:Session A 记录了早期完整对话;当上下文过长时,Hermes 生成关键摘要和任务状态,开启 Session B,并让 B 指向 A。这样,当前模型窗口更轻,历史又没有丢。以后如果需要复盘,仍然可以沿着父子链路查回去。
这对企业智能客服、研发助手、投研助手都很有价值。真实任务不会永远停留在一个上下文窗口内,必须有"历史归档 + 当前摘要 + 父子链路"的机制,才能稳定支撑长周期任务。
十、群聊、线程与多平台会话隔离
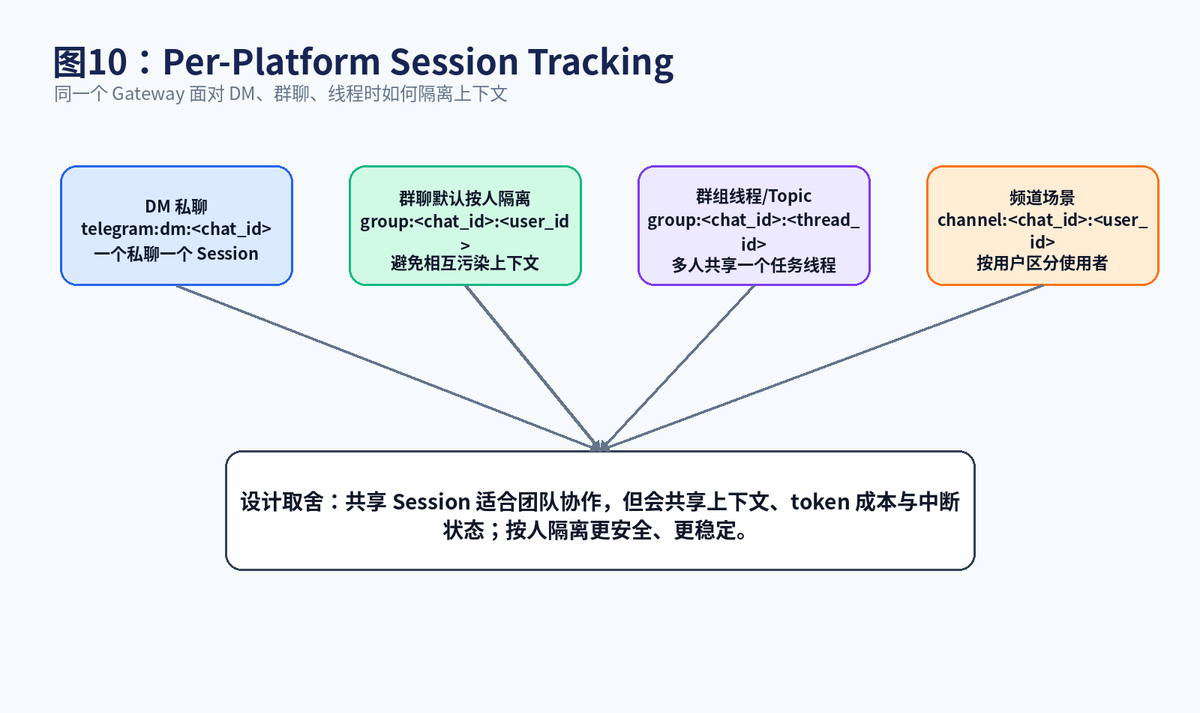
跨平台还不够,Hermes 还要处理更复杂的场景:私聊、群聊、频道、线程、Topic。官方 Sessions 文档说明,Messaging 平台上的 Sessions 会根据消息来源构造 deterministic session key,比如 DM 私聊按 chat_id 建 Session,群聊默认可以按 user_id 隔离,线程或 Topic 可以共享一个 session。
为什么要这么细?因为群聊里最怕上下文污染。Alice 让 Agent 排查数据库问题,Bob 同时让它写周报,如果两个人共享同一个上下文,很容易互相干扰,也会共享 token 成本和中断状态。官方文档也提到,默认 group_sessions_per_user 为 true,使同一频道里的不同用户不共享 transcript history。
当然,团队协作场景也可能需要"一个共享房间大脑"。这时可以把 group_sessions_per_user 设为 false,让一个群或频道共用上下文。这个开关背后体现的是一个产品设计取舍:个人任务要隔离,团队任务要共享。
十一、Session 运维命令:长期运行必须可管理
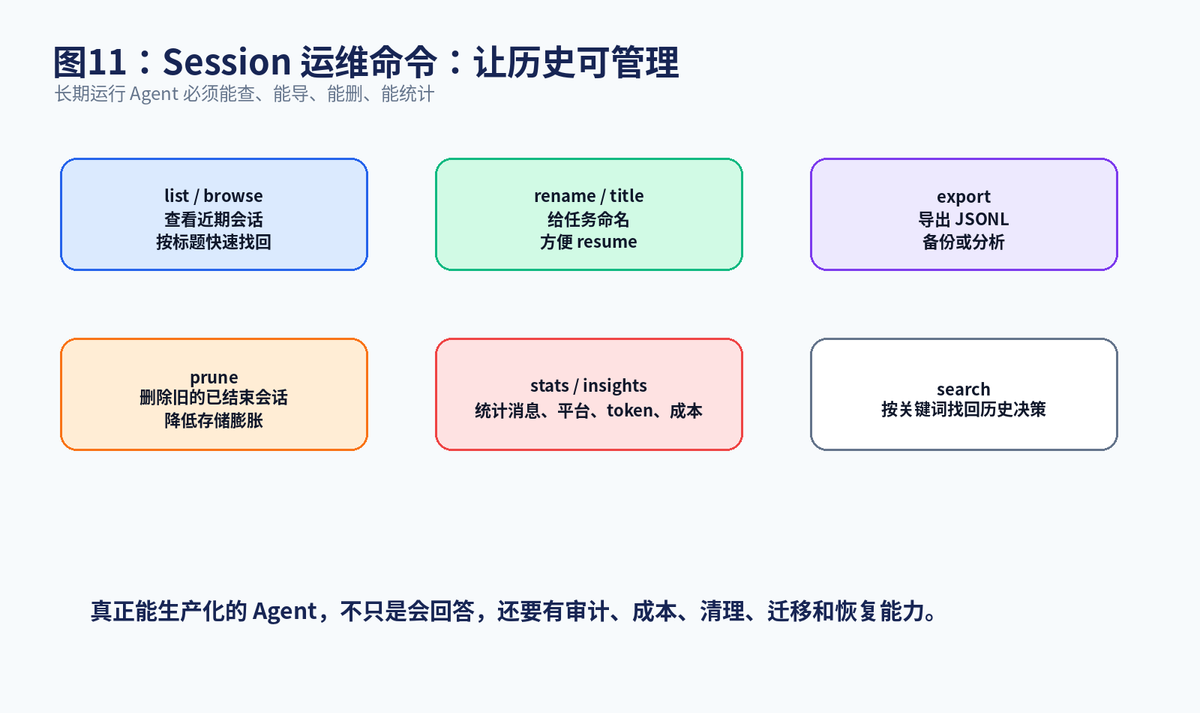
只要 Agent 长期运行,历史就会越来越多。所以 Hermes 不只提供 resume,还提供 list、browse、rename、export、prune、stats、insights 等管理能力。比如 hermes sessions export 可以把所有或某个平台的 sessions 导出为 JSONL;hermes sessions prune 可以删除超过指定天数的已结束会话;hermes sessions stats 可以统计 session 和 message 数量。
这些能力看起来像"工具命令",本质上是生产化 Agent 必备的运维接口。没有 export,就难以备份和迁移;没有 prune,历史会无限膨胀;没有 stats 和 insights,就无法分析成本、平台使用情况和高频任务;没有 title 和 rename,用户很难在大量历史中找回某个任务。
对自研 Agent 平台来说,这一块非常值得借鉴。很多项目第一版只做"用户问、模型答",但上线后马上会遇到:历史太多怎么清理?用户要查之前的任务怎么办?同一用户多端登录怎么接续?工具调用失败如何复盘?这些都离不开 Session 体系。
十二、源码阅读路线:想深入就从这几条线看
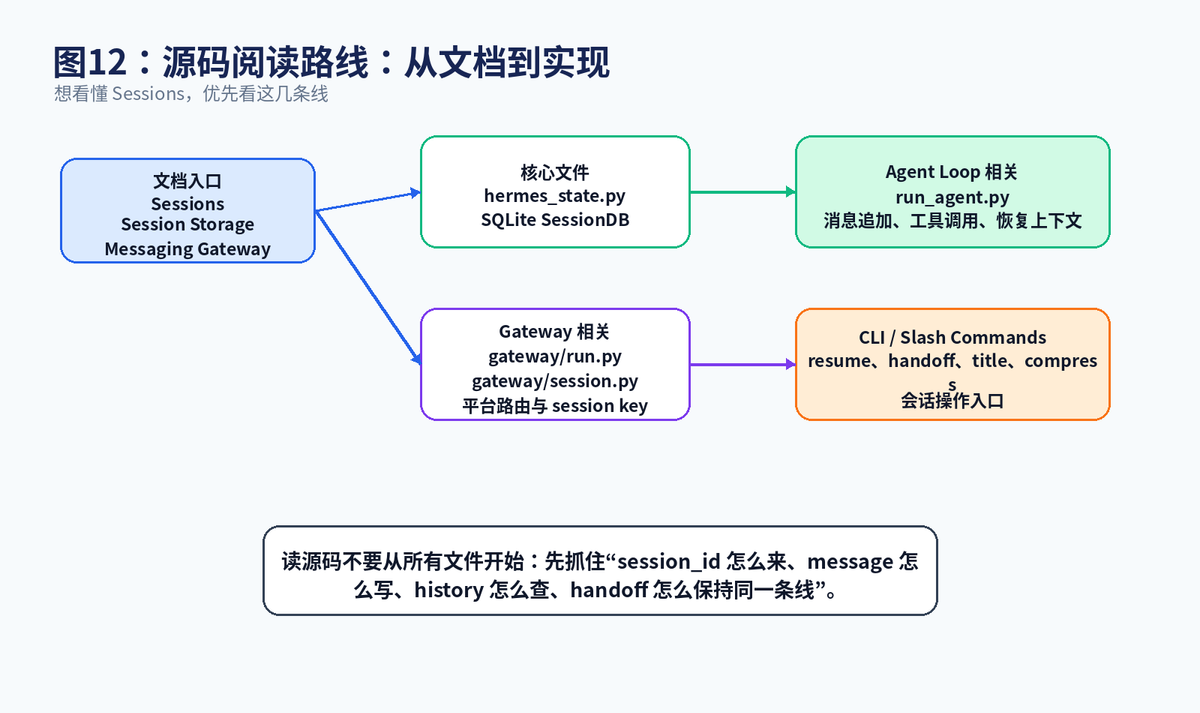
如果你要从源码层面理解 Sessions,不建议一上来全仓库乱翻。优先抓住四条主线:第一条,看官方 Sessions 文档和 Session Storage 文档,建立概念;第二条,看 hermes_state.py,理解 SQLite SessionDB 的建表、消息追加、FTS5 搜索和并发处理;第三条,看 gateway/session.py 与 gateway/run.py,理解不同平台如何构造 session key 并路由到 Agent;第四条,看 run_agent.py,理解 Agent Loop 中消息怎么进入、工具结果怎么写入、上下文怎么恢复。
阅读时带着四个问题:session_id 是什么时候生成的?消息以什么格式写入 messages 表?session_search 怎么从 FTS5 命中结果变成可用上下文?跨平台 handoff 为什么能保持同一条任务线?只要这四个问题打通,你就真正理解了 Hermes Sessions 的工程主线。
十三、对国内 AI 应用平台的工程启发
1、智能客服:每个用户会话不应只是前端聊天窗口,而应有统一 session_id、工单状态、工具调用历史、转人工历史、知识库命中历史。用户第二天回来时,系统要能知道"问题处理到哪一步"。
2、AI 编程助手:一次排查 Bug 可能跨越多轮命令、多个文件、多个测试结果。Sessions 应该记录目标、修改过的文件、执行过的命令、失败原因和最终决策,这样才能支持复盘和继续。
3、企业知识助手:不要把所有历史都塞进 prompt,而是用"完整存储 + 按需检索 + 精准注入"。用户提到过去的项目时,先搜历史,再把相关片段放进当前上下文。
4、多端产品:PC、网页、微信、飞书、钉钉、邮件只是入口,真正的任务状态应该在后端 Session 层统一管理。这样用户才能从任意入口继续同一件事。
5、审计与安全:既然 Agent 会调用工具,就必须记录工具调用、命令、结果、时间、平台来源和用户身份。否则出现误操作时无法追责,也无法优化工具链。
十四、总结:Sessions 让 Agent 从"聊天窗口"进化为"任务系统"
Hermes Agent 的 Sessions 机制,表面看是在保存聊天历史,实质上是在构建长期 Agent 的任务状态层。它把多平台入口、Agent Loop、工具调用、历史检索、上下文压缩、跨平台交接、成本统计和运维管理连接在一起。
最重要的结论有三点:第一,Session 不是聊天记录,而是任务轨迹;第二,History 不等于 Context,历史要完整保存,但推理时只注入必要内容;第三,跨平台 Agent 的关键不是接多少聊天软件,而是能否让同一个任务在不同入口之间保持同一条主线。
如果你正在做 AI 客服、AI 编程助手、企业知识库、自动化运营助手,Hermes Sessions 的设计非常值得参考:统一 session_id,保存完整消息和工具历史,用全文检索找回过去,用压缩和父子链路支撑长任务,用平台 session key 做隔离,用管理命令做运维。这样,Agent 才能真正从"一问一答"走向"长期协作"。
十五、核心概念对照表
|----------------|------------------------|-----------------------------------------------------------|
| 概念 | 通俗解释 | 在 Hermes Sessions 中的作用 |
| Session | 一次可恢复的任务轨迹 | 保存平台来源、用户、模型、消息、工具调用、token、标题和父子链路 |
| state.db | 本地 SQLite 状态仓库 | 统一存储 CLI 与 Gateway 会话,支持 FTS5 搜索 |
| session_id | 任务的唯一身份 | 恢复、搜索、导出、handoff 都围绕它进行 |
| session key | 平台消息到 session_id 的映射规则 | 解决私聊、群聊、线程、频道的上下文归属问题 |
| session_search | 跨会话检索工具 | 在过去会话中找关键历史,而不是让用户重复解释 |
| Handoff | 跨平台交接 | 把 CLI 里的 live conversation 转移到 Telegram/Discord/Slack 等平台 |
| Lineage | 父子会话链路 | 压缩或拆分后仍保留任务历史关系 |
| Prune / Export | 会话运维 | 清理、备份、迁移和分析长期历史 |