目录
[1. Tool Calling 是什么?](#1. Tool Calling 是什么?)
[2. Tool 的输入输出 Schema 怎么定义?](#2. Tool 的输入输出 Schema 怎么定义?)
[3. 工具调用失败怎么处理?](#3. 工具调用失败怎么处理?)
[4. 参数错误怎么兜底?](#4. 参数错误怎么兜底?)
[5. 如何防止模型调用危险工具? & 6. 暴露机制:直接给模型还是服务端分发?](#5. 如何防止模型调用危险工具? & 6. 暴露机制:直接给模型还是服务端分发?)
[7. 如何判断是 Prompt 问题还是模型能力问题?](#7. 如何判断是 Prompt 问题还是模型能力问题?)
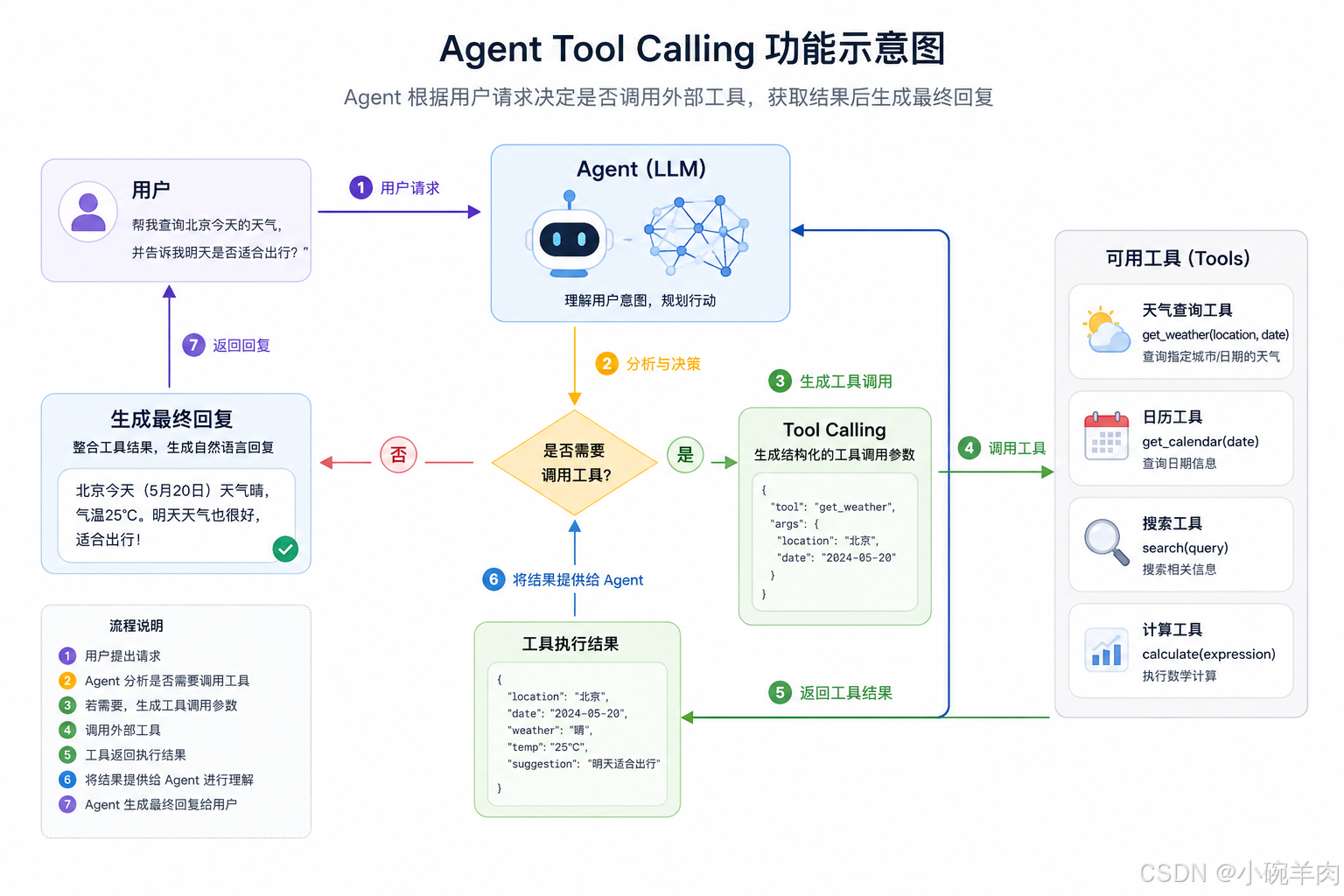
1. Tool Calling 是什么?
Tool Calling(有时也叫 Function Calling)是大模型输出结构化数据(通常是 JSON)以请求执行外部特定功能的能力。
大模型本身只是一个文本预测引擎,它无法联网、无法查数据库、也无法发送邮件。
Tool Calling 的本质是:你告诉模型有哪些工具可用(提供工具说明书),模型在理解用户意图后,如果认为需要使用某个工具,就会按你要求的格式输出一段包含"工具名"和"参数"的代码。真正的"执行"动作是由你的后端代码完成的,最后再把执行结果喂回给模型。
2. Tool 的输入输出 Schema 怎么定义?
业界目前事实上的标准是采用 JSON Schema 规范(OpenAI 也是采用此标准)。
-
输入定义 (Input Schema):
-
name: 工具的唯一标识符(只能用字母、数字、下划线)。 -
description: 最核心的部分! 这是写给模型看的"Prompt"。你需要清晰描述这个工具是做什么的、什么时候该用、什么时候不该用。 -
parameters: 定义各个参数的名称、数据类型(string, integer, boolean 等)、描述信息(告诉模型如何提取或构造这个参数),以及哪些是必填项(required)。
-
一个Input Schema的例子:
{
"name": "get_weather",
"description": "查询指定城市的天气",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,例如 Beijing"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["city"]
}
}-
输出定义 (Output Schema):
-
输出虽然不需要像输入那样严格遵循 JSON Schema,但关键原则是"克制"与"高信噪比"。
-
不要把原始的巨大 API 响应(比如包含几百个无用字段的 HTML 源码或复杂 JSON)直接扔给模型。在后端提取出模型回答用户问题所必需的关键字段,组装成精简的 JSON 或纯文本返回。这能大幅节省 Token 并减少模型的幻觉。
-
3. 工具调用失败怎么处理?
不要把原始异常直接丢给模型。建议返回结构化错误:
{
"ok": false,
"error_code": "TIMEOUT",
"message": "天气服务超时",
"retryable": true
}服务端可以按错误类型处理:
- 参数错误:让模型修正参数或向用户澄清
- 权限错误:提示用户授权
- 网络超时:自动重试 1-2 次
- 业务失败:返回可读原因
- 危险操作失败:不要自动重试
关键原则:工具失败不是模型失败,应该把失败变成模型可以理解的上下文。
4. 参数错误怎么兜底?
推荐分三层:
- 第一层:JSON Schema 校验,类型、必填、枚举、格式
- 第二层:业务校验,比如 user_id 是否存在、日期是否合法
- 第三层:修复或澄清
可自动修复的就修复,比如 "1" 转成 1、日期标准化、城市别名映射。不能确定的就让模型问用户,不要猜关键参数。
5. 如何防止模型调用危险工具? & 6. 暴露机制:直接给模型还是服务端分发?
绝对不能将工具直接暴露给模型执行。 * 架构层面(服务端分发): 模型只负责"决定调什么"并生成 JSON,真正的调用动作完全由你的后端服务器去发起。模型是一个不值得绝对信任的客户端,你的服务端必须扮演网关的角色。
-
防止危险调用的机制:
-
权限隔离 (RBAC): 不要在提供给模型的 Schema 里放入它不该知道的工具。根据当前用户的权限,动态组装可用工具列表。
-
服务端校验: 即使模型"幻觉"出了一个
delete_database的调用,只要你的服务端白名单里没有这个工具,或者校验发现当前用户无权限,直接拒绝执行。 -
Human-in-the-Loop (HITL) 审批: 对于高危操作(如转账、发送正式邮件、删除数据),模型生成调用指令后,前端必须弹窗要求真实用户点击"确认"后,服务端才会真正放行执行。
-
7. 如何判断是 Prompt 问题还是模型能力问题?
在调试 Agent 时,经常会遇到模型死活不调工具、乱调工具或参数拼错的情况。可以通过以下步骤交叉验证:
-
控制变量法(换模型测): 把相同的 Prompt 和 Tool Schema 喂给行业标杆模型(如 GPT 或 Claude)。
-
如果 GPT完美执行了,大概率是你当前使用的模型能力不足(特别是一些小参数量的开源模型,对复杂 JSON Schema 的遵循能力较差)。
-
如果 GPT也晕头转向,那绝对是你的 Prompt 或 Schema 描述写得有问题。
-
-
精简测试法: 把系统 Prompt 中与当前工具无关的设定全部删掉,只保留最基础的角色和这一个工具,看看模型能不能调对。如果能调对,说明原来的 Prompt 信息过载(上下文干扰)。
-
审查 Description: 检查你的工具和参数
description。不要用程序员思维写(比如param1: config map),要用自然语言向一个实习生解释(比如param1: 用户当前的地理位置,用于查询天气)。 -
增加 Few-shot (少样本提示): 在 Prompt 中给出一个正确调用工具的对话示例。如果加了示例后模型就能稳定调用,说明模型具备该能力,只是单凭 Schema 领悟不到你的意图,本质上还是原始 Prompt 的引导力不够。